









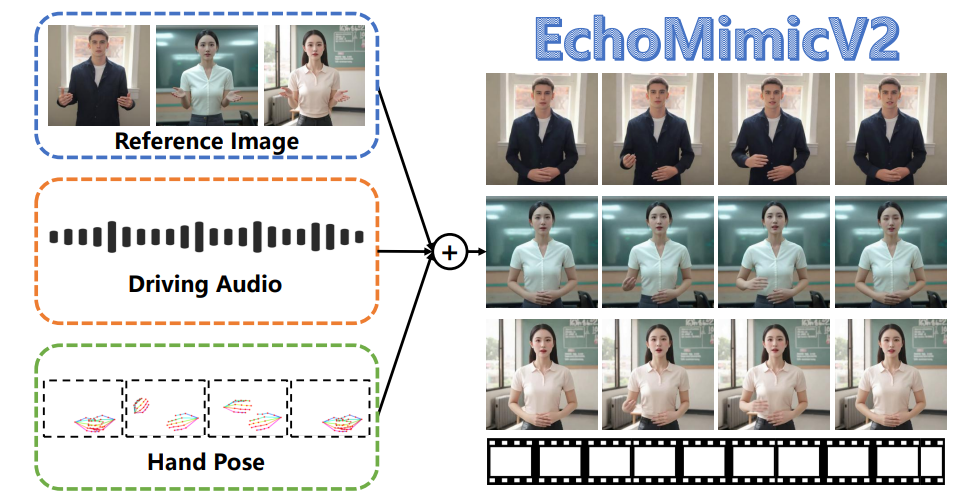
在之前的文章中已经给大家介绍过蚂蚁集团的开源数字人项目EchoMimic,现在EchoMimic升级到V2版本了,V1仅是用图片和音频生成数字脸,V2就是真正的数字人了。一张半身照片,配上中文或英语音频,就能生成带手势的数字人视频。
EchoMimicV2利用参考图像、音频片段和一系列手部姿势来生成高质量的动画视频,确保音频内容和半身动作之间的连贯性。
视频展示:
相关链接
-
论文:https://arxiv.org/pdf/2411.10061
-
代码:https://github.com/antgroup/echomimic_v2
-
模型:https://huggingface.co/BadToBest/EchoMimicV2
-
主页:https://antgroup.github.io/ai/echomimic_v2
论文介绍

近期关于人体动画的研究通常涉及音频、姿势或运动图条件,从而实现逼真的动画质量。然而,这些方法往往面临实际挑战,因为额外的控制条件、繁琐的条件注入模块或头部区域驱动的限制。因此,是否有可能在简化不必要条件的同时实现引人注目的半身人体动画。
为此,论文提出了一种半身人体动画方法称为EchoMimicV2,该方法利用一种新颖的音频姿势动态协调策略,包括姿势采样和音频扩散,来增强半身细节、面部和手势表现力,同时减少条件冗余。
方法
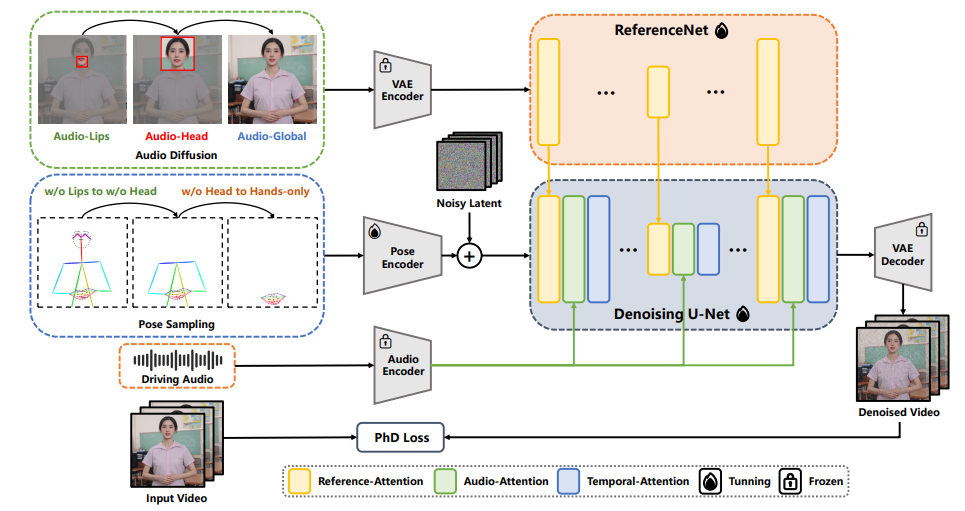
EchoMimicV2 的整体流程。 EchoMimicV2 利用参考图像、音频片段和一系列手势来生成高质量的动画视频,确保音频内容和半身动作之间的连贯性。 为了弥补半身数据的稀缺,利用头部部分注意力将头像数据无缝地容纳到训练框架中,这些数据可以在推理过程中被省略。此外,还设计了阶段特定的去噪损失,分别来指导特定阶段动画的运动、细节和低级质量。此外还提出了一个用于评估半身人体动画效果的新基准。大量实验和分析表明,EchoMimicV2 在定量和定性评估方面均超越了现有方法。
效果展示

EchoMimicV2 在给定不同参考图像、手势和音频的情况下的结果。

EchoMimicV2 的结果与姿势驱动的半身人体动画基线进行了比较。

EchoMimicV2 的结果与音频驱动的半身人体动画基线进行了比较。
结论
论文提出了一种有效的 EchoMimicV2 框架来简化的条件下生成引人注目的半身人体动画。通过提出的 APDH 训练策略和时间步长特定的 PhD Loss 实现了音频姿势条件协作和姿势条件简化,同时通过 HPA 无缝增强了面部表情。综合实验表明,EchoMimicV2 在定量和定性结果方面都超过了目前最先进的技术。



















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











