







一、实验目的
掌握采用 DCGAN生成新的Anime卡通图片
二、实验内容
1.指对Anime数据集生成新的图片样本的任务,借鉴DCGAN_minst实验和WGAN_GP_Anime的实验结果,实现DCGAN_Anime生成新图片样本的实验。
2.借鉴DCGAN_mins、WGAN_GP_Anime教学案例,合理DCGAN_Anime实战中epochs\损失函数的设置
三、实验结果
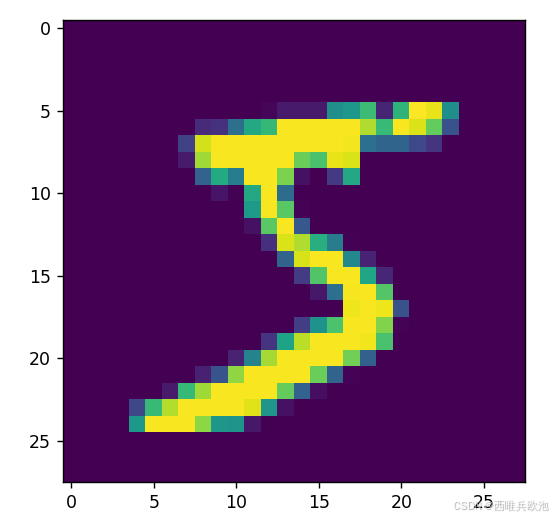
加载MNIST数据集,并显示其中的第一张图像:
测试模型的可行性。随机生成1x100的噪声序列传入模型并查看结果。
每 15个epoch保存一次模型,开始时较为模糊。
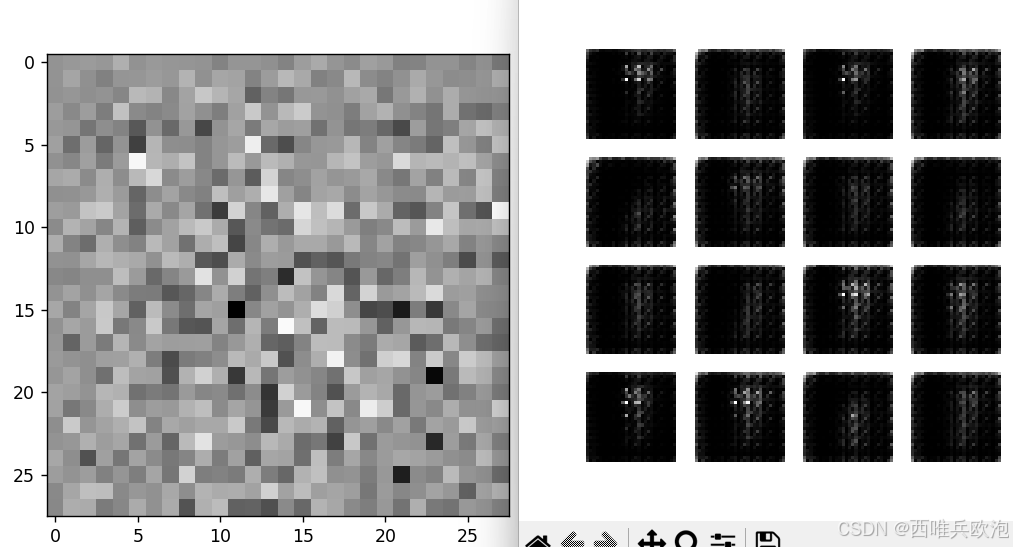
进行模型训练,并查看最后一次的训练结果:

每间隔 100 个 Epoch,进行一次图片生成测试。
通过从先验分布中随机采样隐向量,送入生成器获得生成图片,并保存为文件。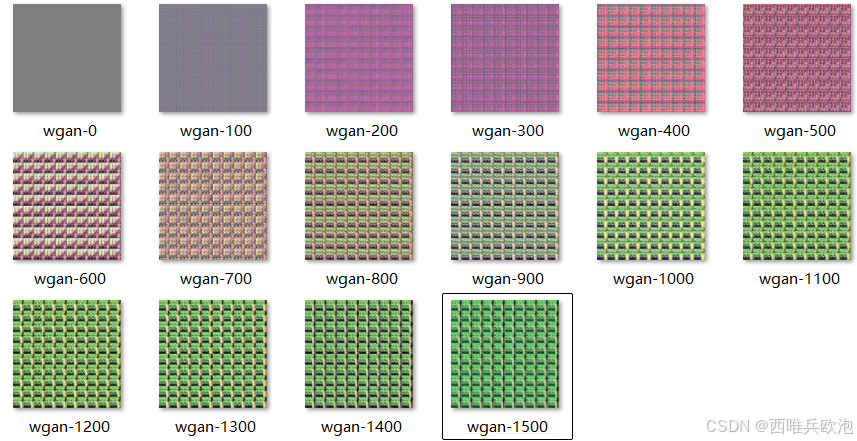
四、源码
数据集私信作者
DCGAN_MINST代码
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
import glob
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
plt.imshow(train_images[0])
plt.show()
#图片预处理,修改图片形状以及标准化。这里将图片标准化到[-1,1]区间,因此使用127.5
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # 将图片标准化到 [-1, 1] 区间内
#打乱图片顺序并将数据集批量化
BUFFER_SIZE = 60000
BATCH_SIZE = 256
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
"""定义生成器。一开始层的input_shape定为100,因为准备生成大小为1x100大小噪声并传入模型。
为什么不是100x1而是1x100?因为模型的第一层为100x12544(7*7*256个神经元)。
因此为了满足矩阵相乘,将大小设置为该尺寸。相乘完后得到了1x12544大小的向量。
但是因为最后输出的图片是以28x28x1的形式的(和MNIST数据集匹配)。因从需要先将图片reshape成(7x7x256),
之后再通过3次反卷积生成图片(28,28,1)的满足要求的图片大小"""
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7 * 7 * 256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256))) # 修改图片大小
assert model.output_shape == (None, 7, 7, 256) # batch size 没有限制
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False)) # 反卷积
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
#测试模型的可行性。随机生成1x100的噪声序列传入模型并查看结果
generator = make_generator_model()
noise = tf.random.normal([1,100])
generated_image = generator(noise,training=False) #设置模型为未训练模式
plt.imshow(generated_image[0,:,:,0],cmap='gray')
# 构建判别器
"""判别器的构造比较简单,其实就是对图片不断的进行卷积并提取特征,最后转为一维向量得到结果。这和前面的分类案例的过程差不多。"""
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same', input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
#将刚才生成的噪声图片传入判别器,验证判别器的可行性
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
#模型参数设置
#1.定义损失函数。因为是真(1)和假(0)分类,因此选用binarycrossentropy。这里的from_logits意思是直接让分类结果为1或0,而不是返回概率。
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
#2.定义判别器损失函数
"""因为真实图片最后判别的结果必须要为1,
因此real_loss的意思是真实的图片x和正确判别结果y(全部为1的图片矩阵)的loss值。
而假的图片最后判别的结果是0,因此fake_loss的意思是生成的假图片x和正确判别结果y(全部为0的图片矩阵的)的loss值。"""
def discriminator_loss(real_output,fake_output):
real_loss = cross_entropy(tf.ones_like(real_output),real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output),fake_output)
total_loss = real_loss + fake_loss #总的loss
return total_loss
#3.定义生成器损失函数
#因为要让生成器生成以假乱真的图片,如果判别器判别的结果为(1)真,则会传给生成器(1)真。因此在生成器中将判别器的判别结果和1(真)之间的loss即为我们的生成器损失函数。
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output),fake_output)
#4.定义优化器
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
#5.定义checkpoint。训练时自动保存
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir,"ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
#6.定义训练次数和噪声维度等参数
EPOCHS = 40
noise_dim = 100
num_examples_to_generate = 16
seed = tf.random.normal([num_examples_to_generate, noise_dim]) #随机种子
# 模型训练
# 1.定义每步模型训练的过程。这里要通过gradient函数自动求微分
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True) # 生成的图片
real_output = discriminator(images, training=True) # 真实图片的判别结果
fake_output = discriminator(generated_images, training=True) # 生成图片的判别结果
gen_loss = generator_loss(fake_output) # 生成器损失函数
disc_loss = discriminator_loss(real_output, fake_output) # 判别器损失函数
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables) # 生成器的梯度
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables) # 判别器的梯度
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables)) # 对生成器进行优化
discriminator_optimizer.apply_gradients(
zip(gradients_of_discriminator, discriminator.trainable_variables)) # 对判别器进行优化
# 2.定义模型训练函数
def train(dataset, epochs):
for epoch in range(epochs): # 总训练的次数
start = time.time()
for image_batch in dataset: # 一次训练时训练所有的batch
train_step(image_batch)
display.clear_output(wait=True)
generate_and_save_images(generator, epoch + 1, seed)
# 每 15个epoch保存一次模型
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
print('Time for epoch {}is{}sec'.format(epoch + 1, time.time() - start))
# 最后一个 epoch 结束后生成图片
display.clear_output(wait=True)
generate_and_save_images(generator, epochs, seed)
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i + 1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
#进行模型训练,并查看最后一次的训练结果
train(train_dataset, EPOCHS)WGAN_Anime_faces代码
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import multiprocessing
import os
import numpy as np
from PIL import Image
import glob
import matplotlib.pyplot as plt # 新增用于绘图的库
# GAN模型结构
class Generator(keras.Model):
def __init__(self):
super(Generator, self).__init__()
# z:[b,100]=>[b,3*3*512]=>[b,3,3,512]=>[6,64,64,3]
self.fc = layers.Dense(3 * 3 * 512)
self.conv1 = layers.Conv2DTranspose(256, 3, 3, 'valid')
self.bn1 = layers.BatchNormalization()
self.conv2 = layers.Conv2DTranspose(128, 5, 2, 'valid')
self.bn2 = layers.BatchNormalization()
self.conv3 = layers.Conv2DTranspose(3, 4, 3, 'valid')
def call(self, inputs, training=None):
# [z,100]=>[z,3*3*512]
x = self.fc(inputs)
x = tf.reshape(x, [-1, 3, 3, 512])
x = tf.nn.leaky_relu(x)
#
x = tf.nn.leaky_relu(self.bn1(self.conv1(x), training=training))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = self.conv3(x)
x = tf.tanh(x)
return x
class Discriminator(keras.Model):
def __init__(self):
super(Discriminator, self).__init__()
# [b,64,64,3]=>[b,1]
self.conv1 = layers.Conv2D(64, 5, 3, 'valid')
self.conv2 = layers.Conv2D(128, 5, 3, 'valid')
self.bn2 = layers.BatchNormalization()
self.conv3 = layers.Conv2D(256, 5, 3, 'valid')
self.bn3 = layers.BatchNormalization()
# [b,h,w,c]=>[b,-1]
self.flatten = layers.Flatten()
self.fc = layers.Dense(1)
def call(self, inputs, training=None):
x = tf.nn.leaky_relu(self.conv1(inputs))
x = tf.nn.leaky_relu(self.bn2(self.conv2(x), training=training))
x = tf.nn.leaky_relu(self.bn3(self.conv3(x), training=training))
# [b,h,w,c]=>[b,-1]
x = self.flatten(x)
# [b,-1]=>[b,1]
logits = self.fc(x)
return logits
# 数据集处理
def make_anime_dataset(img_paths,
batch_size,
resize=64,
drop_remainder=True,
shuffle=True,
repeat=1):
@tf.function
def map_fn(img):
img = tf.image.resize(img, [resize, resize])
img = tf.clip_by_value(img, 0, 255)
img = img / 127.5 - 1
return img
dataset = disk_image_batch_dataset(img_paths,
batch_size,
drop_remainder=drop_remainder,
map_fn=map_fn,
shuffle=shuffle,
repeat=repeat)
img_shape = (resize, resize, 3)
len_dataset = len(img_paths) // batch_size
return dataset, img_shape, len_dataset
def batch_dataset(dataset,
batch_size,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
# set defaults
if n_map_threads is None:
n_map_threads = multiprocessing.cpu_count()
if shuffle and shuffle_buffer_size is None:
shuffle_buffer_size = max(batch_size * 128, 2048) # set the minimum buffer size as 2048
# [*] it is efficient to conduct `shuffle` before `map`/`filter` because `map`/`filter` is sometimes costly
if shuffle:
dataset = dataset.shuffle(shuffle_buffer_size)
if not filter_after_map:
if filter_fn:
dataset = dataset.filter(filter_fn)
if map_fn:
dataset = dataset.map(map_fn, num_parallel_calls=n_map_threads)
else: # [*] this is slower
if map_fn:
dataset = dataset.map(map_fn, num_parallel_calls=n_map_threads)
if filter_fn:
dataset = dataset.filter(filter_fn)
dataset = dataset.batch(batch_size, drop_remainder=drop_remainder)
dataset = dataset.repeat(repeat).prefetch(n_prefetch_batch)
return dataset
def memory_data_batch_dataset(memory_data,
batch_size,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
dataset = tf.data.Dataset.from_tensor_slices(memory_data)
dataset = batch_dataset(dataset,
batch_size,
drop_remainder=drop_remainder,
n_prefetch_batch=n_prefetch_batch,
filter_fn=filter_fn,
map_fn=map_fn,
n_map_threads=n_map_threads,
filter_after_map=filter_after_map,
shuffle=shuffle,
shuffle_buffer_size=shuffle_buffer_size,
repeat=repeat)
return dataset
def disk_image_batch_dataset(img_paths,
batch_size,
labels=None,
drop_remainder=True,
n_prefetch_batch=1,
filter_fn=None,
map_fn=None,
n_map_threads=None,
filter_after_map=False,
shuffle=True,
shuffle_buffer_size=None,
repeat=None):
"""
Batch dataset of disk image for PNG and JPEG.
img_paths : 1d-tensor/ndarray/list of str
labels : nested structure of tensors/ndarrays/lists
"""
if labels is None:
memory_data = img_paths
else:
memory_data = (img_paths, labels)
def parse_fn(path, *label):
img = tf.io.read_file(path)
img = tf.image.decode_png(img, 3) # fix channels to 3
return (img,) + label
if map_fn: # fuse `map_fn` and `parse_fn`
def map_fn_(*args):
return map_fn(*parse_fn(*args))
else:
map_fn_ = parse_fn
dataset = memory_data_batch_dataset(memory_data,
batch_size,
drop_remainder=drop_remainder,
n_prefetch_batch=n_prefetch_batch,
filter_fn=filter_fn,
map_fn=map_fn_,
n_map_threads=n_map_threads,
filter_after_map=filter_after_map,
shuffle=shuffle,
shuffle_buffer_size=shuffle_buffer_size,
repeat=repeat)
return dataset
# 训练相关函数
def save_result(val_out, val_block_size, image_path, color_mode): # 把图片拼接后保存
def preprocess(img):
img = ((img + 1.0) * 127.5).astype(np.uint8)
return img
preprocesed = preprocess(val_out)
final_image = np.array([])
single_row = np.array([])
for b in range(val_out.shape[0]):
# concat image into a row
if single_row.size == 0:
single_row = preprocesed[b, :, :, :]
else:
single_row = np.concatenate((single_row, preprocesed[b, :, :, :]), axis=1)
# concat image row to final_image
if (b + 1) % val_block_size == 0:
if final_image.size == 0:
final_image = single_row
else:
final_image = np.concatenate((final_image, single_row), axis=0)
# reset single row
single_row = np.array([])
if final_image.shape[2] == 1:
final_image = np.squeeze(final_image, axis=2)
Image.fromarray(final_image).save(image_path)
def celoss_ones(logits):
# logits : [b, 1]
# labels : [b] = [1, 1, 1, 1,...]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=tf.ones_like(logits))
return tf.reduce_mean(loss)
def celoss_zeros(logits):
# logits : [b, 1]
# labels : [b] = [0, 0, 0, 0,...]
loss = tf.nn.sigmoid_cross_entropy_with_logits(logits=logits, labels=tf.zeros_like(logits))
return tf.reduce_mean(loss)
def gradient_penalty(discriminator, batch_x, fake_image):
batchsz = batch_x.shape[0]
t = tf.random.uniform([batchsz, 1, 1, 1])
# [b, 1, 1, 1] => [b, h, w, c], 把 t 广播为 batch_x 的size, 来进行插值
t = tf.broadcast_to(t, batch_x.shape)
interplate = t * batch_x + (1 - t) * fake_image
with tf.GradientTape() as tape:
tape.watch([interplate])
d_interplote_logits = discriminator(interplate, training=True)
grads = tape.gradient(d_interplote_logits, interplate)
# grads:[b, h, w, c] => [b, -1]
grads = tf.reshape(grads, [grads.shape[0], -1])
gp = tf.norm(grads, axis=1) # 对于每个样本求二范数
gp = tf.reduce_mean((gp - 1) ** 2) # 求所有样本的均方差
return gp
def d_loss_fn(generator, discriminator, batch_z, batch_x, is_training):
# 1. treat real image as real
# 2. treat generated image as fake
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
d_real_logits = discriminator(batch_x, is_training)
d_loss_real = celoss_ones(d_real_logits) # 真图片的交叉熵, 真尽可能真
d_loss_fake = celoss_zeros(d_fake_logits) # 生成图片的交叉熵,假尽可能假
gp = gradient_penalty(discriminator, batch_x, fake_image)
loss = d_loss_fake + d_loss_real + 1. * gp # lamda = 1
return loss, gp
def g_loss_fn(generator, discriminator, batch_z, is_training):
fake_image = generator(batch_z, is_training)
d_fake_logits = discriminator(fake_image, is_training)
loss = celoss_ones(d_fake_logits) # 假尽可能真
return loss
def main():
tf.random.set_seed(22)
np.random.seed(22)
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
assert tf.__version__.startswith('2.')
# 超参数
z_dim = 100
epochs = 1100 # 修改训练轮数为1000轮
batch_size = 512
learning_rate = 0.002
is_training = True
img_path = glob.glob(r'D:\tf_data\Anime_Faces\*.jpg')
dataset, img_shape, _ = make_anime_dataset(img_path, batch_size)
dataset = dataset.repeat()
db_iter = iter(dataset)
generator = Generator()
generator.build(input_shape=(None, z_dim))
discriminator = Discriminator()
discriminator.build(input_shape=(None, 64, 64, 3))
g_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
d_optimizer = tf.optimizers.Adam(learning_rate=learning_rate, beta_1=0.5)
# 用于记录损失值,方便可视化
d_losses = []
g_losses = []
gps = []
for epoch in range(epochs):
batch_z = tf.random.uniform([batch_size, z_dim], minval=-1., maxval=1.)
batch_x = next(db_iter)
# train D
with tf.GradientTape() as tape:
d_loss, gp = d_loss_fn(generator, discriminator, batch_z, batch_x, is_training)
grads = tape.gradient(d_loss, discriminator.trainable_variables)
d_optimizer.apply_gradients(zip(grads, discriminator.trainable_variables))
# train G
with tf.GradientTape() as tape:
g_loss = g_loss_fn(generator, discriminator, batch_z, is_training)
grads = tape.gradient(g_loss, generator.trainable_variables)
g_optimizer.apply_gradients(zip(grads, generator.trainable_variables))
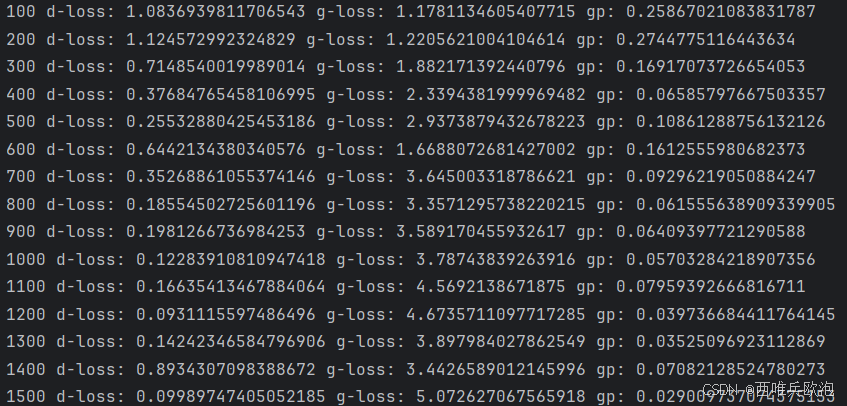
if epoch % 100 == 0:
print(epoch, 'd-loss:', float(d_loss), 'g-loss:', float(g_loss), 'gp:', float(gp))
d_losses.append(float(d_loss))
g_losses.append(float(g_loss))
gps.append(float(gp))
z = tf.random.uniform([100, z_dim])
fake_image = generator(z, training=False)
img_path = os.path.join('WGAN_images', 'wgan-%d.png' % epoch) # immages文件夹下, 图片名为:wgan-epoch.png
save_result(fake_image.numpy(), 10, img_path, color_mode='P') # 10*10, 彩色图片
# 绘制损失变化曲线
plt.plot(range(0, epochs, 100), d_losses, label='d-loss')
plt.plot(range(0, epochs, 100), g_losses, label='g-loss')
plt.plot(range(0, epochs, 100), gps, label='gp')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Variation during Training')
plt.legend()
plt.show()
if __name__ == '__main__':
main()


















 2942
2942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











