






一、前言
目前大模型的微调方法有很多,而且大多可以在消费级显卡上进行,每个人都可以在自己的电脑上微调自己的大模型。
但是在微调时我们时常面对一个问题,就是数据集问题。网络上有许多开源数据集,但是很多时候我们并不想用这些数据集微调模型,我们更希望使用某本书、某个作者的作品、我们自己的聊天记录、某个角色的对话来微调模型。
用于微调的数据通常是成千上万的问答对,如果手工搜集,需要花费大量时间。
文本将介绍一种方式,利用大模型来构造自己的数据集,并使用我们构造的数据集来微调大模型。
二、构造数据集
2.1 目的
数据集通常是问答对形式,比如alpaca数据集的形式如下:
{
"instruction": "保持健康的三个提示。",
"input": "",
"output": "以下是保持健康的三个提示:\n\n1. 保持身体活动。每天做适当的身体运动,如散步、跑步或游泳,能促进心血管健康,增强肌肉力量,并有助于减少体重。\n\n2. 均衡饮食。每天食用新鲜的蔬菜、水果、全谷物和脂肪含量低的蛋白质食物,避免高糖、高脂肪和加工食品,以保持健康的饮食习惯。\n\n3. 睡眠充足。睡眠对人体健康至关重要,成年人每天应保证 7-8 小时的睡眠。良好的睡眠有助于减轻压力,促进身体恢复,并提高注意力和记忆力。"
}
但是实际上我们能拿到的数据通常是一大段文本的形式,比如:
小时候,那时我还只有6岁,看到一本描写原始森林壮观景象的书,名叫真实的故事。书里有一幅很精彩的插画,画的是一条大蟒蛇正在吞食一只动物,下面就是那幅插画的复制品。
这本书上说:“大蟒蛇把它们的猎物不加咀嚼地整个吞下去,之后,就再也不动了,然后通过长达六个月的睡眠来消化掉这些食物。”
...
现在我们要做的就是把大段文本形式的数据转换成alpaca的形式。
在以往我们只能通过人工的方式完成,而现在我们可以借助大模型的能力。大致思路就是让大模型根据文本,总结出对话、问答内容。这点可以通过Prompt工程实现。
2.2 Prompt设计
在系统Prompt中,我们需要强调根据上下文内容,让模型提取对话、问答等内容。比如:

这样就可以让模型自己提问,自己回答。然后我们需要规定输出的格式,我们希望得到字典数组,所以用户Prompt可以设置成:

根据问题不同,可以对上面的内容进行一些调整。下面可以开始编写代码。
2.3 处理文档
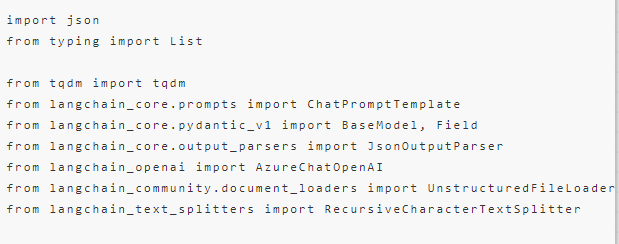
首先导入需要用到的模块:
在构建chain前,我们先完成文档处理的操作。我们希望传入的内容是文本数据,这里可以是txt等文件形式。我们这里以txt为例:
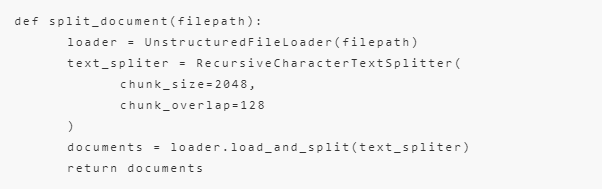
使用上面的函数,可以返回大段的文本片段。
2.4 构建chain
下面就是构建用于生成数据集的chain,包括Prompt、LLM、Outputparser三个部分内容分别如下:
2.4.1 Prompt
我们使用ChatPromptTemplate将上面的Prompt整合起来,代码如下:
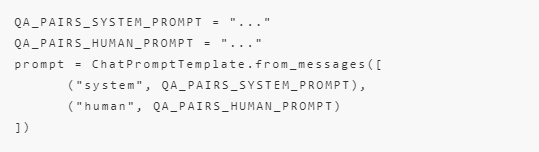
在QA_PAIRS_HUMAN_PROMPT中我们添加了{text}占位,invoke时需要传入{“text”: “xxx”}。
2.4.2 LLM
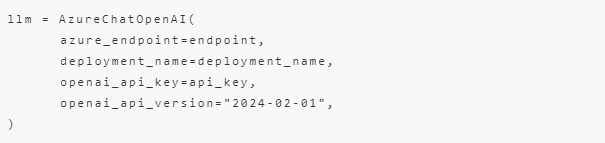
大模型的选择非常多,一般的建议是选择长上下文、且能力比你要微调的模型强的模型。这里使用GPT-3.5-16k,代码如下:
2.4.3 OutputParser
最后是提取出结果,我们定义结果的Model:

最后将三者连接起来:
chain = prompt | llm | parser
我们把构建chain的操作写成create_chain函数:

下面我们可以来试一试效果:

我使用小王子的书作为测试,下面是生成的部分数据集:

我们可以收集同一作者的大量书籍,使用上面的方式构建数据集。在构建过程中,每次执行后,结果可能不一样,因此可以通过多次构建的方式生成更多样本。
三、微调模型
在准备好数据集后,我们就可以进行微调了,我们可以使用已有的项目进行微调,比如LLaMA-Factory就是一个不错的选择,链接如下:
https://github.com/hiyouga/LLaMA-Factory
具体的微调方式可以参考项目文档。
本文选择使用peft模块实现微调操作,其实其它项目也是使用这个项目来完成。先导入必要的模块:
from peft import LoraConfig, TaskType
from transformers import Trainer
from datasets import load_dataset
from transformers import AutoModelForCausalLM, TrainingArguments, AutoTokenizer
from peft import get_peft_model
3.1 加载模型和配置LoRA
首先需要加载模型以及配置微调模型,我们选择使用LoRA进行微调:
# 配置参数
peft_config = LoraConfig(task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1)
# 加载模型
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
关于LoRA的原理,可以参考:https://juejin.cn/post/7280436307914407976
3.2 加载数据集
接下来加载我们创建的数据集:

3.3 配置训练参数并训练
接下来配置训练参数开始训练:

我们可以根据硬件情况调整per_device_train_batch_size和per_device_eval_batch_size。现在只需要运行代码,等待片刻即可训练完成。
四、推理
接下来我们要做的就是推理了。LoRA是一个旁支网络,我们需要在原有的模型上,添加LoRA,添加方式如下:
model.load_adapter('outputs', adapter_name='lora01')
model.set_adapter("lora01")
调用上面代码后,model的推理操作就是添加LoRA后的推理。推理的完整代码如下:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
model = model.to("cuda")
model.load_adapter('outputs', adapter_name='lora01')
model.set_adapter("lora01")
model.eval()
inputs = tokenizer("作者小时候看了一本关于什么的书?", return_tensors="pt")
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=50)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
最后我们可以和使用正常的AutoModelForCausalLM模型一样使用微调后的模型。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 3214
3214

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









