







出发点
之前写的几篇关于大模型从输入到输出的代码都是transformer结构的代码,这次挑战一下MOE的代码,我是基于Deepseek-MOE-16B-chat的代码做的修改,这中间关于模型结构deepseek-llm-7b-chat调整的内容不是很多,主要是MOE的部分做了调整。请先阅读上一篇,关于完全一样的内容,这里不再重复
模型结构
# 这里强调一下,transformers==4.46.0
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "/usr/downloads/deepseek-moe-16b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "你是谁?"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
# ' 我是DeepSeek Chat,一个基于DeepSeek大语言模型开发的智能AI机器人。我可以回答各种问题,包括但不限于科学、文化、历史、技术、生活等方面的问题。如果您有任何问题,欢迎随时向我提问。'
"""
DeepseekForCausalLM(
(model): DeepseekModel(
(embed_tokens): Embedding(102400, 2048)
(layers): ModuleList(
(0): DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=2048, bias=False)
(v_proj): Linear(in_features=2048, out_features=2048, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): DeepseekRotaryEmbedding()
)
(mlp): DeepseekMLP(
(gate_proj): Linear(in_features=2048, out_features=10944, bias=False)
(up_proj): Linear(in_features=2048, out_features=10944, bias=False)
(down_proj): Linear(in_features=10944, out_features=2048, bias=False)
(act_fn): SiLU()
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
(1-27): 27 x DeepseekDecoderLayer(
(self_attn): DeepseekAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=2048, bias=False)
(v_proj): Linear(in_features=2048, out_features=2048, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): DeepseekRotaryEmbedding()
)
(mlp): DeepseekMoE(
(experts): ModuleList(
(0-63): 64 x DeepseekMLP(
(gate_proj): Linear(in_features=2048, out_features=1408, bias=False)
(up_proj): Linear(in_features=2048, out_features=1408, bias=False)
(down_proj): Linear(in_features=1408, out_features=2048, bias=False)
(act_fn): SiLU()
)
)
(gate): MoEGate()
(shared_experts): DeepseekMLP(
(gate_proj): Linear(in_features=2048, out_features=2816, bias=False)
(up_proj): Linear(in_features=2048, out_features=2816, bias=False)
(down_proj): Linear(in_features=2816, out_features=2048, bias=False)
(act_fn): SiLU()
)
)
(input_layernorm): DeepseekRMSNorm()
(post_attention_layernorm): DeepseekRMSNorm()
)
)
(norm): DeepseekRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=102400, bias=False)
)
"""
模型从tokenizer、model的加载和Deepseek-llm-7b-chat是一模一样的,模型结构的有一些变化,简单说一下看出来的差别
- 为了保证参数量,hidden_size舍弃了4096,使用了2048
- layer0是和之前的一样的
- layer1-27是添加了MOE的
- MOE中每个专家头(64个)都是一个MLP层,只是维度没有升高,反而降到1408
- layer1-27中每层都带有一个共享专家头,同样为MLP层,维度从2048升到2816
- 为了每个token可以选择使用哪些专家头,带有一个Gate层来做选择(模型架构看不出来,但可以想一下,输入维度是2048,输出维度是64,最简单的就是一个linear层)
参数量
简单分析一下参数量,其实从模型结构里就能很明白的看出来了,我这里就是记录一下
419430400+2048+(4096+16777216+8650752*64+17301504+131072)*27+67239936+16777216+4096=16330903552
# 激活数量只有28亿
419430400+2048+(4096+16777216+8650752*6+17301504+131072)*27+67239936+16777216+4096=2828650496
"""
# 注意一下,所有的线性层都没有bias
# word embedding+lm_head
2048*102400*2=419430400
# 最后一层后面的LN
2048
# 0层有的参数
# LN
2048*2=4096
# self_attn
2048*2048*4=16777216
# MLP
2048*10944*3=67239936
# 1-27层每层都有的参数
# LN
2048*2=4096
# self_attn
2048*2048*4=16777216
# 64个专家都有的
2048*1408*3=8650752
# 共享专家
2048*2816*3=17301504
# gate
2048*64=131072
"""
不变的部分
主流程图、model部分、MLP层、RMSNorm、attention部分、rotaryEmbedding部分都是不变的,只是将代码中的Llama改为了Deepseek
这部分省略了
DecoderLayer
其实这部分只有在初始化的地方有一点不一样,流程图是一样的
class DeepseekDecoderLayer(torch.nn.Module):
"""A single transformer layer.
Transformer layer takes input with size [s, b, h] and returns an
output of the same size.
"""
def __init__(self, config: DeepseekConfig, layer_idx, device=None):
super(DeepseekDecoderLayer, self).__init__()
# Layernorm on the input data.
self.input_layernorm = DeepseekRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# Self attention.
self.self_attn = DeepseekAttention(config=config, layer_idx=layer_idx)
# Layernorm on the attention output
self.post_attention_layernorm = DeepseekRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
# MLP
# ------------------------------------------------------------------------------
# 唯一一个改动点
# 当layer_idx符合条件的时候,使用DeepseekMOE,其他时候使用DeepseekMLP
# 这里是从layer_idx=1到27都是使用的DeepseekMOE
self.mlp = DeepseekMoE(config) if (config.n_routed_experts is not None and \
layer_idx >= config.first_k_dense_replace and layer_idx % config.moe_layer_freq == 0) \
else DeepseekMLP(config)
MOEGate
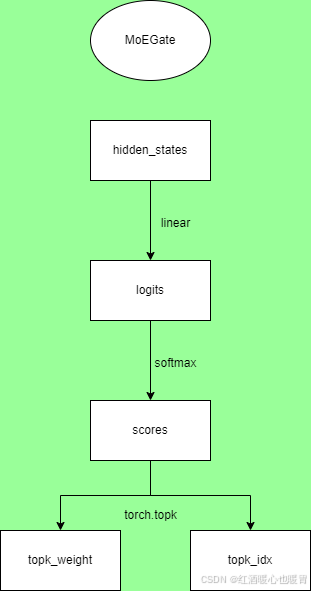
class MoEGate(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.top_k = config.num_experts_per_tok
self.n_routed_experts = config.n_routed_experts
self.scoring_func = config.scoring_func
self.alpha = config.aux_loss_alpha
self.seq_aux = config.seq_aux
# topk selection algorithm
self.norm_topk_prob = config.norm_topk_prob
self.gating_dim = config.hidden_size
self.weight = nn.Parameter(torch.empty((self.n_routed_experts, self.gating_dim)))
self.reset_parameters()
def reset_parameters(self) -> None:
import torch.nn.init as init
init.kaiming_uniform_(self.weight, a=math.sqrt(5))
def forward(self, hidden_states):
bsz, seq_len, h = hidden_states.shape
### compute gating score
hidden_states = hidden_states.view(-1, h)# bsz*seq_len, h
logits = F.linear(hidden_states, self.weight, None)# 64,2048得到bsz*seq_len, 64
scores = logits.softmax(dim=-1)
### select top-k experts
topk_weight, topk_idx = torch.topk(scores, k=self.top_k, dim=-1, sorted=False)# bsz*seq_len, 6
### norm gate to sum 1
if self.top_k > 1 and self.norm_topk_prob:
denominator = topk_weight.sum(dim=-1, keepdim=True) + 1e-20
topk_weight = topk_weight / denominator
### expert-level computation auxiliary loss
aux_loss = None
return topk_idx, topk_weight, aux_loss
整体操作就像流程图那样,比较简单
DeepseekMoE
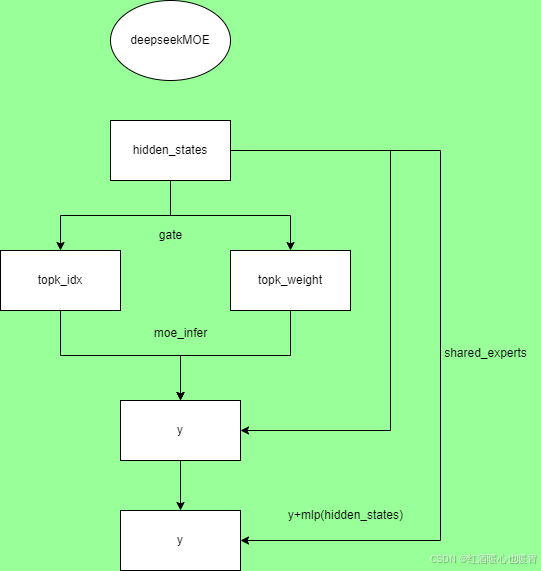
从流程图可以看出来,通过hidden_states得到topk_idx和topk_weight以后,将这两个和hidden_states一起输入moe_infer函数得到y,将y和经过shared_experts后的结果相加,得到最后的输出。这个流程比较清晰,比较难得是moe_infer
class DeepseekMoE(nn.Module):
"""
A mixed expert module containing shared experts.
"""
def __init__(self, config):
super().__init__()
self.config = config
self.num_experts_per_tok = config.num_experts_per_tok# 6
self.experts = nn.ModuleList([DeepseekMLP(config, intermediate_size = config.moe_intermediate_size) for i in range(config.n_routed_experts)])
self.gate = MoEGate(config)
if config.n_shared_experts is not None:
intermediate_size = config.moe_intermediate_size * config.n_shared_experts
self.shared_experts = DeepseekMLP(config=config, intermediate_size = intermediate_size)
def forward(self, hidden_states):# 流程图中画得出来的
identity = hidden_states
orig_shape = hidden_states.shape
topk_idx, topk_weight, aux_loss = self.gate(hidden_states)
hidden_states = hidden_states.view(-1, hidden_states.shape[-1])# bsz*seq_len,h
flat_topk_idx = topk_idx.view(-1)# bsz*seq_len*6
y = self.moe_infer(hidden_states, flat_topk_idx, topk_weight.view(-1, 1)).view(*orig_shape)
if self.config.n_shared_experts is not None:
y = y + self.shared_experts(identity)
return y
@torch.no_grad()
def moe_infer(self, x, flat_topk_idx, topk_weight):
expert_cache = torch.zeros_like(x)# bsz*seq_len,h
idxs = flat_topk_idx.argsort()# 按升序排列元素的索引
tokens_per_expert = flat_topk_idx.bincount().cpu().numpy().cumsum(0)
token_idxs = idxs // self.num_experts_per_tok
for i, end_idx in enumerate(tokens_per_expert):
start_idx = 0 if i == 0 else tokens_per_expert[i-1]
if start_idx == end_idx:
continue
expert = self.experts[i]
exp_token_idx = token_idxs[start_idx:end_idx]
expert_tokens = x[exp_token_idx]
expert_out = expert(expert_tokens)
expert_out.mul_(topk_weight[idxs[start_idx:end_idx]])
expert_cache.scatter_reduce_(0, exp_token_idx.view(-1, 1).repeat(1, x.shape[-1]), expert_out, reduce='sum')
return expert_cache
先简单叙述一下moe_infer在干一件什么样的事情OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER,如下图所示,它是在完成右边根据gate的结果找到对应的expert、然后乘上权重,最后相加的事情。
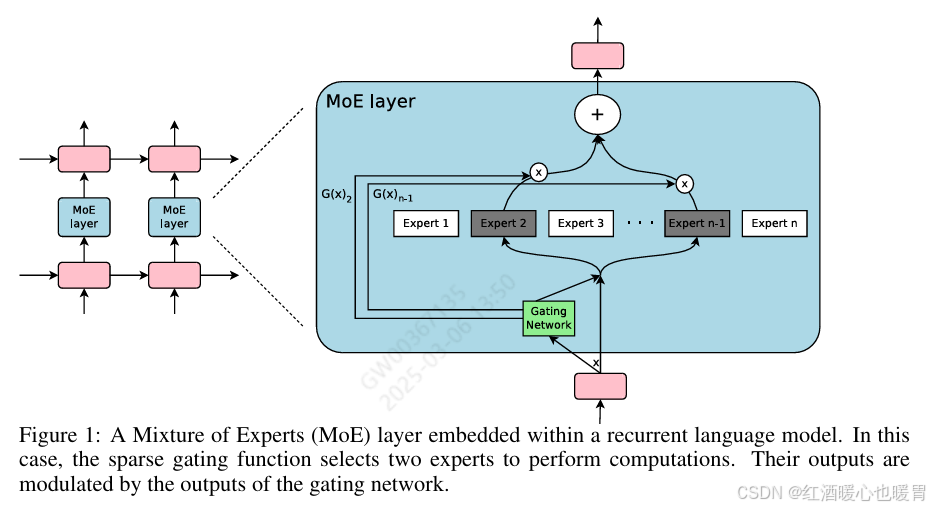
如果让我来做这个事情,那我肯定按照token来遍历啊,下面先来说官方代码
import torch
from torch import nn
from transformers import AutoModelForCausalLM
model_name = "/usr/downloads/deepseek-moe-16b-chat"
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto", trust_remote_code=True)
# 基础设置-专家的头数
num_experts_per_tok = 6
# 经过gate处理后,8个token,每个token对应了6个头,拉平后的结果
flat_topk_idx = torch.tensor([12, 36, 39, 56, 58, 40, 6, 9, 26, 44, 50, 55, 8, 26, 30, 32, 63, 16, 6, 16, 28, 36, 49, 48, 30, 35, 57, 59, 61, 18, 28, 35, 40, 54, 55, 63, 2, 21, 56, 59, 63, 52, 23, 32, 33, 38, 39, 25]).to(model.device)
# 每个专家对应的权重
topk_weight = torch.randn(48,1, dtype=torch.bfloat16).to(model.device)
# 8个token对应的向量值
hidden_states = torch.randn(8,2048, dtype=torch.bfloat16).to(model.device)
# 从model中找到layer1的64个专家
experts = model.model.layers[1].mlp.experts
# 模型做法
def moe_infer(x, flat_topk_idx, topk_weight):
expert_cache = torch.zeros_like(x)# bsz*seq_len,h
idxs = flat_topk_idx.argsort()# 按升序排列元素的索引
tokens_per_expert = flat_topk_idx.bincount().cpu().numpy().cumsum(0)
token_idxs = idxs // num_experts_per_tok
for i, end_idx in enumerate(tokens_per_expert):
start_idx = 0 if i == 0 else tokens_per_expert[i-1]
if start_idx == end_idx:
continue
expert = experts[i]
exp_token_idx = token_idxs[start_idx:end_idx]
expert_tokens = x[exp_token_idx]
expert_out = expert(expert_tokens)
expert_out.mul_(topk_weight[idxs[start_idx:end_idx]])
expert_cache.scatter_reduce_(0, exp_token_idx.view(-1, 1).repeat(1, x.shape[-1]), expert_out, reduce='sum')
return expert_cache
final = moe_infer(hidden_states, flat_topk_idx, topk_weight)
按照token来遍历的代码写好以后,我发现了一个之前没注意到的问题,那就是在bfloat16的情况下,每个值相加的顺序会影响最后的结果,同理float16、float32也是有影响的,int是没有影响的。
import torch
a = torch.randn(10,40,dtype=torch.bfloat16)
b = torch.randn(10,40,dtype=torch.bfloat16)
c = torch.randn(10,40,dtype=torch.bfloat16)
aa = a + b + c
bb = a + c + b
aa == bb
"""
tensor([[ True, False, True, True, False, True, True, True, True, False,
False, False, True, True, True, False, True, True, True, True,
True, True, False, True, True, True, True, True, True, True,
False, False, True, True, True, True, True, True, False, True]
....
"""
-0.2090-0.3535+0.8047
# 0.24219999999999997
-0.2090+0.8047-0.3535
# 0.24220000000000003
按照token来遍历-错误做法
# 相加顺序不对,结果也不能完全对上
def moe_infer_1(x, flat_topk_idx, topk_weight):
expert_cache = torch.zeros_like(x)
for i, end_idx in enumerate(x):# token遍历
weight = topk_weight[i]
for j in range(6):# 每个token对应的专家遍历
print (flat_topk_idx[i*6+j])
expert = experts[flat_topk_idx[i*6+j]]# 找到对应的专家
expert_out = expert(end_idx)# 专家处理该token
expert_cache[i] = expert_cache[i] + expert_out.mul_(topk_weight[i*6+j])# 每个专家处理后的结果相加
return expert_cache
final1 = moe_infer_1(hidden_states, flat_topk_idx, topk_weight)# 相加顺序不对,结果也不能完全对上
final == final1
# False
# 其中token1和token5是一样的,因为它对应的专家序列刚好是升序的
按照token来遍历-正确做法
def moe_infer_2(x, flat_topk_idx, topk_weight):
expert_cache = torch.zeros_like(x)
for i, end_idx in enumerate(x):
aa, bb = flat_topk_idx[i*6:(i+1)*6].sort()# 先将专家头排序,aa记录了升序后的专家,bb记录了原始位置
for j in range(6):
expert = experts[aa[j]]
expert_out = expert(end_idx)
expert_cache[i] = expert_cache[i] + expert_out.mul_(topk_weight[i*6 + bb[j]])
return expert_cache
final2 = moe_infer_2(hidden_states, flat_topk_idx, topk_weight)# 相加顺序对了,结果能完全对上
final == final2
# True
官方做法

for i, end_idx in enumerate(tokens_per_expert):
start_idx = 0 if i == 0 else tokens_per_expert[i-1]# 找到前一个专家出现的次数和
if start_idx == end_idx:# 如果当前专家出现的次数和与前一个专家出现的次数和相等,那么则当前专家未出现过
continue
expert = experts[i]# i对应的是专家的index
exp_token_idx = token_idxs[start_idx:end_idx]# 找到能对应到这个专家的token行 idx
expert_tokens = x[exp_token_idx]# 根据token行idx找到对应的token hidden_states
expert_out = expert(expert_tokens)# 专家处理这个token
#print (expert_out.shape)
#print (topk_weight[idxs[start_idx:end_idx]].shape)
expert_out.mul_(topk_weight[idxs[start_idx:end_idx]])# 先找到token对应的权重,将专家输出与权重相乘
expert_cache.scatter_reduce_(0, exp_token_idx.view(-1, 1).repeat(1, x.shape[-1]), expert_out, reduce='sum')# 将每个token对应的专家输出相加
几点说明:
- scatter_reduce_ pytorch中的scatter_add_函数解析
- 按照专家头遍历复杂度是O(n),而按照token遍历复杂度是O(6*num_of_token),当token数量很大时,这个复杂度很高的
- 我尽量写的清楚明白了,具体逻辑还是要好好思考一下的
最后一点代码量
到此基本就写完了代码,最后补充上一点import和实际调用的代码
import copy
import re
import torch
import torch.nn.functional as F
from torch import nn
from typing import Optional, Tuple, List, Callable
from transformers.modeling_utils import PreTrainedModel
from transformers.modeling_rope_utils import ROPE_INIT_FUNCTIONS
from configuration_deepseek import DeepseekConfig# 这里有点变动,是deepseek,不是Deepseek
from transformers.activations import ACT2FN
import math
把这些代码保存成deepseek.py,放在deepseek-MOE-16b-chat的代码中,就可以正常使用了
from deepseek import *
from transformers import AutoTokenizer
model_path = "/usr/downloads/deepseek-moe-16b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = DeepseekForCausalLM.from_pretrained(model_path, trust_remote_code=True, torch_dtype=torch.bfloat16).cuda()
messages = [
{"role": "user", "content": "你是谁?"}
]
response = model.chat(tokenizer, messages)
print (response)
代码量在550行,原始代码量是1500,减少一半的代码的小目标基本实现(成功)
结束语
之前就知道MOE的计算方法(权重*MLP的结果),从来没有想过具体实现过程,这次借着Deepseek的机会好好了解了一下,很妙的想法。将代码从1500+缩减到了不到600行,简单明了、通俗易懂,成功。


















 3159
3159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









