










22年8月来自谷歌和Everday Robots的论文“Do As I Can, Not As I Say: Grounding Language in Robotic Affordances”。
大语言模型可以编码大量有关世界的语义知识。这些知识对于旨在按照自然语言表达的高级、时间扩展指令采取行动的机器人非常有用。然而,语言模型的一个显著弱点是它们缺乏现实世界的经验,这使得很难利用它们在给定的具身中进行决策。例如,要求语言模型描述如何清理洒出物,可能会产生合理的叙述,但它可能不适用于需要在特定环境中执行此任务的特定智体(例如机器人)。
本文提议通过预训练技能提供现实世界落地,这些技能用于约束模型,才能提出既可行又适合上下文的自然语言动作。机器人可以充当语言模型的“手和眼睛”,而语言模型则提供有关该任务的高级语义知识。将低级技能与大语言模型相结合,这样语言模型提供有关复杂且时间延长指令程序执行的高级知识,而与这些技能相关的价值函数则提供将这些知识连接到特定物理环境的落地。在许多现实世界的机器人任务上评估了该方法,展示了对现实世界基础的需要,并且这种方法能够在移动机械手上完成长期、抽象、自然语言指令。
最近,在训练大语言模型 (LLM) 方面取得的进展已使系统能够根据提示生成复杂文本、回答问题,甚至就各种主题进行对话。这些模型从网络上挖掘的文本语料库中吸收了大量知识,那么编码在这些模型中的日常任务知识,是否可以被机器人用来在现实世界中执行复杂任务?但是,具身智体如何提取和利用 LLM 的知识来完成物理落地任务呢?
这个问题提出了一个重大挑战。LLM 并非扎根于物理世界,它们不会观察到其生成对任何物理过程的影响 [1]。这不仅会导致 LLM 犯下在人们看来不合理或滑稽的错误,还会对特定物理情况来说以毫无意义或不安全的方式解释指令。如图显示了一个例子——一个能够执行“拿起海绵”或“走向桌子旁”等技能的厨房机器人可能会被要求帮忙清理洒落的东西(“我把饮料洒了,你能帮忙吗?”)。语言模型可能会用对机器人来说不可行或无用的合理叙述来回应。如果场景中没有真空吸尘器或机器人无法使用真空吸尘器,那么“你可以尝试使用吸尘器”就是不可能的。通过提示工程,LLM 可能能够将高级指令拆分为子任务,但如果没有机器人能力的背景以及机器人和环境的当前状态,它就无法做到这一点。

注:图中LLM 尚未与环境互动,也未观察其反应结果,因此无法扎根于现实世界。SayCan 通过预训练技能的价值函数为 LLM 奠定基础,让它们能够对机器人执行现实世界、抽象、长远的命令。
受此示例的启发,本文研究如何提取 LLM 中的知识以使具体智体(例如机器人)能够遵循高级文本指令的问题。机器人配备了一套学习技能,用于能够进行低级视觉运动控制的“原子”行为。利用这样一个事实:除了要求 LLM 简单地解释指令之外,还可以用它来评估单个技能在完成高级指令方面取得进展的似然。然后,如果每项技能都有一个affordance函数来量化从当前状态成功的可能性(比如一个学习的价值函数),那么它的价值就可以用来衡量该技能的似然。这样,LLM 描述每项技能在完成指令的贡献概率,而affordance函数描述了每项技能成功的概率——将两者结合起来就可以得出每项技能成功执行指令的概率。affordance函数让 LLM 了解当前场景,而将完成情况限制在技能描述范围内,可以让 LLM 了解机器人的能力。此外,这种组合可以产生一个完全可解释的步骤序列,机器人将执行这些步骤来完成一个指令——即一个通过语言表达的可解释规划。
虽然大语言模型可以利用从大量文本中学到的丰富知识,但它们不一定会将高级命令分解为适合机器人执行的低级指令。如果问一个语言模型“机器人如何给我拿一个苹果”,它可能会回答“机器人可以去附近的商店帮你买一个苹果”。虽然这个回答对于提示来说是一个合理的补充,但它不一定对具身智体具有可操作性,因为具身智体可能只有一组狭窄而固定的能力。因此,为了使语言模型适应问题陈述,必须以某种方式告知它们,特别希望将高级指令分解为可用的低级技能序列。一种方法是仔细的提示工程 [5, 11],这是一种将语言模型诱导到特定响应结构的技术。提示工程在上下文文本(“提示”)中为模型提供示例,这些示例指定模型模拟的任务和响应结构。然而,这不足以将输出完全限制为具身智体可接受的原始技能,有时它确实会产生不可接受的动作或语言,这些动作或语言的格式不易解析为单独的步骤。
通过输出的语言模型分配概率,对语言模型进行评分,为受限响应开辟了一条途径。一个语言模型表示潜在完成的分布 p(wk|w0~k-1),其中 wk 是出现在文本中第 k 个位置的单词。虽然典型的生成应用程序(例如,对话智体)从该分布中采样或解码最大似然完成,但也可以使用该模型对候选补全进行评分。在 SayCan 中,正式给定一组低级技能 Π、它们的语言描述 lΠ 和指令 i,计算技能 lπ 的语言描述朝执行指令 i 前进的概率:p(lπ|i),这对应于潜在补全的模型查询。根据语言模型,最佳技能通过 lπ = argmax lπ 计算。一旦选定,该过程就会通过迭代选择技能并将其附加到指令中继续进行。实际上,在这项工作中,将规划构建为用户和机器人之间的对话,其中用户提供高级指令(例如,“您如何给我拿可乐罐?”),语言模型以明确的顺序响应(“我会:1. lπ”,例如,“我会:1. 找到一个可乐罐,2. 拿起可乐罐,3. 把它带给你”)。
如图所示:查询一个价值函数模块 (a),根据当前观察形成动作基元的价值函数空间。可视化“拾取”价值函数,在 (b) 中,“拾起红牛罐”和“拾起苹果”具有高价值,因为两个物体都在场景中,而在 © 中,机器人正在空旷的空间中导航,因此所有拾取动作均未获得高价值。

这得到了可解释性的额外好处,因为该模型不仅输出生成响应,而且还给出许多可能响应的似然概念。如图显示了将 LLM 强制为一个语言模式的过程,其中任务集是低级策略能够掌握的技能,提示工程显示了规划示例以及用户和机器人之间的对话。通过这种方法,能够有效地从语言模型中提取知识,但它留下了一个主要问题:虽然以这种方式获得的指令解码始终包含机器人可用的技能,但这些技能不一定适合在机器人当前所处的特定情况下执行所需的高级任务。例如,如果我要求机器人“给我拿一个苹果”,如果视野内没有苹果或者它手里已经有一个苹果,则最佳技能集会发生变化。

SayCan 的关键思想,是通过价值函数(affordance函数)为大语言模型打下基础,这些affordance函数可以捕获特定技能在当前状态下能够成功的对数似然。给定技能 π、其语言描述 lπ 及其对应的价值函数(该价值函数提供 p(cπ|s,lπ),即在状态 s 下完成 lπ 所描述技能的概率),形成一个 affordance 空间 {p(cπ|s,lπ)}π。该价值函数空间捕获所有技能的affordance [12]。对于每项技能,affordance 函数和 LLM 概率相乘,最终选择最可能的技能,即 π = argmax p(cπ|s,lπ)p(lπ|i)。一旦选择了技能,智体就会执行相应的策略,并修改 LLM 查询以包含 lπ,然后再次运行该过程,直到选择终止 token(例如“完成”)。整个过程在算法 1 中进行描述。这两个镜像过程共同导致了 Say-Can 的概率解释,其中 LLM 提供了技能对高级指令有用的概率,而affordance提供了成功执行每项技能的概率。将这两个概率结合在一起,可以得出该技能进一步执行用户命令的高级指令的一个概率。

要实例化 SayCan,必须为其提供一组技能,每个技能都有一个策略、一个价值函数和一个简短的语言描述(例如,“拿起罐子”)。这些技能、价值函数和描述可以通过多种不同的方式获得。在实现中,要么使用基于图像的行为克隆(遵循 BC-Z 方法 [13])来训练单个技能,要么使用强化学习(遵循 MT-Opt [14])来训练单个技能。无论技能的策略是如何获得的,都使用通过时域差(TD)备份训练的价值函数作为该技能的affordance模型。虽然BC 策略在数据收集过程的当前阶段实现了更高的成功率,但 RL 策略提供的价值函数作为将控制能力转化为对场景语义理解的抽象至关重要。为了分摊训练多项技能的成本,分别使用多任务 BC 和多任务 RL,其中不是针对每项技能训练单独的策略和价值函数,而是训练以语言描述为条件的多任务策略和模型。注:此描述仅对应于低级技能 - SayCan 中 LLM 的作用,仍然是解释高级指令并将其分解为单独的低级技能描述。
为了根据语言来调节策略,使用预训练的大型句子编码器语言模型 [15]。在训练期间冻结语言模型参数,并使用传入每项技能的文本描述所生成的嵌入。这些文本嵌入用作策略和价值函数的输入,用于指定应执行哪些技能。由于用于生成文本嵌入的语言模型不一定与用于规划的语言模型相同,因此 SayCan 能够利用适合不同抽象级别的不同语言模型——理解针对多种技能的规划,而不是更细致地表达特定技能。
实验中,在两个办公室厨房环境中使用移动机械手和一组物体操纵和导航技能评估 SayCan。如图显示了环境设置和机器人。用办公室厨房中常见的 15 种物体和 5 个具有语义的已知位置(两个柜台、一张桌子、一个垃圾桶和用户位置)。在两种环境中测试方法:一个真实的办公室厨房和一个模拟厨房的模拟环境,后者也是训练机器人技能的环境。所使用的机器人是来自 Everyday Robots 的移动机械手,带有 7 自由度手臂和两指夹持器。除非 LLM 另有说明,否则使用的 LLM 是 540B PaLM [9]。将 PaLM 的 SayCan 称为 PaLM-SayCan。

如图是PaLM-SayCan的决策可视化:

RL 策略网络
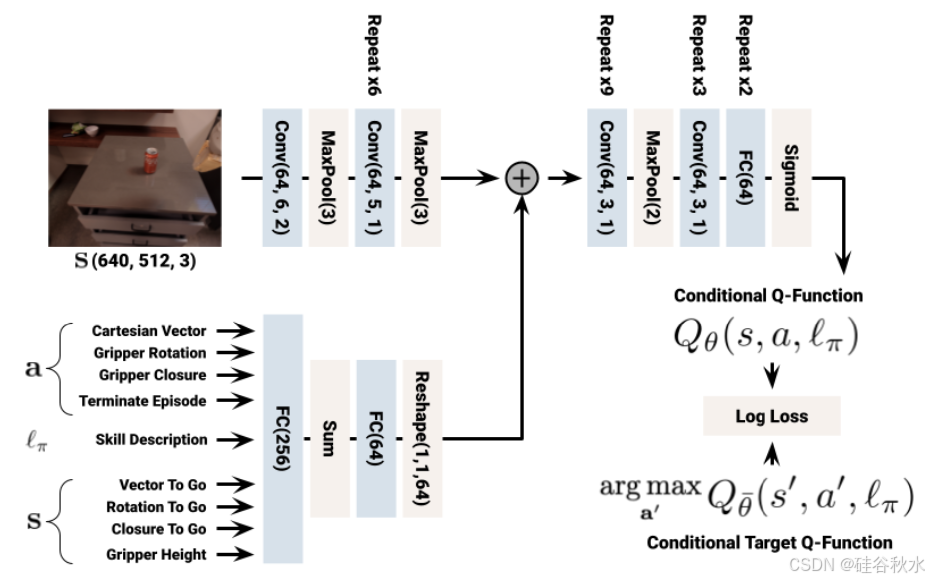
除了在 BC 设置中使用演示之外,还使用 RL 学习语言条件价值函数。为此,用技能和环境的模拟版本补充真实机器人队列。为了缩小模拟与现实之间的差距,通过 RetinaGAN [16] 转换机器人图像,使其看起来更逼真,同时保留通用目标结构。为了学习语言条件 RL 策略,在 Everyday Robots 模拟器中使用 MT-Opt [14],使用上述模拟-到-现实的转换。利用模拟演示来提供初步成功,从而引导模拟策略的性能,然后通过模拟中在线数据收集不断提高 RL 性能。应用标准图像增强(随机亮度和对比度)以及随机裁剪。640 x 512 输入图像左右填充 100 像素,上下填充 40 像素,然后裁剪回 640 x 512 图像,允许随机空间移动而不限制视野。使用与 MT-Opt 类似的网络架构。
RL 模型使用 16 个 TPUv3 芯片训练,耗时约 100 小时,同时使用 3000 个 CPU 工作者(worker)池来收集情节,并利用另外 3000 个 CPU 工作者来计算目标 Q 值。在 TPU 之外,计算目标 Q-值允许 TPU 仅用于计算梯度更新。情节奖励稀疏且始终为 0 或 1,因此使用对数损失来更新 Q 函数。使用优先经验重放 [88] 训练模型,其中情节优先级经过调整,鼓励每个技能的重放缓冲区训练数据接近 50% 的成功率。情节按其优先级按比例采样,定义为 1 + 10 · |p − 0.5|,其中 p 是重放缓冲区中情节的平均成功率。
下图是RL中的网络结构细节:
BC 策略网络
使用 68000 个远程操作演示,这些演示是在 11 个月内用 10 个机器人组成的团队收集的。操作员使用 VR 头戴式控制器来跟踪他们的手部运动,然后将其映射到机器人的末端执行器姿势上。操作员还可以使用操纵杆来移动机器人的底座。用 276000 个学习策略的自主情节扩展了演示数据集,这些情节后来被成功过滤并包含在 BC 训练中,从而产生了另外 12000 个成功情节。为了进一步处理数据,还要求评估者将情节标记为不安全(即,如果机器人与环境发生碰撞)、不受欢迎(即,如果机器人扰动了与技能无关的物体)或不可行(即,如果技能无法完成或已经完成)。如果满足任何这些条件,则情节将被排除在训练之外。
为了在现实世界中大规模学习语言调节的 BC 策略,在 BC-Z [13] 的基础上构建类似的策略网络架构。它使用 MSE 损失对连续动作组件进行训练,使用交叉熵损失对离散动作组件进行训练。每个动作组件的权重均等。使用标准图像增强(随机亮度和对比度)以及随机裁剪。640 x 512 输入图像从左到右填充 100 像素,从上到下填充 40 像素,然后裁剪回 640 x 512 图像,允许随机空间偏移而不限制视野。为了在训练性能下降可忽略不计的情况下加快迭代速度,图像输入被下采样为一半大小(256 x 320 图像)。affordance价值函数使用全尺寸图像进行训练,因为在学习 Q(s, a, lπ) 时,一半大小的图像效果不佳。 BC模型采用16块 TPUv3 芯片进行训练,训练时间约27小时。
如图是BC的网络结构细节:


















 663
663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









