










21年3月来自清华,北京智源、MIT和Recurrent AI(清华和CMU的AI学者成立的公司)的论文“GPT Understands, Too“,提出P-tuning这个调优方法。
虽然采用传统微调的 GPT模型 未能在自然语言理解(NLU)上取得优异的结果,但在 NLU 任务上用一种P - tuning方法,可以让GPT优于或与类似大小的 BERT相媲美—— 它采用可训练的连续提示嵌入。 在知识探测 (LAMA) 的基准上,最好的 GPT 恢复了 64% (P@1) 的世界知识,而在测试期间没有提供任何额外文本,这把之前的最佳成绩大幅提高了 20+ 个百分点。 在 SuperGlue 基准测试中,GPT 在监督学习中的性能与类似大小的 BERT 相当,有时甚至更好。 重要的是,P-tuning 还提高了 BERT 在小样本和监督设置中的性能,同时大大减少了对提示工程的需求。
给定一个预训练的语言模型 M,一系列离散输入token X= {x0, x1, …, xn} 将被映射到输入嵌入 {e(x0), e(x1),…。 …, e(xn)} 。在特定场景中,在上下文X的条件下,经常使用一组目标token y 的输出嵌入进行下游处理。 例如,在预训练中,X指的是未屏蔽的token,y指的是屏蔽[MASK]的token; 在句子分类中,X指的是句子token,而y通常指的是[CLS]。
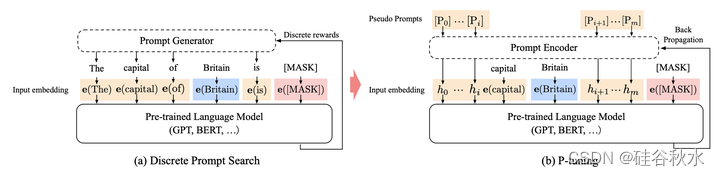
提示 p 的功能,是将上下文X、目标 y 及其本身,组织成模板 T。如图所示,在预测一个国家首都的任务中(LAMA-TREx P36),模板可能是“英国的首都是 [MASK]。” ,其中“……的首都是……”是提示符,“英国”是上下文,“[MASK]”是目标。 提示可以非常灵活,甚至可以将它们插入上下文或目标中。令 V 记作语言模型 M 的词汇表,[Pi] 记做模板 T 中的第 i 个提示token。给定模板 T,与传统的离散提示相比,P-tuning 将 [Pi] 视为伪token,并将模板映射到可训练的嵌入张量。 这样就能够找到更好的连续提示,超出M的原始词汇V所能表达的范围。 最后,利用下游损失函数L,可以可微分地优化连续提示hi。
在图中,给定上下文(蓝色区域,“英国”)和目标(红色区域,“[MASK]”),橙色区域指的是提示token。 图(a)中,提示生成器仅接收离散奖励; 相反,在图(b)中,伪提示和提示编码器以可微分的方式进行优化。 有时,添加一些与任务相关的锚tokens(例如图(b)中的“首都”)会带来进一步的改进。
虽然训练连续提示的想法很简单,但在实践中,它面临两个优化挑战:
1)离散性:M的原始词嵌入e在预训练后已经变得高度离散;如果 h 用随机分布初始化,然后用随机梯度下降(SGD)进行优化,这已被证明只能改变小邻域内的参数(Allen-Zhu 2019),同时优化器很容易陷入局部极小值 ;
2)关联:另一个问题是,直观上提示嵌入值 hi 应该相互依赖而不是独立; 需要某种机制来将提示嵌入相互关联。
鉴于这些挑战,在 P-tuning 中,使用提示编码器将 hi 建模为序列,该提示编码器由一个非常精简的神经网络组成,可以解决离散性和关联问题。 在实践中,作者选择LSTM,并用 ReLU 激活的两层MLP来鼓励离散性。虽然 LSTM头的使用确实为连续提示的训练添加了一些参数,但 LSTM头比预训练模型小了几个数量级。 而且,在推理中,只需要输出嵌入h并且可以丢弃LSTM头。
此外,添加少量锚token有助于 SuperGLUE 基准测试中的某些 NLU 任务。 例如,对于 RTE 任务,标记“?” 在提示模板中“[PRE][prompt tokens][HYP]?[prompt tokens][MASK]”是专门添加的锚token,对性能影响很大。 通常这样的锚单词表征每个组件,在本例中为“?” 表明“[HYP]”充当询问部分。

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









