








在 Retrieval Augmented Generation (RAG) 技术中,检索是直接影响生成输出质量的关键步骤。然而,基础 RAG 中的向量检索技术通常不足以满足所有情况。例如,传统的检索方法在处理大型私有文档存储库时往往表现不佳。许多研究团队已经开始将知识图谱整合到 RAG 中,来提高检索准确性,并取得了可喜的结果。今天,我们将探讨知识图谱的原理及其在 RAG 中的应用。
一、什么是知识图谱?
知识图谱是使用图结构来表示实体及其在现实世界中的关系并对其进行建模的一种技术方法。它将信息组织为节点(实体)和边(关系),形成一个有机网络,可以有效地存储、查询和分析复杂的知识。知识图谱的核心在于它使用三元组 (entity-relationship-entity) 来描述实体之间的关联。这种结构化数据表示形式捕获语义含义,便于理解和分析。
1.1 整体流程
在 RAG 中使用知识图谱一般流程如下图所示:
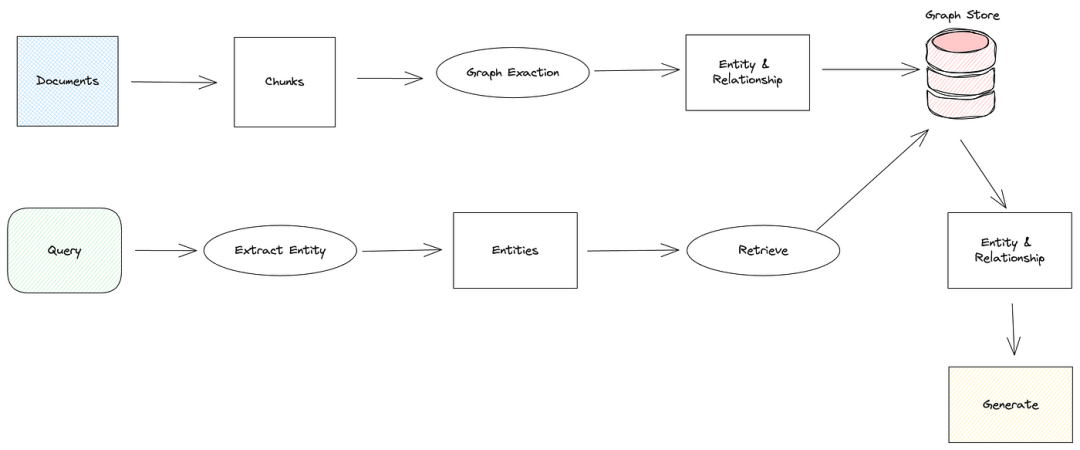
在数据摄取阶段,文档将被分块,并且知识图谱 RAG 系统将从这些块中提取实体和关系。这些实体和关系通常存储在图数据库中。
在检索过程中,知识图谱 RAG 从查询中提取实体,并从图数据库中检索相关实体和关系。检索结果通常会形成一个庞大的实体关系网络,然后将其与查询相结合,并提交给大型语言模型 (LLM) 以生成答案。
知识图谱 RAG 的一些实现结合了图检索和向量检索,利用两者的优势来提高检索的准确性和效率。
1.2 知识图谱解决RAG难点
在 RAG 中使用知识图谱主要解决了大型文档存储库的问答和理解挑战,尤其是基于 RAG 方法难以解决的全球性问题。Base RAG 在回答跨整个文档存储库的问题时通常表现不佳,例如“告诉我有关 XXX 的所有信息”。此类问题的上下文可能分散在大型存储库中,这使得通常使用 top-k 算法的矢量检索方法难以捕获所有相关的文档块,从而导致信息检索不完整。
此外,还有 LLMs上下文窗口问题。全局问题通常涉及大量上下文文档,将它们全部提交给 LLM 很容易超过其窗口限制。通过将文档提取到实体和关系中,知识图谱可以显著压缩文档块,从而可以将所有相关文档提交到LLM。
1.3 知识图谱RAG与Base RAG区别
- 知识图谱 RAG 使用图形结构来表示和存储信息,从而捕获实体之间的复杂关系,而Base RAG 通常使用矢量化文本数据。
- 知识图谱 RAG 通过图遍历和子图搜索来检索信息,而Base RAG 依赖于向量相似性搜索。
- 知识图谱 RAG 可以更好地理解实体之间的关系和层次结构,从而提供更丰富的上下文,而Base RAG 在处理复杂关系方面受到限制。
二、数据摄取
让我们看看知识图谱 RAG 的具体数据摄取过程。在Base RAG 中,文档块使用嵌入模型进行矢量化,并保存到矢量数据库中。相比之下,知识图谱 RAG 在摄取期间从文档块中提取实体和关系,并将其存储在图形数据库中。
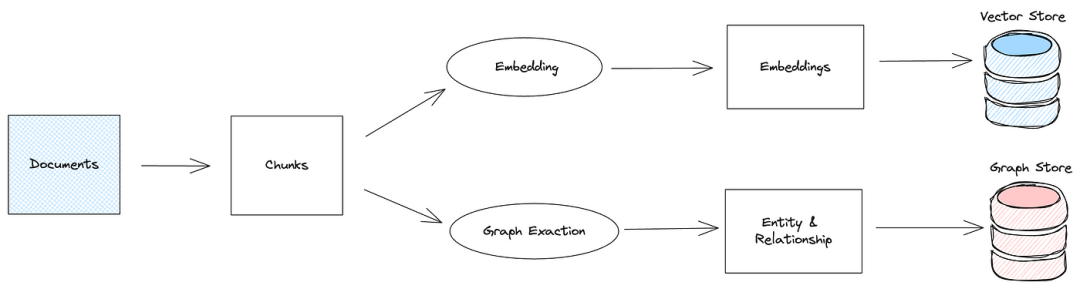
传统的实体提取方法基于预定义的规则和字典、统计机器学习或深度学习。在 LLM 时代,实体提取越来越多地利用 LLMs,从而更好地理解文本语义并简化实现。
例如,在 LlamaIndex[1] 的 KnowledgeGraphIndex 类中,实体提取提示如下所示:
DEFAULT_KG_TRIPLET_EXTRACT_TMPL = ("Some text is provided below. Given the text, extract up to ""{max_knowledge_triplets} ""knowledge triplets in the form of (subject, predicate, object). Avoid stopwords.\n""---------------------\n""Example:""Text: Alice is Bob's mother."
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 464
464

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











