




论文标题:
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
代码地址:
0. 摘要
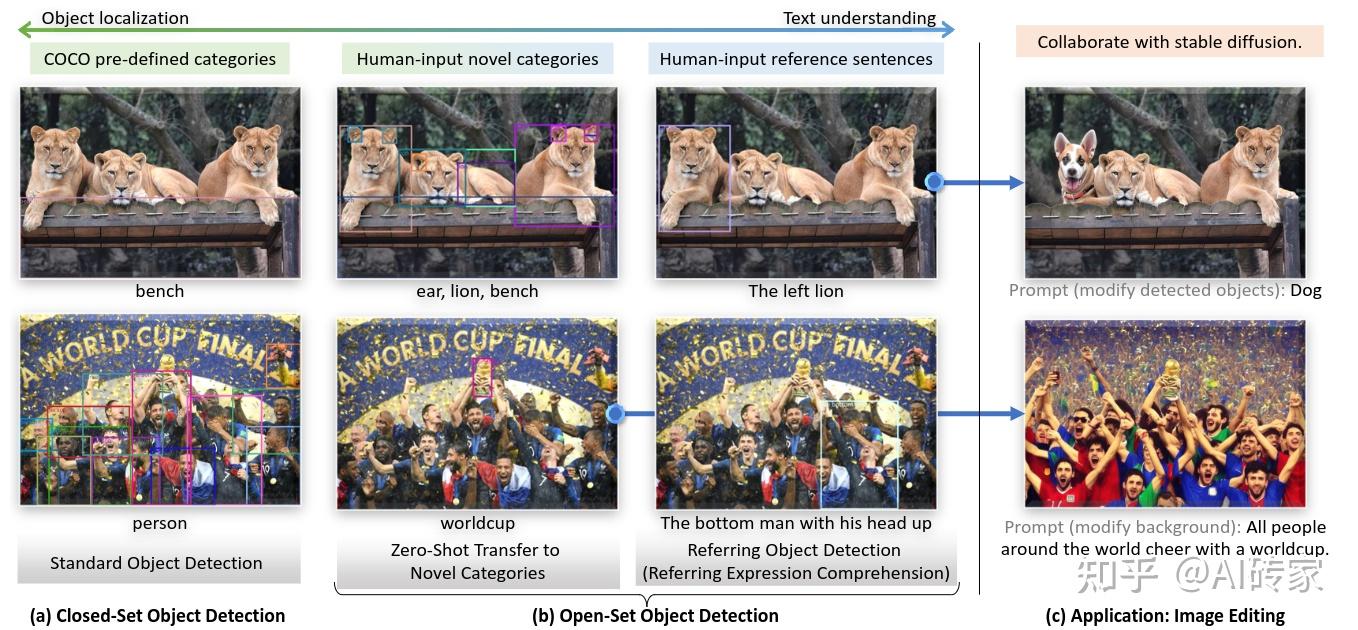
本文提出了一种开放集物体检测器,称为基于定位的DINO,通过将基于Transformer的检测器DINO与定位预训练相结合,可以检测任意物体,如人工输入的类别名称或指称表达等。开放集物体检测的关键解决方案是将语言引入封闭集检测器以实现开放集概念推广。为了有效地融合语言和视觉模态,我们从概念上将封闭集检测器分为三个阶段,并提出了紧密融合解决方案,包括特征增强器、语言指导的查询选择和跨模态解码器进行跨模态融合。尽管以前的工作主要在新类别上评估开放集物体检测,但我们提出也对用属性指定的对象进行指称表达理解评估。基于定位的DINO在所有三个设置上表现出色,包括在COCO、LVIS、ODinW和RefCOCO/+/g的基准测试。在不使用任何COCO训练数据的情况下,基于定位的DINO在COCO物体检测零样本转换基准测试上达到了52.5的平均精度 (AP)。在使用COCO数据微调后,基于定位的DINO达到了63.0的AP。它以26.1的平均AP在ODinW零样本基准测试上刷新了记录。
1. 引言
理解新概念是视觉智能的基本能力。在这项工作中,我们旨在开发一个强大的系统来检测人类语言输入指定的任意对象,我们将其称为开放集物体检测。由于其作为通用物体检测器的巨大潜力,这项任务具有广泛的应用前景。例如,我们可以将其与生成模型相结合进行图像编辑(如图1(b)所示)。
开放集检测的关键是利用语言实现未见对象的泛化[1,7,26]。例如,GLIP[26]通过将物体检测改造为短语定位任务并引入对象区域和语言短语之间的对比训练。它展示了这种表述形式在异构数据集上的巨大灵活性和在封闭集和开放集检测方面的显着性能。尽管GLIP取得了令人印象深刻的结果,但其性能可能受到限制,因为它是在基于传统的单阶段检测器Dynamic Head[5]上设计的。由于开放集和封闭集检测息息相关,我们认为一个更强大的封闭集物体检测器可以产生一个更好的开放集检测器。
受Transformer基础的检测器的进展鼓舞[24, 25, 31, 58],在本文中,我们提出在DINO[58]的基础上构建一个强大的开放集检测器,DINO不仅提供了目前最先进的物体检测性能,而且允许我们通过定位预训练将多级文本信息集成到其算法中。我们将该模型称为基于定位的DINO。与GLIP相比,基于定位的DINO具有几个优势。首先,其基于Transformer的架构与语言模型类似,从而更容易处理图像和语言数据。例如,由于图像和语言分支都是用Transformer构建的,我们可以轻松地在整个流程中融合跨模态特征。其次,基于Transformer的检测器已证明具有利用大规模数据集的卓越能力。最后,作为类似DETR的模型,DINO可以端到端优化,而不需要使用任何手工设计的模块,如NMS,这大大简化了整个定位模型的设计。
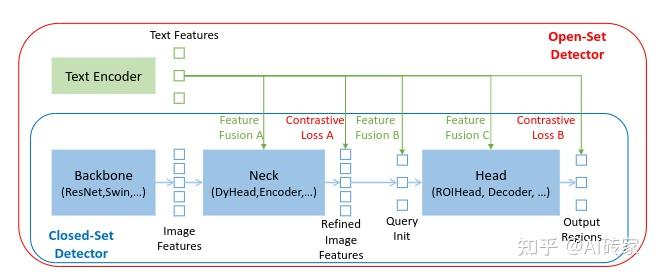
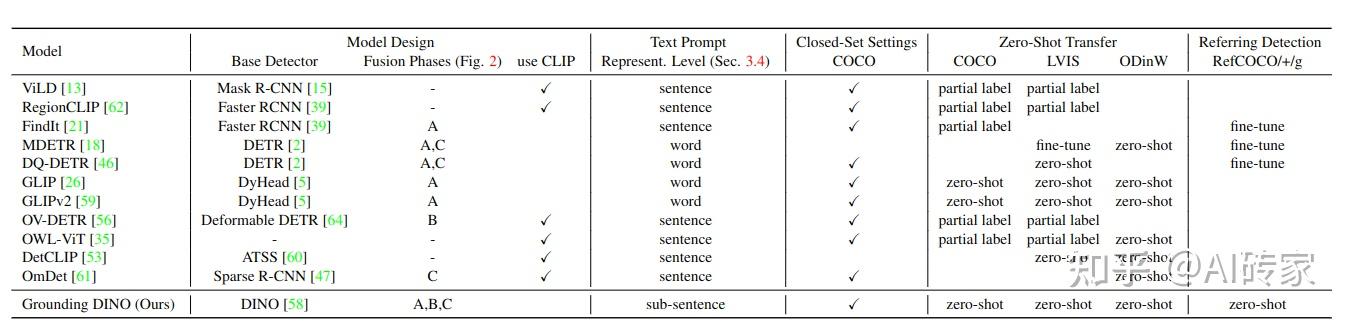
大多数现有的开放集检测器都是通过从封闭集检测器扩展到开放集场景并引入语言信息来开发的。如图2所示,一个封闭集检测器通常有三个重要模块,一个主干网络用于特征提取,一个颈部用于特征增强,以及一个头部用于区域调整(或框预测)。可以通过学习语义意识的区域嵌入来将封闭集检测器推广到检测新对象,以便每个区域可以在语义意识的语义空间中分类为新类别。实现这一目标的关键是在颈部和/或头部输出处使用区域输出和语言特征之间的对比损失。为了帮助模型对齐跨模态信息,一些工作尝试在最终损失阶段之前融合特征。图2显示,特征融合可以在三个阶段进行:颈部(阶段A)、查询初始化(阶段B)和头部(阶段C)。例如,GLIP[26]在颈部模块(阶段A)中执行了早期融合,OV-DETR[56]将语言感知查询用作头部输入(阶段B)。
我们认为管道中的更多特征融合使模型表现得更好。值得注意的是,检索任务更喜欢类似CLIP的两塔架构,该架构仅在末端执行多模态特征比较以提高效率。然而,对于开放集检测,模型通常同时给定图像和指定目标对象类别或特定对象的文本输入。在这种情况下,由于图像和文本一开始就可用,更喜欢紧密(和早期)融合模型以获得更好的性能[1, 26]。尽管概念上简单,但以前的工作难以在所有三个阶段进行特征融合。类似Faster RCNN等经典检测器的设计使其难以在大多数模块中与语言信息交互。与经典检测器不同,基于Transformer的检测器DINO与语言块具有一致的结构。分层设计使其可以轻松地与语言信息进行交互。在此原则下,我们在颈部、查询初始化和头部阶段设计了三种特征融合方法。更具体地,我们通过堆叠自注意力、文本到图像交叉注意力和图像到文本交叉注意力来设计特征增强器作为颈部模块。然后,我们开发了一种语言指导的查询选择方法来初始化头部的查询。我们还为头部阶段设计了一个具有图像和文本交叉注意力层的跨模态解码器,以提升查询表示。这三个融合阶段有效地帮助模型在现有基准测试上获得更好的性能,这将在第4.4节中显示。
尽管在多模态学习中取得了显着改进,但大多数现有的开放集检测工作仅在新类别的对象上评估其模型,如图1(b)左列所示。我们认为另一个重要的场景也应考虑,其中对象用属性描述。在文献中,该任务被称为指称表达理解 (REC) [30, 34]。我们在图1(b)右列中给出了一些REC的示例。这是一个密切相关的领域,但在以前的开放集检测工作中往往被忽视。在本文中,我们将开放集检测扩展到支持REC,并对其在REC数据集上的性能进行评估。
我们在所有三种设置下进行实验,包括封闭集检测、开放集检测和指称对象检测,以全面评估开放集检测性能。Grounding DINO明显优于竞争对手。例如,Grounding DINO在不使用任何COCO训练数据的情况下在COCO minival上达到了52.5 AP。它还以26.1的平均AP在ODinW [23]零样本基准测试上确立了新的最先进水平。
本文的贡献总结如下:
- 我们提出了Grounding DINO,它通过在多个阶段执行视觉语言模态融合来扩展封闭集检测器DINO,包括特征增强器、语言指导的查询选择模块和跨模态解码器。这种深度融合策略有效改进了开放集物体检测。
- 我们提出将开放集物体检测的评估扩展到REC数据集。它有助于评估模型对自由文本输入的性能。
- 在COCO、LVIS、ODinW和RefCOCO/+/g数据集上的实验表明,Grounding DINO在开放集物体检测任务上的有效性。
2. 相关工作
检测Transformer。基于定位的DINO建立在类似DETR的模型DINO [58]之上,DINO是一个端到端的基于Transformer的检测器。DETR首先在[2]中提出,然后在过去几年中从许多方面得到改进[4,5,12,17,33,50,64]。DAB-DETR [31]引入了锚框作为DETR查询,以进行更准确的框预测。DN-DETR [24]提出了查询去噪以稳定匹配。DINO [58]进一步开发了几种技术,在COCO物体检测基准测试中刷新了记录。然而,这些检测器主要侧重于封闭集检测,很难推广到新类别,因为预定义类别有限。
开放集物体检测。开放集物体检测使用现有的边界框注释进行训练,目的是检测任意类别的对象,语言泛化提供帮助。OV-DETR [57]使用由CLIP模型编码的图像和文本嵌入作为查询,以在DETR框架中解码类别指定的框。ViLD [13]从CLIP老师模型中蒸馏知识到类似R-CNN的检测器,以便学习到的区域嵌入包含语言的语义。GLIP [11]将物体检测形式化为定位问题,利用额外的定位数据帮助学习短语和区域层面上的语义对齐。它显示这样的表述甚至可以在完全监督的检测基准测试上取得更强的性能。DetCLIP [53]涉及大规模图像字幕数据集,并使用生成的伪标签来扩展知识数据库。生成的伪标签有效帮助扩展检测器的泛化能力。
然而,以前的工作只在部分阶段融合多模态信息,这可能会导致次优的语言泛化能力。例如,GLIP仅考虑在特征增强(阶段A)中进行融合,而OV-DETR仅在解码器输入(阶段B)处注入语言信息。此外,REC任务在评估中通常被忽视,这是开放集检测的一个重要场景。我们在表1中比较了我们的模型与其他开放集方法。
3. 基于定位的DINO
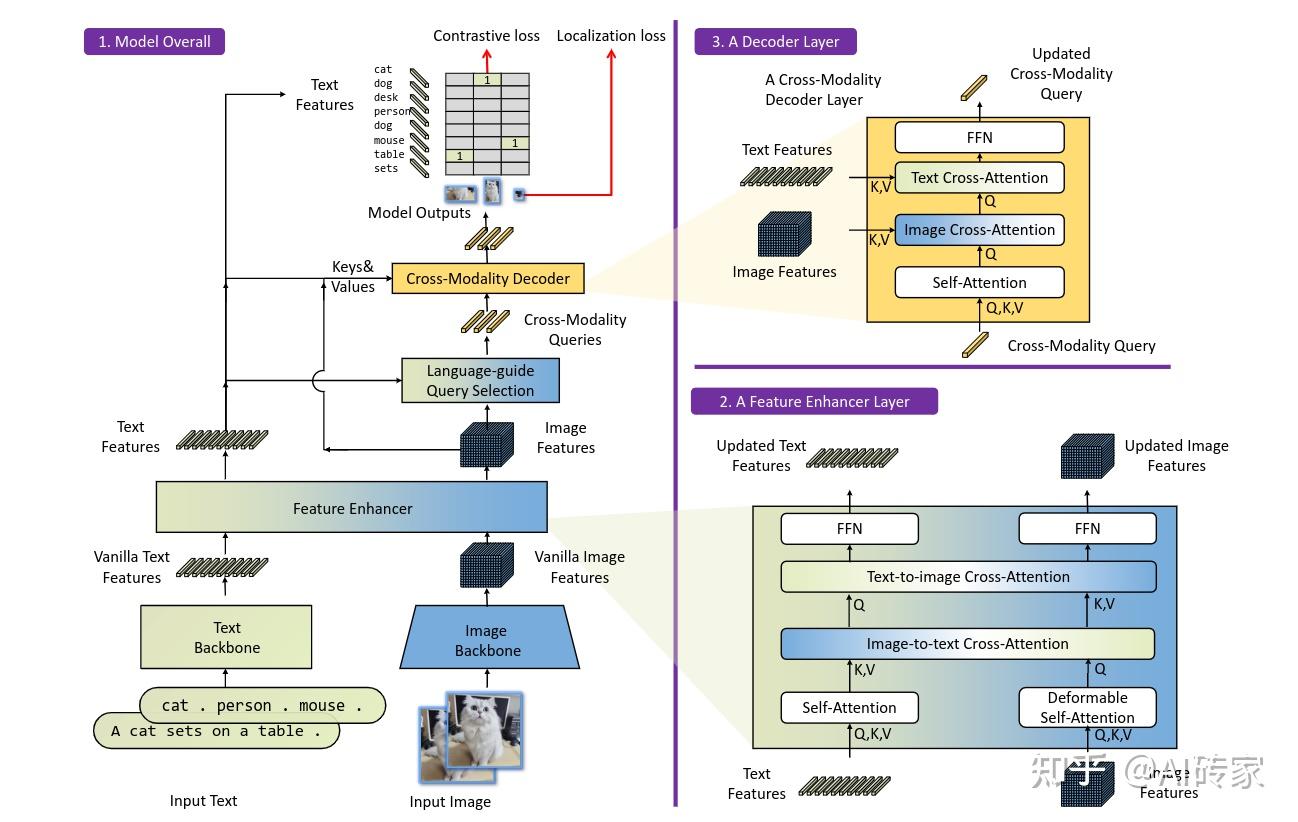
对于给定的(图像,文本)对,基于定位的DINO输出多个对象框和名词短语对。例如,如图3所示,模型从输入图像中定位一只猫和一张桌子,并从输入文本中提取词语cat和table作为对应的标签。物体检测和REC任务都可以与该流程对齐。遵循GLIP [26],我们将所有类别名称连接为物体检测任务的输入文本。REC需要每个文本输入一个边界框。我们使用得分最高的输出对象作为REC任务的输出。
基于定位的DINO是双编码器单解码器体系结构。它包含一个图像主干网络用于图像特征提取,一个文本主干网络用于文本特征提取,一个特征增强器用于图像和文本特征融合(第3.1节),一个语言指导的查询选择模块用于查询初始化(第3.2节),以及一个跨模态解码器进行框调整(第3.3节)。总体框架如图3所示。
对于每个(图像,文本)对,我们首先分别使用图像主干网络和文本主干网络提取原始图像特征和文本特征。这两种原始特征被输入到特征增强器模块中进行跨模态特征融合。在获得跨模态文本和图像特征之后,我们使用语言指导的查询选择模块从图像特征中选择跨模态查询。与大多数基于DETR的模型中的对象查询一样,这些跨模态查询将被馈送到跨模态解码器中,以从两个模态特征中探测所需特征并更新自身。最后一层解码器的输出查询将用于预测对象框并提取对应的短语。
3.1. 特征提取和增强器
给定一个(图像,文本)对,我们使用类似Swin Transformer [32]的图像主干网络提取多尺度图像特征,使用类似BERT [8]的文本主干网络提取文本特征。遵循以前的基于DETR的检测器[58, 64],从不同模块的输出中提取多尺度特征。在提取原始图像和文本特征后,我们将它们输入到特征增强器中进行跨模态特征融合。特征增强器包含多个特征增强层。我们在图3块2中说明了一个特征增强层。我们利用可变形自注意力来增强图像特征,利用普通自注意力增强文本特征。受GLIP [26]的启发,我们添加了图像到文本的交叉注意力和文本到图像的交叉注意力进行特征融合。这些模块帮助调整不同模态之间的特征。
3.2. 语言指导的查询选择
基于定位的DINO旨在检测输入文本指定的图像中的对象。为了有效利用输入文本指导物体检测,我们设计了一个语言指导的查询选择模块,用于选择与输入文本更相关的特征作为解码器查询。我们以PyTorch风格在算法1中呈现查询选择过程。变量image_features和text_features分别用于图像和文本特征。num_query是解码器中的查询数,在我们的实现中设置为900。我们在伪代码中使用bs和ndim表示批量大小和特征维度。num_img_tokens和num_text_tokens分别用于图像和文本标记的数量。
语言指导的查询选择模块输出num_query个索引。我们可以根据所选索引提取特征来初始化查询。遵循 DINO [58],我们使用混合查询选择来初始化解码器查询。每个解码器查询包含两部分:内容部分和位置部分[33]。我们将位置部分形式化为动态锚框[31],它们使用编码器输出进行初始化。另一部分内容查询在训练期间被设置为可学习的。
3.3. 跨模态解码器
我们开发了一个跨模态解码器来组合图像和文本模态特征,如图3块3所示。每个跨模态查询被馈送到自注意力层、图像交叉注意力层以组合图像特征、文本交叉注意力层以组合文本特征和每个跨模态解码器层中的FFN层。与DINO解码器层相比,每个解码器层都有一个额外的文本交叉注意力层,因为我们需要向查询中注入文本信息以实现更好的模态对齐。

3.4. 子句级文本特征
先前的工作探索了两种文本提示,我们将其分别命名为句子级表示和单词级表示,如图4所示。句子级表示[35,53]将整个句子编码为一个特征。如果短语定位数据中的某些句子有多个短语,则它会提取这些短语并丢弃其他单词。通过这种方式,它在损失句子中的细粒度信息的同时消除了单词之间的影响。
单词级表示[11,18]可以在一次前向传播中编码多个类别名称,但在输入文本是多个类别名称的任意顺序连接时,它会引入类别之间不必要的依赖关系。如图 4 (b) 所示,一些不相关的词在注意力机制中进行交互。为了避免不必要的词交互,我们引入注意力屏蔽来屏蔽不相关类别名称之间的注意力,称为“子句”级表示。它在保持词级特征以进行细粒度理解的同时消除了不同类别名称之间的影响。
3.5. 损失函数
遵循之前的DETR类工作[2,24,31,33,58,64],我们使用L1损失和GIOU [41]损失进行边界框回归。我们遵循GLIP [26] 在预测对象和语言标记之间使用对比损失进行分类。具体来说,我们将每个查询与文本特征进行点积以预测每个文本标记的逻辑,然后为每个逻辑计算focal损失[28]。边界框回归和分类成本首先用于在预测和真值之间进行双分匹配。然后我们在相同的损失组件下计算真值和匹配预测之间的最终损失。遵循DETR类模型,我们在每个解码器层之后和编码器输出之后添加辅助损失。
4. 实验
4.1. 设置
我们在三个设置下进行广泛的实验:封闭集设置下的COCO检测基准测试(第C.1节),零样本COCO、LVIS和ODinW的开放集设置(第4.2节),以及RefCOCO/+/g上的指称检测设置(第4.3节)。然后进行了消融实验以显示我们的模型设计的有效性(第4.4节)。我们还探索了一种通过训练几个插件模块将训练良好的DINO转移到开放集场景的方法,见第4.5节。我们的模型效率测试呈现在第I节。
实现细节我们训练了两个模型变体,分别具有Swin-T [32]和Swin-L [32]作为图像主干网络的Grounding-DINO-T和Grounding-DINO-L。我们从Hugging Face [51]利用BERT-base [8]作为文本主干网络。由于我们更关注模型在新类别上的性能,我们在主文本中列出了零样本转换和指称检测结果。更多实现细节请见附录第A节。
4.2. Grounding DINO的零样本转换
在此设置中,我们在大规模数据集上预训练模型,并直接在新数据集上评估模型。我们还列出了一些微调结果,以便我们的模型与先前的工作进行更全面的比较。
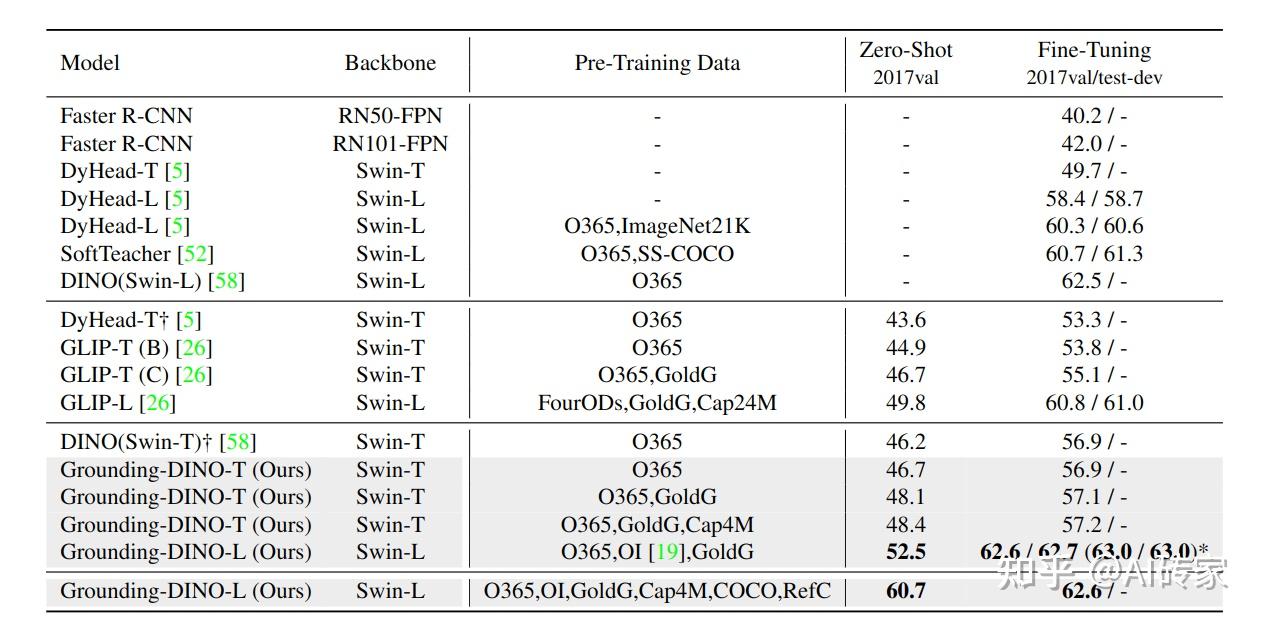
COCO基准测试我们在表2中将Grounding DINO与GLIP和DINO进行了比较。我们在大规模数据集上预训练模型,并直接在COCO基准测试上评估我们的模型。由于O365数据集[44]已经覆盖了COCO中的所有类别,我们将O365预训练的DINO评估为COCO上的零样本基准线。结果表明,DINO的COCO零样本转换优于DyHead。在相同设置下,Grounding DINO优于所有以前的模型,与DINO和GLIP相比,分别提高了+0.5AP和+1.8AP。定位数据对于Grounding DINO仍然有帮助,在零样本转换设置上带来了1AP以上的改进(48.1对46.7)。随着更强大的主干网络和更大的数据量,Grounding DINO在COCO物体检测基准测试上刷新了记录,在不看任何COCO图像的训练下达到了52.5的AP。在COCO物体检测基准测试上,在训练期间没有看任何COCO图像的情况下达到了52.5的AP。Grounding DINO在COCO minival上获得了62.6的AP,优于DINO的62.5 AP。当将输入图像放大1.5倍时,收益减少。我们怀疑文本分支增大了具有不同输入图像的模型之间的差距。尽管如此,Grounding DINO在使用COCO数据集微调后,在COCO test-dev上获得了63.0的AP(见表2括号中的数字)。
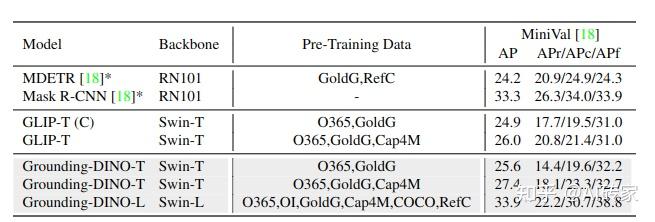
LVIS基准测试 LVIS[14]是一个长尾对象的数据集。它包含超过1000个类别进行评估。我们将LVIS用作下游任务来测试我们模型的零样本能力。我们使用GLIP作为我们模型的基准线。结果如表3所示。在相同设置下,Grounding DINO优于GLIP。我们在结果中发现了两个有趣的现象。首先,Grounding DINO在常见对象上比GLIP效果更好,但在稀有类别上效果较差。我们怀疑900个查询的设计限制了长尾对象的能力。相比之下,单阶段检测器使用特征图中的所有提议进行比较。另一个现象是,Grounding DINO随着更多数据的增加比GLIP获得更大的收益。例如,Grounding DINO随着字幕数据Cap4M引入了+1.8 AP的收益,而GLIP只有+1.1 AP。我们认为Grounding DINO具有比GLIP更好的可扩展性。我们将扩大规模训练留作未来工作。
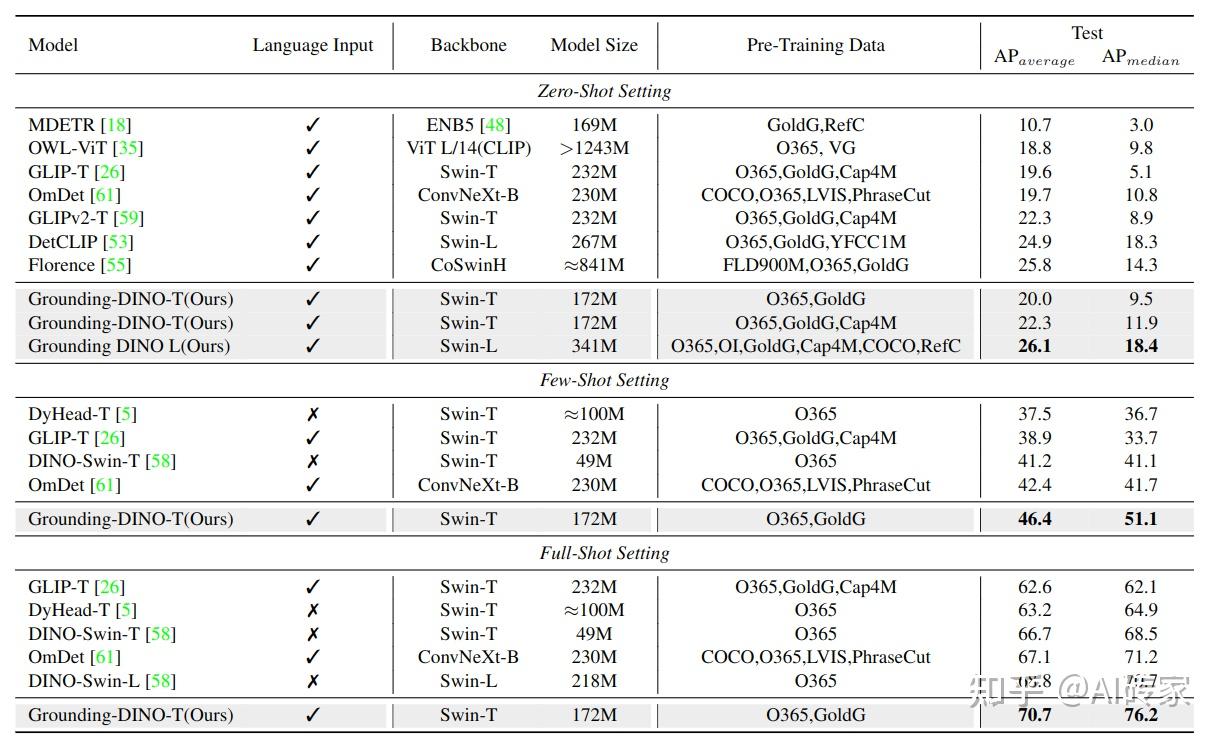
ODinW基准测试 ODinW(野外物体检测)[23]是一个在真实场景下测试模型性能的更具挑战性的基准测试。它收集了超过35个数据集进行评估。我们报告零样本、少样本和全样本三个设置的结果,见表4。Grounding DINO在该基准测试上表现良好。仅用O365和GoldG进行预训练,Grounding-DINO-T在少样本和全样本设置上优于DINO。令人印象深刻的是,具有Swin-T主干网络的Grounding DINO在全样本设置上优于具有Swin-L的DINO。在零样本设置下,Grounding DINO在相同主干网络下优于GLIP,与GLIPv2[59]相当,后者没有使用像遮蔽训练这样的新技术。结果显示了我们提出的模型的优越性。Grounding-DINO-L在ODinW零样本上刷新记录,达到26.1 AP,甚至优于巨型Florence模型[55]。结果表明Grounding DINO的泛化能力和可扩展性。
4.3. 指称对象检测设置
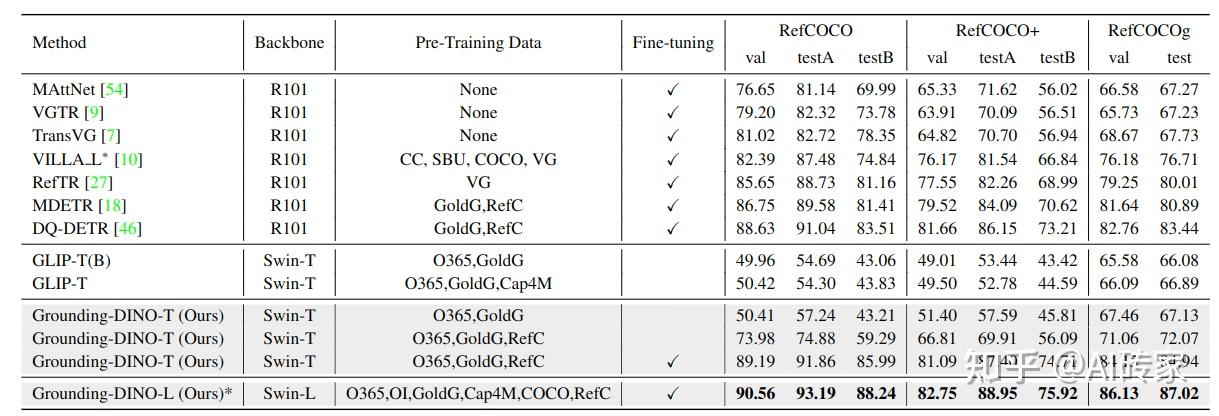
我们进一步探索了我们的模型在REC任务上的性能。我们利用GLIP [26]作为我们的基准线。我们直接在RefCOCO/+/g上评估模型性能。结果如表5所示。在相同设置下,Grounding DINO优于GLIP。尽管如此,如果没有REC数据,GLIP和Grounding DINO的表现都不佳。更多的训练数据(如字幕数据)或更大的模型有助于最终性能,但改进很小。将RefCOCO/+/g数据注入训练后,Grounding DINO获得了显著提升。结果表明,现今大多数开放集物体检测器需要更关注细粒度检测。
4.4. 消融实验
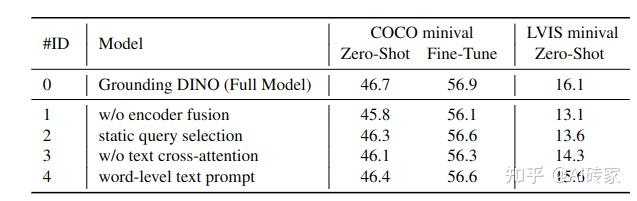
我们在本节进行了消融实验。我们为开放集物体检测提出了一个紧密融合的定位模型和子句级文本提示。为验证模型设计的有效性,我们为不同的变体移除了一些融合模块。结果如表6所示。所有模型都在带Swin-T主干网络的O365上进行了预训练。结果表明,每个融合都有助于最终性能。编码器融合是最重要的设计。单词级文本提示的影响最小,但也有帮助。语言指导的查询选择和文本交叉注意力分别对LVIS和COCO有较大影响。
4.5. 从DINO向Grounding DINO的迁移
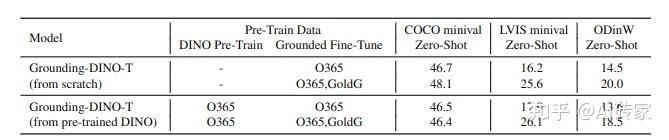
最近的工作呈现了许多使用DINO架构的大规模图像检测模型。从头开始训练一个Grounding DINO模型的计算成本非常高。但是,如果我们利用预训练的DINO权重,成本可以大大降低。因此,我们进行了一些实验,将预训练的DINO迁移到Grounding DINO模型。我们冻结DINO和Grounding DINO中共存的模块,仅微调其他参数。(我们在第E节比较了DINO和Grounding DINO)结果如表7所示。
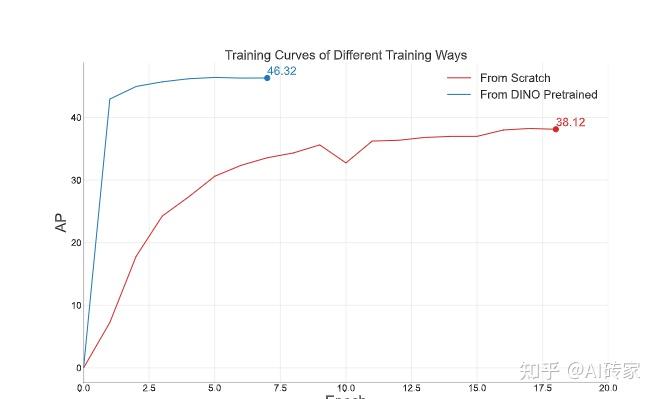
结果表明,我们可以只使用预训练DINO的文本和融合模块,实现与从头训练Grounding-DINO-T类似的性能。有趣的是,在相同设置下,DINO预训练的Grounding DINO优于标准Grounding DINO在LVIS上的性能。结果表明模型训练还有很大的改进空间,这将是我们未来要探索的方向。与从零开始训练相比,具有预训练DINO初始化的模型收敛速度更快,如图5所示。值得注意的是,我们在图5的曲线中使用了无指数移动平均 (EMA) 的结果,这导致与表7中的最终性能不同。由于从零开始训练的模型需要更多训练时间,我们仅显示早期时期的结果。
5. 结论
本文提出了基于定位的DINO模型。Grounding DINO将DINO扩展到开放集物体检测,使其能够检测给定文本作为查询的任意对象。我们回顾了开放集检测器的设计,并提出了一种紧密融合方法在跨模态信息中进行更好的融合。我们提出了子句级表示法,以更合理的方式使用检测数据作为文本提示。结果表明我们的模型设计和融合方法是有效的。此外,我们将开放集物体检测扩展到REC任务并进行相应的评估。我们发现现有的开放集检测器在没有微调的情况下在REC数据上表现不佳。因此,我们呼吁在未来研究中对REC的零样本性能给予额外关注。
局限性:尽管在开放集物体检测设置上表现出色,但Grounding DINO无法用于像GLIPv2这样的分割任务。此外,我们的训练数据少于最大的GLIP模型,这可能限制了我们的最终性能。
6. 致谢
我们感谢GLIP[26]的作者:Liunian Harold Li、Pengchuan Zhang和Haotian Zhang的帮助讨论和指导。我们还要感谢OmDet [61]的作者Tiancheng Zhao和DetCLIP [53]的作者Jianhua Han对他们模型细节的回应。我们感谢香港科技大学的He Cao对扩散模型的帮助。
7. 基于GroundingDINO的检测框自动标注的脚本
from time import time
import os
import cv2
import numpy as np
from PIL import Image
from typing import Tuple, Any
from GroundingDINO.groundingdino.util.inference import load_model, load_image, predict, annotate
import GroundingDINO.groundingdino.datasets.transforms as T
from database.read_database import ReadImages
class AutoLabellingObjectDetect:
def __init__(self):
self.data = ReadImages()
self.cont: int = 0
self.num_images: int = 0
self.class_id: int = 0
self.box_threshold: float = 0.25
self.text_threshold: float = 0.25
self.out_image_path: str = 'datasets/images/val'
self.out_txt_path: str = 'datasets/labels/val'
self.prompt: str = 'eye'
self.home: str = os.getcwd()
self.save: bool = True
self.draw: bool = False
self.images: list = []
self.names: list = []
self.bbox_info: list = []
def save_data(self, image_copy: np.ndarray, list_info: list):
timeNow = time()
timeNow = str(timeNow)
timeNow = timeNow.split('.')
timeNow = timeNow[0] + timeNow[1]
cv2.imwrite(f"{self.out_image_path}/{timeNow}.jpg", image_copy)
for info in list_info:
f = open(f"{self.out_txt_path}/{timeNow}.txt", 'a')
f.write(info)
f.close()
def config_grounding_model(self) -> Any:
config_path = os.path.join(self.home, "GroundingDINO/groundingdino/config/GroundingDINO_SwinT_OGC.py")
check_point_path = 'GroundingDINO/weights/groundingdino_swint_ogc.pth'
model =load_model(config_path, check_point_path, device="cuda")
return model
def main(self):
self.images, self.names = self.data.read_images('C:\\Utils\\Real_time_drowsy_driving_detection\\database\\open_eyes\\val')
self.num_images = len(self.images)
grounding_model = self.config_grounding_model()
# Crear los directorios si no existen
if not os.path.exists(self.out_image_path):
os.makedirs(self.out_image_path)
if not os.path.exists(self.out_txt_path):
os.makedirs(self.out_txt_path)
while self.cont < self.num_images:
self.bbox_info = []
print('------------------------------------')
print(f'name_image: {self.names[self.cont]}')
process_image = self.images[self.cont]
copy_image = process_image.copy()
draw_image = process_image.copy()
transform = T.Compose(
[
T.RandomResize([800], max_size=1333),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]
)
img_source = Image.fromarray(process_image).convert("RGB")
img_transform, _ = transform(img_source, None)
boxes, logits, phrases = predict(
model = grounding_model,
image = img_transform,
caption = self.prompt,
box_threshold = self.box_threshold,
text_threshold = self.text_threshold,
device = "cuda"
)
if len(boxes) != 0:
h, w, _ = process_image.shape
xc, yc, an, al = boxes[0][0], boxes[0][1], boxes[0][2], boxes[0][3]
# Error < 0
if xc < 0: xc = 0
if yc < 0: yc = 0
if an < 0: an = 0
if al < 0: al = 0
# Error > 1
if xc > 1: xc = 1
if yc > 1: yc = 1
if an > 1: an = 1
if al > 1: al = 1
self.bbox_info.append(f"{self.class_id} {xc} {yc} {an} {al}")
x1, y1, x2, y2 = int(xc * w), int(yc * h), int(an * w), int(al * h)
print(f"boxes: {boxes}\nxc: {x1} yc:{y1} w:{x2} h:{y2}")
if self.save:
self.save_data(copy_image, self.bbox_info)
if self.draw:
annotated_img = annotate(image_source=draw_image, boxes=boxes, logits=logits, phrases=phrases)
out_frame = cv2.cvtColor(annotated_img, cv2.COLOR_BGR2RGB)
cv2.imshow('Grounding DINO detect', out_frame)
cv2.waitKey(0)
self.cont += 1
auto_labeling = AutoLabellingObjectDetect()
auto_labeling.main()
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









