







上文书,我们讲到NV GPU的SM,SM的组件
(1)CUDA Core:向量运行单元 (FP32-FPU、FP64-DPU、INT32-ALU),这块最容易被混淆,CUDA Core来实现矩阵计算是用的向量化能力,直接矩阵对矩阵式用Tensor Core,这块后面会讲。另外,实际上Volta,也就是V100那个架构以后,因为FP32FPU和INT32ALU都是单独的独立出来了,所以严格说就没CUDA Core了,但是大家都这么叫也不改口了。
(2)Tensor Core:Tensor也就是张量运算单元(FP8、FP16、BF16、TF32、INT8、INT4)
(3)Special Function Units:特殊函数(超越函数和数学函数,反平方根、正余弦啥的)
(4)Warp Scheduler:线程束调度器
(5)Dispatch Unit:指令分发单元
(6)Multi level Cache:多级缓存(L0/L1 Instruction Cache、L1 Data Cache & Shared Memory)
(7)Register File:寄存器
(8)Load/Store:访问存储单元LD/ST(折腾io的)
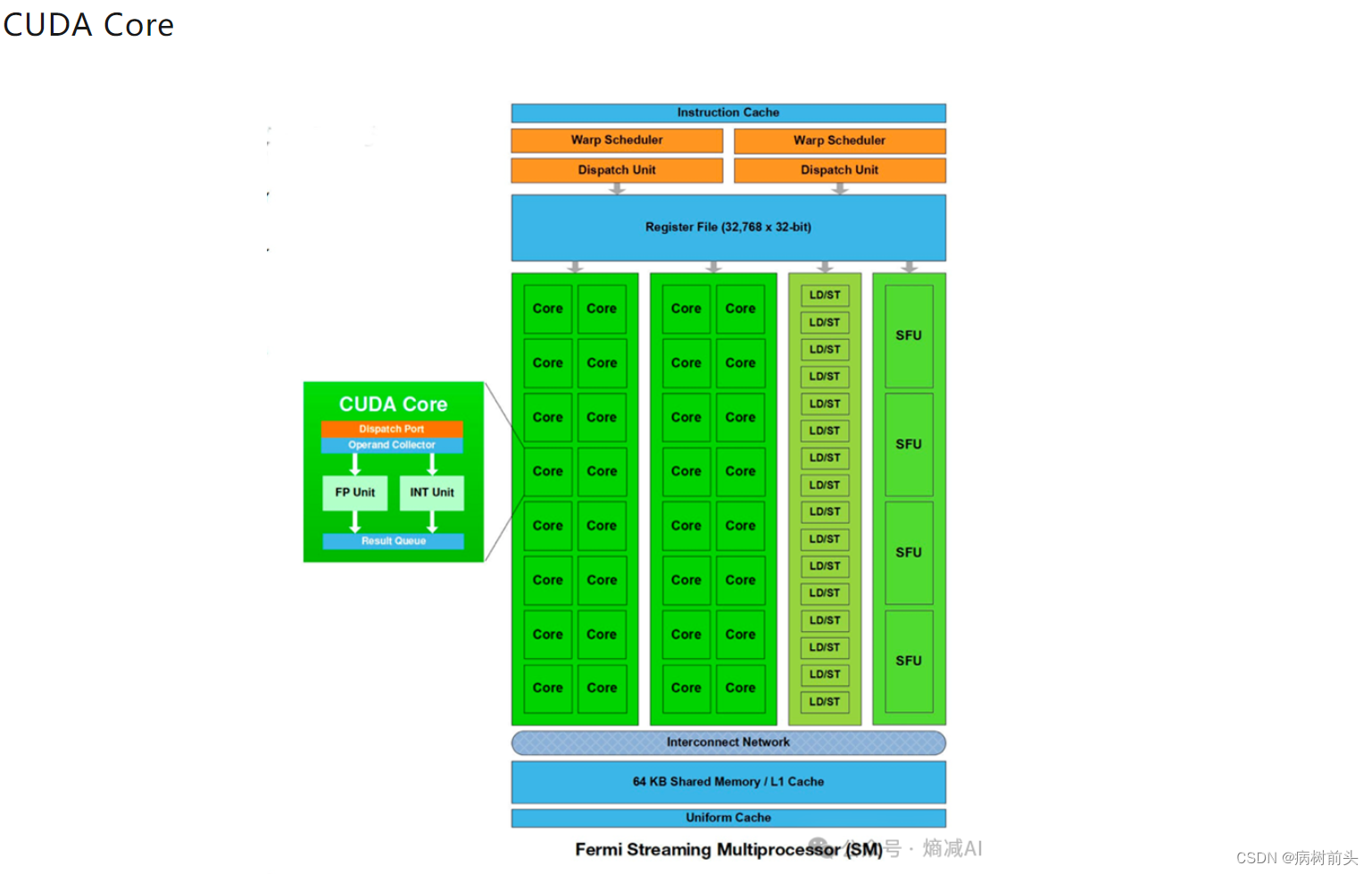
CUDA Core是在Fermi架构时候提出的,是最小的运算计算单元,每个 CUDA Core 含有一个整数计算单元ALU (Integer Arithmetic Logic Unit) 和一个浮点计算单元 FPU (Floating Point Unit) 。
如上文说的,Volta架构之后,CUDA Core其实都单立了,但是也保持着原来的叫法。为啥叫CUDA Core呢,就是给CUDA用的呗。
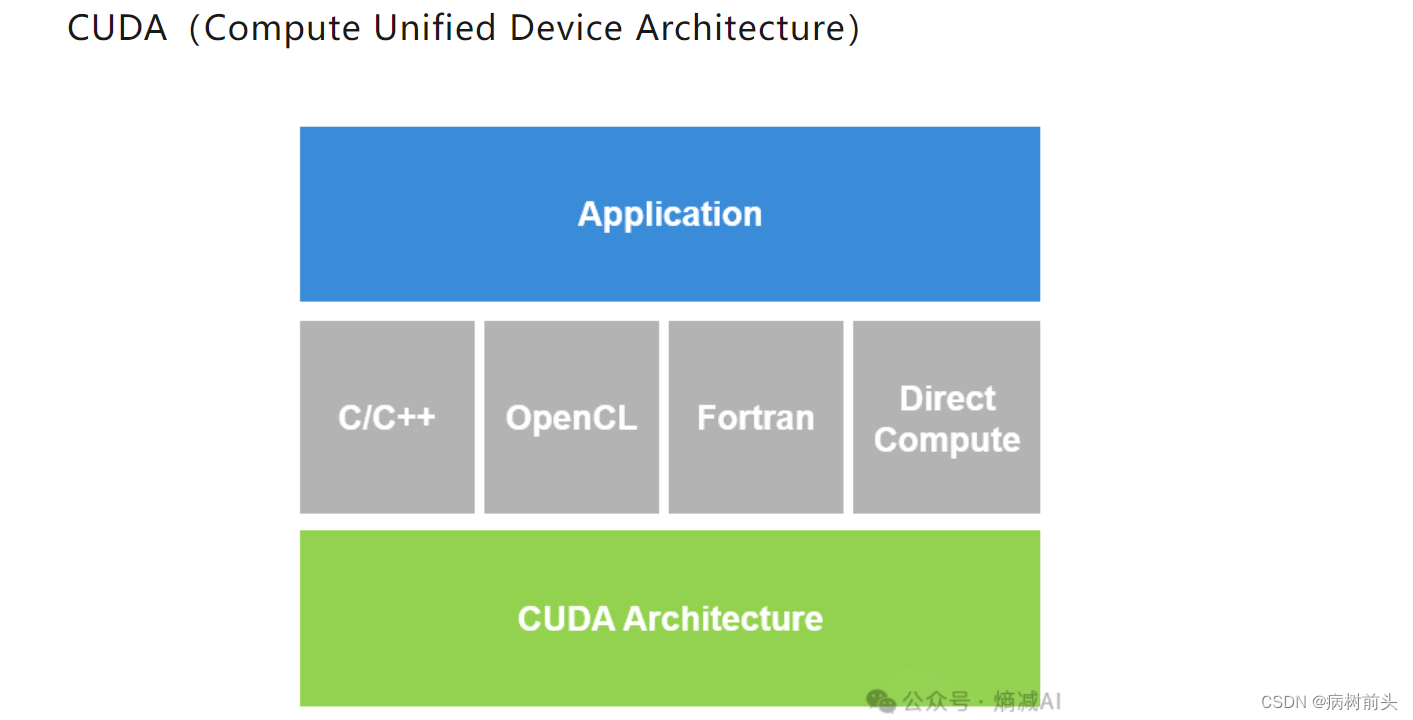
CUDA是2006年11月出的,到现在都小20年了,从某个角度上讲,它可能才是NV的护城河(当然真正护城河是因为它软硬结合,可是CUDA确实有点厉害,虽然一堆垃圾代码)???
简单说它就是NV自己的通用并行计算架构,是一种并行计算平台和编程模型,该架构使GPU能够解决复杂的计算问题,连接程序和GPU的核心,它一般情况用C来开发,3.0以后也提供了对其它编程语言的支持,如C/C++,Fortran等语言。还有pycuda的库,可以支持让python程序利用GPU来计算。
一般装CUDA也装一大堆东西,什么CUDA driver什么CUDA toolkit(里面有API和runtime),大多数情况,还得装cuDNN啥的,这些东西啥关系呢?
CUDA可以看作是一个工作包,包里可以有扳手,可以有钳子啥的。cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。它就相当于工作包里的工具,比如它就是个扳手。但是光有CUDA的工具包,没扳手,还是干不了活,想要在CUDA上运行深度神经网络,就要安装cuDNN。
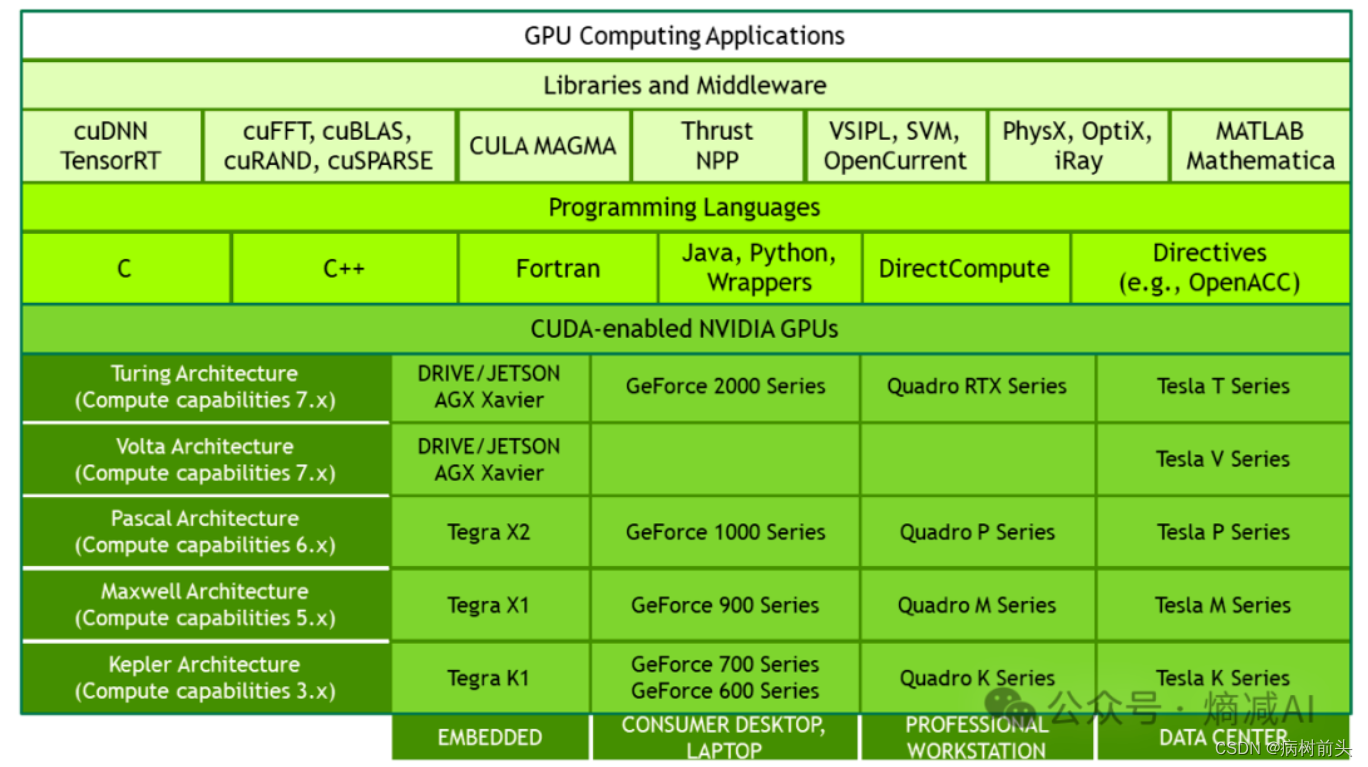
上图有点老,但是意思是对的 。另外还有除了编程接口(API)及其运行库(Runtime)、还有两个较高级别的通用数学库,即CUFFT 和 CUBLAS。 刚才讲了CUDA是工具包,是并行计算框架,那它的特点是什么呢?
Kernel
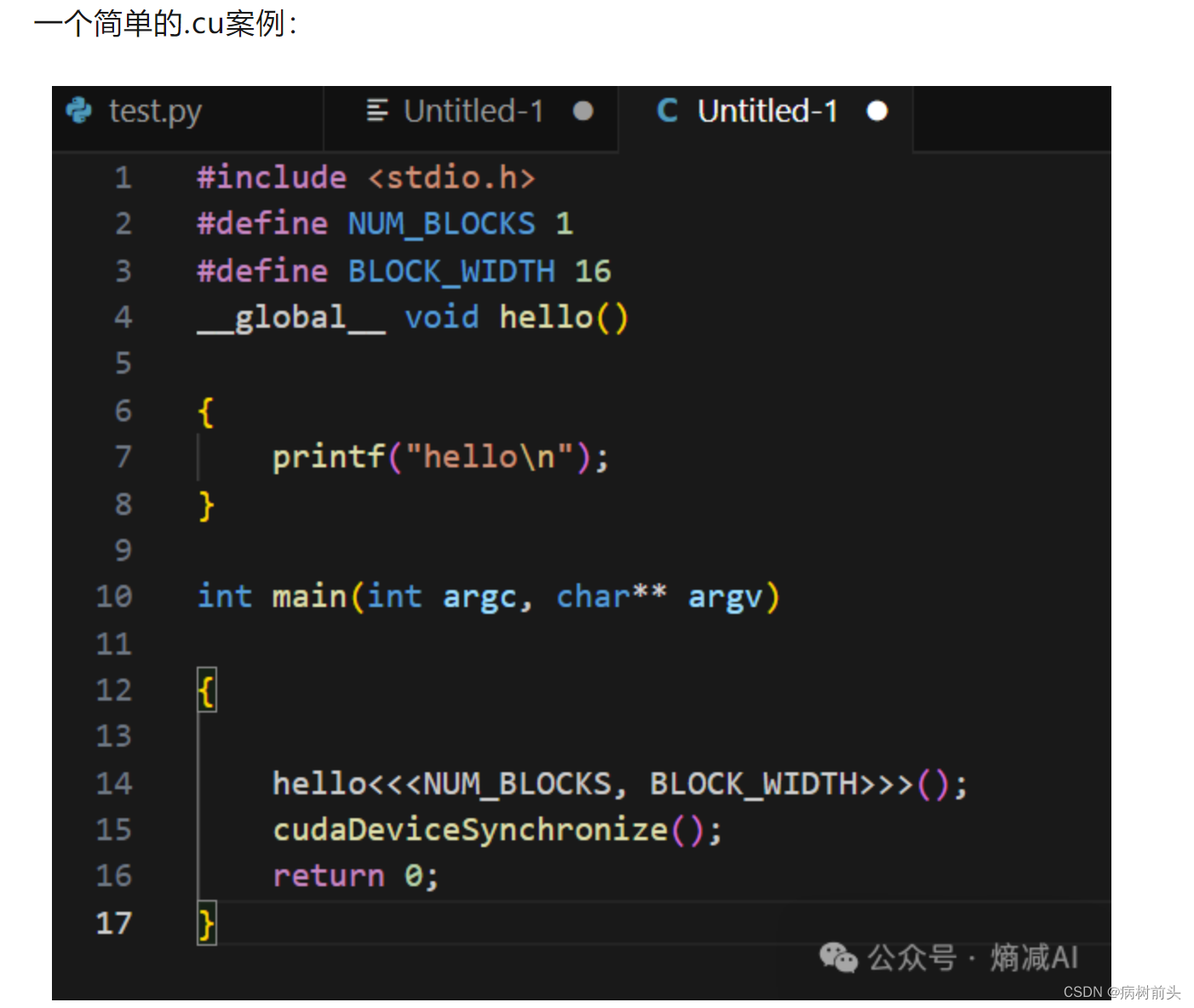
CUDA执行时最重要的一个流程是调用CUDA的核函数来执行并行计算,kernel是CUDA中的核心概念之一。
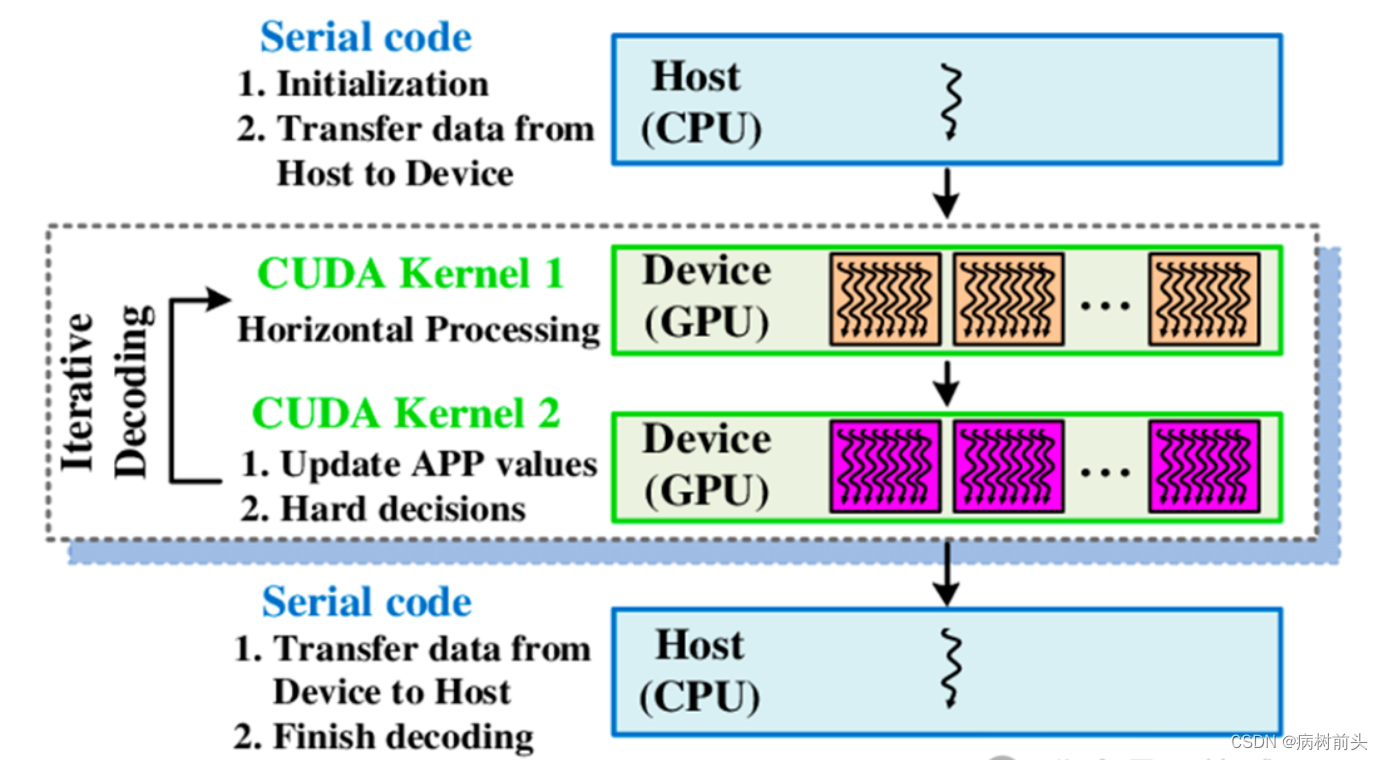
CUDA它肯定是给GPU用的,这个没问题,但是你安装CUDA的时候实际上不是在CPU上面吗。
如上图所示,CUDA有host和device的概念,在 CUDA程序构架中,Host 代码部分在CPU上执行,就是一般的C。当遇到程序要进行并行处理的,CUDA就会将程序编译成GPU能执行的程序,并传送到GPU,这个被编译的程序在CUDA里称做核(kernel),Device 代码部分在 GPU上执行。
CUDA里另外一个不次于kernel的概念就是三级线程管理
怎么个三级,Grid—> Block—>threads
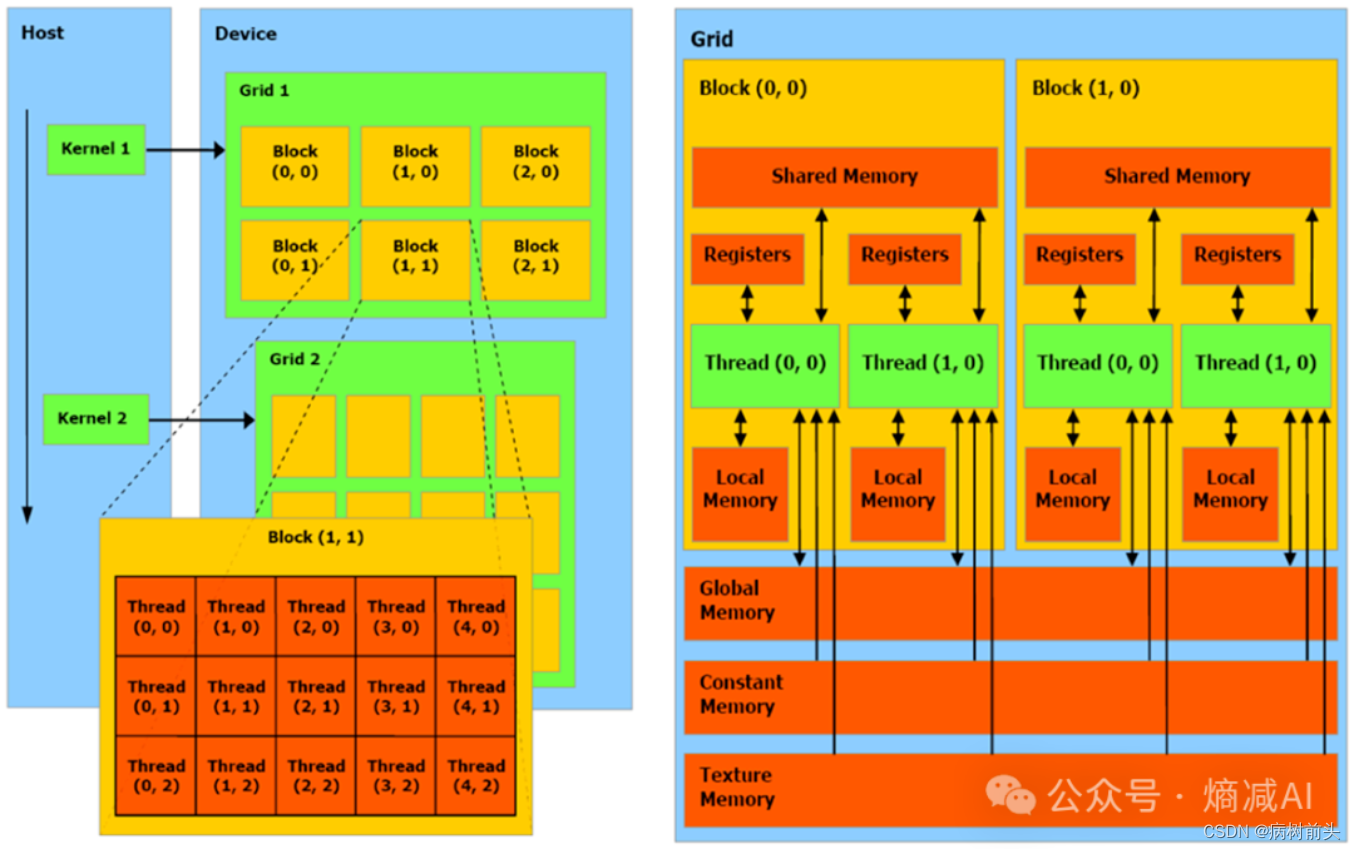
Grid
kernel 在 device上跑,实际上启动一大堆线程,一个 kernel 所启动的所有线程称为一个Grid,一个Grid的所有线程是共享一大段内存,也就是相同的全局内存(显存)空间。
Block
Grid再分下去就是block层级,block里面才是装的thread,也就是线程。虽然一个Grid里面的所有线程,都是共享全局显存地址空间,但是,block之间都是隔离的,自己玩自己的,并行执行(注意,不是并发),每个 block自己的共享内存(Shared Memory),里面的Thread 共享,别的block的thread不能来访问。
Thread
block 内部的 threads,怎么玩都可以了,可以同步,也可以通过 shared memory通信。
如果把GPU的组件和CUDA的通信体系做一个1:1的mapping的话,大概长这样
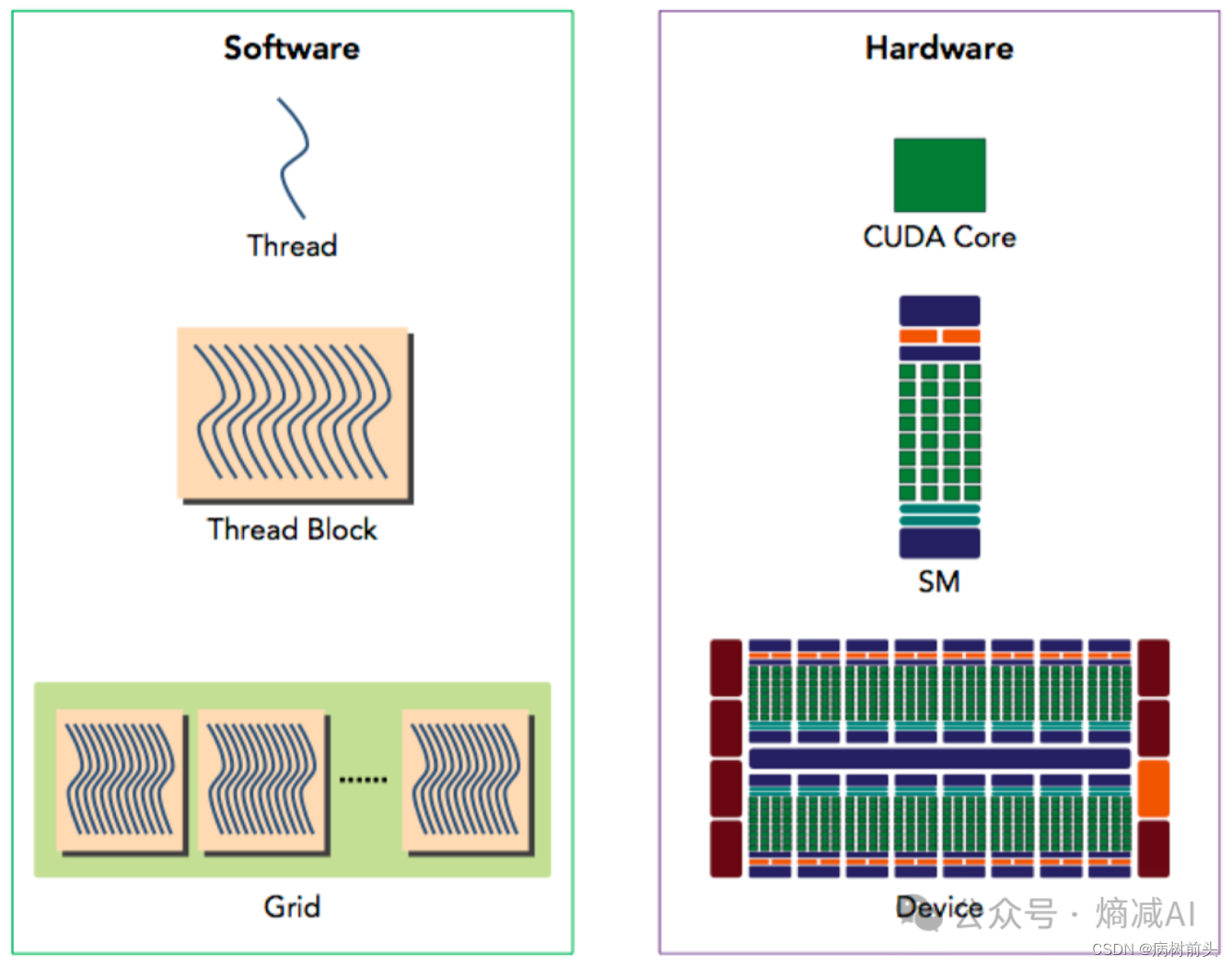
Grids是跑在Device(GPU)层级,block相当于包工头对应SM层级,而真正的干活的CUDA core呢,对应的就是拿到现成thread去执行了。
OK今天就讲这些,大概把CUDA的编程知识点和硬件的关联性给大家理了一下,我第一篇就说过,CUDA core对于矩阵计算,实际上可以认为是向量对向量的乘然后并行,(A矩阵的行向量,去乘B矩阵的列向量)这也是大部分的GPU,NPU执行矩阵计算的逻辑,那有没有更好的方式呢?那必须有,是什么呢?















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









