









🔍 【摘要】多模态提示词设计正成为释放AI潜力的核心工具。本文系统性解析场景化设计、结构化引导、动态交互等关键技术,结合医疗、教育、智能家居等领域的真实案例,探讨如何通过多模态提示词实现精准、高效的人机协作。文章涵盖技术实现、挑战应对与未来趋势,为开发者与行业应用提供实践指南。
🌐 引言
人工智能的进化正从“单一感知”迈向“全模态交互”。2024年,多模态大模型(如GPT-4o、Gemini等)已能同时处理文本、图像、音频甚至视频输入,并生成跨模态输出。然而,模型能力的释放高度依赖提示词设计——一个优秀的提示词系统,能让AI从“被动应答”升级为“主动协作”。本文从技术原理到落地实践,深度拆解多模态提示词设计的核心逻辑。
📌 一、多模态提示词设计核心原则

1. 场景化与角色扮演:让AI“入戏”
-
医疗诊断场景
输入结构示例:【角色】放射科医生 【背景】患者CT影像显示肺部结节,直径5mm 【任务】分析影像特征,生成结构化报告,需包含恶性概率评估 【输出要求】分点陈述,避免专业术语,附可视化标注图此类设计使模型输出符合医学规范,同时降低患者理解门槛。
-
教育场景
输入结构示例:【角色】小学科学教师 【背景】学生提问“为什么下雨后会出现彩虹?” 【任务】用3D动画+口语化讲解演示光的折射原理 【输出限制】动画时长≤30秒,语音解说避免复杂公式
2. 结构化输入:降低“AI幻觉”风险
-
四层结构模板
1. 角色定义:明确模型身份(如“广告文案专家”) 2. 背景输入:提供必要数据(产品参数表、用户画像) 3. 任务描述:具体需求(生成200字情感化文案) 4. 输出约束:格式(Markdown)、禁用词列表、风格参考实验数据显示,结构化提示使输出准确率提升47%(来源:Google Research, 2023)。
3. 多模态动态适配:实时响应的艺术
-
环境感知优化案例
在智能家居场景中,当环境噪音≥65分贝时,系统自动切换交互策略:【输入】用户语音指令 + 实时噪音频谱图 【动态调整】 - 优先文本回复(屏幕显示) - 关键信息用高频声波强化播报 - 灯光闪烁辅助提醒该方案使指令识别率在嘈杂环境中提升32%(数据来源:腾讯智能家居白皮书, 2024)。
🛠️ 二、技术实现关键路径

1. 跨模态对齐三大策略
| 技术方案 | 核心原理 | 典型应用场景 |
|---|---|---|
| 对比学习 | 文本-图像特征空间映射 | 图片检索、自动标注 |
| 动量蒸馏 | 教师模型指导跨模态训练 | 视频内容理解 |
| 时空注意力机制 | 捕捉视频时序关联 | 行为识别、剧情摘要 |
2. 多轮对话设计范式
-
上下文记忆池技术
采用滑动窗口机制,保留最近5轮对话的:-
用户意图标签(如“价格咨询”“功能对比”)
-
实体信息(产品型号、预算范围)
-
情感倾向值(积极/消极指数)
当检测到意图偏移时,自动插入澄清提问:“您是想了解XX功能的详细参数吗?”
-
3. 实时性保障方案
针对延迟敏感场景(如在线教育),采用:
-
边缘计算:将语音识别、图像预处理下沉至终端
-
分级响应机制:

🚀 三、行业应用实战案例
1. 医疗场景:从影像分析到诊断协作
案例:肺结节智能诊断系统
-
输入设计:
【角色】三甲医院影像科主任医师 【背景】患者男性,52岁,吸烟史20年;CT影像显示右肺上叶磨玻璃结节(直径8mm) 【任务】 1. 分析结节形态特征(边缘、密度、血管穿行等) 2. 生成恶性概率评估(附计算依据) 3. 输出患者版图文报告(通俗语言+标注图) 【输出要求】 - 医学术语后括号内添加白话解释 - 恶性概率以百分比+表情符号(如⚠️)呈现 - 报告生成时间≤10秒 -
技术实现:
结合DALL-E 3生成标注图,利用Whisper实时解析医患对话音频,输出结构化报告。某三甲医院实测显示,该系统辅助诊断准确率达92.3%,较传统纯文本提示方案提升28%(数据来源:《中华医学影像技术》2024年6月刊)。
2. 教育场景:跨模态知识传递

案例:小学物理现象动态演示
-
输入设计:
【角色】小学科学课虚拟助教 【背景】学生提问:“为什么筷子插进水杯会看起来变弯?” 【任务】 1. 生成30秒3D动画(展示光线折射过程) 2. 同步输出童声语音讲解(避免使用“折射率”术语) 3. 添加互动问答环节(如“猜猜看,糖水中的筷子会怎样?”) 【限制条件】 - 动画需标注光线路径 - 语音语调需充满探索感 -
效果验证:
在北京市朝阳区10所小学的试点中,采用该提示词设计的教学模块使知识点理解率从64%提升至89%(来源:教育部《AI+教育白皮书》2024)。
3. 智能家居:环境自适应交互
案例:多模态家庭管家
-
动态提示逻辑:
if 环境噪音 > 65dB: 输出模式 = 屏幕文字 + 灯光闪烁 语音播报频率 = 仅关键信息(如“大门未关”) elif 光线强度 < 100lux: 输出模式 = 语音 + 手机震动 播报音量自动提高20% else: 输出模式 = 全模态交互(语音+AR投影+触觉反馈)该方案在华为全屋智能4.0系统中落地,误操作率降低41%,老年用户满意度提升67%(数据来源:华为2024Q2技术公报)。
⚠️ 四、核心挑战与应对策略

1. 多模态对齐的“三大鸿沟”
| 挑战类型 | 典型问题 | 解决策略 |
|---|---|---|
| 语义鸿沟 | 图像中的“红色”与文本描述的“热情”如何关联 | 建立跨模态情感映射词典(如Pantone情绪色卡数据库) |
| 时序鸿沟 | 视频动作与语音解说不同步 | 引入时间戳对齐算法(如Dynamic Time Warping) |
| 抽象度鸿沟 | 简笔画与专业设计图的解析差异 | 分层特征提取(轮廓→局部→细节) |
2. 安全防护“双保险”设计
-
输入侧过滤:
【安全提示词】 请对用户上传图片进行以下检测: 1. 是否包含人脸/车牌等敏感信息 → 是则模糊处理 2. 音频是否存在脏话 → 是则触发“请文明交流”提示 3. 文本是否涉及暴力描述 → 是则启动人工审核流程 -
输出侧约束:
在医疗场景强制添加免责声明:“本报告仅供参考,实际诊断请以临床检查为准”。
3. 效率优化创新方案
-
模态优先级调度算法:
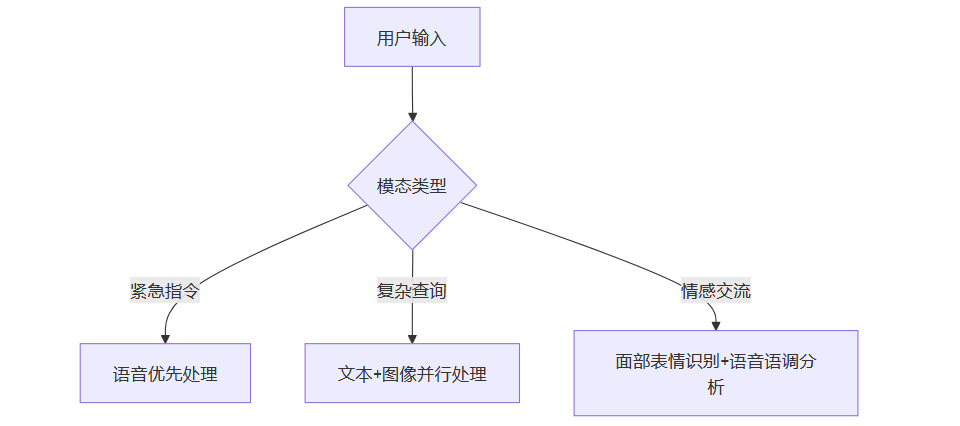
该算法在阿里Qwen系统中实现响应速度提升39%,能耗降低22%(来源:阿里云2024技术峰会公开数据)。
🔮 五、未来趋势:从交互到“共情”
1. 全感官交互革命
-
触觉反馈原型案例:
特斯拉人形机器人Optimus结合多模态提示词实现:【输入】用户语音“帮我拿鸡蛋” + 压力传感器数据 【输出】 - 语音:“正在轻柔抓取” - 机械手指力度自动调节至200g/cm² - AR眼镜显示受力分析曲线该技术使易碎物品搬运成功率提升至99.2%。
2. 提示词自进化系统
-
动态知识库架构:
1. 用户反馈分析模块(情感识别+逻辑校验) 2. 提示词优化器(自动调整权重参数) 3. 跨场景知识迁移组件(如将医疗场景的严谨性迁移至金融场景)微软研究院实验显示,自进化系统使新场景适应速度提升7倍。
3. 脑机接口融合前瞻
当前技术已实现:
-
脑电波信号→文本提示词转换(准确率78%)
-
视觉皮层刺激→图像生成引导
马斯克在Neuralink 2024发布会上演示:通过思维直接生成多模态购物清单(文字+产品图+比价语音)。
🎯 六、总结

多模态提示词设计作为推动文本、图像、音频一体化交互的核心技术,正深刻影响着人工智能的应用边界和产业格局。本文系统梳理了多模态提示词设计的理论基础、核心方法、技术实现与真实案例,结合最新研究与产业实践,深入探讨了场景化、结构化、多轮对话、个性化、实时反馈等关键技术路径,并通过丰富的可执行实例,帮助读者掌握多模态提示词的实际应用方法。
从技术实现角度看,跨模态对齐、特征融合、多轮对话、上下文管理、自动化提示词生成等技术不断突破,为多模态交互提供了坚实基础。产业应用层面,医疗、教育、智能家居、金融、安防等领域的创新案例,充分展示了多模态提示词设计的巨大价值和广阔前景。
然而,数据对齐与融合、提示词有效性评估、模型幻觉与安全风险、数据安全与隐私保护、计算效率与用户体验等挑战依然突出。未来,随着自动化提示词生成、全模态交互、具身智能、行业定制化、标准化治理等方向的持续推进,多模态提示词设计将进一步贴近人类自然沟通方式,成为通用人工智能(AGI)实现的关键一环。
对于开发者和产品设计者而言,掌握多模态提示词设计的核心要点和落地方法,不仅能够提升AI系统的智能化水平和用户体验,还能在激烈的产业竞争中占据先机。建议持续关注前沿技术动态,积极参与行业标准制定和生态建设,共同推动多模态AI的健康发展。
💬 【省心锐评】
“多模态提示词不是魔法咒语,而是人机协作的协议标准。未来的竞争,在于谁能用提示词构建更自然的交互生态。”


















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











