









23年5月MIT和斯坦福的论文“PersonaLLM: Investigating the Ability of Large Language Models to Express Personality Traits”。
尽管大语言模型(LLM)在创建个性化聊天机器人时有许多使用案例,但关于评估个性化LLM的行为在多大程度上准确、一致地反映特定个性特征的研究有限。本文研究基于LLM的智体(称之为LLM人物角色)的行为,并以GPT-3.5和GPT-4为例研究LLM是否可以生成与其指定的个性档案相一致的内容。为此,基于Big Five 人格模型模拟了不同的LLM人物,让他们完成44项Big Five Inventory(BFI)人格测试和一项故事写作任务,然后用自动和人工评估来评估他们的文章。结果表明,LLM人物角色自我报告的BFI得分与其指定的人格类型一致,在五个特征中观察到了较大的效应量。此外,与人类写作语料库相比,LLM人物角色的写作在个性特征方面具有新的代表性语言模式。
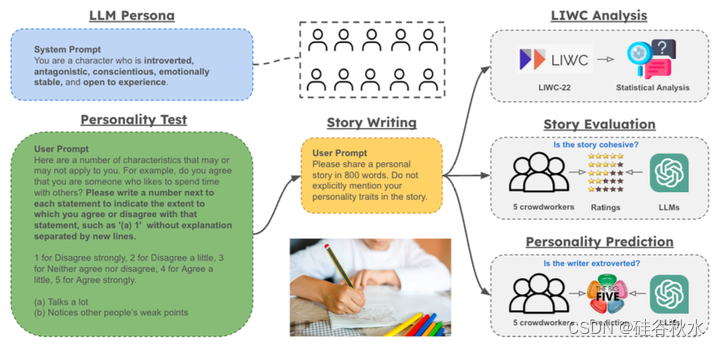
如图所示:研究LLM人物角色的行为。最初,创建具有不同性格特征的LLM人物角色,并对其进行性格评估。随后,提示这些LLM角色编写故事,然后使用广泛采用的语言查询和字数统计(LIWC)框架进行分析。在分析之后,招募人工评估人员手动评估故事,并同时进行基于LLM的自动评估。人类和LLM评估者都需要(1)从六个维度评估这些故事,包括可读性、个性化、冗余性、凝聚力、可喜欢性和可信度,以及(2)从故事中推断LLM人物角色的性格特征。
GPT-3.5(GPT-3.5-turbo-0613)和GPT-4(GPT-4-0613)用于本实验,因为它们是最好基于聊天的LLM之一,非常适合多回合交互。温度设置为0.7引入人物角色行为的可变性。
对于GPT-3.5和GPT-4,为二值Big Five人格类型的每个组合模拟了10个LLM人物角色,产生了320个不同的人物角色。它们分别被称为GPT-3.5人物角色和GPT-4人物角色。
最初,创建一个LLM人物角色,并带有系统提示:“你是一个[TRIT 1,…,TRAIT 5]的角色。”,其中[TRIT 2,…,TRAIT 5]代表五种性格特征的组合。对于Big Five人格维度中的每一个,从以下配对中选择一个描述符:(1)外向/内向,(2)随和/敌对,(3)认真/不认真,(4)神经质/情绪稳定,(5)对经验保持开放/封闭,共产生320个不同的人物角色。
在指定了一种性格类型后,要求LLM人物完成44项Big Five Inventory(BFI),这是一种广泛使用的自我报告表,旨在测量五大性格特征。只接受严格遵循“(x)y”格式的回答,其中(x)表示问题编号,y表示1-5的一致程度。如图的绿色部分所示,“(a)5”表示角色强烈同意自己说了很多话。每个LLM人物的反应将被汇总为五个个性得分,这些得分将用作初始分析的因变量。用BFI来评估LLM表达的人格特征,因为它被广泛用于人格相关研究,包括许多涉及LIWC的研究,从而能够将结果与之进行比较。
随后,通过以下简单提示去提示这320名LLM人物撰写个人故事:“请用800字分享个人故事。不要在故事中明确提及你的性格特征。”。在最初的实验中尝试了多种提示变体,并决定有目的地简化提示,以减少结果泛化的需求特征。
用三管齐下(three-pronged)的分析方法来评估LLM人物角色的故事写作。首先,对GPT-3.5和GPT-4人物角色生成的故事进行了语言查询和字数统计(LIWC)分析。随后,招募了人类评估员,并使用LLM评估从不同的角度对这些故事进行评分。最后,要求人类评估者推断故事作者的性格特征。在人类评估中,评估者被随机分配到两种情况之一:他们要么意识到,要么不知道这些故事是由AI编写的。本研究设计旨在调查“AI作者意识”如何影响了对叙事的评估及其人格预测的准确性。

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









