






各聊天大模型中都有个参数,决定了每次大模型回复时能说最多多少个字的内容,这个参数就是“Max_Tokens”。
说到这个参数,不得不先说一下“Token”这个词。
在聊天大模型中,Token是模型的最小单位,也是聊天大模型可以理解我们人类自然对话的主要形式。
每一次聊天大模型的输入和输出,都会由各大模型根据已经设定好的处理方式处理成Token。
用户的每一次对话,文本在发给大模型后,会被模型使用各种方式拆分成若干个片断,也就是传说中的分词技术,这分出来的每一个片断就是一个Token。
同样的,大模型每次输出来的内容,也需要通过这种技术进行转换。
通俗一点的说法,就是大模型每次需要将用户说的每一句话先翻译成模型可以理解的语言文字。然后大模型根据模型里已经建立的逻辑,用自己的语言输出回答,再翻译成人类可以认识的语言文字给我们看。

这个时候,不同大模型处理不同国家的主语言文字,其效果就出现区别了。
像GPT、Claude这些海外聊天大模型,其初创及用户群体都以国外为主,他们对英语更加熟悉,这也就意味着这些聊天大模型对英语单词的处理会更好一些。
而国内各平台的聊天大模型,最开始的时候还会参考一些海外大模型的Token处理方式,现在已经逐渐走出了适合汉字的Token处理和计算方式。
国内大模型第一面对和服务的对象主要还是国内用户,毕竟我们国家的人口基数摆在那,那些海外大模型的分词技术对于中文的处理其实并不是太好。
汉字历史悠久,语言博大精深,什么多音字多意字人称代词之类的,指望一群老外能够理解中文,实在是有些为难的。
无论是建立一套属于我们自己的行业标准,还是建立国内大模型的技术壁垒,又或者更好地服务用户,总之,现在大多数国内各家聊天大模型,对于中文的支持和处理能力,明显能感受出是有一定优势的。
从一些数据就能看出来明显的区别:
GPT目前的Token计算中,1 Token约等于4个英文字符,或者0.75个中文汉字。
而国内各家大模型中,不看别的,仅看Token与中文汉字的换算,就与海外模型的计算区别非常明显。
阿里的通义千问,一个Token约等于1.52个中文,Minimax新出的6.5版本的各个模型中1Token明确等于1.6个中文,字节火山引擎的各模型中,1Token在11.5个汉字不等。
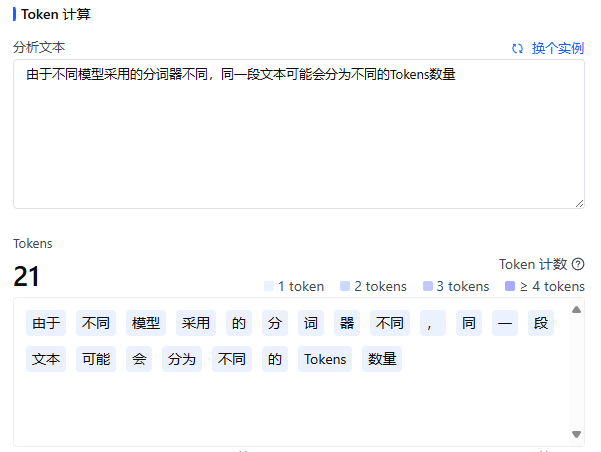
(图为火山提供的Token计算器)
对于用户而言,最直接的好处就是:如果聊天大模型本身能力和价格都差不多的话,那在国内聊天大模型中用中文聊天,绝对省钱!!
这可能是国人对于国内大模型发展的最朴素的愿望?
反正我是这么想的!
“Max_Tokens”这个参数,就与Token紧密相关。
通常情况下,它通过模型输入输出的Tokens的总数量,控制着聊天大模型单次生成内容的最大长度。
注意,是最大长度,而不是指定长度。
这里面有两层意思:
第一层意思,是指单次聊天,有可能会生成Max_Tokens这么长的内容,但也有可能生成的很短。毕竟,Max_Tokens只是个生成范围,只是这个范围比较大而已。
第二层意思,是说如果需要输出的内容超出Max_Tokens的最大值,那就需要做好可能被聊天大模型主动截断的准备。
每次就只准备说这么多,爱啥啥,聊天大模型就是这么霸气!
除此之外,聊天大模型的这个Max_Tokens是存在明确上限的,只不过在不同的聊天大模型上,其上限不太一样而已。
比如GPT的很多模型,Max_Tokens是4096;Minimax的聊天大模型中,Max_Tokens通常是8192;而在阿里的通义千问闭源聊天模型中,Max_Tokens通常只有2000。
另外还有一个要注意的是,每个聊天大模型都有上下文的总Tokens长度限制,而Max_Tokens有个隐藏上限,即受限于这个总Tokens长度限制。
换个说法,就是聊天大模型的输入输出的总Tokens值是有上限的,而每次给聊天大模型发消息,加上上下文等组成Messages,是需要消耗掉一部分Tokens的,如果扣除这些消耗之后,剩下的Tokens不够满足Max_Tokens的话,那会以剩下的Tokens为标准进行输出。
所以,如果我们在使用的过程中发现大模型的内容输出长度明显不对的时候,有可能不是大模型在抽疯,是我们没用好参数。
老规矩,说些你可能不了解的信息:
Max_Tokens这个参数在很多模型中都是值得信赖的,模型在内容输出时基本会参考这个参数进行处理,但要注意两点:
\1. Max_Tokens设置过小时可能会不生效。 比如将它设为1,然后你让大模型给你写个200字的小作文,很多模型就会不管这个参数进行输出。
又要让模型干活,又不给它活路,换你,这活你也不好干啊!

\2. Max_Tokens设置过大(比如边界值或者超出上限)时,可能会以奇怪的方式生效。
前面说过,Max_Tokens是模型生成内容的最大长度,只要在这个长度范围内的生成,都算是生效的。但在某些聊天大模型里,我曾经遇到过一个奇怪的生效方式,就是大模型会在内容完成后,继续填充一些莫名其妙的字符以填充长度。
至今我依然无法确定这是灵异事件还是模型抽疯,也不知道12315管不管!
3

Tempurature
我曾经一直以为热运动只是一个物理学中的概念。
但当我看到大模型中的Tempurature参数后,只是稍作了解,我便对把这个词用在这里的那位大神佩服得五体投地。
原来热物理现象还可以这么通用的。
形象点说,就是温度越高,不规则运动越多,也就更加地无规律。在大模型中的表现,就是温度越高,输出内容的随机性越高,创新性越强。
相反,温度越低,运动便会越发地趋向稳定。大模型中的表现便是在低温度值的设定下,输出相同内容的概率大幅度提升,温度越低,内容变化越少。
与我们现实中的“温度”有点不太一样的是,大模型中的“温度”,其值通常在0-1之内,部分模型最多也就是0-2而已。
聊天大模型和现实的温度差异,也就是数值放大100倍(或者50倍)的差异,本质还是异曲同工的。
Temperature这个参数,在聊天大模型的实际应用中使用频率还是挺高的,而且应用方向也非常容易判断:
比如在写作、写剧本等等需要创意或者多样化的生产环境中,Temperature的设定倾向于较高的值,像Deepseek给出的参考推荐就是1.25(它的温度区间是0-2),已经是区间内偏高位的值了。
而正常对话,如果没有特殊要求,各模型一般是用的默认值,这个值通常需要聊天大模型保持一定程度的多样性,又不能太过分。如果Temperature在0-1区间的话,一般在0.7-0.8的设定内,0-2区间的Temperature通常会设定在1.0。
而如果是技术文档、数据分析、知识问答之类的场景,Temperature的值通常会设的比较低,甚至有可能设定为0,以确保聊天大模型对话时内容能趋向稳定。
专业性的内容,还是不要太跳脱的好!要是每次给个不一样的答案,换谁都不敢轻易相信啊!
说点可能不知道的信息:
在实测各模型的过程中,发现一个情况,就是如果不太确定的话,最好不要将Temperature设成边界值,比如0-1区间的Temperature,不要轻易设成0或者1,有需要的话,可以设成0.01或0.99。
在一些模型中,将Temperature设定成边界值,有时候反而会坏事。
最常见的表现就是模型会输出一堆乱七八糟或者没有意义的内容,很像是人们烧糊涂了或者冻糊涂了导致神志不清,从而引发的胡言乱语现象。
错倒是也没错,毕竟聊天大模型很像是人的脑子,对温度还是挺敏感的。
4

Top_p
这个参数曾经困扰了我很久。
我曾经一度认为,它和Temperature的功能出现了一些重复。
但事实上,它和Temperature能达到的效果确实是不一样的。
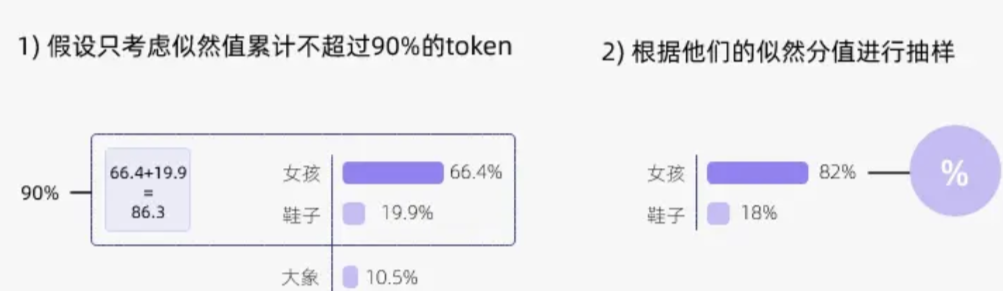
举个例子,比如现在有“女孩”、“大象”这两个词:
Temperature决定的是这两个词被选择的概率。
温度越低,这两个词的其中某个词的被选概率就越高,带来的结果就是某个词被选中的概率也越高。输出经常都是同一个词,那自然看起来模型输出的稳定性就越高,变化也越小。
相反,温度越高,两个词被选中的概率就会越来越趋向于平均,这意味着每次输出的词都可能是其中的任何一个,自然也就提升了输出的多样性。
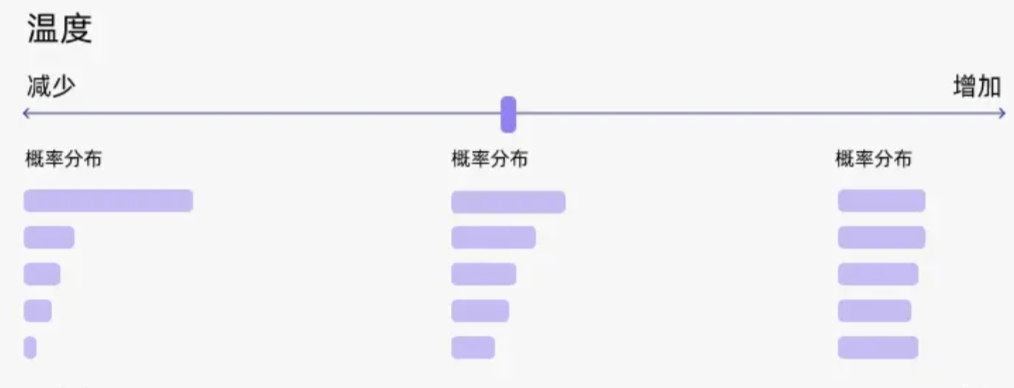
Top_p却是决定了词被选择的范围。
每个词都有一个概率分,在聊天大模型生成对话的时候,每一次都会按照Top_p的值进行概率筛选,从前往后(从大到小)先保留概率和累计达到Top_p的所有词,然后再重新分配概率后,选择一个词作为结果。
简单点说,如果Top_p设定的值越大,那每次可以获取到的词的数量也会越多,结果随机性也可能会越大。
从聊天大模型开始输出第一个词起,大模型的每一次输出的过程都是在筛选下一个词的路上。
Top_p的存在让大模型的上下文输出更加稳定,又能有一定的灵活性。
毕竟通常情况下,Top_p不会设定成上限或者下限,这也就意味着每次都会筛选掉不合适的词,又保留了可以筛选到的最高概率的合适词汇。
说点值得注意的信息:
Top_p这个参数和Temperature参数一样,如没有特殊需求,通常不建议设置为上下限的边界值。
不知道有没有人注意过,使用聊天大模型时,很多聊天大模型的参数说明中,通常都会有这么一句话:“建议Temperature和Top_p同时只调整其中一个。”
从上面的例子可以看出,这两个参数只调整其中一个,对于大模型调整后的输出是可以预期的:要么是内容多样化变了,要么就是上下文的质量变了。
而同时调整两个,无论是词的概率还是上下文都会受到影响,直接从根本上改变输出的效果,从而导致结果完全无法预期,或者无法和之前的效果进行比较。
这里有几个小技巧:
如果想要输出的内容更多样化或者随机性,或者想让输出的内容更稳定,优先调整Temperature,效果其实不错。
如果调高了Temperature,但输出内容依然多样化效果不佳,可以考虑增加Top_p。
如果经常输出无意义的内容,或者容易产生知识幻觉,降低Temperature和Top_p,可以减少这类情况的发生。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 2800
2800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









