







文章目录
本节介绍
下面我们开始agent的学习,先从开始的概念介绍,以及流程说明,到使用openai来实现一个agent,再到使用langchain框架改进我们饿实现,以完整我们对agent有一个清晰的了解
Agent与LLM Agent
我们今天讨论的 Agent 是一种能够自主感知周围环境、做出决策、采取行动达成特定目标的系统。“自主”是 Agent 与传统软件系统之间的差异。
Agent 虽然在人工智能领域已经存在了很长的时间,但终究只在这个领域内部讨论,一个重要的原因就是 Agent 缺少一个好“大脑”。
虽然很多人都在把大模型当作一个更好的聊天机器人在用,但实际上,大模型还有一个很强的能力,就是推理能力。所以,有人开始把大模型视为一个强大的通用问题解决器(general problem solver)。
AutoGPT 刚刚出来的时候,惊艳到了很多人。只需要一个简单提示词,AutoGPT 就能开始自己分析任务、拆解任务乃至执行任务。这远远超出普通人对大模型边界的认知,殊不知,如此表现的 Agent 同样也是人工智能研究领域翘首期盼的,一个好用的新脑。随着 AutoGPT 的流行,各种以大模型为新脑的 Agent 纷纷问世,AI 领域曾经无法很好实现的 Agent 终于可以落地了。
大模型虽然很好,但它并不是一个完整的 Agent。所以,要想让 Agent 真正落地,我们还需要补充一些组件,下面是一个常见的 Agent
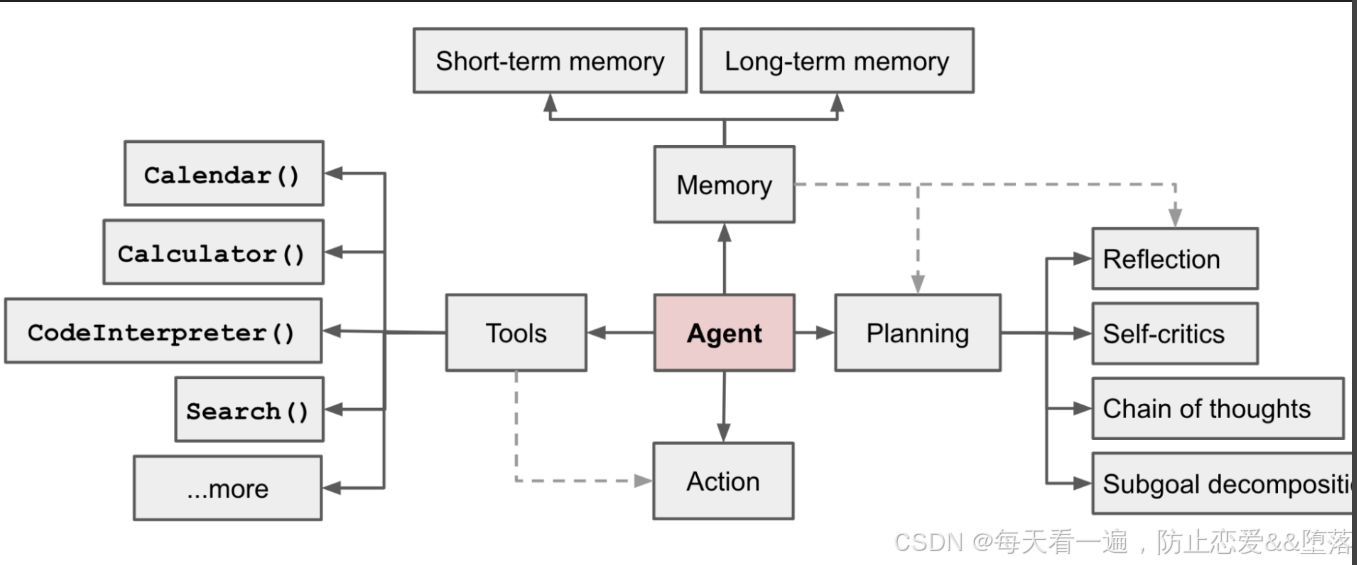
这里面包含了一些重要的组件:
- 规划(Planning),它负责将大目标分解成小的子目标,也可以对已有行为进行反思和自我改善。
- 记忆(Memory),包括短期记忆和长期记忆,短期记忆提供上下文内的学习,长期记忆则提供长时间保留和回忆信息的能力。
- 工具(Tools),通过调用外部 API 获取外部信息(作为感知器),执行外部动作(作为执行器)。
从这些组件的简介我们不难看出,规划组件的能力是需要智能完成的,这个部分要归属于大脑,在实现中,我们可以让大模型来做这部分工作。在记忆组件中,短期记忆可以用聊天历史的方式解决,而长期记忆,我们可以存放到向量数据库中,采用类似 RAG 的方式解决。工具组件主要是与不同的内容集成,这个部分是程序员最熟悉的部分,属于常规的编码。
为了帮助你更好地理解,我们用一个处理流程来看一下 Agent 是如何工作的。Agent 的处理流程通常会分成两步:规划和执行。
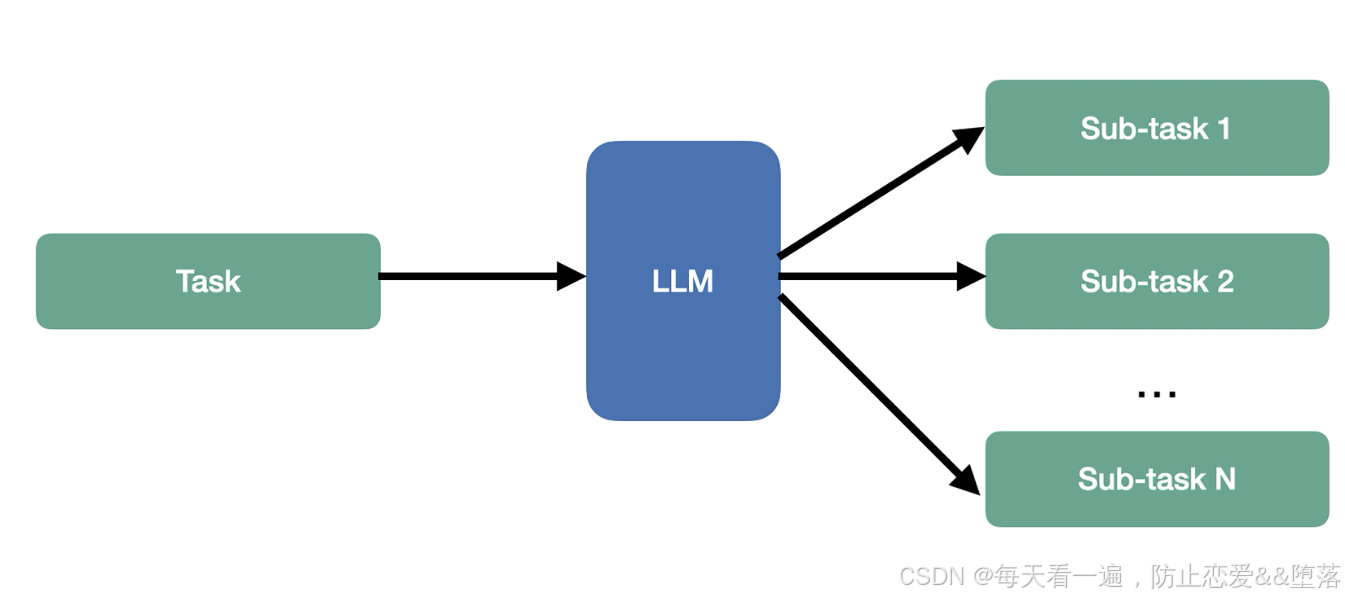
当 Agent 接收到用户请求时,它会让规划组件将大任务分解成更小的子任务,剩下的就是逐步执行这些子任务。进行任务分解,关键就是使用提示词。为了能更好地完成任务,我们可以采用提示工程的技术,比如思维链。具体采用哪种提示词,需要结合自己应用的特点进行选择。经过这个过程,一个大任务就会变成很多的子任务。
有了分解出来的子任务,我们就可以执行了。不过,通常情况下,我们还会做一些评估,比如,判断任务的有效性,是否需要继续执行等等。这种任务也可以交给大模型,用到的也是提示工程,比如,ReAct。我们讲过,ReAct 会通过思考(Thought)、行动(Action)、观察(Observation)三个阶段进行任务处理。通常我们会循环这个过程,直到通过观察,判断需要结束。
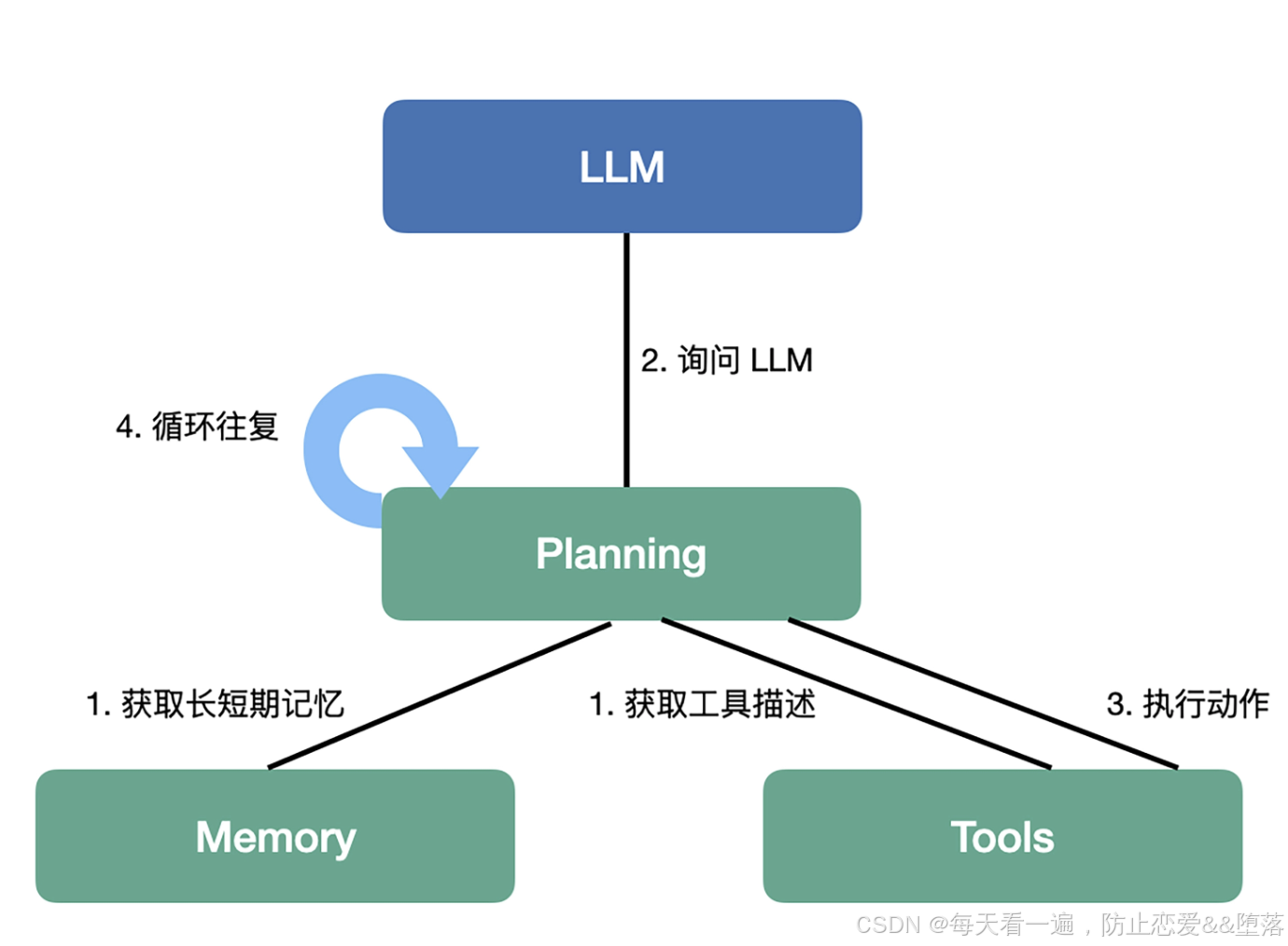
执行一个具体的任务,往往是我们问大模型要做什么,然后,由大模型结合上下文信息做出判断,指定一个具体要做的事情。在这个过程中,我们要告诉大模型我们能做什么,常规的做法就是把工具组件的能力在提示词中描述出来,比如,我们告诉大模型说它能够查询某个地区的天气。此外,提示词里包含的上下文则是来自记忆组件,可能包括作为短期记忆的聊天历史,以及从长期记忆中搜索得到的相关信息。
当我们把完整的提示词发给大模型,大模型会告诉我们该做什么。比如,它告诉我们该查询天气,并告诉我们具体的参数是什么。这时,大模型已经完成了思考过程,这就轮到我们行动了。我们会调用工具组件的查询天气功能,得到一个结果。
接下来,我们会把得到的结果再发给大模型,进入下一个执行循环。如此往复,直到大模型判断说,应该停下来。
通过这个介绍,你可以看到 Agent 的执行过程本质上是一个循环,一直会执行到大模型认为应该结束为止。所以,一旦控制不好,Agent 执行过程成本是非常高的。从实践的角度,有时我们会控制一下循环的次数。
虽然我们介绍的 Agent 包含了完整的组成部分,但在实际的开发过程,我们可能并不需要所有的组件。比如,一个辅助孩子解决奥数问题的 Agent,可能就不需要使用工具,因为它需要的只是一些推理过程。再比如,一个辅助写作的 Agent,流程可能是固定的:搜集资料、列出大纲、写作、打磨,它就不需要一个规划的过程,只要一个步骤一个步骤地执行。
前面说到了人工智能领域对 Agent 的探索,实际上,人们在这个方向走出了很远,比如,多个任务的并行执行、分布式 Agent、多智能体协调等等。如果你想在这个方向走得更远,里面还是有很多东西可以去研究的,毕竟,人工智能研究的内容就是理性智能体。
从头实现一个Agent
这一讲,我们来实现一个 Agent。不同于之前借助 LangChain,这次我们会用更底层的方式实现一个 Agent,帮助你更好地理解 Agent 的运作原理。
我们构建这个 Agent 会基于 ReAct 来实现,我们在上面介绍过,ReAct 表示 Reasoning + Acting,也就是推理和行动。采用这个模式,要经历思考(Thought)、行动(Action)、观察(Observation)三个阶段。
大模型会先思考要做什么,决定采用怎样的行动,然后在环境中执行这个行动,返回一个观察结果。有了这个观察结果,大模型就会重复思考的过程,再次考虑要做什么,采用怎样的行动,这个过程会持续到大模型决定这个过程结束为止。
我们的实现代码参考了 Simon Willison 的一篇文章,这篇文章介绍了如何用 Python 实现 ReAct 模式。
基础的聊天机器人
我们先来实现一个基础的聊天机器人,代码如下:
from openai import OpenAI
DEFAULT_MODEL = "gpt-4o-mini"
client = OpenAI()
class Agent:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def invoke(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def exec 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









