






1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义
随着城市化进程的加速和交通工具的普及,城市道路上的交通流量不断增加,给城市交通管理和交通安全带来了巨大的挑战。为了提高交通管理的效率和交通安全的水平,研究者们一直在寻找有效的方法来对城市场景中的路面交通车辆和行人进行准确的识别和分割。
传统的图像分割方法主要基于手工设计的特征和规则,但是这些方法在复杂的城市场景中往往难以达到较高的准确性和鲁棒性。而深度学习作为一种基于数据驱动的方法,具有自动学习特征和模式的能力,已经在图像分割领域取得了巨大的成功。因此,基于深度学习的城市场景路面交通车辆行人障碍物图像分割系统成为了当前研究的热点和重要方向。
首先,基于深度学习的图像分割方法可以提高交通管理的效率。通过准确地分割出图像中的车辆和行人,交通管理人员可以更加精确地监控和控制交通流量,及时发现和解决交通拥堵和事故等问题。同时,基于深度学习的图像分割方法还可以为交通管理决策提供更加准确的数据支持,帮助交通管理部门制定更加科学和有效的交通管理策略。
其次,基于深度学习的图像分割方法可以提高交通安全的水平。准确地分割出图像中的车辆和行人,可以帮助驾驶员更好地感知周围的交通环境,减少交通事故的发生。此外,基于深度学习的图像分割方法还可以用于智能交通系统中的自动驾驶技术,通过对车辆和行人的准确识别和分割,提高自动驾驶系统的安全性和可靠性。
此外,基于深度学习的图像分割方法还可以应用于城市规划和建设中。通过准确地分割出图像中的车辆和行人,可以帮助城市规划者更好地了解城市交通流量和人口分布情况,为城市交通规划和交通设施建设提供科学依据。同时,基于深度学习的图像分割方法还可以用于城市环境监测和污染控制,通过准确地分割出图像中的车辆和行人,可以帮助城市管理者及时发现和解决环境污染问题。
综上所述,基于深度学习的城市场景路面交通车辆行人障碍物图像分割系统具有重要的研究意义和应用价值。通过准确地分割出图像中的车辆和行人,可以提高交通管理的效率和交通安全的水平,为交通管理决策和智能交通系统提供准确的数据支持。同时,基于深度学习的图像分割方法还可以应用于城市规划和建设中,为城市交通规划和环境监测提供科学依据。因此,深入研究基于深度学习的城市场景路面交通车辆行人障碍物图像分割系统具有重要的理论和实践意义。
2.图片演示



3.视频演示
基于深度学习的城市场景路面交通车辆行人障碍物图像分割系统_哔哩哔哩_bilibili
4.城市场景分割网络
UNet和 Deeplab网络都是在FCN 的基础上发展而来,他们作为语义分割的代表网络,在不同的研究领域都有举足轻重的地位,研究者通过改良其结构同样获得了更好的路面分割效果。本文主要研究特征自干扰机制与注意力机制方法,因此本章对主流的路面分割网络进行介绍,并分析其结构特点,最后通过实验数据分析他们存在的不足。
UNet
UNet的编解码结构考虑到特征提取过程中浅层特征和深层特征对分割均有帮助,根据实验分析设计了四层的编码器结构,并将每次下采样的特征以拼接的方式结合到解码器的上采样层当中,从而使解码器能从更厚的特征提取到更丰富的信息。由于UNet 的编解码结构上是对称,像一个深U型,所以又叫U型网络。四个采样层的链接成为跳跃连接(skip-connection),网络结构如图所示:
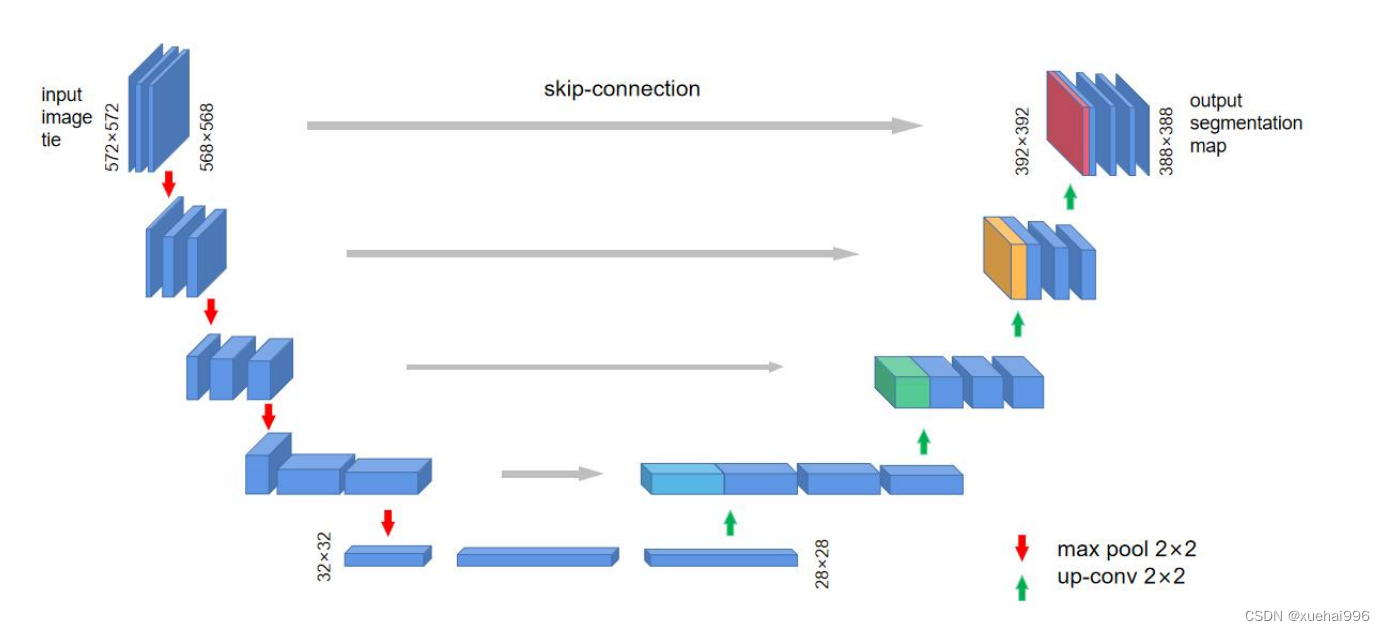
网络是一个经典的全卷积网络,网络的输入是一张经过overlap-tile策略的572×572的图像,在网络的左侧是由卷积和最大池化构成的一系列降采样操作,论文中将这一部分叫做压缩路径。压缩路径由4个模块组成,每个模块使用了3个有效卷积和1个最大池化降采样,每次降采样之后特征图的个数乘2,因此有了图中所示的特征图尺寸变化。最终得到了尺寸为32×32的特征图。网络的右侧部分在论文中叫做扩展路径。同样由4个block组成,每个block 开始之前通过反卷积将特征图的尺寸乘2,同时将其个数减半,然后和左侧对称的压缩路径的特征图,由于左侧压缩路径和右侧扩展路径的特征图的尺寸不一样,U-Net是通过将压缩路径的特征图裁剪到和扩展路径相同尺寸的特征图进行归一化的。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的特征图的尺寸是338×338。由于UNet任务是处理医学分割的二分类任务,所以网络有两个输出特征图。
UNet网络有以下突出的优点:输入图像采用overlap-tile策略,当对图像的某一块像素点进行预测时,需要该图像块周围的像素点提供上下文信息,这样以获得更准确的预测。而对边缘缺失的部分,采用镜像补全。网络结构呈“U”型,结构中最有特色的结构就是特征的拼接部分,用叠加的方式取代FCN中的求和方式,在上采样过程中保留了大量的特征通道,可以传递更完整的特征信息,有效提高分割的精确度。采用弹性形变的数据增强方式,使得该网络在数据集较小的任务中也能有良好的表现。
但是UNet 也有其不足,从表可以看出,UNet在训练精度上相比FCN有明显的提高,在图像上相比FCN细节部分也更加丰富,但是对分割物体的完整度呈现还比较欠缺,如图所示的车辆基本轮廓不能很好的分割出来,图中的行人区域分割不够完整,路面远处的行人未能完全识别出来,因此分割网络还需要进一步完善。
5.核心代码讲解
5.1 BaseNetwork.py
根据给定的代码,我将封装为一个名为BaseNetwork的类,代码如下:
class BaseNetwork(nn.Module):
def __init__(self):
super(BaseNetwork, self).__init__()
self.layers = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.layers(x)
这个类继承自nn.Module,并在构造函数__init__中定义了一个包含三个卷积层和ReLU激活函数的序列模块self.layers。在前向传播函数forward中,输入x通过self.layers进行处理并返回结果。
这个程序文件名为BaseNetwork.py,它定义了一个名为BaseNetwork的类,继承自nn.Module类。这个类包含了一个神经网络模型,用于图像处理任务。
在初始化方法中,定义了一个包含多个卷积层的神经网络模型。这个模型的输入通道数为3,输出通道数为256。具体的网络结构为:
- 第一层:输入通道数为3,输出通道数为64,卷积核大小为3x3,步长为1,填充为1,激活函数为ReLU。
- 第二层:输入通道数为64,输出通道数为128,卷积核大小为3x3,步长为1,填充为1,激活函数为ReLU。
- 第三层:输入通道数为128,输出通道数为256,卷积核大小为3x3,步长为1,填充为1,激活函数为ReLU。
在前向传播方法中,将输入数据x传入神经网络模型中,通过self.layers(x)进行处理,并返回处理后的结果。
这个程序文件定义了一个基础的神经网络模型,可以用于图像处理任务中。
5.2 dice_loss.py
def make_one_hot(vol, mask):
'''
:param vol: the segmentation map,[N, 1, :, :, :],N: batch size
:param mask: can be a python list including all kinds of pixel values of your segmentation map; e.g. mask=[1,2,3]
:return: [N, len(mask), :, :, :]
'''
lens = len(mask)
shape = np.array(vol.shape)
shape[1] = lens
shape = tuple(shape)
result = torch.zeros(shape)
for idx, label in enumerate(mask):
tmp = vol == label
result[:,idx] = tmp
return result
class dice_loss(nn.Module):
'''
vol1,vol2: need to make one hot first
'''
def __init__(self, epsilon=1e-5):
super(dice_loss, self).__init__()
self.epsilon = epsilon
def forward(self, vol1, vol2):
vol2=make_one_hot(vol1,vol2)
shape = vol1.shape
total_loss = 0
for i in range(shape[1]):
top = 2 * torch.sum(torch.mul(vol1[:,i], vol2[:,i]), dtype=float)
bottom = torch.sum(vol1[:,i], dtype=float) + torch.sum(vol2[:,i], dtype=float)
bottom = torch.max(bottom, (torch.ones_like(bottom, dtype=float) * self.epsilon)) # add epsilon.
loss_tmp = -1 * (top / bottom)
total_loss += loss_tmp
return total_loss / shape[1]
class DiceLoss(nn.Module):
def __init__(self):
super(DiceLoss, self).__init__()
self.epsilon = 1e-5
def forward(self, predict, target):
assert predict.size() == target.size(), "the size of predict and target must be equal."
num = predict.size(0)
pre = torch.sigmoid(predict).view(num, -1)
tar = target.view(num, -1)
intersection = (pre * tar).sum(-1).sum() #利用预测值与标签相乘当作交集
union = (pre + tar).sum(-1).sum()
score = 1 - 2 * (intersection + self.epsilon) / (union + self.epsilon)
return score
这个程序文件是一个用于计算Dice Loss的模块。Dice Loss是一种常用的用于图像分割任务的损失函数。该文件定义了三个类和一个函数。
-
make_one_hot函数用于将输入的分割图像转换为one-hot编码的形式。它接受两个参数,vol表示分割图像,mask表示分割图像中的像素值列表。函数返回一个形状为[N, len(mask), :, :, :]的张量,其中N表示批次大小,len(mask)表示像素值的种类数。 -
dice_loss类是一个继承自nn.Module的模块,用于计算Dice Loss。它接受两个参数vol1和vol2,需要先将它们转换为one-hot编码的形式。在前向传播过程中,它遍历每个像素值的种类,计算Dice Loss,并返回平均值。 -
dice_loss_binary函数是一个简化版的Dice Loss计算函数,用于二分类任务。它接受两个参数vol1和vol2,直接计算Dice Loss并返回结果。 -
DiceLoss类是一个继承自nn.Module的模块,用于计算Dice Loss。它接受两个参数predict和target,其中predict表示模型的预测结果,target表示真实的标签。在前向传播过程中,它首先将predict通过sigmoid函数转换为概率值,然后计算交集和并集,最后计算Dice Loss并返回结果。
5.3 dice_loss2.py
def get_one_hot(label, N):
size = list(label.size())
label = label.view(-1) # reshape 为向量
ones = torch.sparse.torch.eye(N).to("cuda")
ones = ones.index_select(0, label) # 用上面的办法转为换one hot
size.append(N) # 把类别输目添到size的尾后,准备reshape回原来的尺寸
return ones.view(*size)
class DiceLoss(nn.Module):
def __init__(self):
super(DiceLoss, self).__init__()
def forward(self, input, target):
N= target.size(0)
smooth = 1
input_flat = torch.sigmoid(input).view(N, -1)
target_flat = target.view(N, -1)
intersection = input_flat * target_flat
loss = 2 * (intersection.sum(1) + smooth) / (input_flat.sum(1) + target_flat.sum(1) + smooth)
loss = 1 - loss.sum() / N
return loss
class MulticlassDiceLoss(nn.Module):
def __init__(self,classes):
super(MulticlassDiceLoss, self).__init__()
self.classes=classes
def forward(self, input, target, weights=None):
C = self.classes
target = get_one_hot(target, self.classes)
target=target.permute(0,3,1,2)
dice = DiceLoss()
totalLoss = 0
for i in range(C):
diceLoss = dice(input[:, i, :, :], target[:, i,:, :])
if weights is not None:
diceLoss *= weights[i]
totalLoss += diceLoss
return totalLoss/(float)(self.classes)
这个程序文件名为dice_loss2.py,它实现了Dice Loss和多类别Dice Loss的计算。Dice Loss是一种用于图像分割任务的损失函数,用于衡量预测结果与真实标签的相似度。多类别Dice Loss在每个类别上分别计算Dice Loss,并将所有类别的损失相加。程序中还包含了一个函数get_one_hot,用于将标签转换为one-hot编码。在程序的主函数中,演示了如何使用get_one_hot函数将随机生成的标签转换为one-hot编码,并计算多类别Dice Loss。
5.4 FeatureSelfDisturbance.py
class FeatureSelfDisturbance(nn.Module):
def __init__(self):
super(FeatureSelfDisturbance, self).__init__()
self.pseudo_feature_generator = nn.Conv2d(3, 256, kernel_size=1, stride=1)
self.disturbance_generator = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
)
def forward(self, x):
pseudo_feature = self.pseudo_feature_generator(x)
disturbed_feature = self.disturbance_generator(pseudo_feature)
return disturbed_feature
这个程序文件名为FeatureSelfDisturbance.py,它定义了一个名为FeatureSelfDisturbance的类,继承自nn.Module。这个类包含了两个层:pseudo_feature_generator和disturbance_generator。
pseudo_feature_generator是一个卷积层,输入通道数为3,输出通道数为256,卷积核大小为1x1,步长为1。
disturbance_generator是一个序列模块,包含了两个卷积层和一个ReLU激活函数。第一个卷积层的输入通道数为256,输出通道数为256,卷积核大小为3x3,步长为1,填充为1。ReLU激活函数在原地执行。第二个卷积层的输入通道数为256,输出通道数为256,卷积核大小为3x3,步长为1,填充为1。
forward方法接受一个输入x,首先通过pseudo_feature_generator生成伪特征图pseudo_feature,然后将pseudo_feature作为输入传递给disturbance_generator生成干扰特征disturbed_feature,并将其返回。
5.5 loss.py
def make_one_hot(input, num_classes):
shape = np.array(input.shape)
shape[1] = num_classes
shape = tuple(shape)
result = torch.zeros(shape)
result = result.scatter_(1, input.cpu(), 1)
return result
class MulticlassDiceLoss(nn.Module):
def __init__(self):
super(MulticlassDiceLoss, self).__init__()
def forward(self, input, target, weights=None):
input=torch.LongTensor(input.cpu().detach().numpy())
target=torch.LongTensor(target.cpu().detach().numpy())
make_one_hot(target,4)
C = target.shape[1]
dice = DiceLoss()
totalLoss = 0
for i in range(C):
diceLoss = dice(input[:,i], target[:,i])
totalLoss += diceLoss
return totalLoss
5.5 matplot.py
class Plotter:
def __init__(self, x_label, y_label):
self.x_label = x_label
self.y_label = y_label
def plot_curve(self, x_trains, y_trains, x_vals, y_vals, lr_trains, train_lr):
plt.figure(figsize=(12, 10), dpi=80)
plt.xlabel(self.x_label)
plt.ylabel(self.y_label)
plt.scatter(x_trains, y_trains, marker='.')
plt.plot(x_trains, y_trains, label="train_loss")
plt.scatter(x_vals, y_vals, marker='.')
plt.plot(x_vals, y_vals, label="val_loss")
plt.scatter(lr_trains, train_lr, marker='*')
plt.plot(lr_trains, train_lr, label="lr")
plt.title('resnet34 loss')
plt.legend(loc='upper right')
plt.savefig('./data/wangzhenlin/road/plot.png', format='png')
def plot_loss_curve(self, x_trains, y_trains, x_vals, y_vals):
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title('Model Metrics')
ax1.set_ylabel(self.y_label)
ax1.set_xlabel(self.x_label)
plt.scatter(x_trains, y_trains, marker='.')
plt.plot(x_trains, y_trains, label="train_loss")
plt.scatter(x_vals, y_vals, marker='.')
plt.plot(x_vals, y_vals, label="val_loss")
plt.title('train loss')
plt.legend(loc='upper right')
plt.savefig('./data/wangzhenlin/road/road_unet1.png', format='png')
def plot_lr_curve(self, lr_trains, train_lr):
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.set_title('Model LR')
ax1.set_ylabel(self.y_label)
ax1.set_xlabel(self.x_label)
plt.scatter(lr_trains, train_lr, marker='*')
plt.plot(lr_trains, train_lr, label="lr")
plt.title("lr")
plt.legend(loc='upper right')
plt.savefig('./data/wangzhenlin/road/road_unet2.png', format='png')
这个程序文件名为matplot.py,主要是使用matplotlib库绘制曲线图。其中定义了三个函数:plotCurve、plotLossCurve和plotlrCurve。
plotCurve函数用于绘制曲线图,接受多个参数,包括训练集和验证集的x和y值,x和y轴的标签,以及学习率的训练集和验证集。函数内部通过调用matplotlib的scatter和plot函数来绘制散点图和曲线图,并设置图的标题和图例,最后将图保存为png格式的文件。
plotLossCurve函数用于绘制损失曲线图,接受多个参数,包括训练集和验证集的x和y值,x和y轴的标签。函数内部通过调用matplotlib的scatter和plot函数来绘制散点图和曲线图,并设置图的标题和图例,最后将图保存为png格式的文件。
plotlrCurve函数用于绘制学习率曲线图,接受多个参数,包括x和y轴的标签,以及学习率的训练集。函数内部通过调用matplotlib的scatter和plot函数来绘制散点图和曲线图,并设置图的标题和图例,最后将图保存为png格式的文件。
5.6 PixelAttentionMechanism.py
class PixelAttentionMechanism(nn.Module):
def __init__(self):
super(PixelAttentionMechanism, self).__init__()
self.attention_layer = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 1, kernel_size=1, stride=1),
nn.Sigmoid()
)
def forward(self, feature):
attention_map = self.attention_layer(feature)
return feature * attention_map
这个程序文件名为PixelAttentionMechanism.py,它定义了一个名为PixelAttentionMechanism的类,继承自nn.Module。这个类实现了一个像素注意力机制。
在类的初始化方法中,定义了一个名为attention_layer的序列模型。这个序列模型包含了两个卷积层和两个激活函数层。第一个卷积层使用了256个输入通道和256个输出通道,卷积核大小为3x3,步长为1,填充为1。激活函数层使用了ReLU函数。第二个卷积层使用了256个输入通道和1个输出通道,卷积核大小为1x1,步长为1。最后一个激活函数层使用了Sigmoid函数。
在类的前向传播方法中,通过attention_layer对输入的feature进行处理,得到一个注意力图attention_map。然后将feature与attention_map相乘,得到最终的输出。
总结来说,这个程序文件定义了一个像素注意力机制模型,通过卷积层和激活函数层对输入进行处理,得到一个注意力图,然后将输入与注意力图相乘得到输出。
6.系统整体结构
整体功能和构架概括:
该城市场景路面交通车辆行人障碍物图像分割系统基于深度学习技术,旨在对城市场景中的图像进行分割,将不同的物体类别(如车辆、行人、障碍物等)从图像中分离出来。系统的整体构架包括了多个功能模块,如基础网络模型、损失函数、特征融合模块、特征自扰动模块、注意力机制模块等。
下表整理了每个文件的功能:
| 文件名 | 功能 |
|---|---|
| BaseNetwork.py | 定义了基础的神经网络模型 |
| dice_loss.py | 计算二分类任务的Dice Loss |
| dice_loss2.py | 计算多类别Dice Loss |
| FeatureFusionModule.py | 定义了特征融合模块,用于将不同尺度的特征进行融合 |
| FeatureSelfDisturbance.py | 定义了特征自扰动模块,用于生成干扰特征 |
| loss.py | 定义了其他损失函数,如交叉熵损失等 |
| matplot.py | 绘制损失曲线图和学习率曲线图的工具函数 |
| PixelAttentionMechanism.py | 定义了像素注意力机制模块,用于生成注意力图 |
| predict.py | 对输入图像进行预测,生成分割结果 |
| train_visionTrain.py | 训练模型的主程序 |
| ui.py | 用户界面程序,用于交互式操作 |
| val.py | 验证模型的性能 |
| model\resunet.py | 定义了ResUNet模型,用于图像分割任务 |
| model\unet_model.py | 定义了UNet模型,用于图像分割任务 |
| model\unet_parts.py | 定义了UNet模型的组成部分,如编码器、解码器等 |
| utils\aug.py | 定义了数据增强的函数,用于增加训练数据的多样性 |
| utils\dataset.py | 定义了数据集类,用于加载和处理训练和验证数据集 |
| utils_init_.py | 初始化工具函数 |
7.基于特征自干扰机制的道路分割网络
概述
在道路分割网络任务中,主流网络在提取图片特征过程中易受其他目标干扰导致特征鲁棒性降低,使得分割的结果出现噪点和不连续图像,而现有的基于噪声抗干扰机制有着伪特征与真实特征相似度不高这一劣势;针对上述问题提出了基于图像特征自干扰的道路分割网络:该网络分为主干分割网络和特征自干扰网络两部分,干扰网络输入原始图像随机裁剪和插值放大后得到的局部图生成伪特征,此外提出了融合模块用于实现伪特征与真实特征的融合并对主分割网络中间特征进行干扰。
针对以上问题,本文提出基于自干扰机制的道路分割网络,该方法的创新点如下:
1、提出了一种图像特征自干扰机制,在现有主分割网络的基础上增加特征自干扰网络,通过特征融合模块将干扰信息与原始信息结合,主分割网络需要克服干扰准确分割目标以此获得抗干扰能力提升模型的鲁棒性。
2、在主分割网络输出与自干扰网络输出之间设计了特征融合模块,用于实现伪特征对真实特征的自干扰。
3、本文考虑了数据集的大小对归一化效果的影响,采用组归一化(GN)和批归一化(BN)的结合使用方式,在大尺寸输入小批次训练中主网络与辅助网络分别采用组归一化和批归一化,避免了训练批次减小对网络精度的影响。
网络结构
图像特征自干扰网络(ISN)整体结构由两部分组成:主分割网络和特征自干扰网络。特征融合模块位于主分割网络与特征自干扰网络下采样结束层后,为主干特征添加干扰信息,网络的整体结构如图所示:
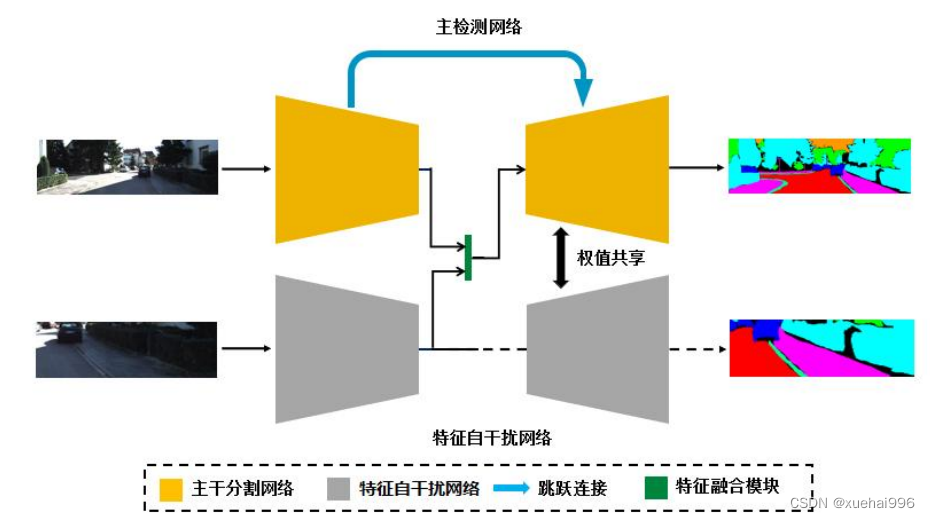
ISN结构由两部分组成:主分割网络和特征自干扰网络。主分割网络为编胖码绐构,细码器由ResNet残差块构成以负责提取道路的空间特征信息,主干网络的解码器由FCRN[8]
快速上采样残差模块(Fast Up-Project)和 ResNet残差块组成;其中快速上采样残差块由多个小尺寸的卷积核来代替大尺寸卷积核,提升感受野的同时也减少」参效里,缓胖」出人仓N对分割结果带来的颗粒感;特征自干扰网络为编码结构,负责生成伪特征以影响主分割网络的特征组成,为缩减模型参数,在训练过程中自干扰网络与主分割网络共用同一个解码器。
在训练中原始道路图像被输入到主分割网络编码器甲得到具头符征,与此问的,你阳图像被随机裁剪和双线性插值放大后得到道路的局部信息图经过特征自干扰网络的提取得到干扰特征。真实特征与干扰特征共同送入到特征融合模块,融合后的特征经过主干网络解码器的特征提取和筛选得到最后的分割结果。由于引入特征干扰信息,增加了模型的复杂度及不兼容性导致网络变得难以收敛,因此我们在编码器与解码器之间仿照 U-Net建立了跳跃连接以增强底层特征信息与深层特征信息的交互,并为梯度的反向传播提供新的方向。图上的虚线表示该流程仅在训练中使用。
8.特征融合模块结构
由于主分割网络编码器提取的特征与特征自干扰网络输出的干扰特征在空间位置上的关联较小,特征兼容性差,直接拼接会导致网络训练困难,难以收敛。为更合理的将干扰特征嵌入网络中,我们设计了四种特征融合模块(FFM),结构如下图所示:
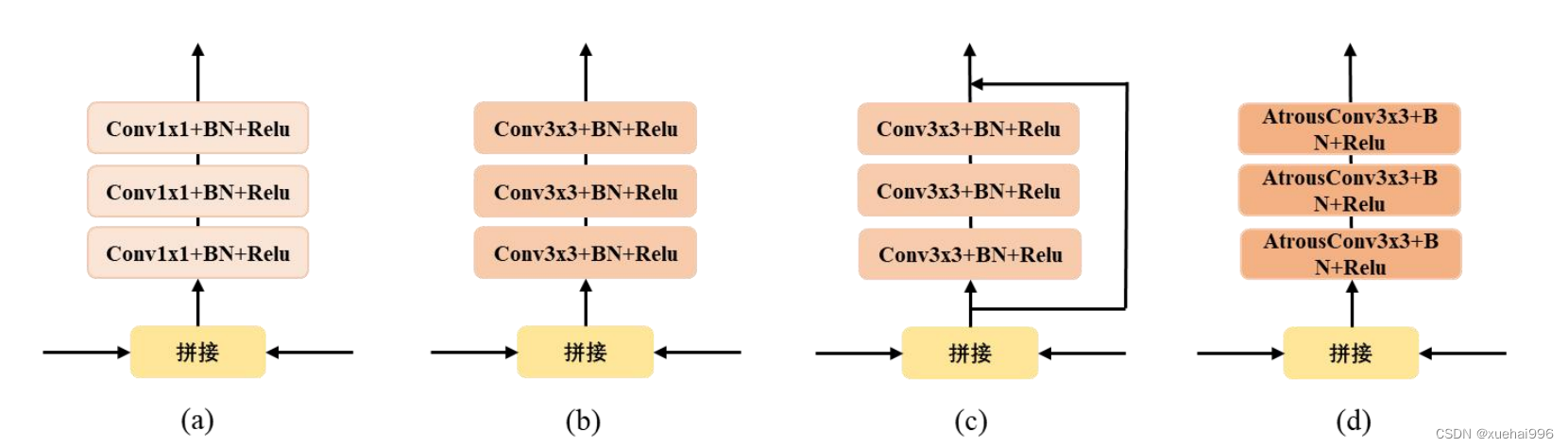
图a融合模块中采用11大小的卷积核进行通道的压缩;图b融合模块中采用33大小的卷积核进行通道的压缩以及区域内的特征关联;图c融合模块在图b的基础上仿照残差结构建立了一个通路;图d融合模块采用3*3大小的空洞卷积实现通道的压缩以及更大区域感受野内的特征关联。经试验结果表明图b结构具有更好的效果,得到更高的精度。
算法流程
在实现高精度道路场景语义分割任务中,本文提出一种基于图像特征自干扰机制的道路检测网络(ISN),首先将图像输入主分割网络编码器中得到原始特征信息;其次将该图像随机裁剪及插值放大后送入经过预训练的特征自干扰网络中得到自干扰特征信息;最后将全局信息和干扰信息进行融合并输入主分割网络的解码器中输出最终分割结果。
9.训练结果可视化分析
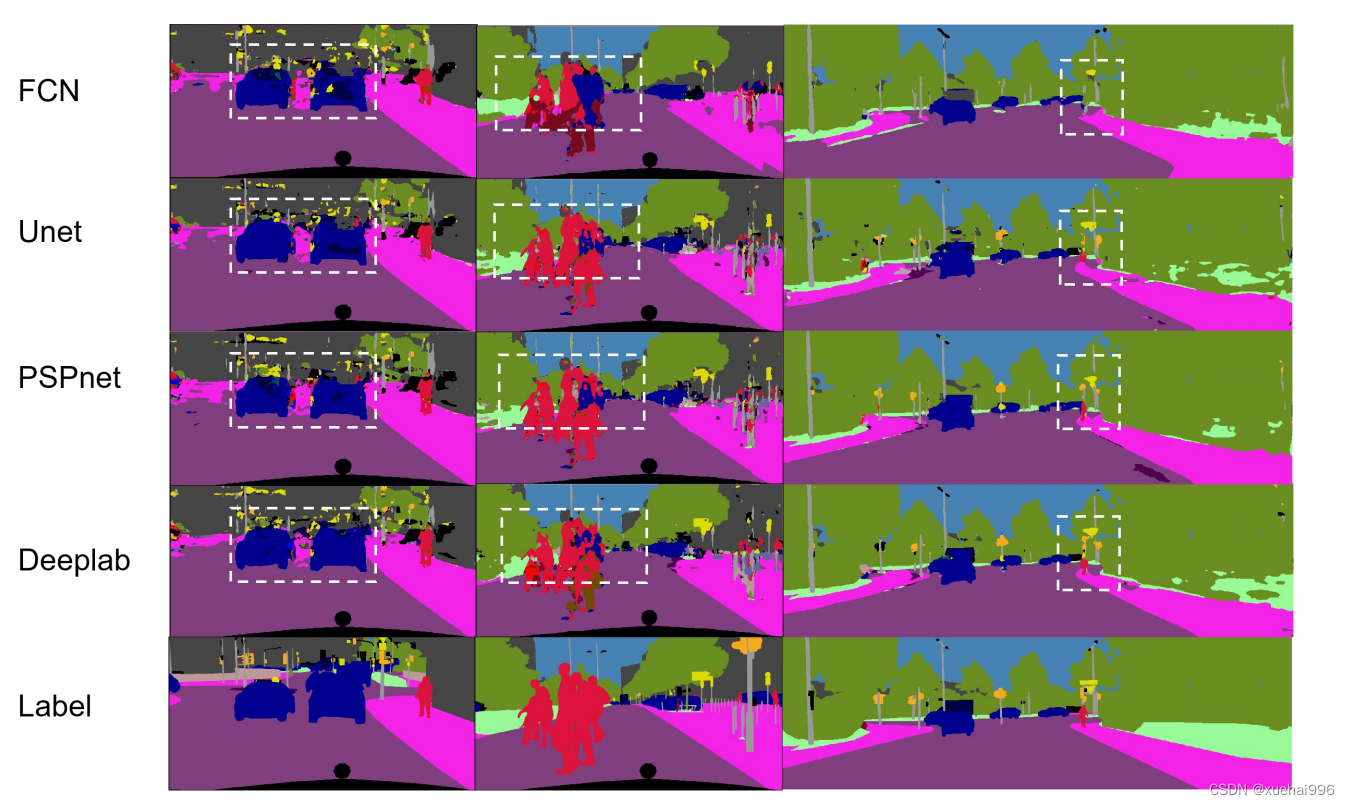
分别采用FCN、DeepLab V3、PSPNet、FCRN、ISN网络结构在两个数据库上进行对比实验,网络检测结果如下图所示:
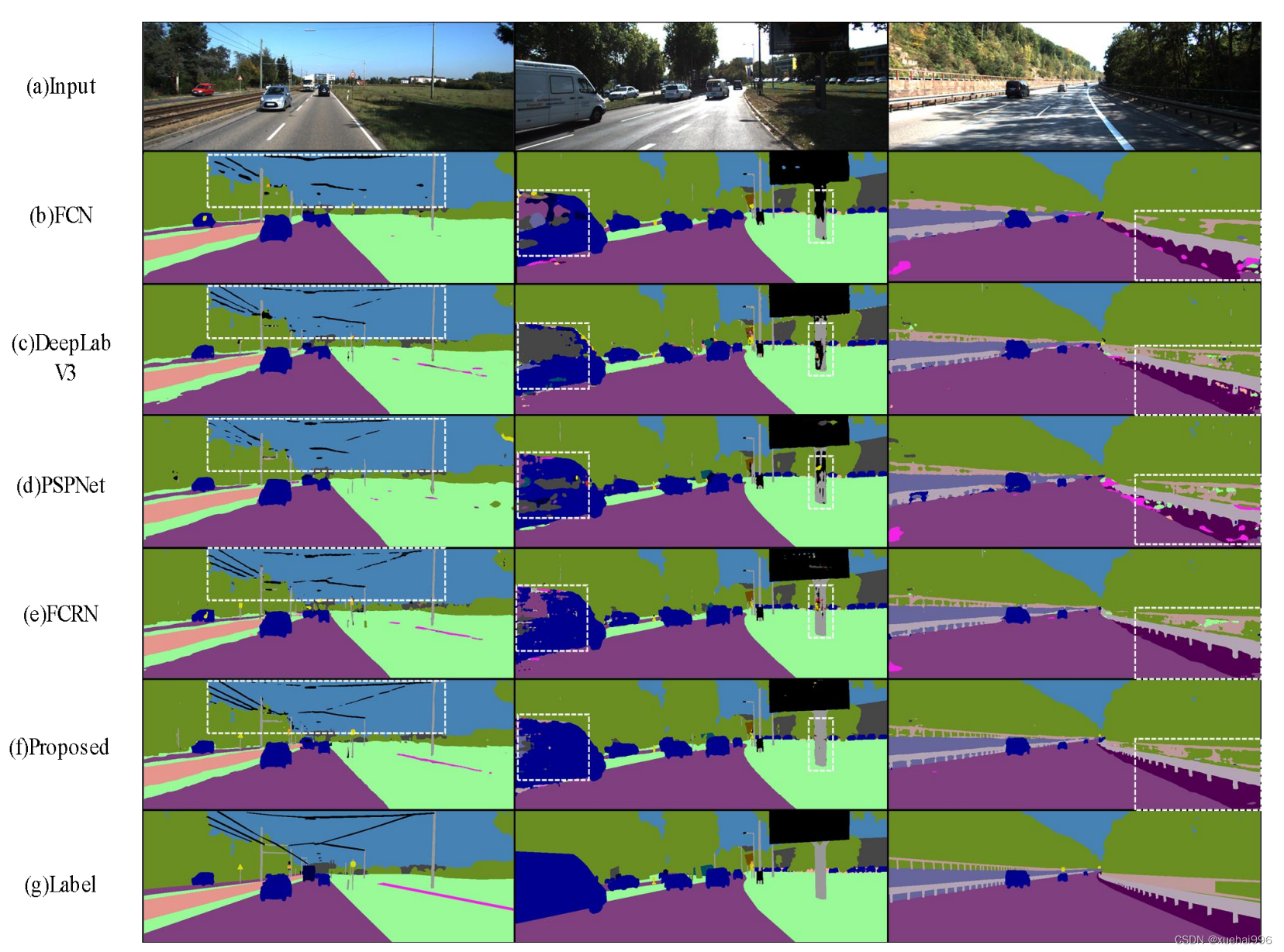
图中,(a)Input表示网络输入;(b)FCN表示FCN网络分割结果;©DeepLab V3表示DeepLab V3网络分割结果;(d)PSPNet表示PSPNet网络分割结果;(e)FCRN表示FCRN网络分割结果;(f) Proposed表示ISN分割结果;(g)Label表示输入标签。
由图的对比实验中可知,FCN作为分割网络的先驱,已较为精准的分割出道路场景中大部分类别,但出现了边缘不平滑和孔洞的现象;DeepLab V3和PSPNet通过引入空间金字塔池化模块,增大了网络对特征的感受野丰富了特征信息,因此分割结果相对平滑,但仍出现了许多误检;FCRN虽然改善了边缘且抑制了空洞的形成,但对小目标分割不精准。如图3-3第二列中右侧和图第二列白色虚线框所示,虽然主流的分割网络可以很好的提取到广告牌柱、行人和建筑物的整体信息,但是这些目标的内部细节被忽视,产生了误检情况。我们通过加入特征自干扰网络来引入干扰信息,主分割网络学习克服这些干扰的方法有效改善了分割图中误检现象。如第一,三列和图六的第一列白色虚线框所示:主流网络的分割结果在空中的电线,路边的护栏和人行道出现了断点和孔洞的现象;我们的方法通过引入像素注意力模块充分关联空间上下文信息,并通过跳跃链接融合底层与高层特征丰富了特征多样性,有效的抑制了断点和孔洞的产生。由实验结果图可知,本文通过加入特征自干扰网络后,与主流的分割方法相比在KITTI和Cityscapes数据集上具有更优秀的分割结果。
道路场景分割精度对比
为验证本文特征自干扰网络中输入的裁剪方式及裁剪倍数、特征融合模块结构对道路场景分割精度的影响,分别对以上两部分进行对比实验以此选出 ISN网络中。特征自干扰网络最合适的裁剪方式与倍数、特征融合模块结构,达到网络在道路场景中分割精度的最大化的效果。
为验证ISN网络中提出特征自干扰网络中输入的裁剪方式及裁剪倍数对道路场景分割精度的影响,分别采取中心裁剪与随机裁剪两种方式中裁剪倍数为原图的0.75、0.5、0.25倍进行对比试验,表列出了不同裁剪方式与倍数对比实验结果:
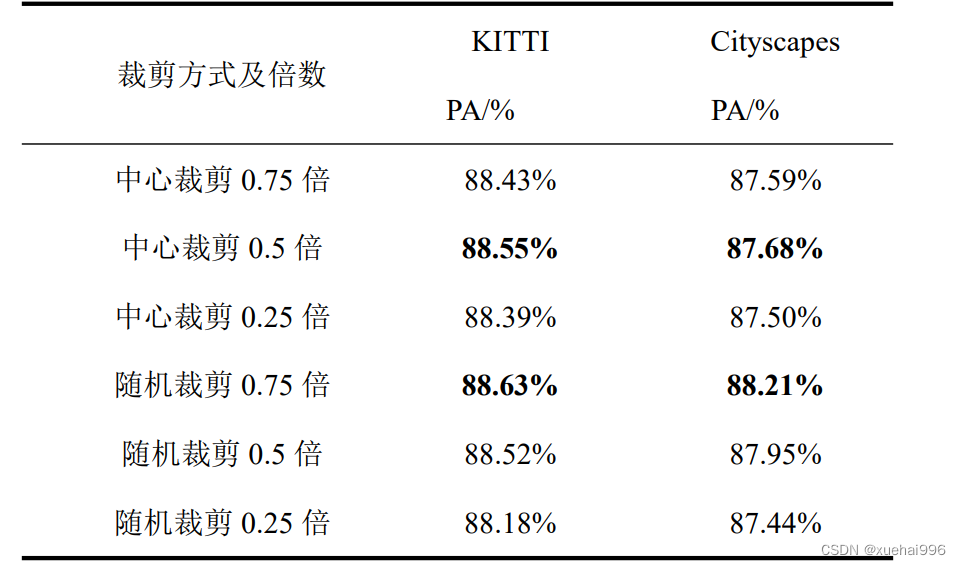
由表可知,当特征自干扰网络的输入方式为随机裁剪0.75倍时道路场景的分割精度最高,原因在于随机裁剪的形式相比于中心裁剪大幅度丰富了特征的多样性,同时在随机裁剪方式中,随着裁剪倍数的降低得到的局部特征很难与全局特征相关联成为了干扰,因此在随机裁剪方式中随着裁剪倍数降低导致分割精度的下降;而在中心裁剪方式中,精度最高时为0.5倍的原因在于过大的裁剪倍数导致局部特征信息相似于主分割网络全局信息,因此无法进一步为主分割网络提供丰富的特征,同时过小的裁剪倍数会丢弃了图片的周边特征。
为验证干扰特征与原始特征通过不同的融合模块结构对道路场景分割精度的影响,我们设计了四种融合模块,表列出了不同融合模块的对比实验结果:
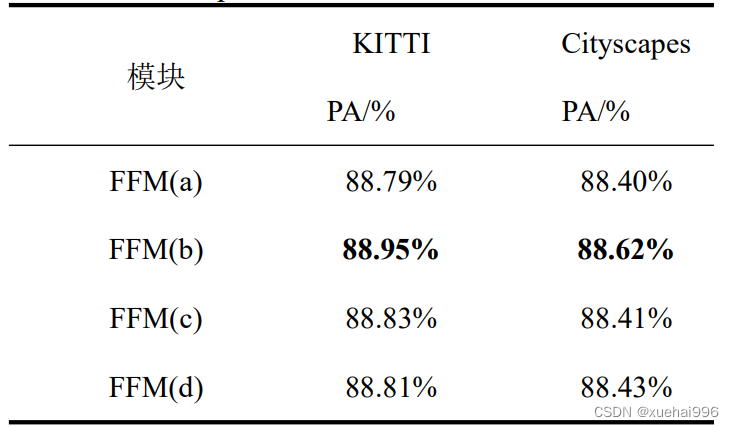
由表可知,当选取融合模块(b)时道路场景的分割精度最高,原因在于相比结构(a)的1*1卷积核更大的卷积核尺寸可以关联区域内特征,然而结构(d)中的空洞卷积不适用于对干扰特征的提取融合,空洞卷积会降低干扰无法达到充分的干扰效果;结构©的残差结构也不适用于此,残差通路会直接将未融合的特征传向解码器,干扰信息过强导致网络难以收敛。
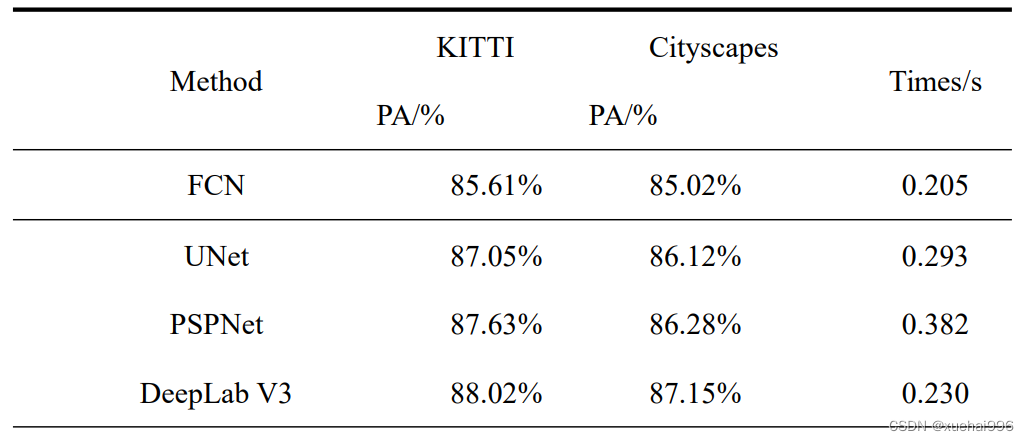
综上表实验结果,本文在选取特征自干扰网络输入的裁剪方式为随机裁剪0.75倍、融合模块采用结构(b)的情况下,与目前主流的道路场景分割模型FCN、PSPNet、FCRN、DeepLab V3在数据集KITTI和 Cityscapes数据集中展开对比实验,实验结果如表所示:
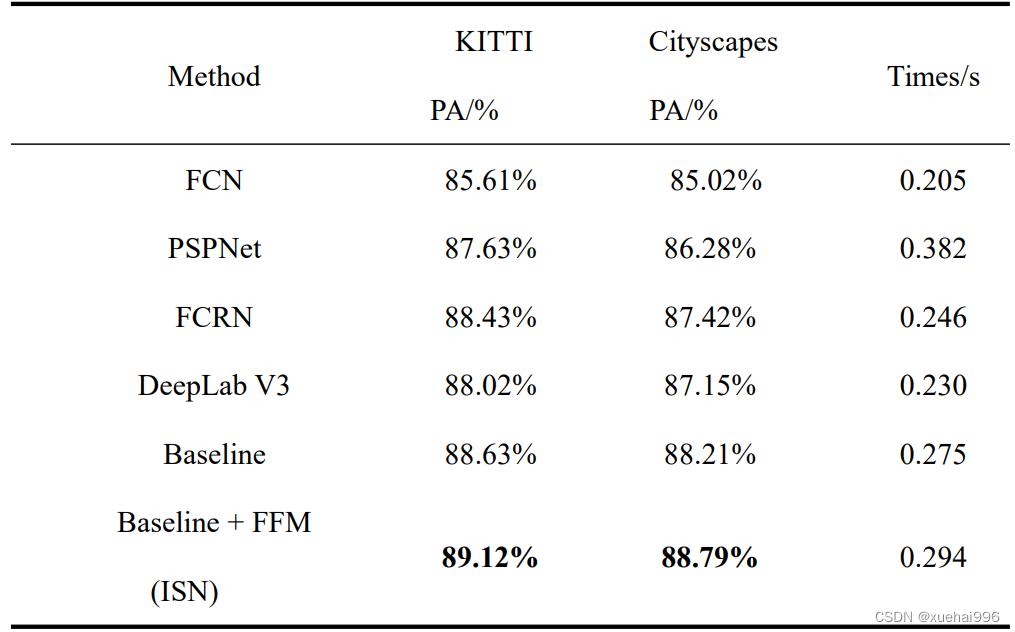
实验证明,通过引入特征自干扰网络生成的伪特征,经融合模块嵌入主分割网络原始特征中来提升网络的抗干扰能力是有效的,抑制了断点和孔洞的产生,最终使得本文的模型具有较高的分割精度,高于主流的分割模型。
10.系统整合

参考博客《基于深度学习的城市场景路面交通车辆行人障碍物图像分割系统》
11.参考文献
[1]付阳阳,陶建军,王夏黎,等.基于改进SegNet模型的斑马线检测方法研究[J].公路交通科技.2022,39(4).DOI:10.3969/j.issn.1002-0268.2022.04.013 .
[2]李紫薇,英昌盛,于晓鹏,等.基于改进SegNet模型的遥感图像建筑物分割[J].吉林大学学报(理学版).2022,60(2).DOI:10.13413/j.cnki.jdxblxb.2021238 .
[3]张丽,张毅,涂金龙.激光雷达的关键技术及其在无人驾驶车辆中的应用[J].现代工业经济和信息化.2021,11(12).DOI:10.16525/j.cnki.14-1362/n.2021.12.064 .
[4]杨丽丽,陈炎,田伟泽,等.田间道路改进UNet分割方法[J].农业工程学报.2021,(9).DOI:10.11975/j.issn.1002-6819.2021.09.021 .
[5]张海川,彭博,许伟强.基于UNet++及条件生成对抗网络的道路裂缝检测[J].计算机应用.2020,(z2).DOI:10.11772/j.issn.1001-9081.2020020197 .
[6]孙朝云,裴莉莉,李伟,等.基于改进Faster R-CNN的路面灌封裂缝检测方法[J].华南理工大学学报(自然科学版).2020,(2).DOI:10.12141/j.issn.1000-565X.180421 .
[7]田萱,王亮,丁琪.基于深度学习的图像语义分割方法综述[J].软件学报.2019,(2).DOI:10.13328/j.cnki.jos.005659 .
[8]冉鹏,王灵,李昕,等.改进Softmax分类器的深度卷积神经网络及其在人脸识别中的应用[J].上海大学学报(自然科学版).2018,(3).DOI:10.12066/j.issn.1007-2861.1831 .
[9]田娟,李英祥,李彤岩.激活函数在卷积神经网络中的对比研究[J].计算机系统应用.2018,(7).DOI:10.15888/j.cnki.csa.006463 .
[10]顾晨晨,王震洲.基于双目摄像头的路面障碍物检测与研究[J].无线互联科技.2018,(19).DOI:10.3969/j.issn.1672-6944.2018.19.017 .















 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









