









前段时间为了分享激光slam,重新整理学习了ROS下开源的几种激光slam. 现在记下这段时间学习的一些关键点。
1. 开源代码repo 说明:
1.1 gmapping
/slam_gmapping ROS封装的gmapping节点
/openslam_gmapping gmapping的实现源码
1.2 Hector
1.3 karto
/slam_karto ROS封装的karto节点
/open_karto karto内部实现
/navigation_2d
1.4 cartographer
googlecartographer/cartographer 算法实现
googlecartographer/cartographer_ros
2. 算法组成说明
2.1 算法框架
(1) 滤波框架:
基于KF,EKF,UKF等,这些一般在比较早期的提特征方式出现,不在当前热门开源的范围内。
基于PF: RBPF. gmapping就是基于这种方式进行的。
(2) 图优化框架: karto cartographer
将激光帧或子图作为节点,形成彼此之间的关系边,构建一张关联的图, 最后利用非线性优化调整每个节点的pose,最终以调整后的结果形成新的map,
(3)单纯scanmatcher: hector
2.2 scanMatcher部分:
slam的处理离不开连续帧间的处理, 对应激光就是scan-scan, 由于连续帧间的匹配没有scan-map匹配稳定,激光中基本采取的是scan-map的方式,(map也就是当前激光帧与前面生成的地图、子图或利用序列激光生成的地图)scanMatcher其中需要注意的点往往就是: 匹配速度要快,匹配准确度要高。
2.3 地图的生成: 2D激光中地图的形式基本上是采用占据栅格的 gridMap的形式
增量式地图:后面的添加都是在前面的统计基础上进行。。 地图有一步开辟,后面慢慢填充, 动态开辟空间,
每次全更新: 每次地图都是利用调整后的全部激光数据,或子图生成地图。(基本就是对应图优化框架)
3. 框架详解
3.1 gmapping 采取的RBPF的框架:详细见论文
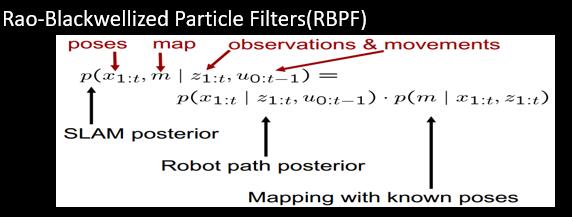
它将slam问题(利用历史输入和观测 同时 定位机器人的pose和构建环境地图的问题)转化为定位机器人的轨迹(MCL定位)和构建地图两部分。以粒子的方式模拟机器人位置分布的概率。每个粒子代表一个机器人分布的可能,存储所有历史时刻的pose,map,和对应权重。 (简单点理解, 如果粒子数量无限多,那总有一个粒子代表真实吧, 那它的轨迹和地图就是所求, 刚开始粒子权重都一样,但随着不同的输入与观测与地图的对应差异,越接近真实的机器人表示的粒子权重会增加,反之逐渐减小)
需要关注的问题: 计算性能考虑,粒子数量不可能是无限增加的;
粒子有限,(更新中出现问题后调整不过来了)那粒子怎么体现更真实的机器人pose, (weight update + resample)

3.2 图优化框架: 以karto为例介绍
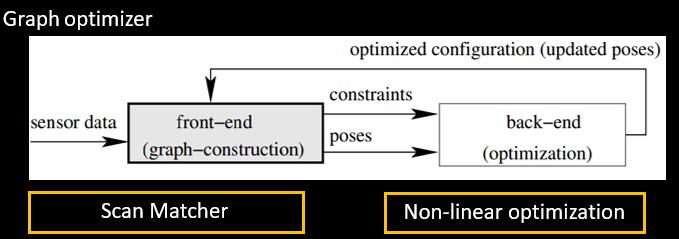
图优化框架主要分为前端的图构建过程,闭环检测,和对构建的图的约束关系进行非线性优化调整每个node的pose. 前端的过程其实就是scanMatcher过程, 闭环检测其实也就是scanMatcher的过程。
vslam的图构建大家一般比较好理解, 以为图像的信息丰富,只需要遍历关键帧,找出与当前帧强匹配的帧。(key-key + 约束)。已建立feature(ref - map))在当前pose(可以认为视觉里程计)下的观测预测(map 成像模型转化到 image frame),图像当前观测偏差(一般认为为较准确反应真实)与 观测预测的偏差作为调整的目标函数(优化feature的pose).
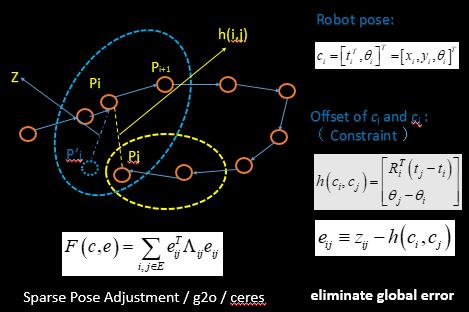
激光的不同在于其信息量较少, 依据scan-scan的闭环检测无法在实际中使用,基本采取scan-map的形式。我认为最大的不同就是当前观测量的使用。 图优化的问题是减小机器人运动过程中的累积误差。(可以先假定这样的认识, 机器人前面的观测对应的子地图 比后面再经过相同地方的子地图更能反映世界坐标系下的地图信息),那当前观测量(Z)我们可以对应依据前段地图(图中蓝色)与当前scan匹配得到调整pose Pj' , 当前观测预测(h(i,j))依据当前子图(图中黄色)与当前scan匹配得到调整pose Pj. 如果没有累积误差那e(i,j)应该为零, 现在就是构建优化函数优化pose使得最后的偏差尽可能小。。。
下面是karto link构建和闭环检测的过程说明:


4. scanMatcher : scan-map
先介绍下sanmatcher匹配好坏的评价标准。 其实就是调整当前帧激光束对应的位置使得激光束与前面生成的gridmap尽量的重合,重合越高,分数越高,越具有参考价值。
当前开源算法中scanMatcher采取的方法主要是以下四种:

关注点: pose调整的过程要快(范围要小), 调整准确,尽可能避免局部最优的干扰(范围要大)。 收敛要快 ==》 金字塔/分层/多分辨率
scanMatcher 主要涉及两个评价函数, 一个score用于优化调整粒子pose作为参考, 一个likelihoodAndScore用于确定优化后的每个粒子pose对应的权重更新作为参考。 基本依据就是每预帧激光的每个激光点预测距离与统计距离(预测点对应栅格单元的pose统计均值)的高斯距离的统计。

score(快)0依赖收敛判定, 迭代次数与步长,搜索范围限制。 计算的是每一次迭代的分数, 因此要求尽可能快, 所以只考虑了端点的匹配情况,评分很直接。
likelihoodAndScore (准 / 稳)的计算针对每个粒子权重,总的时长,只受限于粒子数, 计算权重评分时,为了更稳定,引入了m_kernelSize的矩形窗口选择,同时保证准确性,参考了 端点hit与邻近端点的free对应cell的阈值。 使得这时的激光束与地图的匹配评分更加鲁棒。
score
inline double ScanMatcher::score(const ScanMatcherMap& map, const OrientedPoint& p, const double* readings) const{
double s=0;
const double * angle=m_laserAngles+m_initialBeamsSkip;
OrientedPoint lp=p;
lp.x+=cos(p.theta)*m_laserPose.x-sin(p.theta)*m_laserPose.y;
lp.y+=sin(p.theta)*m_laserPose.x+cos(p.theta)*m_laserPose.y;
lp.theta+=m_laserPose.theta;
unsigned int skip=0;
double freeDelta=map.getDelta()*m_freeCellRatio;
for (const double* r=readings+m_initialBeamsSkip; r<readings+m_laserBeams; r++, angle++){
skip++;
skip=skip>m_likelihoodSkip?0:skip;
if (skip||*r>m_usableRange||*r==0.0) continue;
Point phit=lp;
phit.x+=*r*cos(lp.theta+*angle);
phit.y+=*r*sin(lp.theta+*angle);
IntPoint iphit=map.world2map(phit);
Point pfree=lp;
pfree.x+=(*r-map.getDelta()*freeDelta)*cos(lp.theta+*angle);
pfree.y+=(*r-map.getDelta()*freeDelta)*sin(lp.theta+*angle);
pfree=pfree-phit;
IntPoint ipfree=map.world2map(pfree);
bool found=false;
Point bestMu(0.,0.);
for (int xx=-m_kernelSize; xx<=m_kernelSize; xx++)
{
for (int yy=-m_kernelSize; yy<=m_kernelSize; yy++){
IntPoint pr=iphit+IntPoint(xx,yy);
IntPoint pf=pr+ipfree;
//AccessibilityState s=map.storage().cellState(pr);
//if (s&Inside && s&Allocated){
const PointAccumulator& cell=map.cell(pr);
const PointAccumulator& fcell=map.cell(pf);
if (((double)cell )> m_fullnessThreshold && ((double)fcell )<m_fullnessThreshold){
Point mu=phit-cell.mean();
if (!found){
bestMu=mu;
found=true;
}else
bestMu=(mu*mu)<(bestMu*bestMu)?mu:bestMu;
}
//}
}
}
if (found)
s+=exp(-1./m_gaussianSigma*bestMu*bestMu);
}
return s;
}
likelihoodAndScore:
inline unsigned int ScanMatcher::likelihoodAndScore(double& s, double& l, const ScanMatcherMap& map, const OrientedPoint& p, const double* readings) const{
using namespace std;
l=0;
s=0;
const double * angle=m_laserAngles+m_initialBeamsSkip;
OrientedPoint lp=p;//lp laser_pose ref map
lp.x+=cos(p.theta)*m_laserPose.x-sin(p.theta)*m_laserPose.y;
lp.y+=sin(p.theta)*m_laserPose.x+cos(p.theta)*m_laserPose.y;
lp.theta+=m_laserPose.theta;
double noHit=nullLikelihood/(m_likelihoodSigma);
unsigned int skip=0;
unsigned int c=0;
double freeDelta=map.getDelta()*m_freeCellRatio;
for (const double* r=readings+m_initialBeamsSkip; r<readings+m_laserBeams; r++, angle++){
skip++;
skip=skip>m_likelihoodSkip?0:skip;
if (*r>m_usableRange) continue;
if (skip) continue;
Point phit=lp;//laser hit endpoint
phit.x+=*r*cos(lp.theta+*angle);
phit.y+=*r*sin(lp.theta+*angle);
IntPoint iphit=map.world2map(phit);
Point pfree=lp; //laser free nearestly endpoint
pfree.x+=(*r-freeDelta)*cos(lp.theta+*angle);
pfree.y+=(*r-freeDelta)*sin(lp.theta+*angle);
pfree=pfree-phit;
IntPoint ipfree=map.world2map(pfree);
bool found=false;
Point bestMu(0.,0.);
for (int xx=-m_kernelSize; xx<=m_kernelSize; xx++)
{
for (int yy=-m_kernelSize; yy<=m_kernelSize; yy++){
IntPoint pr=iphit+IntPoint(xx,yy);
IntPoint pf=pr+ipfree;
//AccessibilityState s=map.storage().cellState(pr);
//if (s&Inside && s&Allocated){
const PointAccumulator& cell=map.cell(pr);
const PointAccumulator& fcell=map.cell(pf);
if (((double)cell )>m_fullnessThreshold && ((double)fcell )<m_fullnessThreshold){
Point mu=phit-cell.mean();
if (!found){
bestMu=mu;
found=true;
}else
bestMu=(mu*mu)<(bestMu*bestMu)?mu:bestMu;
}
//}
}
}
if (found){
s+=exp(-1./m_gaussianSigma*bestMu*bestMu);
c++;
}
if (!skip){
double f=(-1./m_likelihoodSigma)*(bestMu*bestMu);
l+=(found)?f:noHit;
}
}
return c;
}















 9157
9157

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









