







通过各个博主的知识中整理了一些自己想留存的,不记得哪个博主写的哪些啦,如有不妥的地方,联系我删除呀~
卷积层(无论输入图片多大,卷积层数参数规模都是固定的)
通过卷积操作对输入图像进行降维和特征抽取。
神经网络前部卷积层有小的感受野,可以捕捉图像局部,细节信息,后面卷积层感受野逐步加大,用于捕获更复杂和更抽象的信息。经过多个卷积层计算最后得到图像在各个不同尺寸下的抽象表示
池化层(下采样)
作用:1 降维,缩减模型大小,提升计算效率
2 降低过拟合概率,提升特征提取鲁棒性
3 对平移,旋转不敏感
池化层的具体实现在卷积之后,对得到的特征图像进行分块,图像被划分为不相交块。计算这些块内的最大值或平均值,得到池化后的图像。
下采样(缩小图像)
主要目的:1 使图像符合现实区域的大小
2 生成对应图像的缩略图
1 用stride = 2的卷积层实现。卷积过程导致的图像变小是为了提取特征,下采样的过程是一个信息损失的过程,而池化层是不可学习的。用步长为2的可学习卷积层代替pooling可以得到更好的效果,但增加了一定的计算量。
2 用stride = 2的吃化成实现池化下采样是为了降低特征的维度。比如max_pooling和average_pooling。目前通常使用max_pooling。因为其计算简单且能更好的保留纹理特征。
上采样(放大图像,图像插值)
主要目的:放大原图像,从而可以显示在更高分辨率的显示设备上
1 插值:一般使用双线性插值,效果最好。计算上比其他插值方式复杂。但卷积比不值一提。
2 转置卷积或反卷积。通过对输入的feature map间隔填充0,再进行标准的卷积计算。可以使得输出的feature map尺寸比输入更大。使用反卷积进行图像“上采样”是可以被学习的(会用到卷积操作,其参数是可以学习的)
Attention(优点:速度快,效果好)
本质的核心逻辑是从关注全部到关注重点。
即将有限的注意力集中在重点信息上,从而节省资源,快速获得有效的信息。

Attention机制每一步计算不依赖于上一步的计算结果。因此可以和CNN一样并行处理。
Attention引入Encoder-Decoder
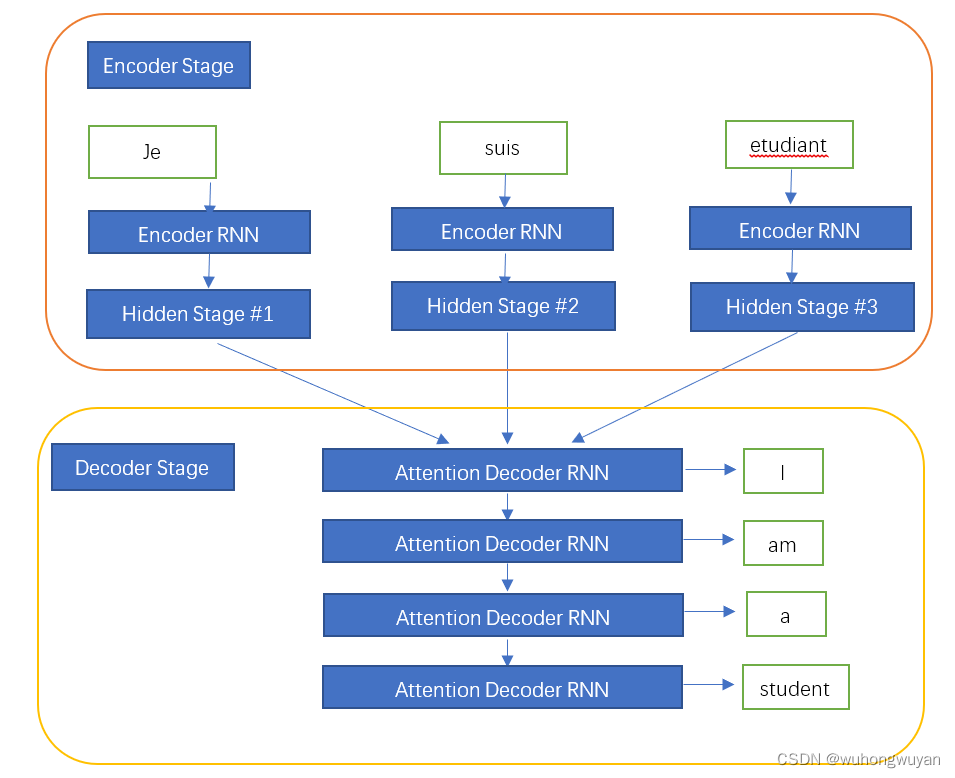
Attention并不一定在Encoder-Deconder下使用,可以脱离该框架。
简单理解:
图书馆(Source)里有很多书(Value),为了方便查找,给书做了编号(Key),比如:当我们看了《复仇者联盟》,想要了解漫威(Query),就可以看相关书籍。为了提高效率,并不是所有的书都要仔细看,针对漫威来说,动漫/电影相关的会看的仔细一些(权重高)但二战的书籍就需要简单扫一下即可(权重低)。


Step1: Query 和 key进行相似度计算,得到权值
Step2: 将权值进行归一化,得到直接可用的权值
Step3: 将权重和Value进行加权求和
根据Attention计算区域,可以分为以下几种:
1 Soft Attention:对所有的key求权重概率。每个key都有一个对应的权重,是一种全局的计算方式(Global Attention),这种方式参考了所有key的内容,再进行加权,但计算量会比较大一些。
2 Hard Attention:直接精准定位到某个key,其余key都不管。相当于这个key的概率2是1,其余key的概率全部为0,因此这种对齐方式要求很高。要求一步到位。如果没有正确对其,会带来很大影响。另一个方面,因为不可导,一般需要用强化学习的方式进行训练。
3 Local Attention:是1,2两种方式的折中,对一个窗口区域进行计算,先用Hard方式定位到某个地方,以该点为中心可以得到一个窗口区域,在这个子区域内可用Soft方式来计算Attention。
















 1121
1121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









