










24年11月来自斯坦福、西北大学、亚马逊公司和MIT的论文“Embodied Agent Interface: Benchmarking LLMs for Embodied Decision Making”。
目的是评估大语言模型 (LLM) 在具身决策中的表现。虽然大量的工作已经利用 LLM 在具身环境中进行决策,但仍然缺乏对其性能的系统了解,因为它们通常应用于不同的领域、用于不同的目的,并且基于不同的输入和输出构建。此外,现有的评估往往仅仅依赖于最终的成功率,这使得很难确定 LLM 缺少什么能力以及问题出在哪里,这反过来又阻碍了具身智体有效和有选择地利用 LLM。为了解决这些限制,提出一个泛化接口 (具身智体接口),支持各种类型任务的形式化和基于 LLM 模块的输入输出规范。具体来说,基于此能够统一 1)涉及状态和时间扩展目标的广泛具身决策任务,2)四个常用的基于 LLM 决策模块:目标解释、子目标分解、动作排序和转换建模,以及 3)一组细粒度指标,将评估分解为各种类型的错误,例如幻觉错误、affordance错误、各种类型的规划错误等。总体而言,基准对 LLM 在不同子任务中的表现进行全面的评估,找出 LLM 赋能的具身 AI 系统优势和劣势,并为在具身决策中有效和有选择地使用 LLM 提供了见解。
大语言模型 (LLM) 已成为构建具身决策智体的强大工具,这些智体能够遵循人类的指令(例如“清洁冰箱”、“擦亮家具”)并通过在各种数字和物理环境中的一系列动作实现指定目标 [1–3]。尽管有许多关于其成功的报道,但对 LLM 在具身决策方面的全部能力和局限性的理解仍然有限。现有的评估方法无法提供全面的见解,原因有三个主要限制:1)缺乏具身决策任务的标准化,2)LLM 可以与之交互或为其实现的模块,以及 3)缺乏超越单一成功率的细粒度评估指标。具身智体接口就是提出来应对这些挑战。
(1)目标规范的标准化:希望具身智体能够实现目标。然而,即使是类似的任务,不同领域的目标规范和智体成功评估标准也存在很大差异。例如,BEHAVIOR [4] 专注于实现满足某些状态目标的状态(例如,如图中的“未染色(冰箱)”),而 VirtualHome [5] 通过对动作施加时间顺序约束来使用时间扩展目标。具身智体接口实现了一种通用的以目标为中心的状态和动作表示,其中目标的状态、关系和动作以抽象语言术语表示(如图所示)。将目标描述为线性时间逻辑 (LTL) 公式,它定义了轨迹上的任务成功标准。LTL 可以指定基于状态和时间扩展的目标,并允许对目标进行其他解释。
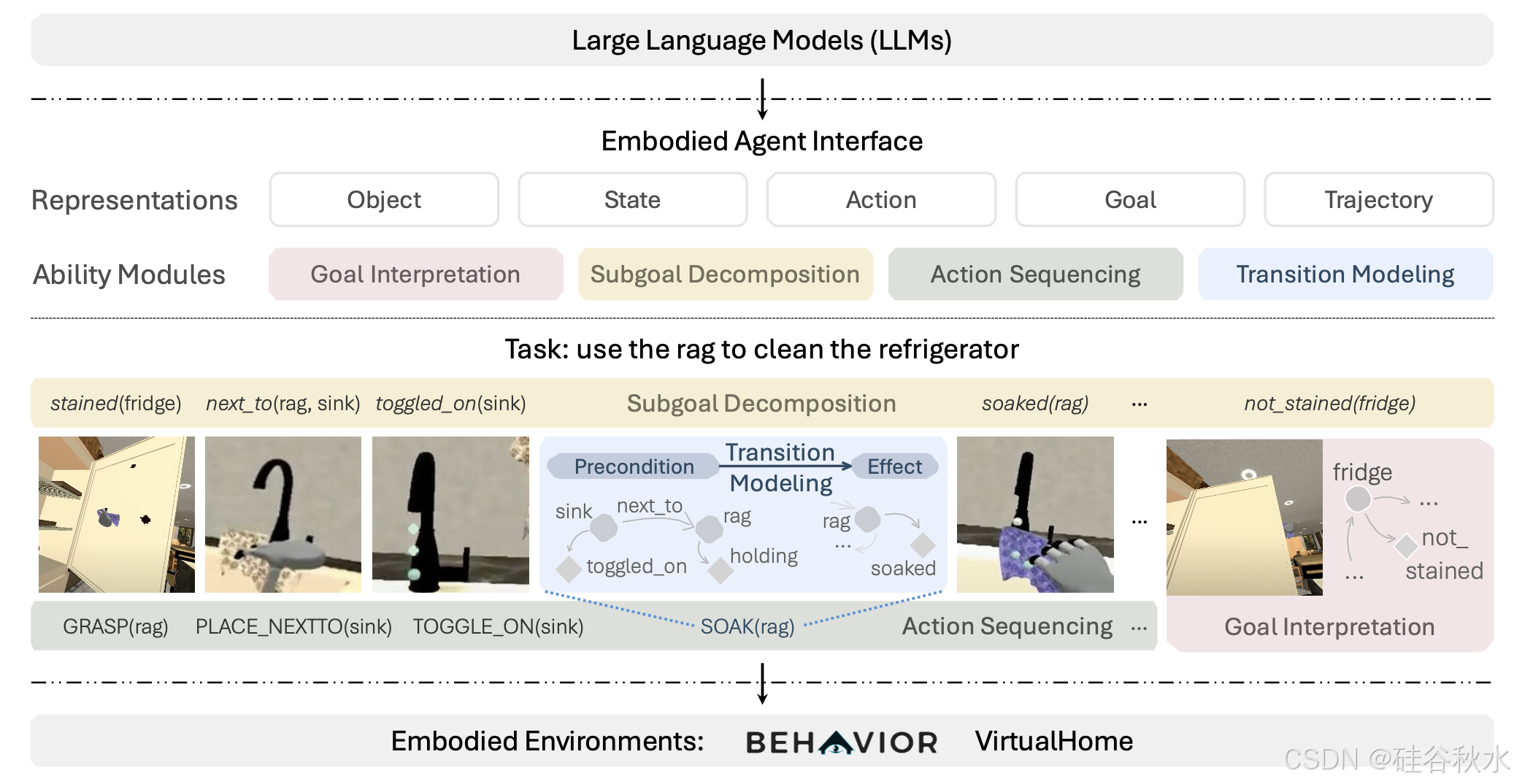
(2)模块和接口的标准化:现有的基于LLM具身智体框架通常会根据额外知识和外部模块的可用性做出不同的假设。例如,Code as Policies [6] 和 SayCan [2] 在给定一组基本技能的情况下利用 LLM 进行动作排序,而 LLM+P [7] 使用 LLM 进行目标解释,并使用具有给定域定义的 PDDL 规划器生成规划;Ada [8] 利用 LLM 以 PDDL 生成高级规划域定义,并使用低级规划器生成控制命令。因此,他们为 LLM 模块定义了不同的输入输出规范,使得比较和评估变得具有挑战性。在基于目标中心和基于 LTL 的任务规范之上构建的具身智体接口中,形式化基于 LLM 具身决策中的四个关键能力模块,如上图所示:目标解释、子目标分解、动作排序、转换建模。形式化 LLM 可用于与环境中的其他模块交互的输入输出规范。
这种模块化接口自动实现不同 LLM 模块和外部模块的集成。如图显示四个能力模块的输入和输出公式。以子目标分解为例,该模块采用初始状态(例如,冰箱最初被弄脏)和任务目标(例如,清洁冰箱),并要求 LLM 生成子目标轨迹(例如,首先将布浸湿,然后智体拿着布,接着智体在冰箱旁边,最后,冰箱被清洁)。

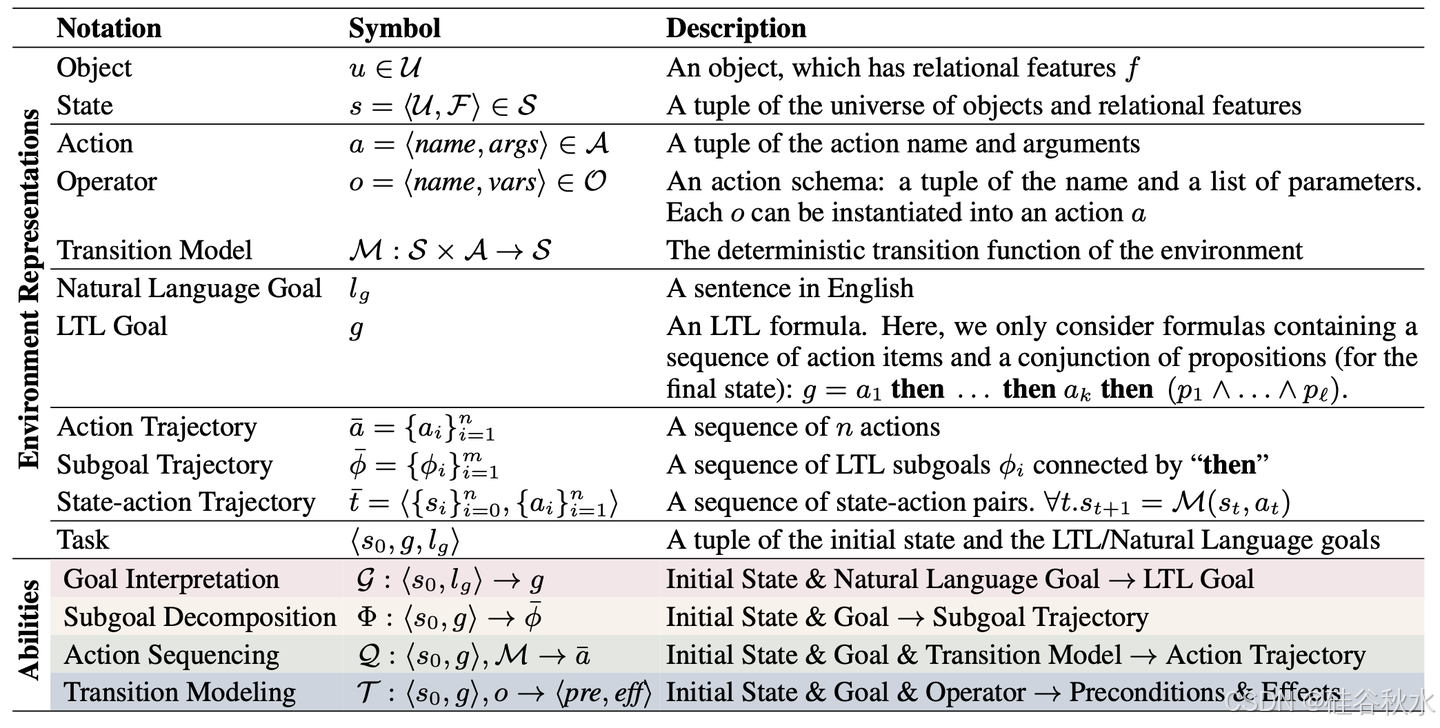
正式定义和符号可在下表中找到。
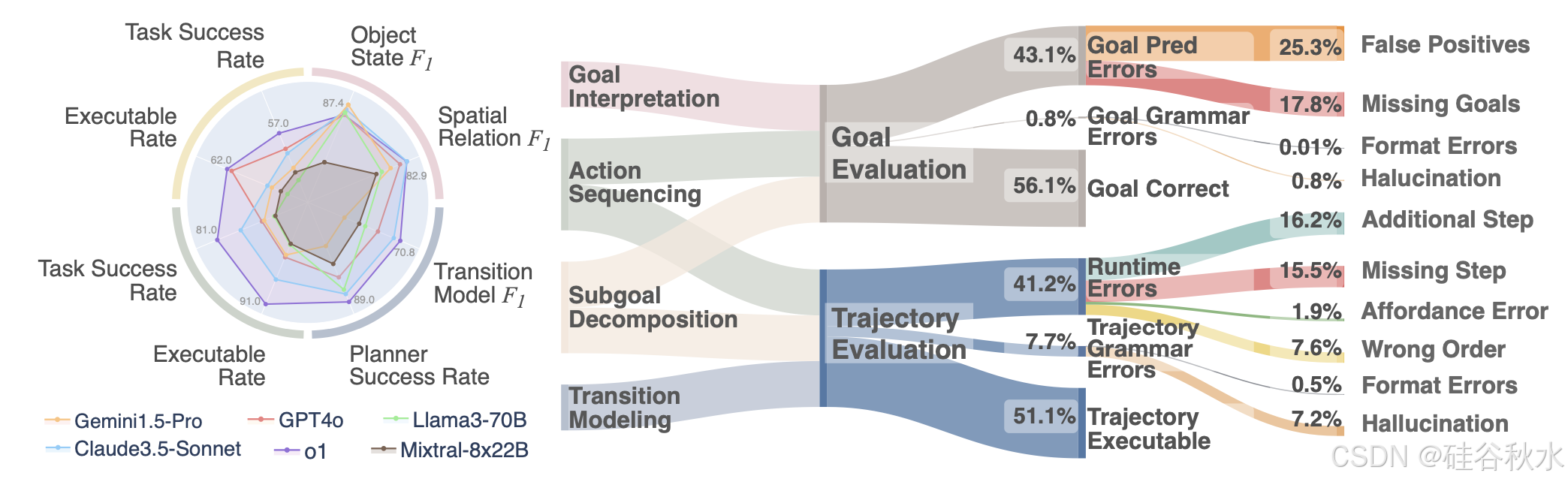
(3) 评估覆盖面广、指标细粒度:目前对具身决策的 LLM 评估过于简单,通常侧重于单个任务的成功率。最近的工作 LOTA-Bench [9] 旨在分解评估,但仅限于生成动作序列,不支持分析细粒度的规划错误。具身智体接口利用以目标为中心和分解的状态和动作表示,实现一组细粒度的评估指标,旨在自动定位不同类型的错误,例如幻觉错误、不同类型的规划错误(例如,目标affordance错误、错误的动作顺序等)。下图说明了 GPT-4o 在两个模拟器上四个不同能力模块上犯的不同类型错误。具体来说,评估每个模块的两个方面:轨迹评估,检查生成的规划是否可以在模拟器中执行,以及目标评估,确保规划实现正确的结果。目标评估适用于目标解释、行动排序和子目标分解,而轨迹评估适用于行动排序、子目标分解和转换建模。
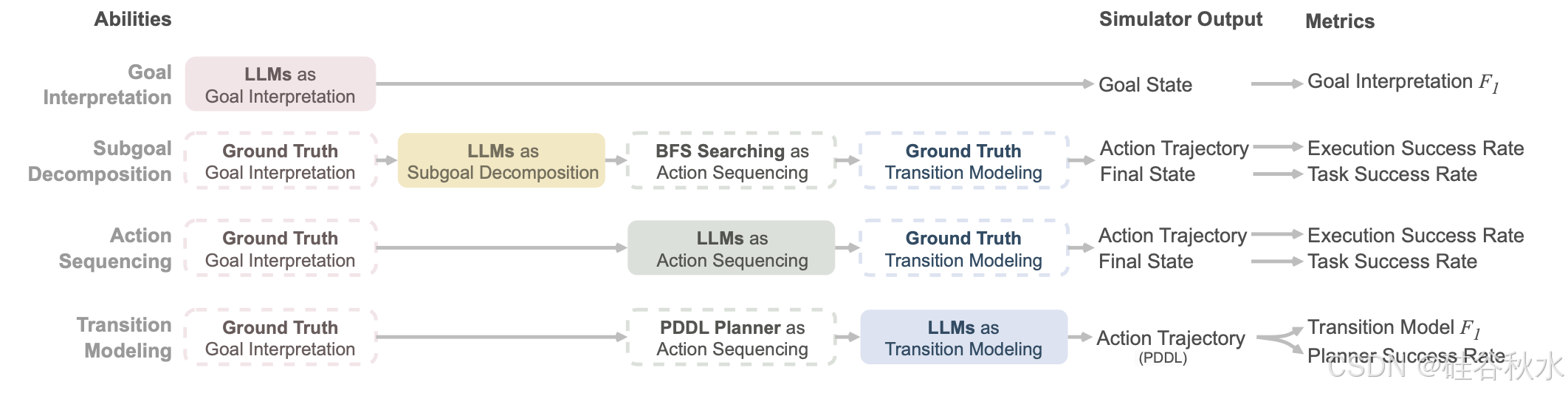
如图所示四种能力的评估流程概述。对于每个能力模块,为了对其进行全面评估,将这个单个模块隔离出来,由 LLM 处理,同时使用现有数据或工具处理其他模块。请注意,流程包括目标解释、实现目标的操作排序以及预测每个操作如何操作环境状态的转换建模。评估子目标分解是一项挑战,因为没有统一的标注策略就无法直接评估它。为了解决这个问题,采用广度优先搜索 (BFS) 来识别实现每个子目标的潜在动作序列,能够将状态轨迹转换为可以在模拟器中评估的可执行动作序列。转换建模评估带来了另一个挑战,首先标注 F1 的转换模型,然后使用 PDDL 规划器来验证支持潜在规划的可行性。
与一般的语言模型相比,具身智体具有三个关键的新能力,包括与环境交互、目标驱动和执行决策以实现目标,如图所示。具身决策的系统评估应涵盖三个方面,即标准化界面、目标表示和评估指标。具身智体界面专注于目标驱动评估、标准界面和模块以及广泛的评估覆盖范围和细粒度指标,可解决传统评估的局限性。
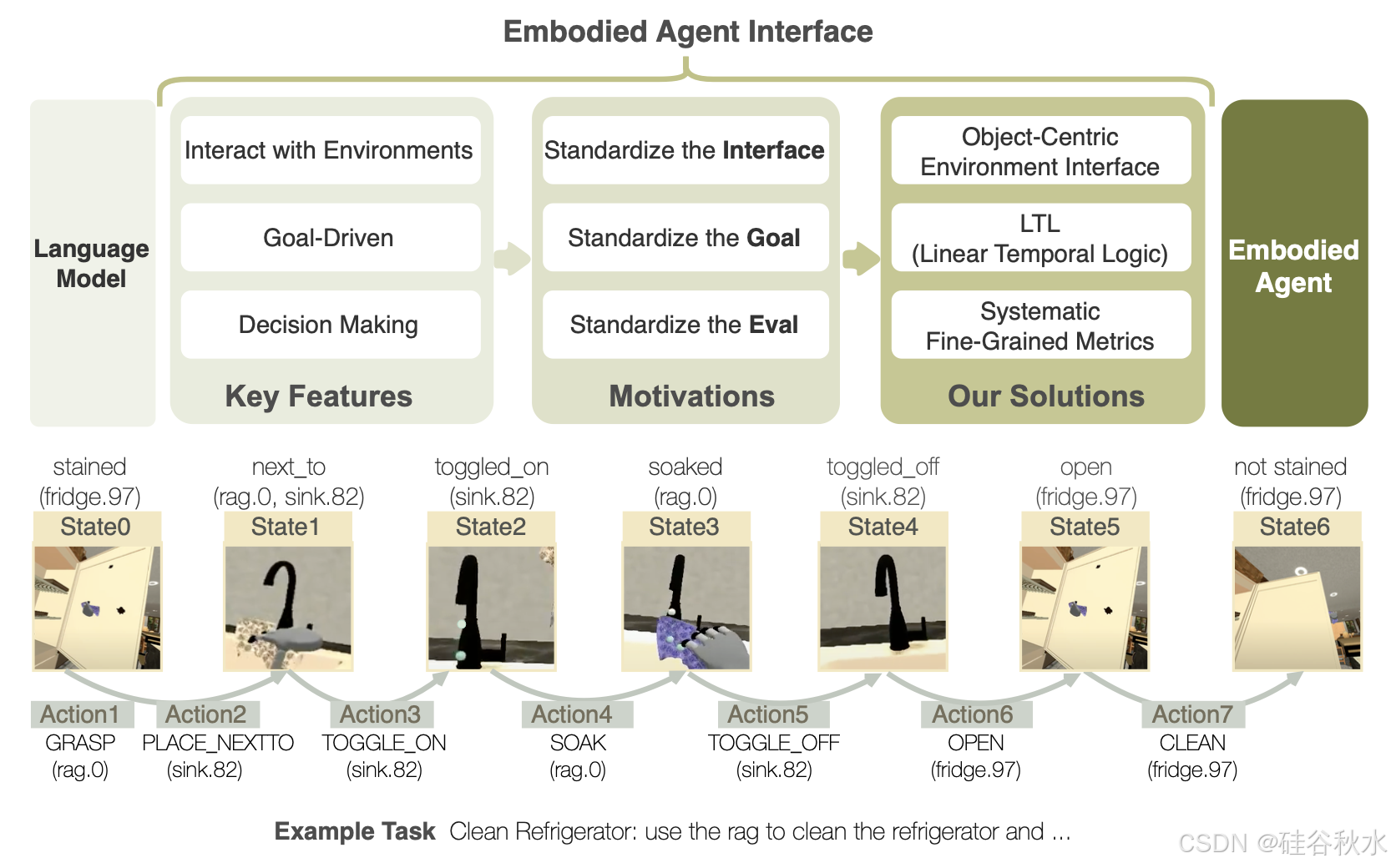
具身智体接口旨在为 LLM 设计一个标准接口,以便其在具身环境中执行任务,如图所示:
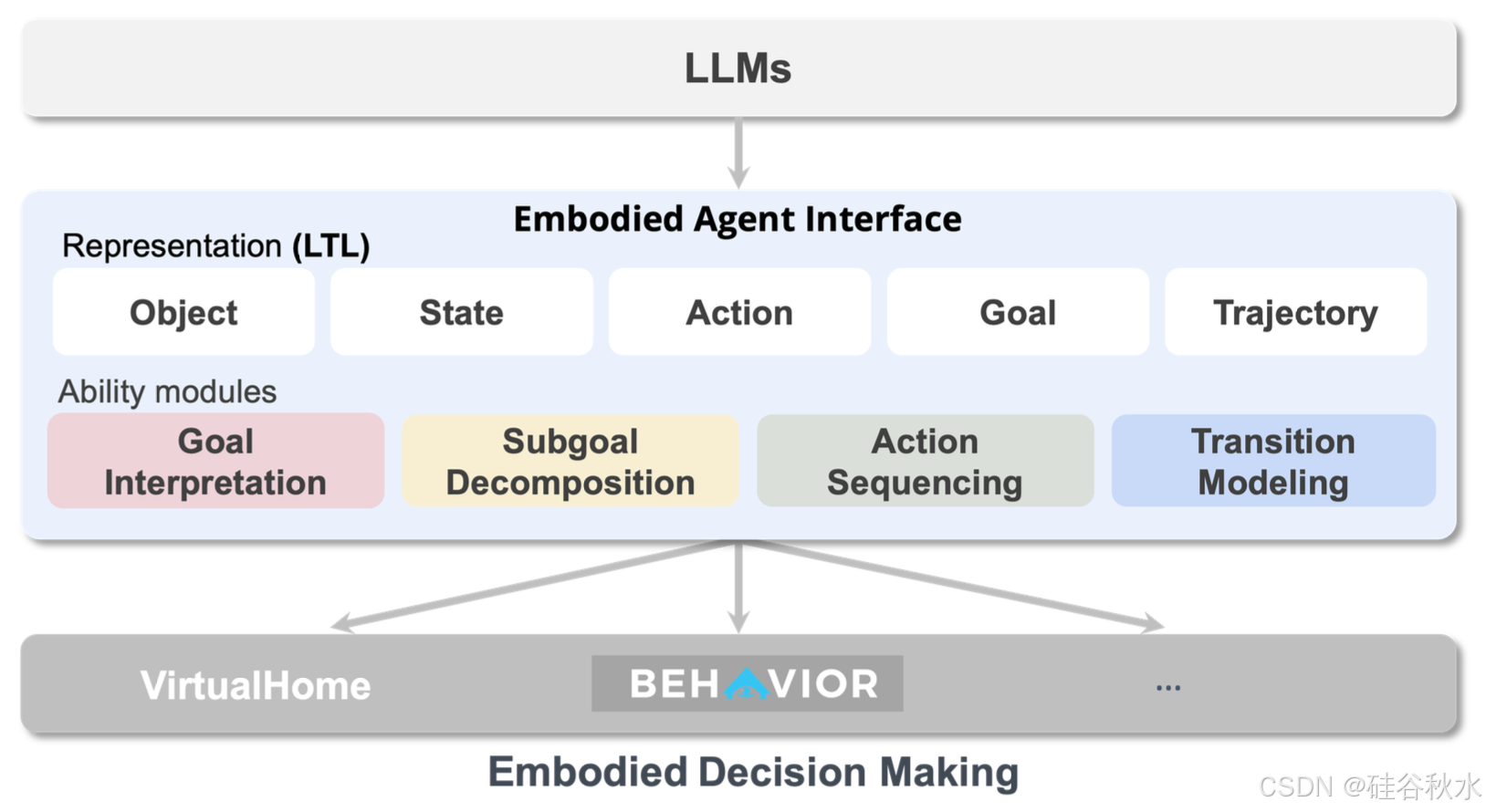
如图所示:具身智体接口和现有 LLM 的具身决策基准对比
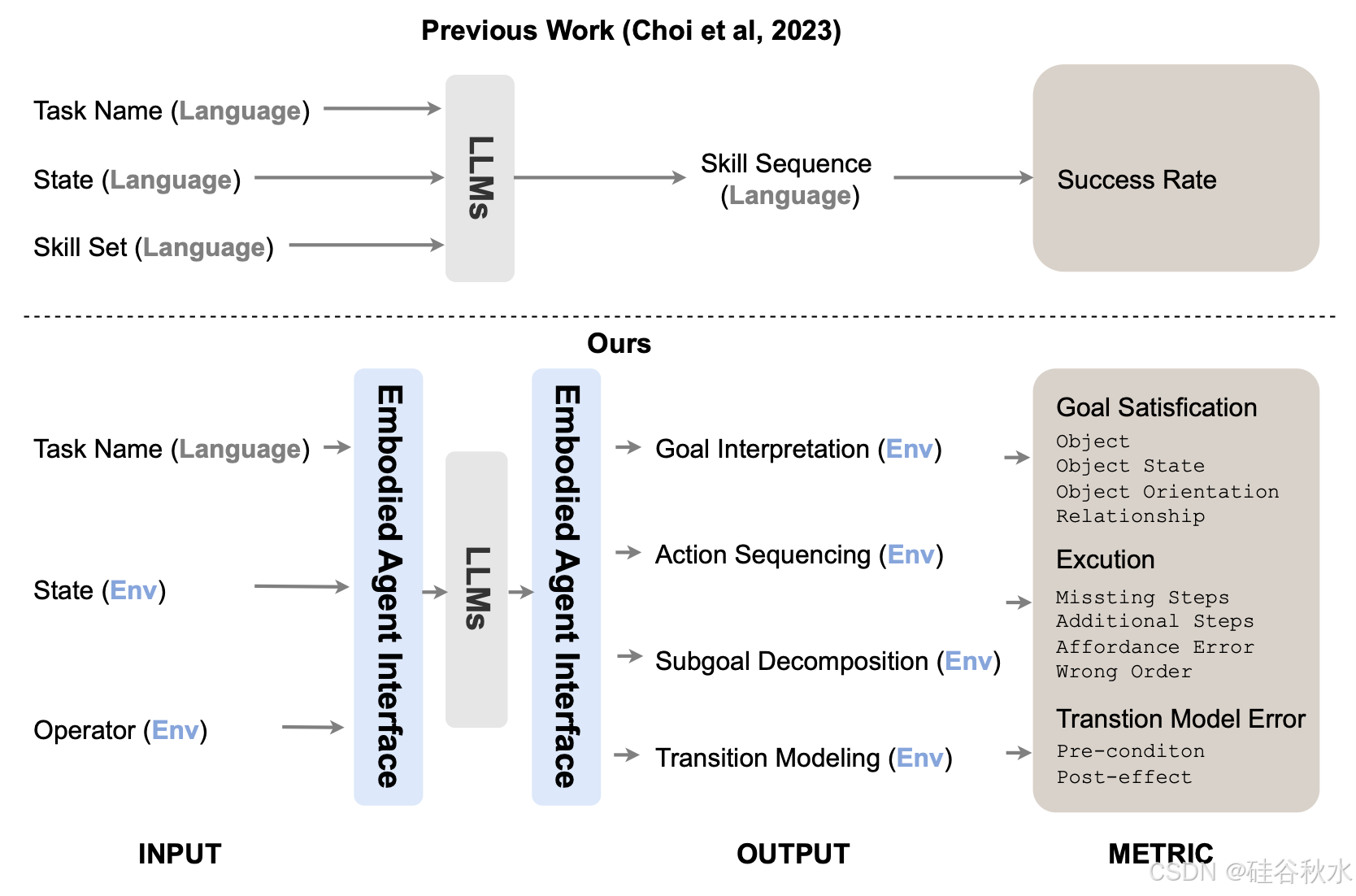

















 1493
1493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









