










24年1月来自上海AI实验室、南京大学、Monash U、香港大学、南洋理工和中科院深圳高等研究院的论文“InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation”。
InternVid 是一个以视频为中心的大规模多模态数据集,可以学习强大且可迁移的视频文本表征,实现多模态理解和生成。InternVid 数据集包含超过 700 万个视频,时长近 76 万小时,产生了 2.34 亿个视频片段,并附有总计 41 亿个单词的详细描述。其开发一种可扩展的方法,使用大语言模型 (LLM) 自主构建高质量的视频文本数据集,从而展示其在大规模学习视频语言表征方面的功效。具体来说,利用多尺度方法来生成与视频相关的描述。此外,提出 ViCLIP,一种基于 ViT-L 的视频文本表征学习模型。通过对比学习在 InternVid 上学习,该模型展示领先的零样本动作识别和具有竞争力的视频检索性能。
下图是 InternVid 的示例(给出每个视频片段的三帧)、相应的生成字幕和 ASR 转录本。在字幕中,用蓝色突出显示名词,用绿色突出显示动词。非英语转录本使用 LLM [1] 翻译成英语。
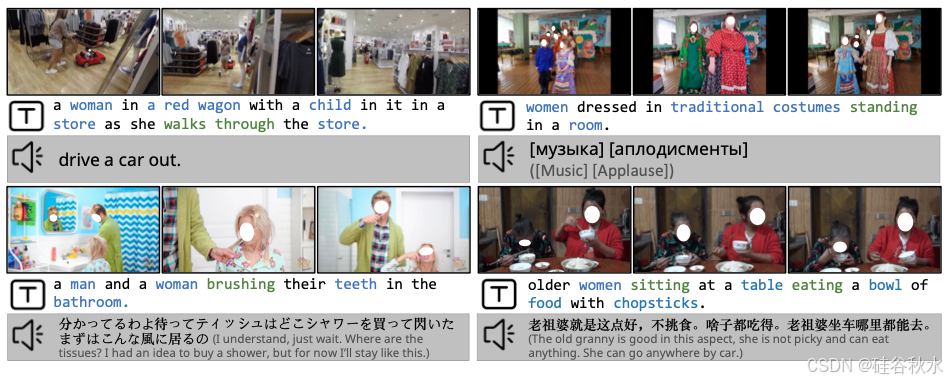
大规模高质量视频文本数据集是开展大规模视频-语言学习及相关任务的前提。构建此数据集的三个关键因素:大量的时域动态、丰富多样的语义以及强大的视频-文本相关性。为了确保较高的时间动态,收集使用基于动作/活动查询词去检索的视频。为了获得丰富多样的语义,不仅抓取不同类别的热门视频,还刻意增加从不同国家和语言收集的数据比例。为了加强视频文本相关性,使用图像字幕和语言模型从特定帧的注释中生成视频描述。
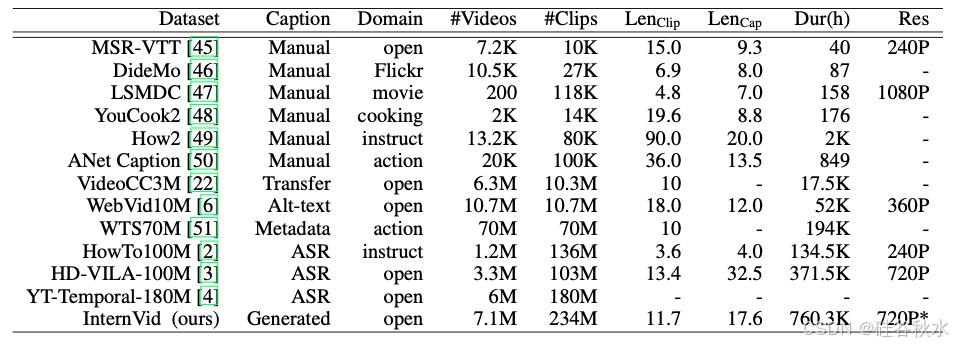
如下表是 InternVid 的统计数据及其与现有视频语言数据集的比较。 *在 InternVid 中,大多数视频(约 85%)为 720P,其余视频为 360P 至 512P。
从 YouTube 收集视频,考虑到其数据的多样性和丰富性,以及它对学术用途的支持。总共获得了 700 万个公开的 YouTube 视频,平均时长为 6.4 分钟,涵盖 16 个主题。创建 YouTube 视频 ID 数据库并排除任何已存在于公开数据集(2023 年 4 月之前发布)中的视频来确保数据集的唯一性。数据管理策略是双重的。一方面,从新闻、游戏等类别中选择热门频道和相应的热门或高评分视频,从而得到 200 万个视频。另一方面,创建一个与动作/活动相关的动词列表。通过它,以及选择检索的热门视频获得 510 万个视频。
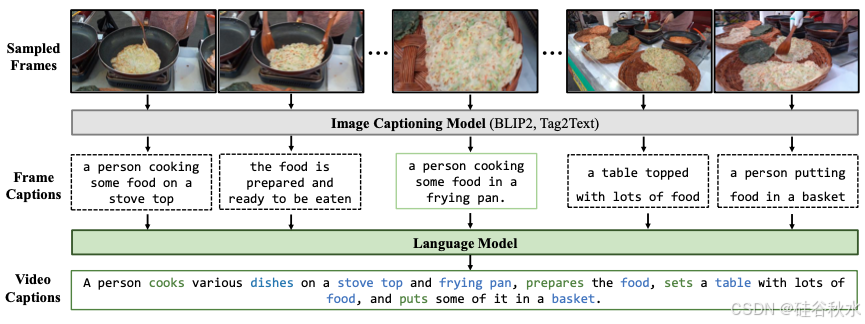
为了生成可扩展、丰富且多样化的视频字幕,采用了一种多尺度方法,包含两种不同的字幕策略,如图所示。在更精细的尺度上,专注于视频片段中的常见目标、动作和场景描述来简化视频字幕制作过程。故意忽略复杂的细节,例如细微的面部表情和动作以及其他细微的元素。在较粗的尺度上,采用 [60] 中的单帧偏差假设,仅对视频的中心帧制作字幕。鉴于关注的是经过场景分割过滤的简短片段(大约 10 秒),大多数视频主要显示一致的目标,而外观没有显著改变。这避免从图像角度处理视频时的身份保留问题。从技术上讲,在更精细的尺度上采用了轻量级图像字幕模型 Tag2Text [61],以逐帧的方式描述低 fps 的视频。然后,使用预训练语言模型 [62, 63] 将这些单独的图像字幕合成为综合视频描述。在较粗略的尺度上,用 BLIP2 [64] 为视频的中间帧添加说明。注:图中粗尺度和细尺度的字幕分别用绿色和深绿色标记。
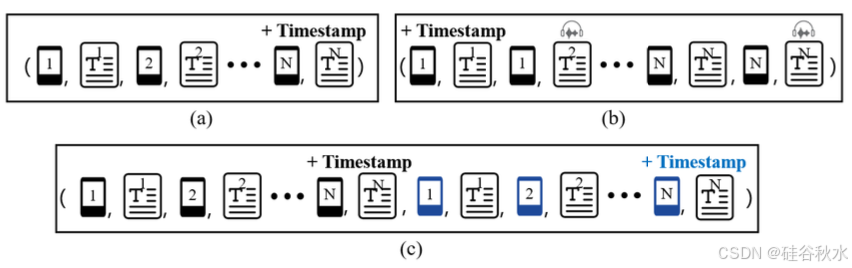
利用创建的视频字幕,可以开发一个集成的视频文本数据集,用于上下文视频学习,使基于视频的序列模型无需额外训练即可执行新任务。先前的研究,如 Flamingo [7, 8]、Kosmos-1 [65] 和 Multimodal C4 [66],证实了对交错的图像文本序列进行预训练可产生显著的多模态上下文能力。本文创建 InternVid-ICL,其中包含 7.1M 个交错的视频文本数据对。其中提出三种不同的方法来组织剪辑及其字幕:如图所示
• 根据同一视频中的时间顺序按顺序排列剪辑及其描述,如图 (a) 所示。
• 将 ASR 文本添加到所使用的剪辑(除了其字幕),增强交错视频文本条目的多样性,如图 (b) 所示。
• 连接两个交错的多模式项目来扩展方法 1,创建一个以视频为中心的对话,模拟涉及多个视频的用户查询,如图(c)所示。
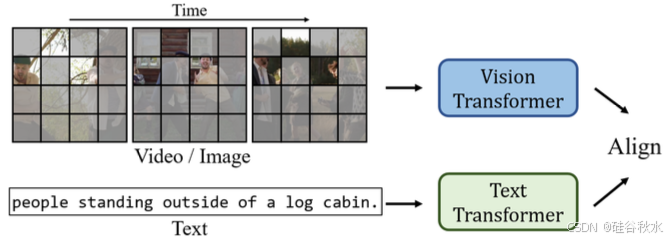
基于 CLIP [67],制作了一个简单的视频文本预训练基线 ViCLIP。它由视频编码器 (ViT) [68] 和文本编码器组成,如图所示。两个模块均从相应的 CLIP 组件初始化。将视频编码器中的原生注意更新为时空注意,同时保留其他设计元素。为了高效学习,在预训练中对视频应用了掩码。优化目标是输入视频和文本嵌入之间的对比损失。
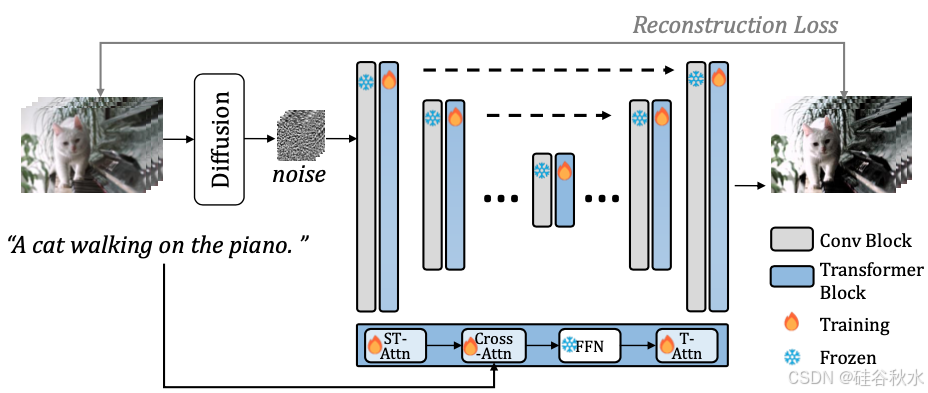
视频生成采用 [80] 中的时空建模方法,并基于 [76] 的工作构建文本-到-视频生成基线。该方法包括一个带有Transformer的 U-Net,对其潜变量进行建模,使用交错时空注意 (ST-Attn)、视觉文本交叉注意、前馈网络 (FFN) 和时间注意 (T-Attn),如图所示。为了将 [76] 中的二维卷积层调整为三维,将 3×3 核扩展为 1×3×3 核。还将原始的空间注意扩展为时空注意。用所有文本-到-图像扩散模型参数初始化基线,而新添加的时间注意层使用默认参数。

















 1758
1758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









