









22年3月来自Cornell大学、Meta AI和哥本哈根大学的论文“Visual Prompt Tuning”。
一种调优预训练模型的操作涉及更新所有主干参数,即全微调。 本文介绍了视觉提示调优(VPT)作为视觉中大规模 Transformer 模型全面微调的高效且有用的替代方案。 受高效调优大语言模型的启发,VPT 在输入空间中仅引入少量(不到模型参数的 1%)可训练参数,同时保持模型主干冻结。 通过对各种下游识别任务的大量实验,与其他参数高效调优的协议相比,VPT 实现了明显性能提升。 最重要的是,在许多情况下,VPT 在模型容量和训练数据规模方面甚至优于全微调,同时降低了每个任务的存储成本。
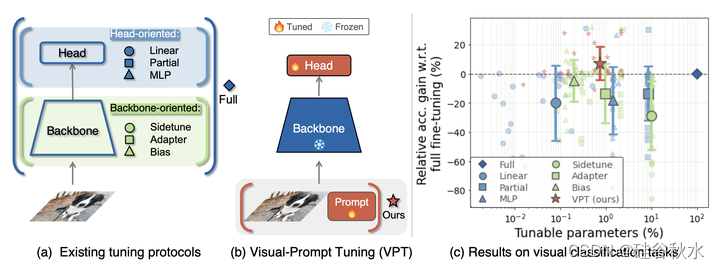
如图所示是视觉提示调优(VPT)与其他迁移学习方法的比较。 (a) 当前的迁移学习协议根据调整范围进行分组:全微调、面向头网络和面向主干网络的方法。 (b) VPT 在输入空间中添加了额外的参数。 © 采用预训练的 ViT-B 主干,不同方法在各种下游分类任务上的性能,其中标注了平均值和标准差。 VPT 优于全微调 24 个案例中的 20 个,同时只用整个模型不到 1% 的参数。
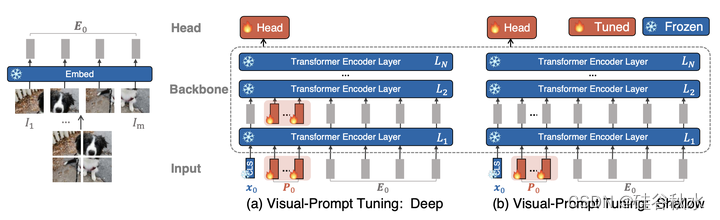
给定一个预训练的 Transformer 模型,在 Embed 层之后的输入空间中引入一组 p 个 d-维的连续嵌入,即提示。 在微调期间,仅更新特定于任务的提示,而 Transformer 主干保持冻结状态。下图是VPT的概述。 其中探索了两种变型:(a)在每个 Transformer 编码器层输入(VPT-deep),添加一组可学习参数; (b) 将提示参数只插入到第一层输入(VPT-shallow)。 在下游任务的训练过程中,仅更新提示和线性头的参数,而整个 Transformer 编码器被冻结。

















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









