









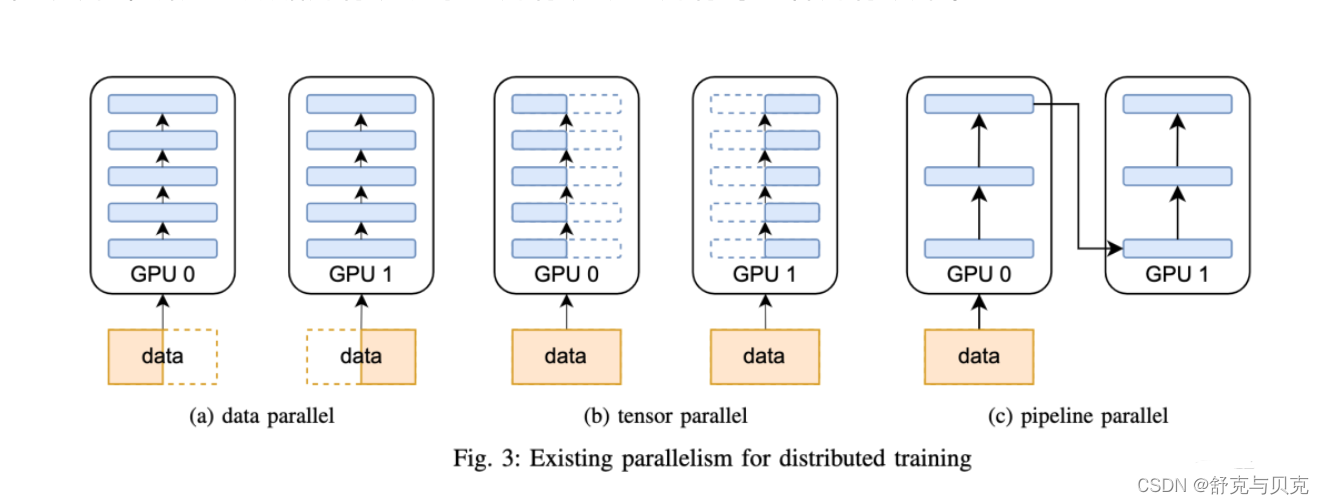
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。
而利用AI集群,使深度学习算法更好地从大量数据中高效地训练出性能优良的大模型是分布式机器学习的首要目标。为了实现该目标,一般需要根据硬件资源与数据/模型规模的匹配情况,考虑对计算任务、训练数据和模型进行划分,从而进行分布式存储和分布式训练。
因此,分布式训练相关技术值得我们进行深入分析其背后的机理。
 但是在进行上百亿/千亿级以上参数规模的超大模型预训练时,通常会组合多种并行技术一起使用。
但是在进行上百亿/千亿级以上参数规模的超大模型预训练时,通常会组合多种并行技术一起使用。
常见的分布式并行技术组合
1. DP + PP
下图演示了如何将 DP 与 PP 结合起来使用。
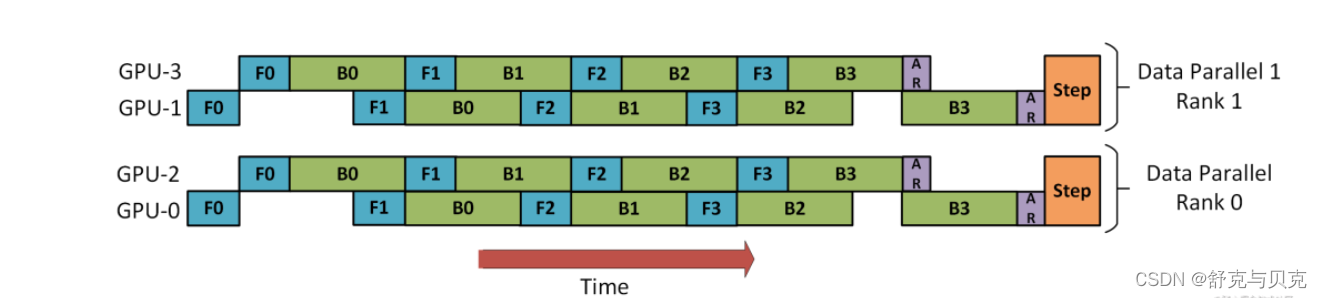
这里重要的是要了解 DP rank 0 是看不见 GPU2 的, 同理,DP rank 1 是看不到 GPU3 的。
对于 DP 而言,只有 GPU 0 和 1,并向它们供给数据。GPU0 使用 PP 将它的一些负载转移到 GPU2。同样地, GPU1 也会将它的一些负载转移到 GPU3 。
由于每个维度至少需要 2 个 GPU;因此,这儿至少需要 4 个 GPU。
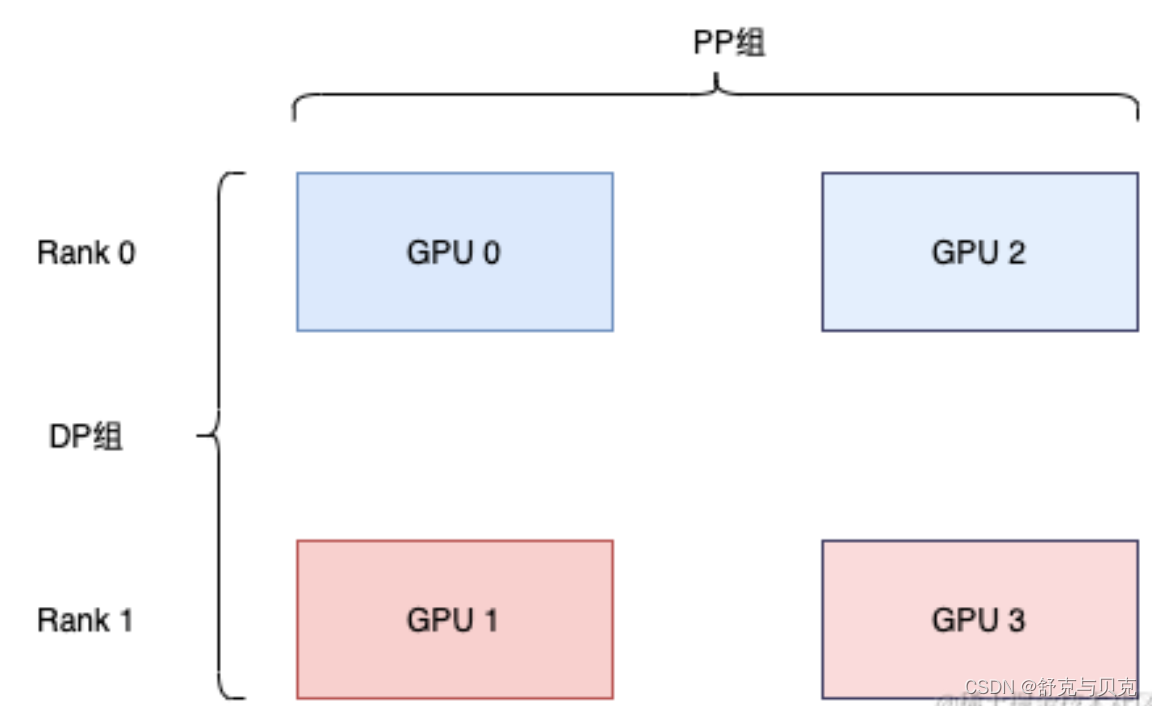
3D 并行(DP + PP + TP)
而为了更高效地训练,可以将 PP、TP 和 DP 相结合,被业界称为 3D 并行,如下图所示。
由于每个维度至少需要 2 个 GPU,因此在这里你至少需要 8 个 GPU 才能实现完整的 3D 并行。
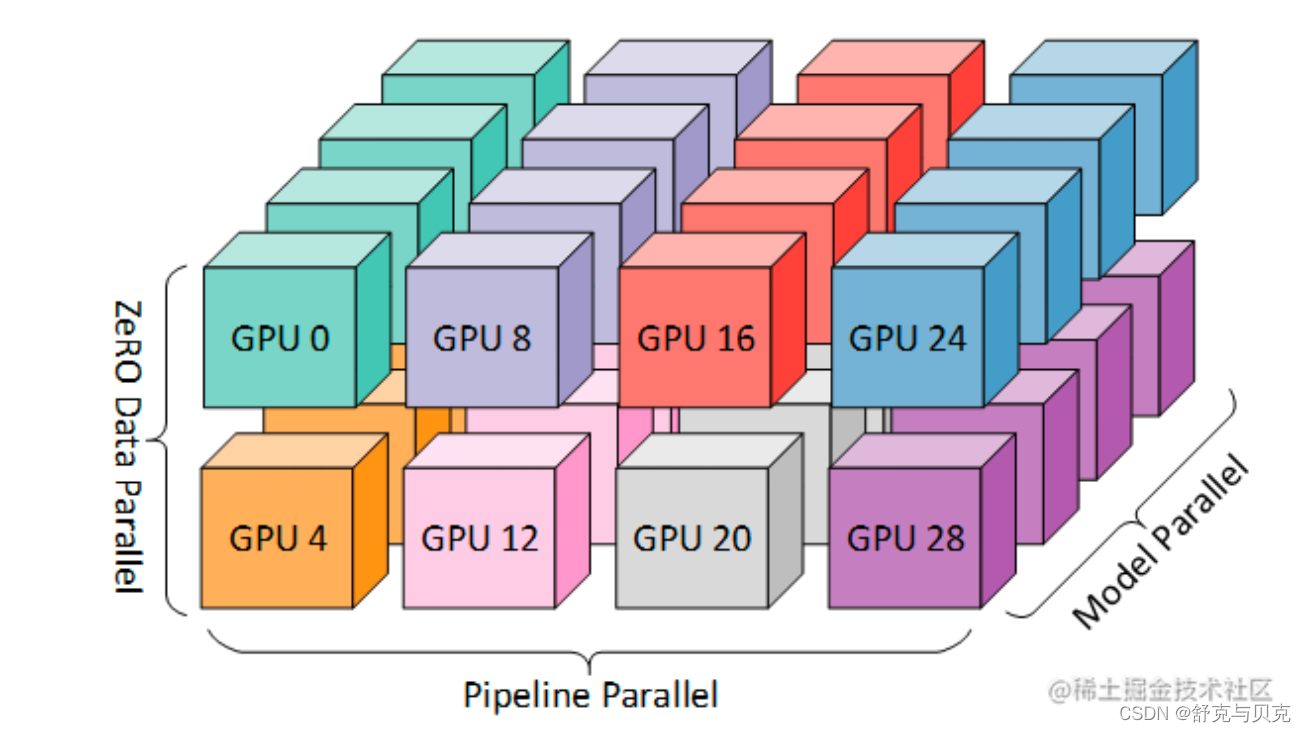
3. ZeRO --- DP + PP + TP
作为 DeepSpeed 的主要功能之一,它是 DP 的超级可伸缩增强版,并启发了 PyTorch FSDP 的诞生。通常它是一个独立的功能,不需要 PP 或 TP。但它也可以与 PP、TP 结合使用。
当 ZeRO-DP 与 PP 和 TP 结合使用时,通常只启用 ZeRO 阶段 1(只对优化器状态进行分片)
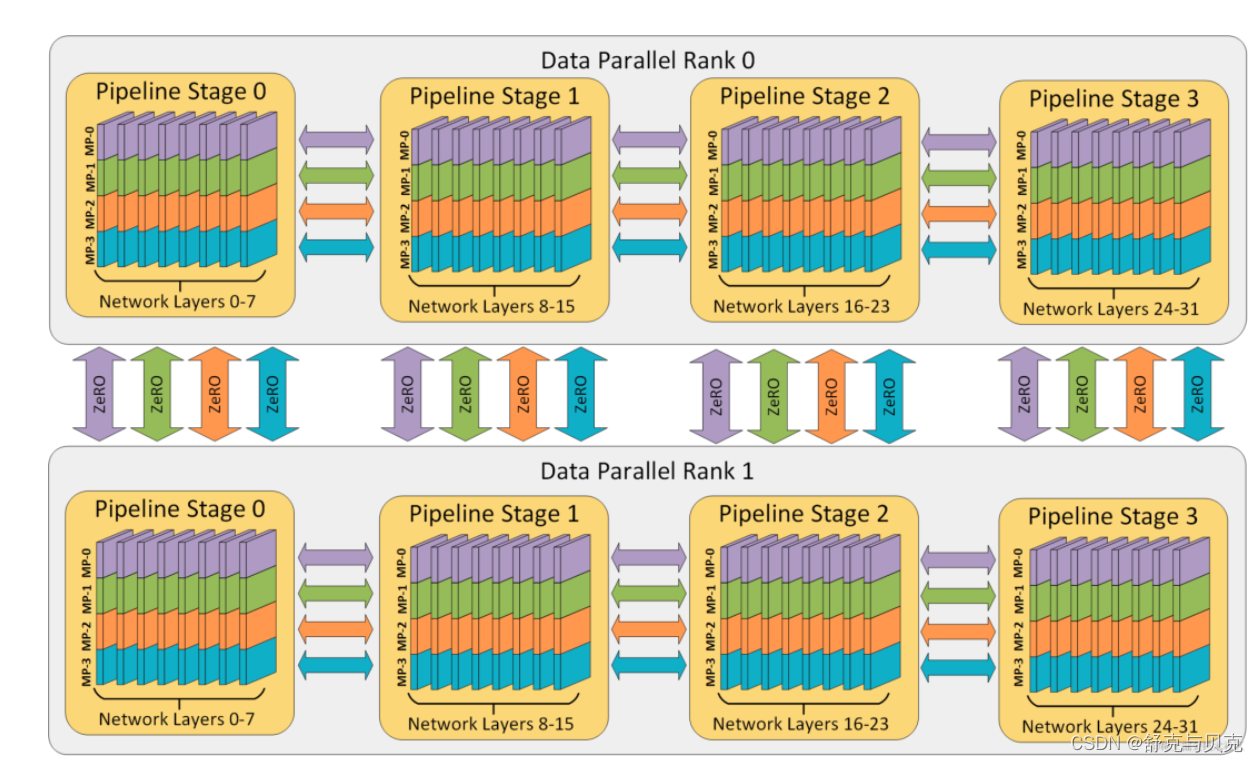
而 ZeRO 阶段 2 还会对梯度进行分片,ZeRO 阶段 3 还会对模型权重进行分片。
虽然理论上可以将 ZeRO 阶段 2 与 流水线并行PP一起使用,但它会对性能产生不良影响。每个 micro batch 都需要一个额外的 reduce-scatter 通信来在分片之前聚合梯度,这会增加潜在的显著通信开销。根据流水线并行的性质,我们会使用小的 micro batch ,并把重点放在算术强度 (micro batch size) 与最小化流水线气泡 (micro batch 的数量) 两者间折衷。因此,增加的通信开销会损害流水线并行。
此外,由于 PP,层数已经比正常情况下少,因此并不会节省很多内存。PP 已经将梯度大小减少了 1/PP,因此在此基础之上的梯度分片和纯 DP 相比节省不了多少内存。
除此之外,我们也可以采用 DP + TP 进行组合、也可以使用 PP + TP 进行组合,还可以使用 ZeRO3 代替 DP + PP + TP,ZeRO3 本质上是DP+MP的组合,并且无需对模型进行过多改造,使用更方便。
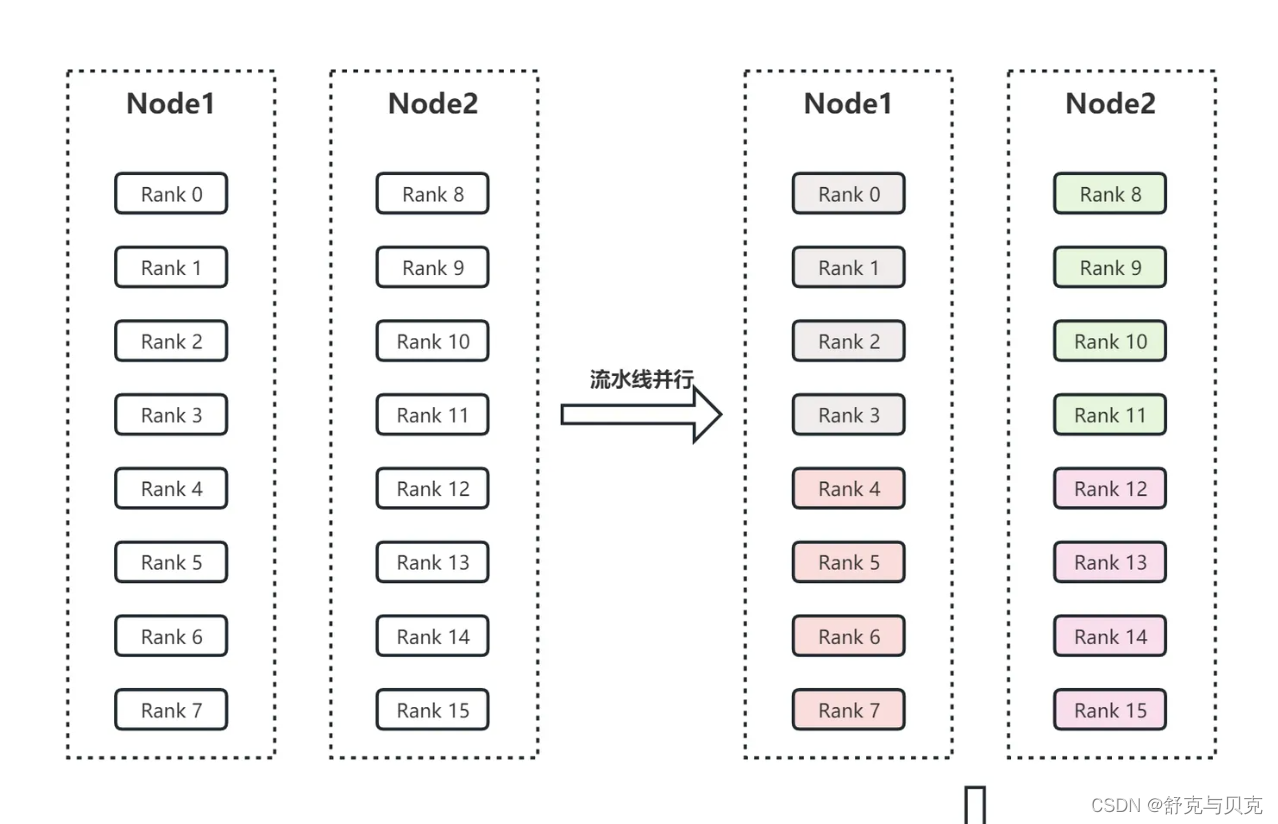
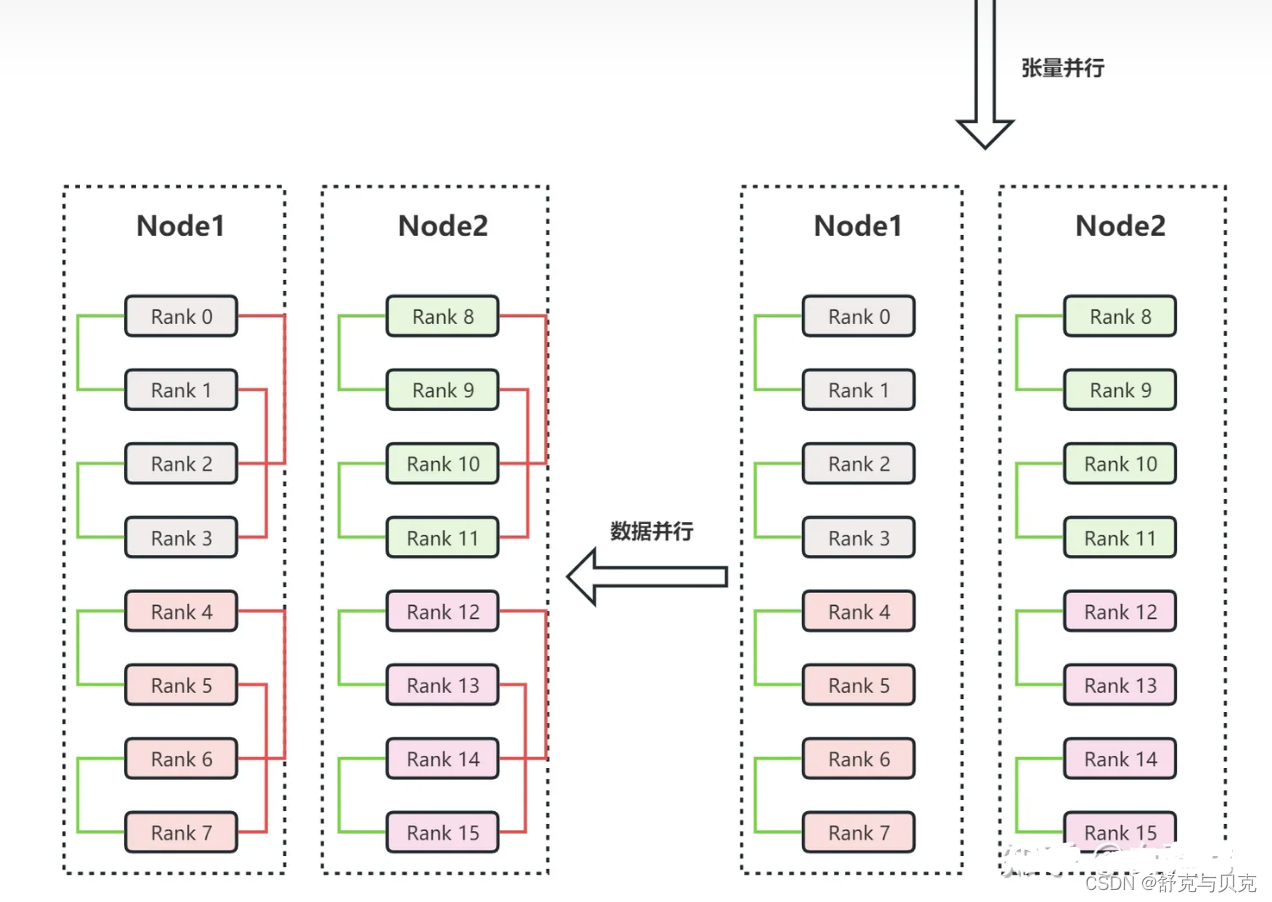
假设有两个节点Node1和Node2,每个节点有8个GPU,共计16个GPU。16个GPU的编号分别为Rank0、Rank1、...、Rank15。此外,假设用户设置流水线并行度为4,张量并行度为2。
1.流水线并行。流水线并行会将整个模型划分为4份,这里称为sub_model_1至sub_model_4。每连续的4张GPU负责一个sub_model。即上图右上角中,相同颜色的GPU Rank0-3(sub_model_1), Rank4-7(sub_model_2) Rank8-11(sub_model_3) Rank12-15(sub_model_4) 负责相同的sub_model。
2. 张量并行。张量并行会针对流水线并行中的sub_model来进行张量的拆分。
即Rank0和Rank1负责一份sub_model_1,Rank2和Rank3负责另一份sub_model_1;
Rank4和Rank5负责sub_model_2,Rank6和Rank7负责另一份sub_model_2;以此类推。上图右下角中,绿色线条表示单个张量并行组,每个张量并行组都共同负责某个具体的sub_model。
3. 数据并行。数据并行的目的是要保证并行中的相同模型参数读取相同的数据。经过流水线并行和张量并行后,Rank0和Rank2负责相同的模型参数,所以Rank0和Rank2是同一个数据并行组。上图左上角中的红色线条表示数据并行组。
为什么3D并行需要按上面的方式划分GPU呢?首先,模型并行是三种策略中通信开销最大的,所以优先将模型并行组放置在一个节点中,以利用较大的节点内带宽。其次,流水线并行通信量最低,因此在不同节点之间调度流水线,这将不受通信带宽的限制。最后,若张量并行没有跨节点,则数据并行也不需要跨节点;否则数据并行组也需要跨节点。
流水线并行和张量并行减少了单个显卡的显存消耗,提高了显存效率。但是,模型划分的太多会增加通信开销,从而降低计算效率。ZeRO-DP不仅能够通过将优化器状态进行划分来改善显存效率,而且还不会显著的增加通信开销。

















 1200
1200

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









