







Qwen2.5 如何成为最佳开源 LLM?
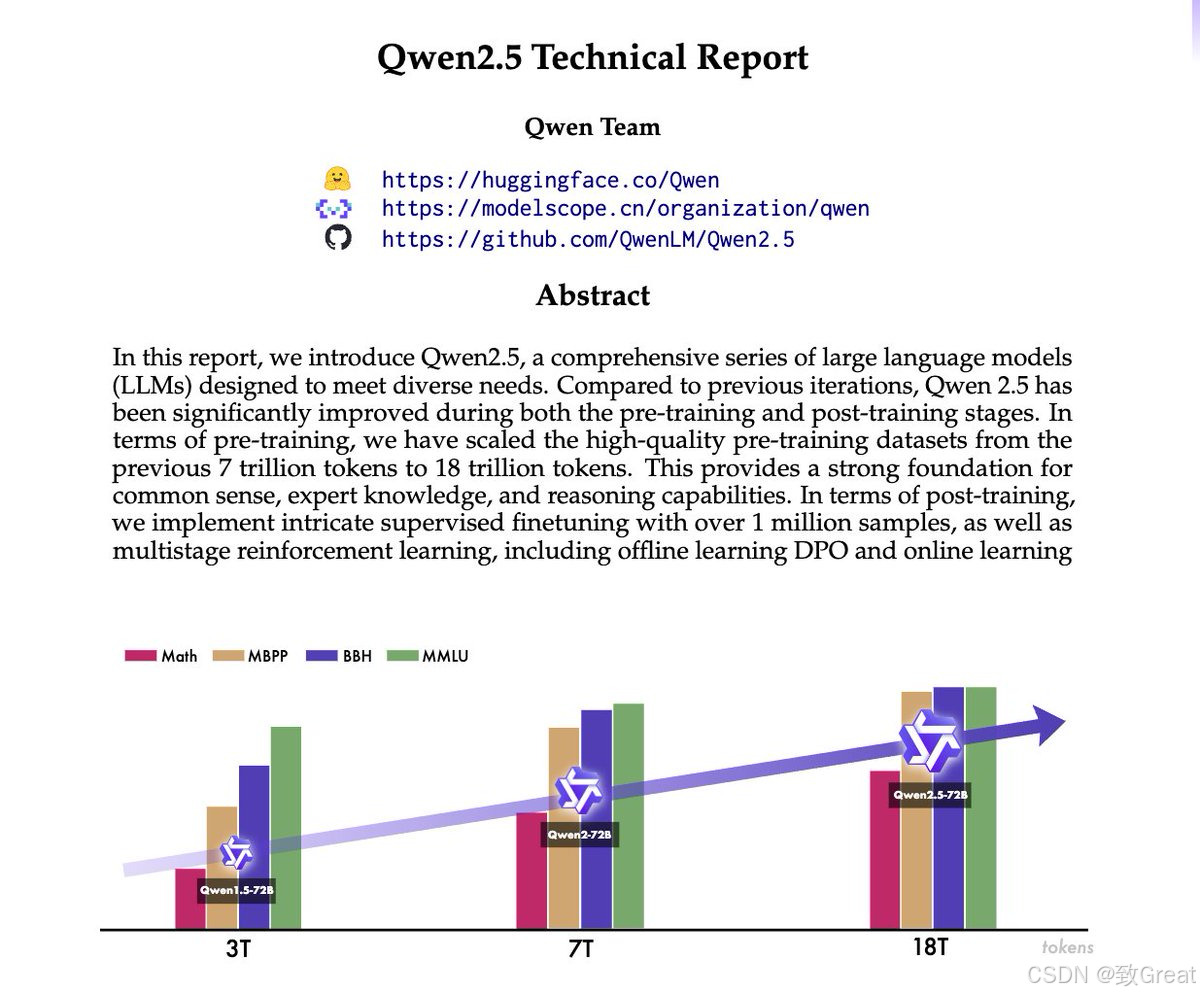
Qwen2.5代表了大型语言模型 (LLM) 开发的重大飞跃。最新版本在前几版的基础上全面改进了预训练和后训练方法。通过利用 18 万亿个 token 的庞大数据集,Qwen2.5 在常识推理、领域专业知识和整体语言理解方面取得了显著进步。
论文链接:https://arxiv.org/pdf/2412.15115
主要特点
1.模型配置:Qwen2.5 提供密集和混合专家 (MoE) 变体,模型大小从 5 亿到 720 亿个参数。还提供指令调优和量化版本,可针对各种应用优化性能。
2.增强训练:与 Qwen2 相比,预训练数据集增加了一倍以上,提高了数学、编码和一般推理任务的性能。包括监督微调和多阶段强化学习在内的训练后创新确保了与人类一致的输出和稳健性。
3.可扩展性:Qwen2.5-Turbo等模型最高支持100万个token,可以适应文档分析、扩展对话等长上下文应用。
Qwen2.5 有哪些改进
- 将预训练数据从 7T 扩展到 18T 标记,使用现有的 LLM 来过滤、分类和评分数据质量;
- 使用对话生成与数学、代码和知识领域相关的合成数据;
- 将 SFT 扩展到 100 万以上样本,涵盖长文本、数学、编码和多语言任务;
- 将指令翻译成不同的语言以提高多语言能力;
- 将 CoT 与拒绝采样相结合以生成高质量的数学数据;
- 在 150K 个训练对上使用离线强化学习 (DPO),重点关注复杂任务,然后与 SFT 模型合并;
- 应用在线强化学习 (GRPO),使用 72B 奖励模型对真实性、帮助性和安全性进行训练,并抽样 8 个回复答案;
Qwen2.5 亮点
- 经过训练的基础模型和 7 种大小的指令调整模型:0.5B、1.5B、3B、7B、14B、32B 和 72;
- 🧠架构:GQA、SwiGLU、RoPE、QKV 在注意力和 RMSNorm 中的偏差;
- ⚖️使用 Qwen2-Instruct 对不同领域的内容进行分类和平衡;
- 📈将预训练的 7T 令牌增加到 18T 令牌可提高所有任务的性能;
- 💡使用 LLM 过滤训练数据比以前的方法有了显著的进步;
- 💪🏻 SFT 模型训练了两个时期,LR 从 7e-6 下降到 7e − 7;
- 🥋 DPO 在 150,000 个样本上训练了 1 个 epoch,LR 为 7e-7;
- 🔄多阶段后训练:结合 SFT、DPO、Merging 和 GRPO;
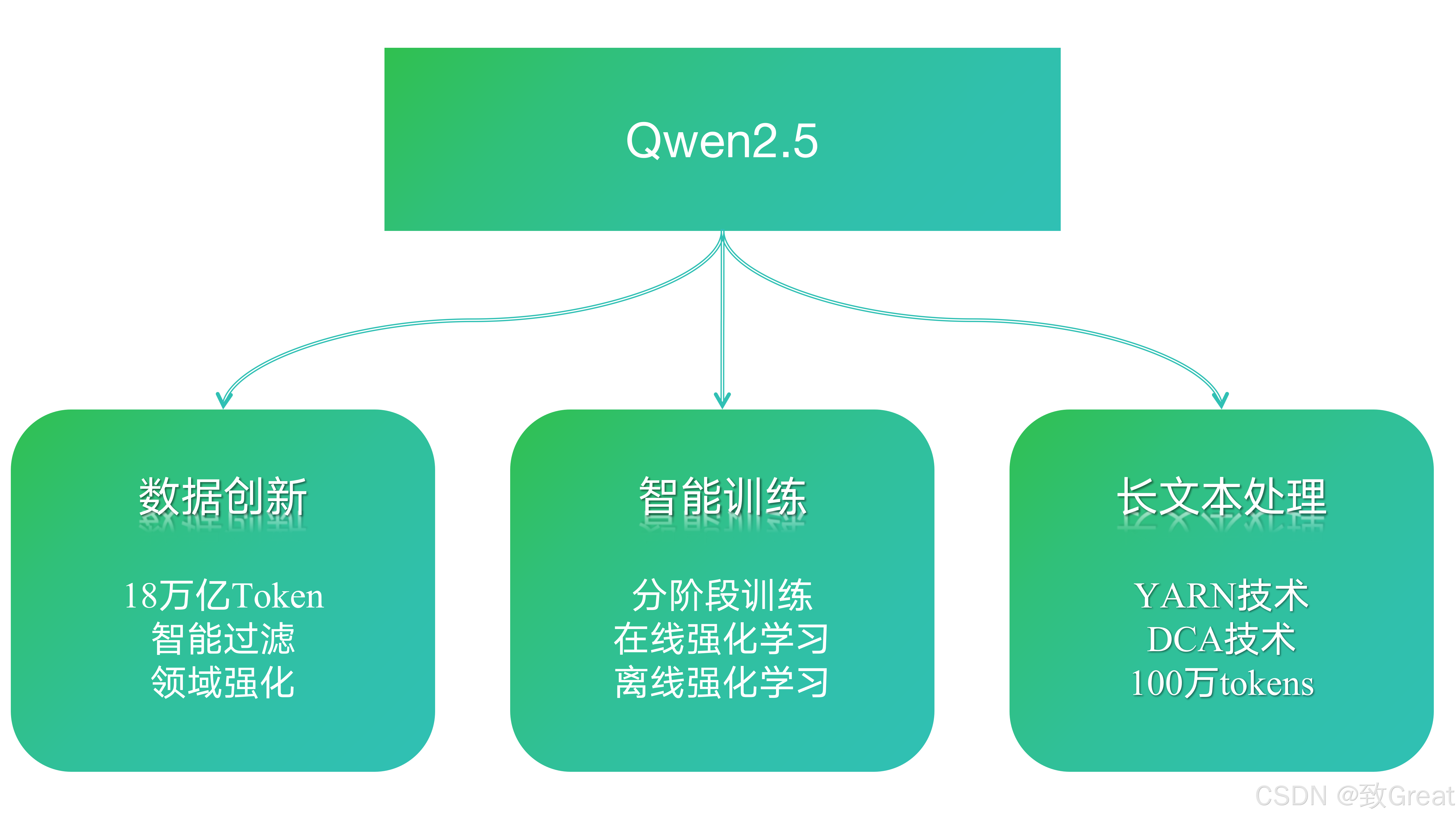
核心突破:
智能训练架构
- 采用"由浅入深"的分阶段训练
- 结合离线和在线强化学习
- 目标:让模型既精通基础任务,又能处理复杂场景
长文本处理能力
- 通过 YARN 和 DCA 技术实现突破
- Turbo 版本可处理 100万tokens
- 保持了短文本处理的高性能
高质量数据策略
- 智能过滤机制确保数据质量
- 重点强化数学和编程领域
- 使用专业模型优化合成数据


















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









