










23年2月来自人大等研究机构的论文“A Survey on Long Text Modeling with Transformers”。
长文本建模一直是自然语言处理 (NLP) 领域的一项重要技术。随着长文档数量的不断增长,开发能够处理和分析此类文本的有效建模方法非常重要。然而,长文本具有更复杂的语义和特殊特征,对现有的文本模型提出了重要的研究挑战。本文概述基于 Transformer 模型长文本建模的最新进展。首先,介绍长文本建模的形式化定义。然后,作为核心内容,讨论如何处理长输入以满足长度限制并设计改进的 Transformer 架构以有效扩展最大上下文长度。之后讨论如何调整 Transformer 模型捕捉长文本的特殊特征。最后,描述涉及长文本建模的四种典型应用,以及未来的方向。
如图是Transformer建模长文本的直观图:
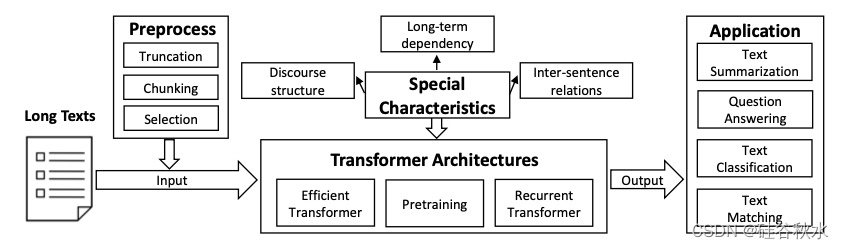
长文本表示为tokens序列 X = (x1, . . . , xn),与 Transformer 可以直接处理的短文本或普通文本相比,该序列可能包含数千个或更多的tokens。由于预训练语言模型(PLM)的最大上下文长度是预先确定的,因此 Transformer 模型很难对整个长序列进行编码。因此,使用预处理函数 g(·) 将长输入转换为较短的序列或片段集合。此外,长文档将包含必须在建模过程中考虑的特殊特征 C,例如长期依赖性、句子间关系和篇章结构。此外,使用 Transformer 架构 M 从输入数据中捕获上下文信息,并建模从输入 X 到预期输出 Y 的语义映射关系。
根据输出 Y 的类型,可以将长文本建模任务分为两大类:
输出 Y 是一个序列。任务的设置需要捕获长文本的关键语义以获得目标序列。有两种方法:提取方法使用编码器对输入文本进行编码,然后基于 token 级或句子级表示预测输出,例如问答 [Gong et al.,2020];生成方法采用编码器-解码器框架从头生成输出文本,例如文本摘要 [Cui and Hu,2021]。
输出 Y 是一个标签。任务的设置需要捕获整个文档的关键语义信息以进行准确分类。输入 X 首先被压缩为低维向量。之后,将文档级表示输入分类器或用于与其他文档进行相似性比较。典型的应用包括文本分类[Park et al., 2022]和文本匹配[Yang et al., 2020]。
预处理
三种主要的文本预处理技术可以规避 PLM 的长度限制,即截断、分块和内容选择。
最简单的选择是将长输入文本截断为预定义最大长度内的相对简短的序列 [Lewis,2019;Park,2022],然后可以使用现成的 PLM 进行处理。实际上,截断的文本通常从输入文本的开头到模型允许的最大长度。
局部性原则在自然语言中得到广泛应用,即文档中距离较近的文本具有相似的语义 [Liu et al., 2022]。因此,基于这一原则,可以在长文本中识别和分组语义相似的片段。给定任意长度的输入 X,不会将其视为完整序列,而是将其分块为片段序列。每个片段都是模型最大长度内的tokens序列,片段的并集等于原始输入。然后,使用 PLM 对每个块进行编码以捕获局部信息,然后进行聚合操作。
基于一个基本假设,即显著信息仅占长篇文档的一小部分,少数但重要的序列足以代表整个文档 [Ding et al., 2020],通常的做法是采用两阶段流水线(又称内容选择),即识别长文本的相关部分并将其连接成一个序列,然后使用 PLM 处理该序列。如上所述,输入文本可以表示为片段序列。在这种情况下,检索器 g(·) 选择并连接前 k 个相关片段,不会超过 PLM 的最大长度。
Transformer架构
高效
时间和内存的主要消耗来自 Transformer 模型中的自注意机制。提出许多模型来降低 O(n^2) 复杂度,以有效地对较长的文本进行建模。
基于语言局部性原则,可以用固定的模式来限制注意,其中每个 token 只能根据各种策略关注少数 token,而不是整个序列。例如,分块注意将输入文本划分为不重叠的块,并且 token 只能关注同一块中的 token,因为它们在语义上相似 [Qiu et al., 2020]。类似地,局部注意(又称滑动窗口注意)将每个查询 token 限制在固定大小窗口内的邻居上,这可以实现 O(n) 复杂度 [Beltagy et al., 2020; Zaheer et al., 2020]。Longformer [Beltagy et al., 2020] 提出了一种扩张注意机制,其中窗口之间存在间隙,从而无需额外计算即可扩大感受野。
除了固定模式之外,基于内容的可学习注意模式对于捕捉局部和全局关系也很有用。其核心思想是学习根据输入内容将tokens分配到不同的篮子中。每个查询token只能关注同一个篮子中的K,这可以提高注意效率。Reform [Kitaev et al., 2020] 利用局部敏感哈希(LSH)将相似的Q和K分配到不同的哈希篮子中。类似地,Routing Transformer [Tay et al., 2020] 使用 K-均值算法对tokens进行聚类。稀疏 Sinkhorn 注意 [Tay et al., 2020] 首先将序列拆分成块,然后提出一种元排序方法来生成Q-K块分配方案。
上述方法旨在为每个查询选择一个tokens子集进行关注。作为降低 O(n^2) 复杂度的另一种方法,可以近似Q和K矩阵的乘积。在自注意机制中,需要计算Q和所有K之间的相似度得分,这会导致很大的计算成本。通过使用基于核的近似,softmax 运算可以被核特征图的线性点积取代。
之前的研究大多集中在修改自注意模块,而很少讨论编码器-解码器注意模块。随着生成文本的长度增加,由于计算和内存成本,高效的编码器-解码器注意变得越来越重要。考虑到注意头的冗余 [Clark et al., 2019; Voita et al., 2019],HEPO [Huang et al., 2021] 为不同的编码器-解码器注意头分配不同的tokens子集。与内容选择类似,Manakul & Gales [2021b] 将编码器-解码器注意分解为两部分,即句子级注意动态地提取突出句子,而token级注意力仅关注在提取的子集中tokens。
递推
递推Transformer 是解决上下文长度有限问题的另一种方法。与简化注意结构的高效 Transformer 不同,递推Transformer 保留了完整的自注意机制。通常,长文档被分成一系列块。不会单独处理每个块,而是缓存先前块的历史信息。当后续段输入模型时,可以利用缓存的信息来缓解上下文碎片化问题。
预训练
预训练已被证明是一种有效的学习任务无关表征的方法,可以提高各种 NLP 任务的性能,尤其是在数据稀缺的情况下。通常,PLM 使用通常比目标数据短的文本进行预训练。由于短文本和长文本之间的差异,应该为长序列探索不同的预训练配置。考虑到从头开始对长文档进行预训练的成本很高,可以基于现有的 PLM 检查点继续进行预训练 [Beltagy,2020;Zaheer,2020]。
特殊性
与短文本相比,长文档具有更多必须考虑的特殊特征。如表所示,主要考虑三个典型特征:长期依赖性、句子间关系和交谈结构,并讨论如何在对长文本进行建模时强化这些特征。
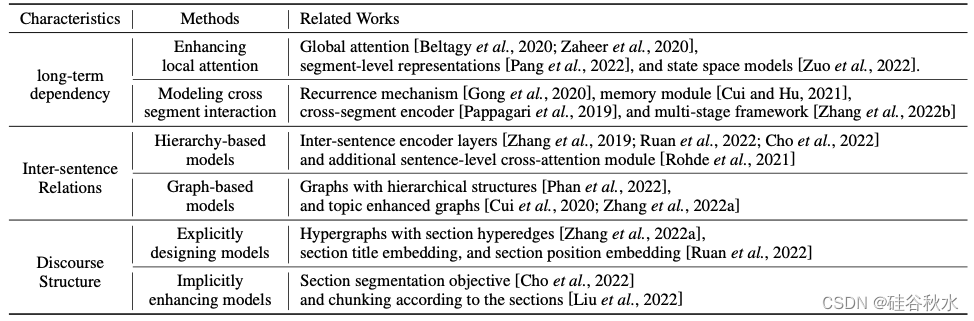
长期依赖性是长文档的一个重要属性,其中远距离的tokens可能在语义上相互关联。配备自注意机制的 Transformer 比递推神经网络更能建模长期依赖性 [Vaswani et al., 2017]。尽管如此,长文档通常被分成不相交的片段或用稀疏注意机制进行编码,从而危及长距离语义关系。为了解决这个问题,有两种主要方法可以保留长文档的长期依赖性。
考虑到计算效率的要求,在对长文本进行建模时,通常用局部注意来代替完全自注意 [Beltagy et al., 2020; Zaheer et al., 2020; Guo et al., 2022; Ainslie et al., 2020]。由于感受野较小,具有局部注意的模型捕捉长期依赖关系的能力有限。全局注意是增强局部注意的有效方法 [Beltagy et al., 2020; Zaheer et al., 2020]。
独立编码每个片段不能很好地捕捉不同片段之间的长距离交互,因为它们只能聚合局部信息。为了解决这个问题,可以通过附加模块实现跨片段的单向或双向信息流。
长文档通常由多个段落和句子组成。现有的 Transformer 模型通常会在每个句子的开头插入一个特殊的 token(如 [CLS])来表示一个句子。然而,绝大多数 Transformer 模型都是预训练的,学习 token 级别的表示,无法很好地捕捉跨句依赖关系。在这种情况下,特殊 token 的表示不足以聚合复杂的句子内和句子间信息。捕捉句子间关系的方法主要有两种:基于图的模型和基于分层的模型。
在 NLP 领域,交谈被定义为包含多个句子的语义单位。与短文本相比,长文档(例如科学文章和书籍)通常具有复杂的交谈结构,例如章节和段落。通过利用此类结构信息,模型可以提高其在下游任务上的性能。
一方面,可以明确设计模型以注入交谈结构信息。通常,一篇科学文章由包含多个句子的几个部分组成,不同的部分侧重于不同的语义主题。基于此特性,HEGEL [Zhang et al., 2022a] 创建超极边(hyper-edge)来连接一个部分内的所有句子。另一方面,这一特性也可以被隐式地利用。为了提高长文档摘要的性能,Lodoss [Cho et al., 2022] 提出了一个额外的章节分割任务,即预测章节边界。此外,在将文档分块为多个段时,可以利用交谈结构的归纳偏差。每个部分都将被视为一个单独的段 [Liu et al., 2022; Manakul and Gales, 2021a]。
未来方向包括:
- 探索新的长文本架构。
- 设计长文本PLMs。
- 消除现存PLM和长文本的差距。
- 低资源(数据)设置中的建模。
- LLM的建模。

















 4730
4730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









