







【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
一、自动驾驶端到端介绍
- 传统自动驾驶系统: 采用模块化部署策略,将感知、预测和规划等任务分别开发并集成到车辆中。但是各模块的优化目标不同,整个系统可能无法对齐到一个统一的目标(如规划/控制任务)
- 端到端自动驾驶系统:
- 简化系统:将感知、预测和规划集成到一个模型中,联合训练。
-
全局优化:整个系统都针对最终任务进行优化。
二、经典论文
论文1:[UniAD] Planning-oriented Autonomous Driving 【CVPR2023 Best Paper】
- 自动驾驶端到端的开山之作
- 为什么需要端到端的自动驾驶?
- 比对过去 模块化(a) 和 多任务模块(b) 的方法
- 模块化(a):每个模型负责单独的子任务,便于调试,但是各个模块做到最优,并不能实现最后的规控结果最优,并且有误差传递的问题。
- 多任务模块(b):共享特征提取器,不同的任务头实现多任务,但是不同任务之间可能会存在负面影响。
- 端到端 (c)
- 隐式端到端:输入传感器数据,直接输出规划或者控制指令【简洁,但缺乏可解释性,难调试迭代】
- 显示端到端:端到端模型包含多个模块(负责不同任务),每个模块各自输出,并将特征传递到下游任务【本工作使用的方法】
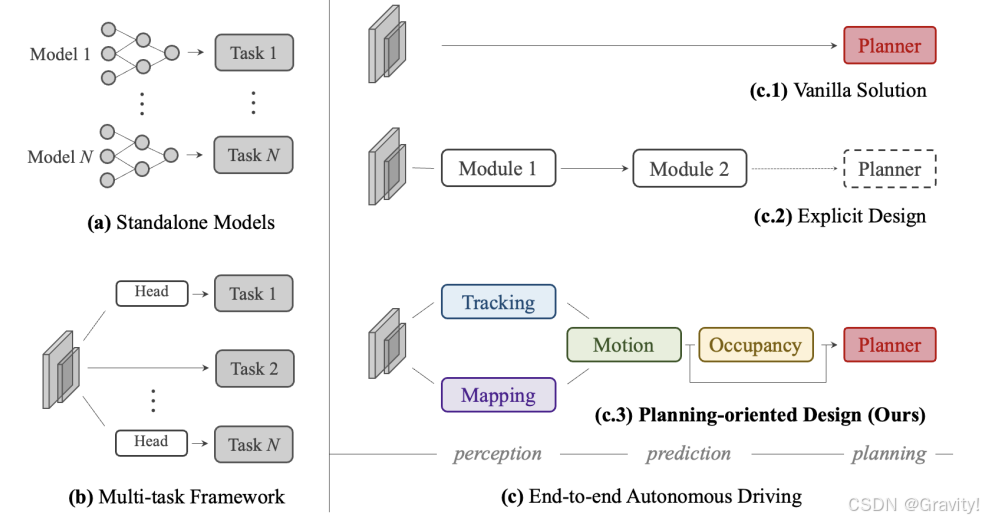
- 比对过去 模块化(a) 和 多任务模块(b) 的方法
- UniAD核心思想:用多组 query 实现了全栈 Transformer 的端到端模型
- 流程:环视图【输入】→ Backbone生成BEV特征 → 感知模块 → 预测模块 → 规划模块 → 规划轨迹
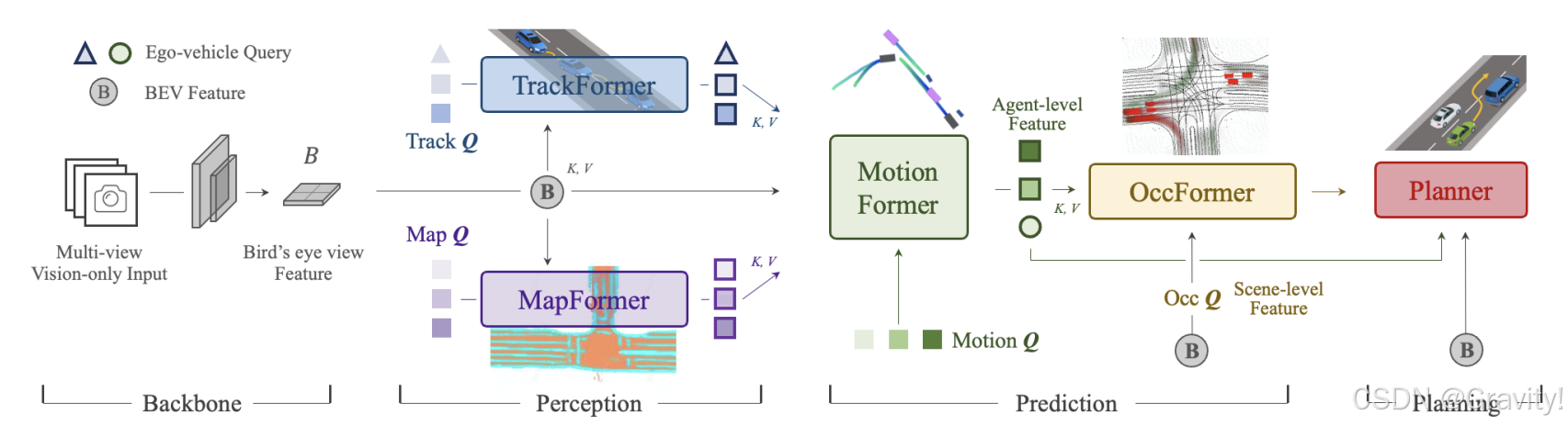
- 三个主要模块:感知模块 (TrackFormer, MapFormer),预测模块(MotionFormer, OccFormer),规划模块(Planner)
- TrackFormer【感知】:
- 负责目标检测和多目标跟踪,Decoder结构
- 用检测查询(detection queries)[新出现的目标] 和跟踪查询(track queries)[已有目标] 来检测和跟踪场景中的动态目标
- MapFormer【感知】:
- 负责在线地图生成,Decoder结构
- 将道路元素(如车道线、分隔线、行人过街区域等)分割为语义类别,用语义查询(map queries)来表示道路元素,解码出地图语义分割结果
- MotionFormer【预测】:
- 负责预测场景中每个目标的未来轨迹,Decoder结构
- 通过多头自注意力和交叉注意力,实现目标-目标、目标-地图和目标-目标点交互
- OccFormer【预测】:
- 负责预测场景中每个位置是否被占用,Decoder结构
- 生成未来多个时间步的占用图
- TrackFormer【感知】:
- 模块之间的Query交互【核心】
- 【TrackFormer】Track query 与 BEV 特征交互 →
【MapFormer】Map query与 BEV 特征交互 → - 【MotionFormer】Motion query 与
、
以及 BEV 特征交互 → 预测的未来轨迹 &
- 【OccFormer】密集的BEV 特征(query) 与
和
→ 预测的占据珊格
- 【TrackFormer】Track query 与 BEV 特征交互 →
- 基于最终“规划”为目标的query交互【核心】
- Track query 中包含一个特定的 ego-vehicle query 用来表示自车属性 → MotionFormer 更新 ego-vehicle query → Planner中与BEV特征交互【此时包含环境的感知与预测信息】
- 利用OccFormer 的输出对自车路径进行优化,避免行驶到未来可能有物体占用的区域
- UniAD为开环端到端方法,在nuScenes上进行实验
论文2:ReasonNet: End-to-End Driving with Temporal and Global Reasoning【CVPR2023】
- 现有挑战(模型模块化系统以及端到端系统):
- 预测场景的未来演变 和 预测物体的未来行为
- 处理极端事件(例如遮挡目标的突然出现)
- 主要贡献:
- 提出了 ReasonNet,一个结合时间推理和全局推理的端到端自动驾驶框架
- 提出 DriveOcclusionSim Benchmark,包含多种遮挡场景,用于系统性地评估遮挡事件
- 在闭环验证的Carla Leaderboard取得第一
- ReasonNet 方法流程:环视图(左右前后) & 点云【输入】→ 感知模块【生成BEV特征】→ 时间推理模块 → 全局推理模块 → 控制模块
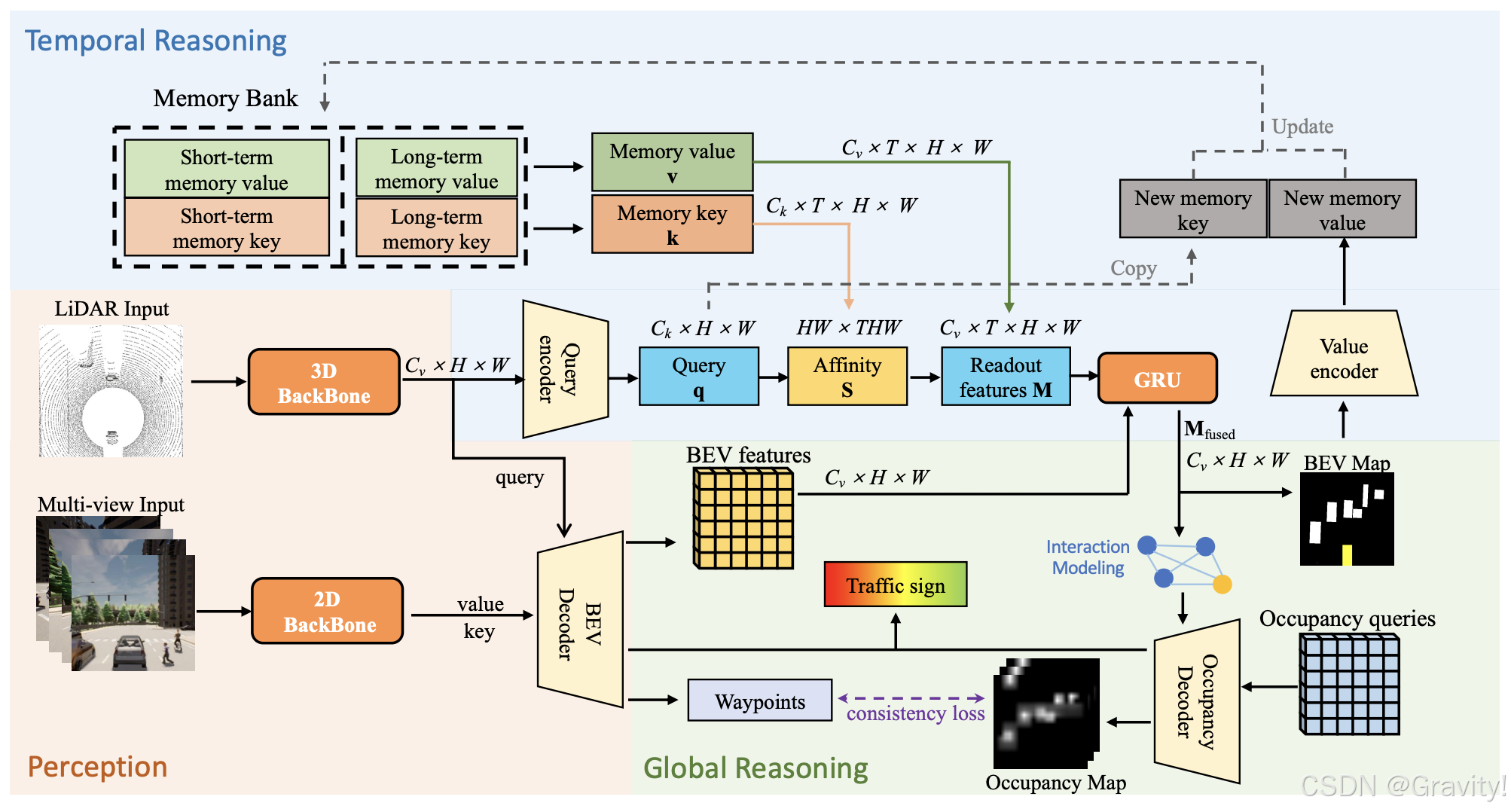
- 感知模块
- 图像特征(by ResNet)【k,v】& 点云特征(by PointPillars+下采样) 【q】
→ 模态融合的BEV Decoder → BEV特征、交通标志特征和路径点(由另外两种query获得)
- 图像特征(by ResNet)【k,v】& 点云特征(by PointPillars+下采样) 【q】
- 时序推理模块(Temporal Reasoning Module)
- 时序处理:通过注意力机制从历史特征提取有用信息,与当前帧的特征融合
- 实现方式:相似度计算 → 特征聚合 → GRU融合时间维度的信息 → 最终输出
特征维度为
- 相似度计算:对存在memory bank中的每个历史帧t,其特征作为key,和当前帧的特征(query)计算相似度
- 特征聚合:相似度 * 历史特征(value)
- 实现方式:相似度计算 → 特征聚合 → GRU融合时间维度的信息 → 最终输出
- Memory Bank 维护
- 短期记忆库(存储最近几秒内的高分辨率特征) + 长期记忆库(存储重要的代表性特征对,标准:大概率有物体存在 & 使用频率高)
- 记忆库更新:BEV图(由当前特征编码而成) 拼接 当前特征 作为记忆值存储
- 时序处理:通过注意力机制从历史特征提取有用信息,与当前帧的特征融合
- 全局推理模块(Global Reasoning Module)
- 交互模块 Interaction Modeling(目标-环境&目标-目标交互建模):
- 占用解码器 Occupancy Decoder:生成未来占用图,GAT的输出特征作为key, value,用可学习query解码未来Occ
- 交互模块 Interaction Modeling(目标-环境&目标-目标交互建模):
- 控制模块(Control Module)
- 用两个PID控制器对自车进行横向和纵向控制,分别跟踪预测路径点的航向和速度
论文3:VAD: Vectorized Scene Representation for Efficient Autonomous Driving 【ICCV2023】
- 动机:现有端到端方法依赖于密集的栅格化(rasterized)场景表示来进行规划,计算量大,并丢失了关键的实例级结构信息
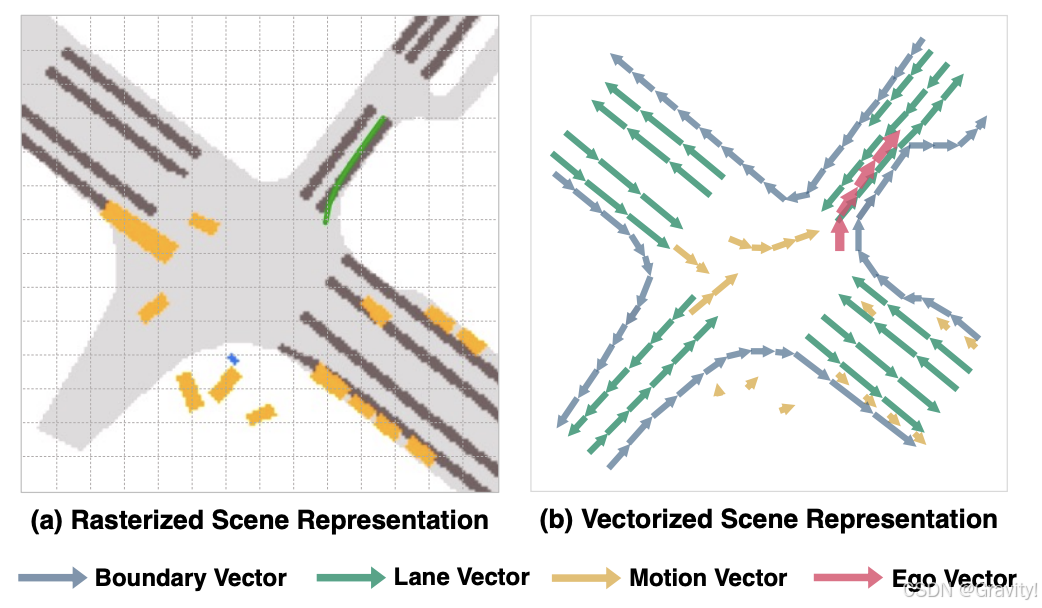
- 本文提出的VAD:端到端的矢量化(vectorized)自动驾驶框架
- VAD的特点和优势
- 完全矢量化表示:保留实例级结构信息,提高计算效率
- 提高规划安全性:矢量化的交通参与者运动和地图元素作为显式的实例级规划约束
- 提高计算效率
- 性能优势:在 nuScenes 数据集上实现SOTA
- 总体框架:环视图【输入】→ Backbone【提取BEV特征】→ 矢量化场景学习【通过agent和map query从 BEV 特征中学习矢量化的场景表示】→ 规划【输出轨迹】→ 矢量化规划约束【训练阶段用矢量化规则约束】
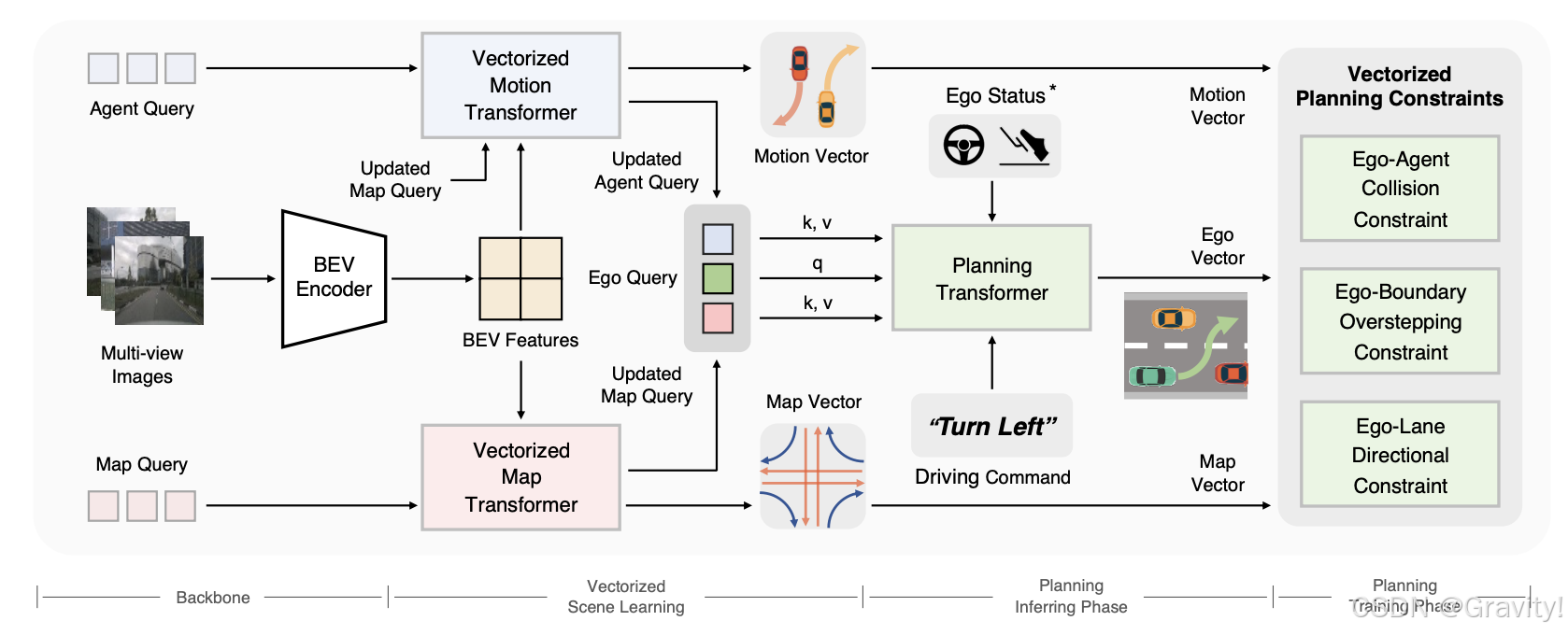
- 矢量化场景学习(Vectorized Scene Learning)
- 核心:将场景信息编码为矢量化地图(Vectorized Map Transformer实现)和交通参与者运动(Vectorized Motion Transformer实现)
- Vectorized Map Transformer:一组Map Query从BEV特征图中提取场景中矢量化的静态元素信息(如车道线,路沿和人行道)
- Vectorized Motion Transformer:一组Agent Query通过可变形注意力从BEV特征图中学习agent级的特征 → MLP从Agent Query中解码代理的属性(如位置、类别分数、方向等)
- 通过交互进行规划(Planning via Interaction)
- Ego-Agent & Ego-Map Interaction:随机初始化的Ego Query (query) 通过 Transformer 解码器和Agent Query (key&val)做交互,然后同理跟Map Query交互,得到更新后的Ego Query
- 规划头输出规划结果
- 矢量化规划约束(Vectorized Planning Constraints)
- 三种约束:1. Ego-Agent 碰撞约束(计算距离loss) 2. Ego-Boundary越界约束(计算距离loss) 3. Ego-Lane方向约束(使车开的方向和车道线方向一致,计算角度loss)
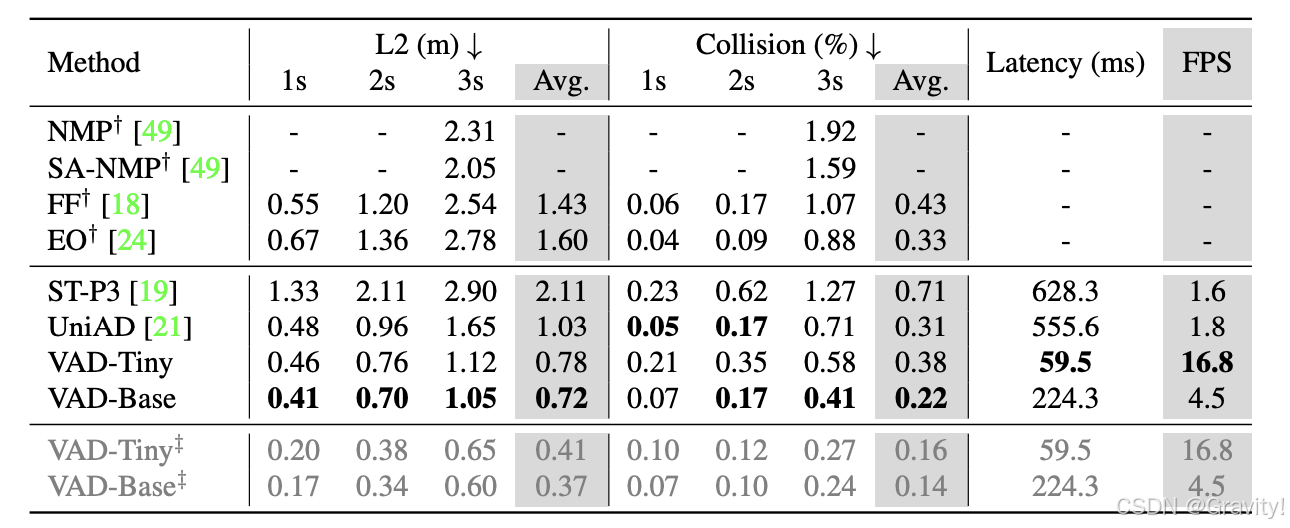
- 开环验证结果(nuscenes)
论文4:VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
- 动机:规划的不确定性(如人类驾驶的差异,和与其他车辆的交互)
- VADv2:基于概率规划的端到端驾驶模型,来解决规划中的不确定性问题
- 概率规划的优势:可以建模出不确定性;丰富的监督信息(不仅为正样本提供监督,还为规划词汇表中的所有候选动作提供监督);可以灵活地将候选规划动作添加到规划词汇表中,并进行评估
- 总体框架:环视图序列【流式输入】→ 生成场景Token → 规划Transformer【输出动作概率】→ 动作采样【用于控制车辆】→ 监督学习
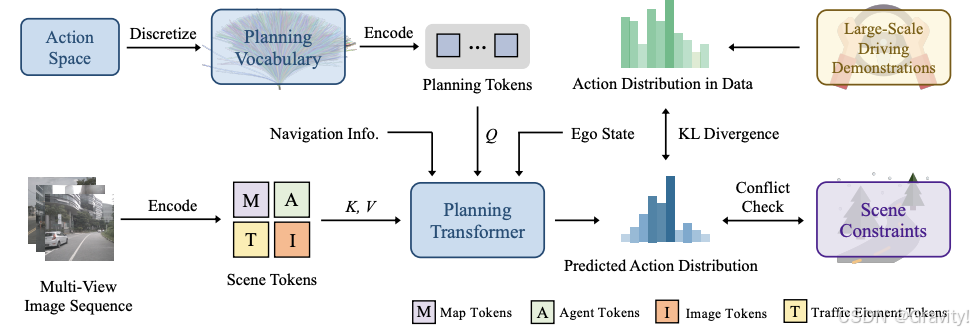
- 概率规划:
- 建立大型规划词汇表
,其中 N = 4096(代表4096条条代表性轨迹)
- 每条轨迹编码为 Planning Token
- Planning Transformer:将Planning Token作为query,Scene Token作为key & value

- 建立大型规划词汇表
- 训练Loss:
- 分布损失:KL散度计算预测轨迹与真实轨迹的差异
- 冲突损失:如果一个轨迹和道路其他物体或边界冲突,则为负样本
- 场景token损失:包括地图token、智能体token和地图元素token对应的损失
- 推理:采样最大概率动作 → 用PID控制器将选定的轨迹转换为控制信号(转向、油门和刹车)
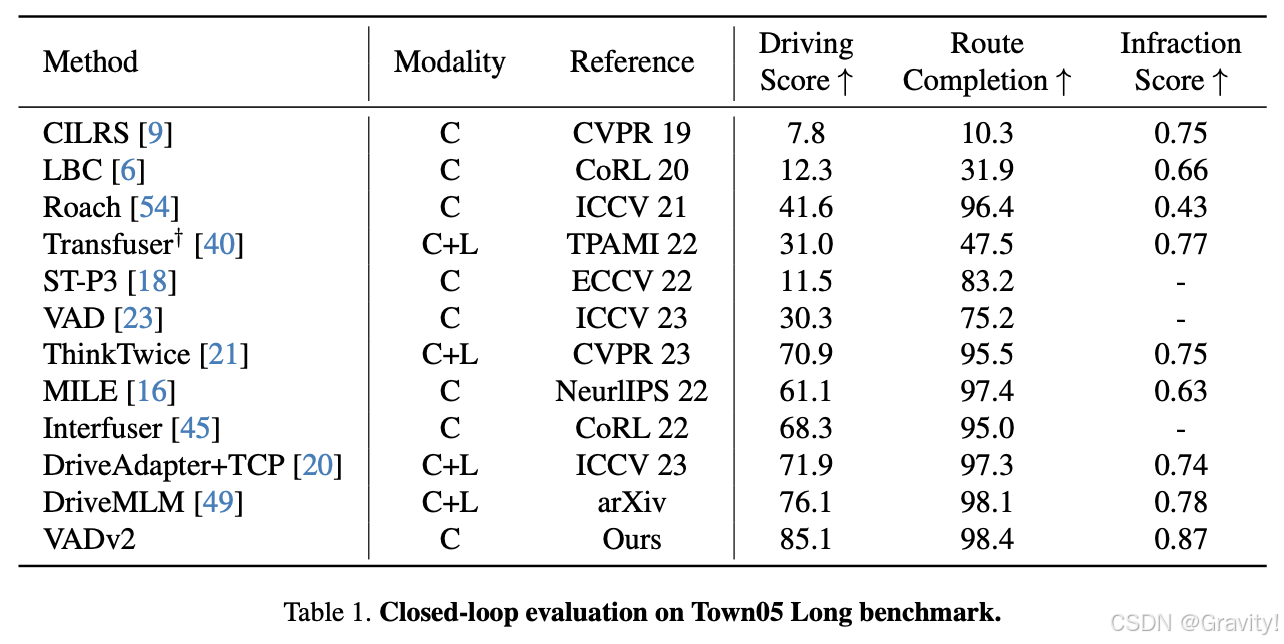
- CARLA上开环验证实验
参考:
https://arxiv.org/pdf/2212.10156
https://arxiv.org/pdf/2305.10507
https://arxiv.org/pdf/2303.12077
https://zhuanlan.zhihu.com/p/616433397

















 1335
1335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









