




1. 引言
作为自动驾驶系统中的环境感知中心,高精度 (HD) 地图通过整合厘米级几何拓扑和地图元素(如道路边界、车道分隔线和行人过街区)的语义交通属性,为决策和规划模块提供可解释的结构化环境表示(Qiao et al., 2023b; Yuan et al., 2024a)。因此,在高精度和长距离下构建HD地图对于确保自动驾驶系统在复杂城市场景中的智能化、可靠性和安全性至关重要(Sun et al., 2023; Luo et al., 2023)。
传统方法采用离线地图构建策略,首先利用配准算法生成大规模全局点云,随后通过人工标注创建全局一致的语义地图(Li等人,2022)。然而,该方法在成本和时间新鲜度方面面临显著挑战(Liu等人,2023a),难以适应动态城市场景。随着硬件和数据处理算法的进步,利用车载传感器数据构建局部高精度地图已成为一种有前景的解决方案。
HDMapNet(Li等人,2022年)是首个基于深度学习的HD地图构建框架,将HD地图构建视为一个语义分割任务,将HD地图栅格化并为每个像素分配标签。通过解码BEV空间中的特征,同时实现了三个子任务:语义分割、实例嵌入和方向估计。HDMapNet(Li等人,2022年)为后续栅格地图估计方法(Liao等人,2024年;Dong等人,2024年;Liu等人,2023b年)建立了基本框架。Jia等人(2024年)将扩散模型引入基本框架,并提出了一种新方法DiffMap,通过添加和移除噪声的过程学习地图先验,确保输出与当前帧观测匹配。然而,栅格化地图并非理想表示。它包含每个像素的冗余信息,需要大量存储空间,尤其是在地图范围较大时(Ding等人,2023年)。它假设像素和元素之间相互独立(Liu等人,2023a年),导致形状错误或缺失(如图1a所示)。此外,后续任务需要对矢量化进行复杂后处理,增加了额外的计算复杂性和累积误差。

为解决上述局限性,端到端构建向量化高精度地图的方法近年来已成为一种日益突出的解决方案,并取得了显著成效。近期研究尝试以统一有序的点集形式对地图元素进行建模,并直接通过模型学习每个点的标签和位置。然而,这种统一的点建模策略难以在计算复杂度和构建精度之间取得平衡(Ding等人,2023)。为此,在过去的两年中,提出了一种将地图元素建模为有序关键点的创新解决方案,如图1b所示,极大地提高了存储效率。然而,当前基于关键点的方法仅使用单一模态,感知能力有限,或直接将不同模态的特征进行拼接,而未考虑协同效应和差异对生成鸟瞰图(BEV)特征的影响,导致地图范围有限(通常在Y轴方向为60米)。此外,仅利用点信息对地图元素进行分类和定位,难以处理元素故障,如元素形状错误或元素之间的缠绕,导致构建精度较低。
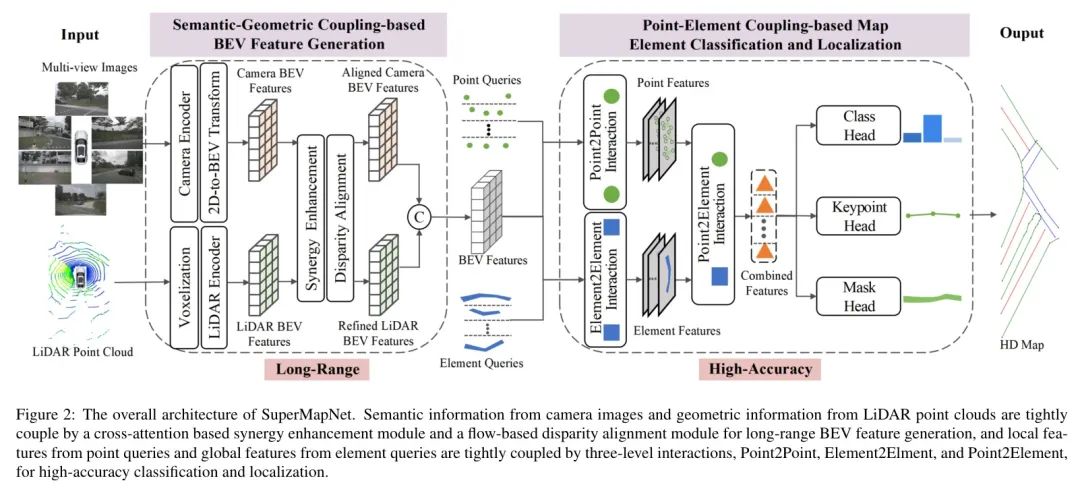
在本研究中,作者提出了SuperMapNet用于构建长距离和高精度的矢量化高精度地图。整体架构如图2所示。相机图像和激光雷达点云均被用作输入。通过每种模态的特征编码器,分别获得带有语义信息的相机BEV特征和带有几何信息的激光雷达BEV特征。然后,相机BEV特征和带有几何信息的激光雷达BEV特征首先通过基于交叉注意力的协同增强模块和基于流的视差对齐模块紧密耦合,以在长距离范围内学习具有丰富语义和几何信息的融合BEV特征。其次,来自点 Query 的局部知识和来自元素 Query 的全局知识通过三个层面的交互紧密耦合,以实现地图元素的高精度分类和定位,其中点与点之间的交互用于学习相同元素内点和每个点之间的局部信息,元素与元素之间的交互用于不同元素之间以及每个元素之间的关系约束和语义信息学习,点与元素之间的交互用于学习其构成点的元素级补充信息。作者的贡献总结如下:
长距离:通过考虑相机图像与激光雷达点云之间的协同效应和差异,SuperMapNet在长距离上表现出色,在Y轴方向上可达120米,是其他对比方法的两倍;
高精度:点 Query 与元素 Query 在三个层次上的交互有效减少了错误形状和元素之间的缠绕,在nuScenes和Argoverse2数据集的困难/简单设置下,分别比之前的SOTA方法提高了14.9/8.8 mAP和18.5/3.1 mAP。
本文组织结构如下。第二节回顾了用于高精度地图构建的相关工作。第三节介绍了SuperMapNet的工作流程以及提出的用于语义和几何信息耦合、点和要素信息耦合的模块。第四节对所提出的SuperMapNet进行了评估与分析,并与SOTA方法进行了比较。第五节讨论了不同模块的消融研究。最后,第六节总结了结论。
2. 相关工作
HD地图构建的主要工作流程可分为两个步骤:BEV特征生成和地图元素的分类与定位。前者旨在将来自不同视角和不同模态的特征转换为相同的BEV空间,后者旨在基于BEV特征确定每个地图元素的具体形状、位置和类别。
2.1. 多模态融合
根据图3所示的不同模态生成BEV特征的方式,现有的局部高精度地图构建方法可分为三种类型:相机LiDAR融合、相机标准定义地图 (SD Map) 融合以及相机时序融合方法。
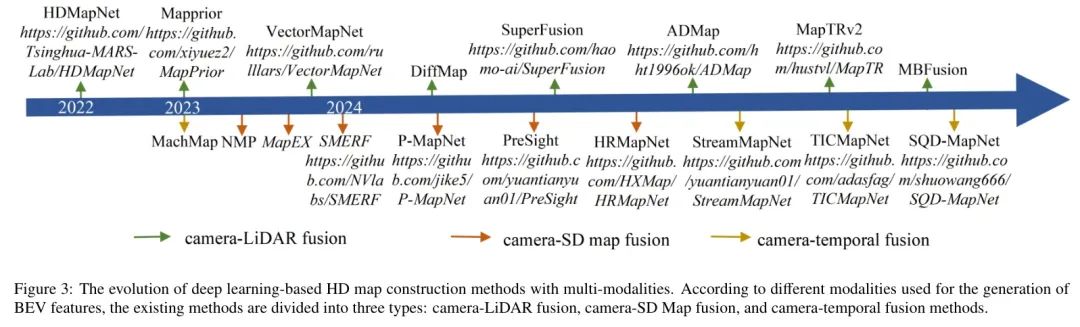
相机-激光雷达融合:HDMapNet(Li等人,2022)开创了首个用于高精度地图构建的相机-激光雷达融合框架,旨在弥补单一模态感知的局限性。该框架首先利用几何投影(如IPM(Mallot等人,1991)和LSS(Philion和Fidler,2020))或基于Transformer的方法(如BEVFormer、PolarFormer和WidthFormer(Yang等人,2024a)),将透视视图中的特征显式或隐式地转换为具有视觉相机先验几何信息的鸟瞰视图。同时,使用PointPillar(Lang等人,2019)、Second(Yan等人,2018)或VoxelNet(Zhou和Tuzel,2018)等模型从 Voxel 化后的激光雷达点云中提取鸟瞰视图特征;然后,将激光雷达鸟瞰视图特征与相机鸟瞰视图特征直接拼接生成融合特征。这种直接拼接策略忽略了不同模态之间的协同效应和差异,导致感知范围有限且精度较低。SuperFusion(Dong等人,2024)显式利用激光雷达点云的几何信息来监督相机图像的深度估计,并使用交叉注意力机制交互两种模态的鸟瞰视图特征,生成融合了点云几何信息与相机图像语义信息的鸟瞰视图特征,从而缓解Sparse点云导致距离细节不足的问题。MBFusion(Hao等人,2024)基于交叉注意力机制增加了一个双动态融合模块,自动从不同模态中选取有价值信息以实现更好的特征融合。相机-激光雷达融合方法通过补充几何和语义信息,可以显著提高模型的准确性和鲁棒性,但现有方法忽略了不同传感器定位误差引起的特征错位问题。
相机-SD地图融合:NMP(Xiong等人,2023)提出了一种基于神经先验网络的高清地图构建新范式,旨在通过利用先验知识(包括显式的标清地图数据和隐式的时序线索)来增强车道感知和拓扑理解,从而提升恶劣天气条件及远距离下的感知能力。该框架首先通过车辆的自车位姿 Query 当前局部SDMap,然后通过CNN和Transformer等模型对局部SD地图先验知识和在线传感器感知信息进行编码。通过计算局部SD地图先验知识与在线传感器BEV特征之间的交叉注意力,构建局部高清地图。NMP提供了基础灵感。
在此基础上,PreSight(Yuan等人,2024b)构建了城市级神经辐射场,引入了基础视觉模型DINO(Caron等人,2021)的知识,构建了包含可泛化语义信息的城市级先验知识,然后直接将在线BEV特征进行拼接以增强感知能力。相机-SD地图融合方法通过静态与动态信息、几何与语义信息的互补性,有效提升了准确性、鲁棒性和感知范围,显著降低了实时计算负担。然而,该策略依赖于先验地图的可用性,需要预先存储大规模城市级SD地图数据,导致存储成本较高。
相机-时间融合方法:MachMap(Qiao等人,2023b)首先提出了一种时间融合策略,该策略利用车辆的ego姿态将BEV特征的先前隐藏状态与当前隐藏状态关联起来,然后通过拼接获得融合特征。该策略旨在利用连续帧的时间信息来解决遮挡和其他复杂场景引起的数据丢失问题。
在此基础上,StreamMapNet(Yuan等人,2024a)和StreamMapNet SQD(Wang等人,2025)提出了一种 Stream 时间融合策略,将所有历史信息编码到记忆特征中以节省成本并建立长期时间关联,然后使用门控循环单元融合不同时间点的BEV特征。考虑到不同时间点的特征坐标差异,TICMapNet(Qiu等人,2024)设计了一个时间特征对齐模块以消除坐标误差,然后通过可变形注意力机制融合时间信息。相机-时间融合方法通过动态静态互补填补特征空洞并扩展感知范围,但该策略的研究仍处于初级阶段。
2.2. 向量化高精度地图构建
矢量化高精度地图构建模型将地图元素映射为有序的点集或线集,基于鸟瞰图特征 Query 建模信息,用于地图元素的位置定位和分类。根据其创新点,现有的矢量化高精度地图构建方法可分为两类:地图元素表示的创新和建模信息 Query 的创新。
地图元素表示的创新:MapTR 是首个端到端的矢量地图构建框架,使用统一有序点集对地图元素进行建模。它通过层级 Query 嵌入编码元素特征,并通过置换等变建模进行层级匹配。该框架为基于统一有序点集的矢量地图元素表示奠定了理论基础,并在后续方法中得到了系统性的应用。然而,这种统一点集建模策略难以在计算复杂度和构建精度之间取得平衡(Ding等人,2023年)。为解决这一问题,Ding等人(2023年)引入了基于有序关键点集的地图元素统一表示方法,并提出了一种名为PivotNet的新框架。统一有序点集被分为两个序列:枢轴序列包含对线条整体形状和方向有贡献且维持其关键特征的点,而共线序列指那些可以安全移除而不影响线条形状的点。基于关键点的该方法可以优化存储效率并保持构建精度。
在此基础上,VectorMapNet(Liu等人,2023a)提出了一种由粗到细的构建策略,以曲线形式对地图元素进行建模。它首先生成地图元素的关键点,然后通过Transformer架构生成多段线。BeMapNet(Qiao等人,2023a)将地图元素建模为分段贝塞尔曲线,并设计了一个分段贝塞尔头用于动态曲线建模,该头采用两个分支进行分类和回归,前者用于分类分段数量以确定曲线长度,后者用于回归控制点坐标以确定曲线形状。然而,上述方法仅使用点信息对地图元素进行分类和定位,难以处理元素故障,如错误形状或元素之间的缠绕(Zhou等人,2024年)。
建模信息 Query 的创新:为解决上述问题,MapTRv2(Liao等人,2024)将元素 Query 与点 Query 结合为混合 Query,沿点维度使用自注意力机制获取点信息,沿元素维度获取元素信息,这显示了元素信息在处理元素故障方面的巨大潜力。类似地,InsMapper(Xu等人,2024)通过混合 Query 生成方案结合元素 Query 与点 Query,并将混合 Query 作为建模信息 Query 的基本处理单元。然而,将混合 Query 视为基本处理单元而不是分别考虑点 Query 和元素 Query,会导致严重的重复处理,例如在 Query 点建模信息时重复元素 Query,在 Query 元素建模信息时重复点 Query,从而导致计算复杂度高。
在此基础上,HIMapNet(Zhou等人,2024)将混合 Query 分别分解为点 Query 和元素 Query,并使用自注意力机制分别增强点建模信息和元素建模信息,遵循点-元素交互器 Query 点与元素之间的信息。然而,他们忽略了点与点之间、元素与元素之间的关系。GeMap(Zhang等人,2025)通过引入平移和旋转不变的表示来增强地图元素的表示,有效利用地图元素的几何特性,并通过位移向量编码地图特征的局部结构。设计了一种基于角度和幅度线索的几何损失,该损失对驾驶场景的刚性变换具有鲁棒性。
MGMapNet(Yang等人,2024b)将元素 Query、点 Query 和参考点作为输入。通过从BEV特征中直接采样点并结合点 Query,提高了预测几何点的准确性;通过使用采样点特征更新元素 Query,有效捕获了道路元素的整体类别和形状信息。
3. 方法
3.1. 架构概述
图2展示了SuperMapNet的整体架构,主要包含一个用于生成BEV特征的语义-几何耦合(SGC)模块和一个用于地图元素分类与定位的点-元素耦合 (PEC) 模块。
基于语义-几何耦合的BEV特征生成。该模块将相机图像和激光雷达点云作为输入,旨在输出具有长距离语义和几何信息的融合BEV特征。对于具有语义信息的相机图像,采用Swin Transformer(Liu等人,2021)作为共享 Backbone 网络,对透视视图中的多视图图像特征进行编码;然后,通过具有相机几何先验的变形Transformer(Zhu等人,2021)将透视视图中的特征连接并转换到统一的BEV空间。对于具有精确几何信息的激光雷达点云,生成BEV特征的复杂度远低于相机。首先,原始点云被下采样以减少数量,然后,应用PointPillars(Lang等人,2019)在XOY平面进行动态 Voxel 化,以在BEV空间中生成激光雷达点云的特征。其次,应用语义-几何耦合 (SGC) 模块来捕捉相机BEV特征和激光雷达BEV特征之间的互补性,并减少不同模态的坐标误差,该模块由基于交叉注意力的协同增强模块和基于流的视差对齐模块组成。最后,通过连接操作生成具有丰富语义和几何信息的融合BEV特征。
基于点-元素耦合的地图元素分类与定位。遵循PivotNet 的方法,作者的SuperMapNet模型以有序关键点集的形式映射地图元素,因为基于关键点的表示可以优化存储效率并保持构建精度。该模块以融合的BEV特征、点 Query 和元素 Query 为输入,旨在输出地图元素的位置和分类。首先应用点-元素耦合 (PEC) 模块来捕获局部和全局建模信息、点 Query 和元素 Query 之间的几何和语义建模信息之间的关系。PEC模块包含三个层级的交互,其中Point2Point交互学习同一元素内点与各点之间的局部几何信息,Element2Element交互学习不同元素之间的关系约束和每个元素的语义信息,Point2Element交互学习其构成点的补充元素信息。最后,具有局部和全局建模信息以及几何和语义建模信息的特征被发送到三个不同任务的解码器,一个分类头用于学习元素的类别,一个带动态匹配模块(Ding等人,2023)的关键点头用于回归关键点坐标和顺序,以及一个 Mask 头用于预测每个元素的 Mask。
3.2. 语义-几何耦合模块 (SGC)
激光雷达点云和相机图像的感知能力各有优劣。激光雷达点云能够提供精确的三维几何信息,但在有效范围内存在无序和Sparse的问题;相机图像可以在远距离捕捉丰富的环境语义信息,但缺乏精确的三维几何信息(Dong等人,2024)。融合激光雷达点云和相机图像的多模态方法能够有效互补,在远距离生成兼具丰富语义和几何信息的特征。然而,由于多模态特征之间的互补性以及不同传感器之间的坐标误差,直接拼接不同模态的特征会导致构建精度较低。因此,如图4所示,提出了一种语义-几何耦合 (SGC) 模块,用于融合不同模态的特征,并考虑了不同模态之间的协同效应和差异。
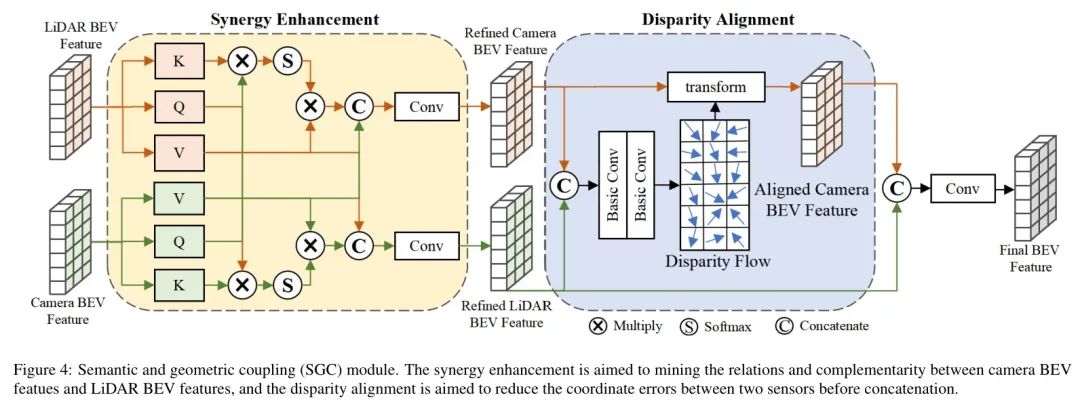
协同增强。针对相机BEV特征与LiDAR BEV特征的协同,提出了一种基于交叉注意力的增强模块,用于丰富语义信息并填补LiDAR BEV特征在距离上的特征空洞,同时为相机BEV特征添加精确的3D几何信息。对于每种模态的BEV特征(如列表所示),首先使用三个MLP层分别获取其 Query
、键
和值
,其中
。
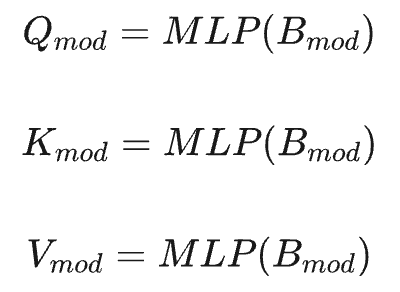
其次,根据式4和式5,从相机BEV特征到LiDAR BEV特征的注意力矩阵是通过不同模态的 Query
和键
之间的内积的softmax归一化得到的,而注意力矩阵
则由
和
获得。然后,通过将注意力矩阵
与其对应模态的值
相乘,得到相机BEV特征的互补信息
,而LiDAR的互补信息
则通过将
与
相乘得到。最后,根据式8,将每个模态的原始值
和互补信息
进行拼接,并将其发送到一个基础卷积块,以学习每个模态的精细BEV特征
,这些特征同时包含语义和几何信息。

图4:ICANMRI耦合,其包含THIO和BV特征以及DR-BEV特征,并且差异性对齐旨在减少两个传感器在连接之前的坐标误差。
![]()
其中 ,并且
是一个缩放因子。
视差对齐。由于传感器误差导致两种模态之间存在视差,直接拼接两种模态的BEV特征会导致低精度。因此,采用基于流的视差对齐模块,将精细化的相机BEV特征与精细化的激光雷达BEV特征进行配准,因为激光雷达的姿态精度始终高于相机。

3.3. 点-单元耦合模块 (PEC)
对于以有序关键点集建模的地图元素,存在三个层次的信息:(1) 点级信息,表示每个点的局部坐标以及同一元素内点之间的几何关系;(2) 元素级信息,表示每个元素的整体形状和语义类别以及相邻元素之间的关系;(3) 元素与附属点之间的信息,其中元素信息为附属点提供全局约束和语义信息,而附属点为其元素提供具体的细节细化。这三个层次的信息相互协作。仅利用一个或两个层次的信息往往会导致元素失效,例如形状错误或元素之间的缠绕。因此,如图5所示,作者提出了点-元素耦合(PEC)模块,以全面耦合点和元素的局部与全局、语义与几何信息,该模块由三个层次的交互组成:点-点、元素-元素、点-元素。
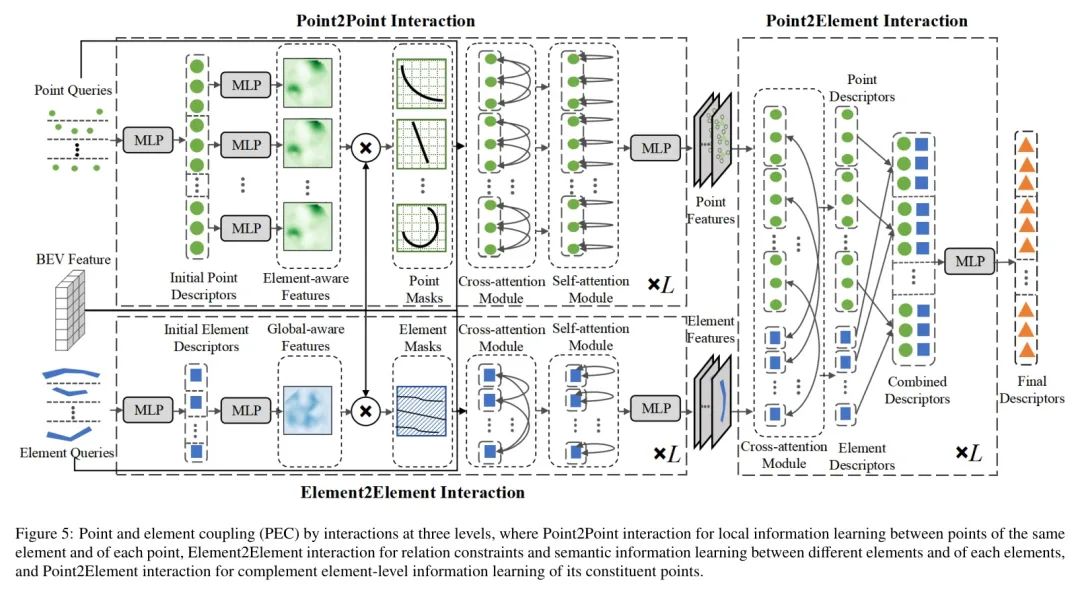


4. 实验
4.1. 实验设置
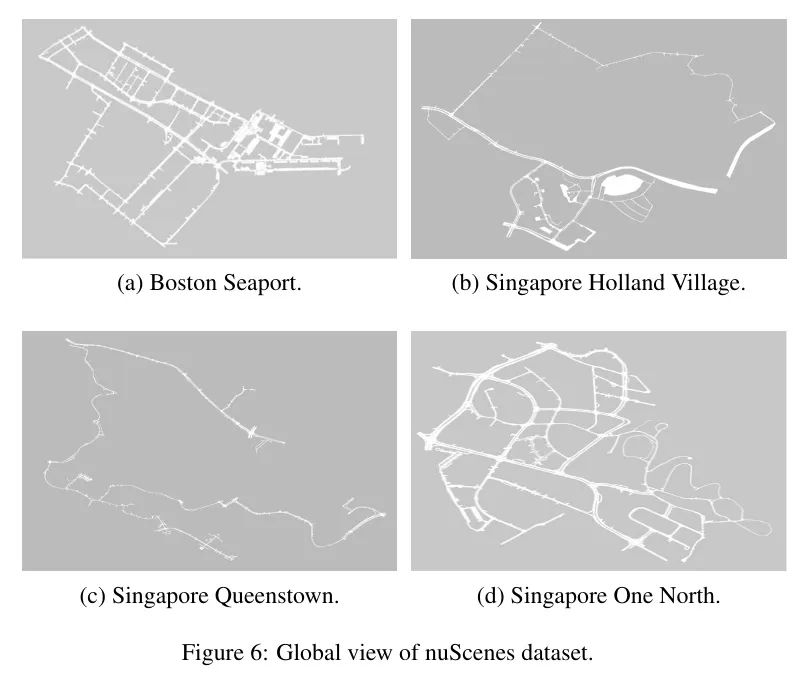
NuScenes数据集。如图6所示,nuScenes数据集(Caesar等人,2020)包含从波士顿港口和新加坡的One North、Queenstown以及Holland Village等以交通密集和驾驶条件极具挑战性而闻名的区域收集的1000个场景。每个场景持续约20秒,并以2Hz的频率进行标注。每个样本包含来自周围摄像头的6张RGB图像以及来自LiDAR扫描的点云数据。遵循先前方法(Ding等人,2023;Qiao等人,2023a),700个场景(28130个样本)用于训练,150个场景(6019个样本)用于验证,6019个样本用于测试。为了进行公平比较,作者重点关注三类地图元素,包括道路边界、车道分隔线和行人过街区。
Argoverse2数据集。该数据集(Wilson等人,2021)包含来自美国六个不同城市的1000条日志,这些城市分别是奥斯汀、底特律、迈阿密、帕洛阿尔托、匹兹堡和华盛顿特区,记录了不同季节、天气条件和一天中的不同时间。每条日志包含来自7个环形相机和2个立体相机的15秒 RGB图像,LiDAR扫描以及一个三维向量化地图。遵循先前的工作(Zhou等人,2024),700条日志(共108, 972个样本)用于训练,150条日志(共23, 542个样本)用于验证,另外150条日志(共23, 542个样本)用于测试。作者关注与nuScenes数据集相同的地图元素类别。
评估指标。遵循先前方法,采用基于Chamfer距离的常用平均精度 (AP) 作为评估指标,其中只有当预测与真实值之间的距离小于阈值时,预测才被视为真实阳性 (TP)。由于现有方法使用不同的AP阈值进行评估,作者设置了两个不同的阈值集和,分别对应困难设置和简单设置。对于每种设置,最终AP结果通过在三个阈值和所有类别上取平均值来计算。
实现细节。以ego车辆为中心,局部地图的感知范围在ΔX轴上设置为[-15.0 m, 15.0 m],在Y轴上设置为[-60.0 m, 60.0 m]。作者将NuScenes数据集的图像大小设置为512×896,Argoverse2数据集的图像大小设置为384×512,并将两个数据集的LiDAR点云 Voxel 化为0.15 m。BEV特征的尺寸设置为100×25。元素类型(如车道分隔线、人行横道和道路边界)的最大数量M分别设置为{20, 25, 15},每种元素类型的建模关键点最大数量N分别设置为N={10, 2, 30}。所有实验均在配备4块Tesla V100-DGXS-32G GPU的机器上进行。在训练阶段,所有GPU均被使用,而在推理阶段仅使用单个GPU。NuScenes数据集使用AdamW优化器和指数调度器进行训练,学习率为0.0001,权重衰减为0.0001,训练30个epoch;Argoverse2数据集训练6个epoch。训练批次大小设置为4。
4.2. 与SOTA的比较
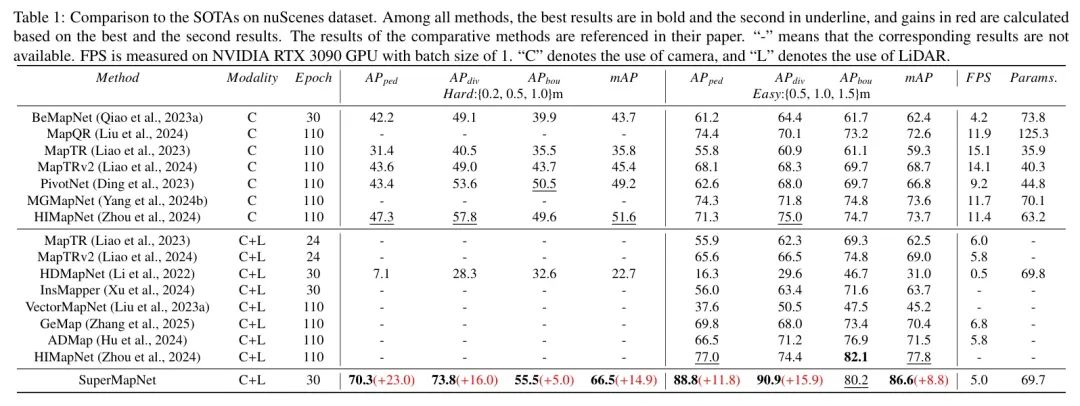
NuScenes数据集上的结果。表1展示了作者的SuperMapNet在nuScenes数据集上困难与简单设置下的性能,并与现有SOTA方法进行了比较。SuperMapNet在困难与简单设置下均达到了新的SOTA水平 (66.5/86.6 mAP),分别比现有SOTA方法提高了14.9/8.8 mAP。作者的SuperMapNet的训练轮次(30轮)远短于其他方法(110轮),并且生成的局部地图的感知范围(Y轴120米)远大于其他方法(Y轴60米),显示出SuperMapNet在提高构建精度和感知范围方面的显著优势。至于推理延迟,与单模态构建方法相比,SuperMapNet的FPS(每秒帧数)要低得多,因为SuperMapNet同时使用相机图像和LiDAR点云作为输入。但与其他多模态方法相比,FPS差异约为1帧,模型参数数量的差异并不显著,大约为70M。
Argoverse2数据集上的结果。表2展示了作者的SuperMapNet在Argoverse2(Wilson等人,2021)数据集上困难与简单设置下的性能,并与现有SOTA方法进行了比较。由于Argoverse2数据集的数据量大约是nuScenes数据集的四倍,大多数方法在Argoverse2数据集上仅训练6轮。很明显,即使在感知范围是其他方法两倍的情况下,作者的SuperMapNet在Argoverse2数据集上困难/简单设置下的性能仍然显著优于现有SOTA方法 (18.5/3.1 mAP)。然而,与nuScenes数据集相比,作者的SuperMapNet在精度上略有下降,困难设置下约2.2 mAP,简单设置下约4.2 mAP,特别是在行人过街区域 (-8.8/-7.0 mAP) 和车道分隔线 (-4.1/-11.0 mAP)。这是由于如图7所示,行人过街区域的分布和形状更为复杂,边界与分隔线之间以及分隔线之间存在重复标注,这对高精度地图构建带来了巨大挑战。尽管如此,与现有SOTA方法相比,作者的SuperMapNet在每个元素类型(道路边界、车道分隔线和行人过街区域)上均实现了最高精度。
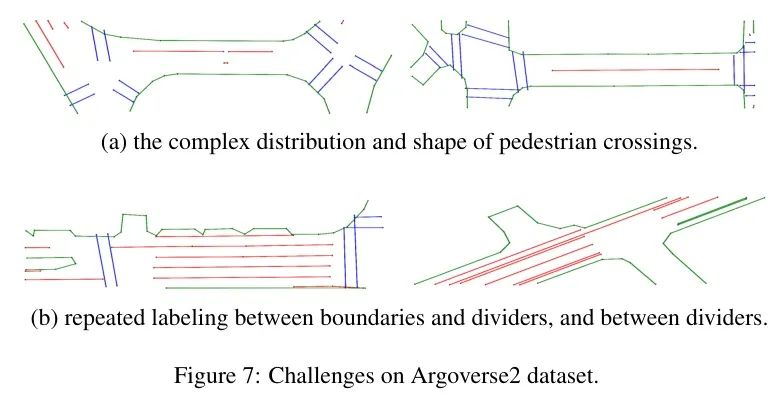
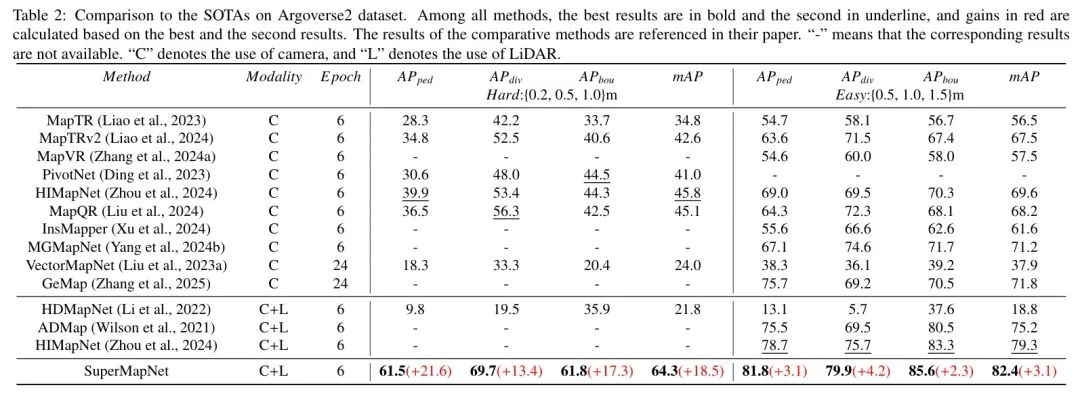
表:igheeadonhten available。FPS在NVIDIA RTX 3090 GPU上以批量大小1进行测量。*C表示使用相机,L"表示使用激光雷达。
5. 消融研究
5.1. 不同元素类型的准确性
不同类型元素形状的显著差异给在统一表示中对地图元素进行建模带来了挑战。表3列出了所提出的SGC模块和PEC模块如何影响不同元素类型的准确性。值得注意的是,即使不包含SGC或PEC模块,作者的多模态 Baseline 模型也已经在与现有SOTA模型的比较中实现了更高的准确性,其中HIMapNet(Zhou等人,2024年)在简单设置下达到了77.8 mAP的准确性,而作者的 Baseline 模型在相同场景中实现了79.7 mAP。

SGC模块:与 Baseline 直接拼接的策略相比,在拼接前添加SGC模块在硬/易设置下实现了4.9/3.2 mAP的更高提升,同时略微降低了FPS(减少0.2)并增加了3.2M的参数量。这是由于 (1) 基于交叉注意力的协同增强,用于语义信息与几何信息之间的信息交换,能够填补LiDAR BEV特征在距离上的特征空洞,并增强感知能力和范围;(2) 基于流的视差对齐,在拼接前减少不同传感器之间的坐标误差。
PEC模块:仅使用PEC模块在硬设置和易设置下均能显著提高精度 (+7.7/+6.7 mAP),特别是在道路边界和车道分隔线上,分别提升了8.9/7.2 mAP和7.4/7.4 mAP。这是因为行人过街通常仅由两个关键点建模,点信息有限,导致PEC模块中的Point2Point交互无效。相比之下,道路边界和车道分隔线由更多关键点建模,具有丰富的点信息,因此Point2Point交互对道路边界和车道分隔线更有效。然而,仅使用PEC模块时,FPS显著下降0.8,参数量增加10.4 M,因为添加了三级交互,即Point2Point、Element2Element和Point2Element。
SGC和PEC模块的组合:将SGC和PEC模块结合并不能完全放大它们的优势,尤其是在容易设置的情况下,添加SGC模块或不添加的效果差异不大(mAP从86.4变化到86.6)。然而,在困难设置下,仍然需要结合这两个模块,与仅使用PEC模块相比,它们可以分别提高人行横道、道路边界和车道分隔线的mAP 1.2、1.6和1.2。
5.2. 不同阈值的准确性
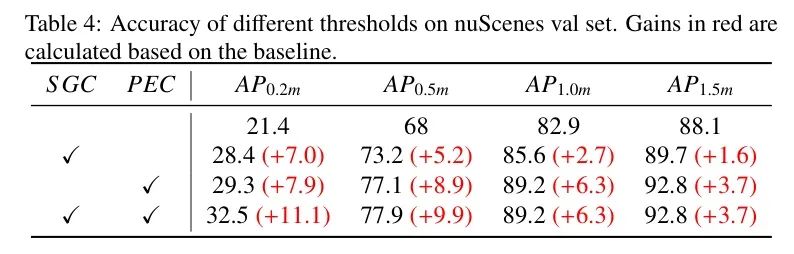
不同的AP阈值代表了性能评估中不同的容错率。考虑到自动驾驶系统在感知、预测和规划中的应用,高精度地图需要厘米级信息以确保安全性、可靠性和智能化。因此,在更严格的阈值下进行改进更具实用性和意义。表4显示使用SGC模块或PEC模块可以显著提高精度,特别是在0.5米和1.0米的阈值下,超过37 mAP,展现出其显著优势。此外,同时使用SGC模块和PEC模块始终在所有阈值上优于 Baseline,提升约20 mAP。通过叠加SGC模块和PEC模块,可以保留并传递它们的优势,实现SOTA性能。
5.3. 可视化
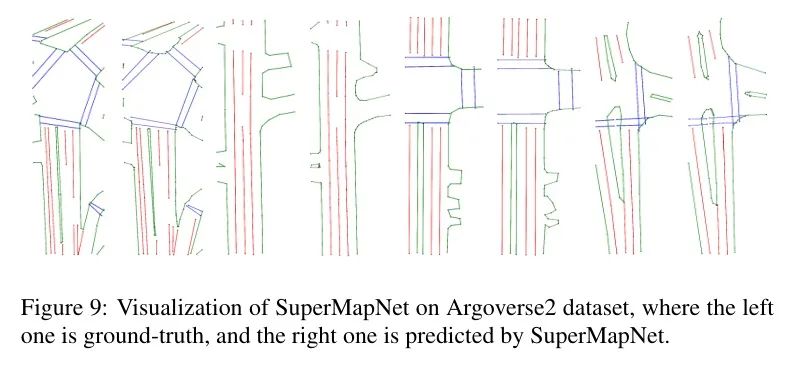
图8和图9分别展示了作者的SuperMapNet在nuScenes和Argoverse2数据集上的可视化结果。从图中可以看出,尽管Argoverse2数据集中的边界更加不规则,且边界之间有重复的 Token ,但作者的SuperMapNet仍然能够很好地检测和建模所有地图元素,并在大多数情况下有效处理错误元素形状或元素之间的缠绕。

6. 结论
SuperMapNet是一种为长距离和高精度矢量化高精度地图构建而设计的有效网络。它具有在考虑协同效应和差异性的同时,在语义信息和几何信息之间建立强大耦合的特点,同时在三个层次上实现点信息与要素信息的耦合,即点对点 (Point2Point)、要素对要素 (Element2Element) 和点对要素 (Point2Element)。
大量实验已证明SuperMapNet的显著潜力,在NuScenes和Argoverse2数据集上均取得了新的SOTA (State-of-the-Art) 成果。作者相信SuperMapNet为未来矢量化高精度地图构建任务的研究提供了新的视角。

















 4177
4177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









