






1.训练过程展示的参数代表
刚刚开始阶段
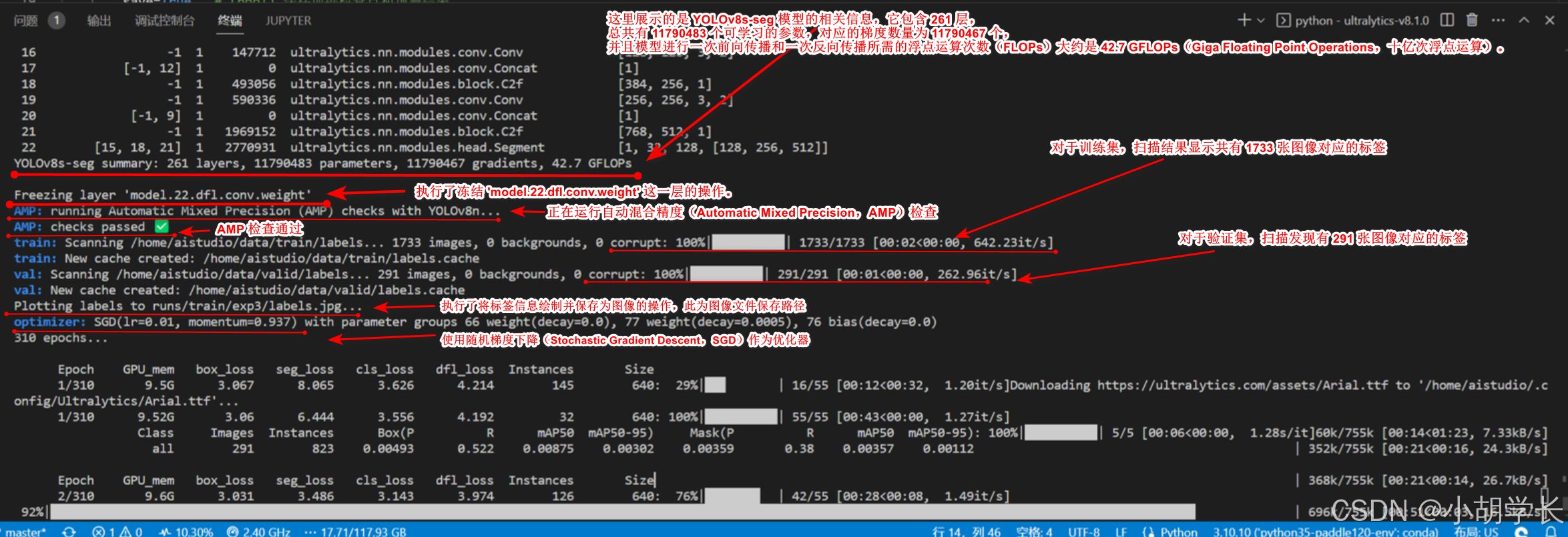
训练阶段

展示了在训练集上的各项性能指标,格式为:
| 参数 | 中文解释 |
| Class | 类别 |
| Images | 图像数量 |
| Instances | 实例数量 |
| Box (P | 边界框精度 |
| R | 边界框召回率 |
| mAP50 | 平均精度均值在 IoU 阈值为 0.5 时 |
| mAP50-95 | 平均精度均值在 IoU 阈值从 0.5 到 0.95 变化时 |
| Mask (P | 掩码精度 |
| R | 掩码召回率 |
| mAP50 | 掩码平均精度均值在 IoU 阈值为 0.5 时 |
| mAP50-95 | 掩码平均精度均值在 IoU 阈值从 0.5 到 0.95 变化时 |
2.训练后的结果
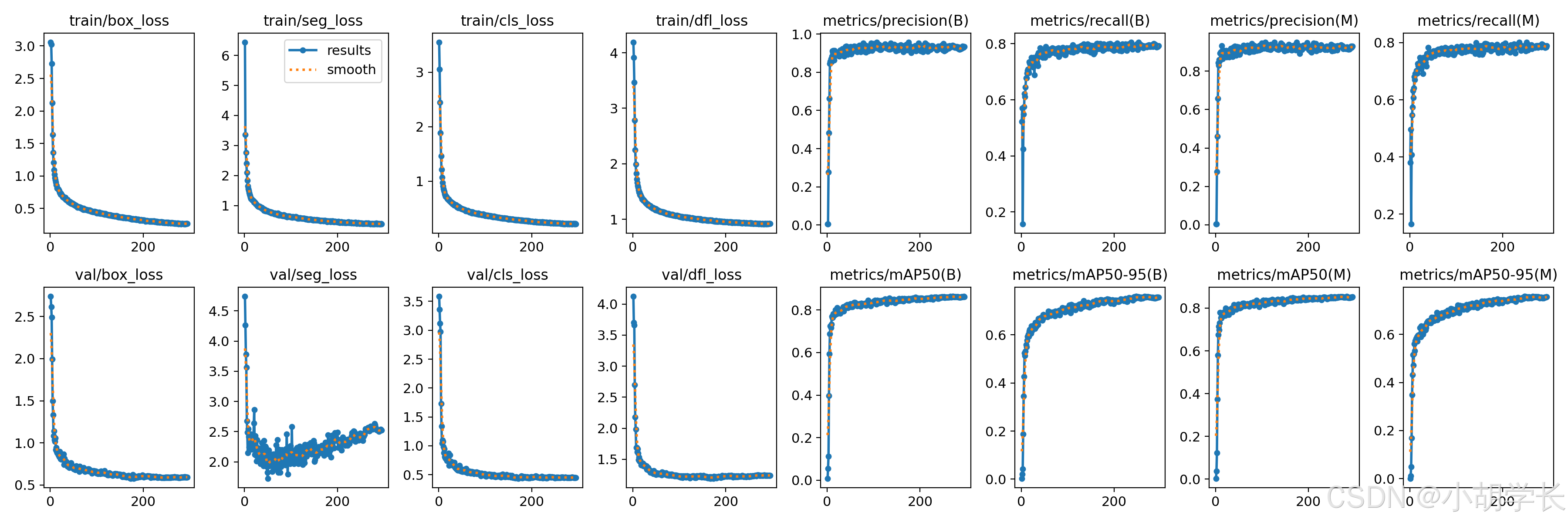
这张图片展示了多个训练和验证指标随迭代次数变化的折线图。整个图像由多个子图组成,每个子图都展示了不同指标的变化趋势。
从左到右、从上到下,这些子图分别展示了以下指标:
- train/box_loss:训练集上的边界框损失。图中蓝色曲线(标注为 “results”)和黄色点(标注为 “smooth”)显示了损失随迭代次数的变化。损失从大约 3.0 开始,逐渐下降到接近 0。
- train/seg_loss:训练集上的分割损失。损失从大约 3.0 开始,逐渐下降到接近 0。
- train/cls_loss:训练集上的分类损失。损失从大约 3.0 开始,逐渐下降到接近 0。
- train/dfl_loss:训练集上的方向场损失。损失从大约 3.0 开始,逐渐下降到接近 0。
- metrics/precision(B):边界框精度。精度从接近 0 开始,逐渐上升到接近 1。
- metrics/recall(B):边界框召回率。召回率从接近 0 开始,逐渐上升到接近 1。
- metrics/precision(M):分割精度。精度从接近 0 开始,逐渐上升到接近 1。
- metrics/recall(M):分割召回率。召回率从接近 0 开始,逐渐上升到接近 1。
- val/box_loss:验证集上的边界框损失。损失从大约 2.5 开始,逐渐下降到接近 0。
- val/seg_loss:验证集上的分割损失。损失从大约 4.5 开始,逐渐下降到接近 0。
- val/cls_loss:验证集上的分类损失。损失从大约 3.5 开始,逐渐下降到接近 0。
- val/dfl_loss:验证集上的方向场损失。损失从大约 3.0 开始,逐渐下降到接近 0。
- metrics/mAP50(B):边界框在 mAP50 指标下的表现。指标从接近 0 开始,逐渐上升到接近1。
- metrics/mAP50-95(B):边界框在 mAP50-95 指标下的表现。指标从接近 0 开始,逐渐上升到接近 1。
- metrics/mAP50(M):分割在 mAP50 指标下的表现。指标从接近 0 开始,逐渐上升到接近 1。
- metrics/mAP50-95(M):分割在 mAP50-95 指标下的表现。指标从接近 0 开始,逐渐上升到接近 1。
- 每个子图都有一个蓝色的曲线(标注为 “results”)和黄色的点(标注为 “smooth”),展示了指标的变化趋势。大部分指标在训练过程中都呈现出逐渐改善的趋势,损失逐渐降低,精度和召回率逐渐提高。 这些子图提供了对模型训练和验证过程中不同方面表现的详细洞察,有助于评估模型的性能和收敛情况。
- 蓝色曲线通常代表原始的训练或评估结果数据。这些数据是在每次迭代(例如,每个训练批次或每个训练轮次)后直接计算得到的指标值。
- 黄色点通常代表对原始数据进行平滑处理后的结果。平滑处理的目的是减少数据中的噪声和波动,以便更清晰地观察数据的整体趋势。
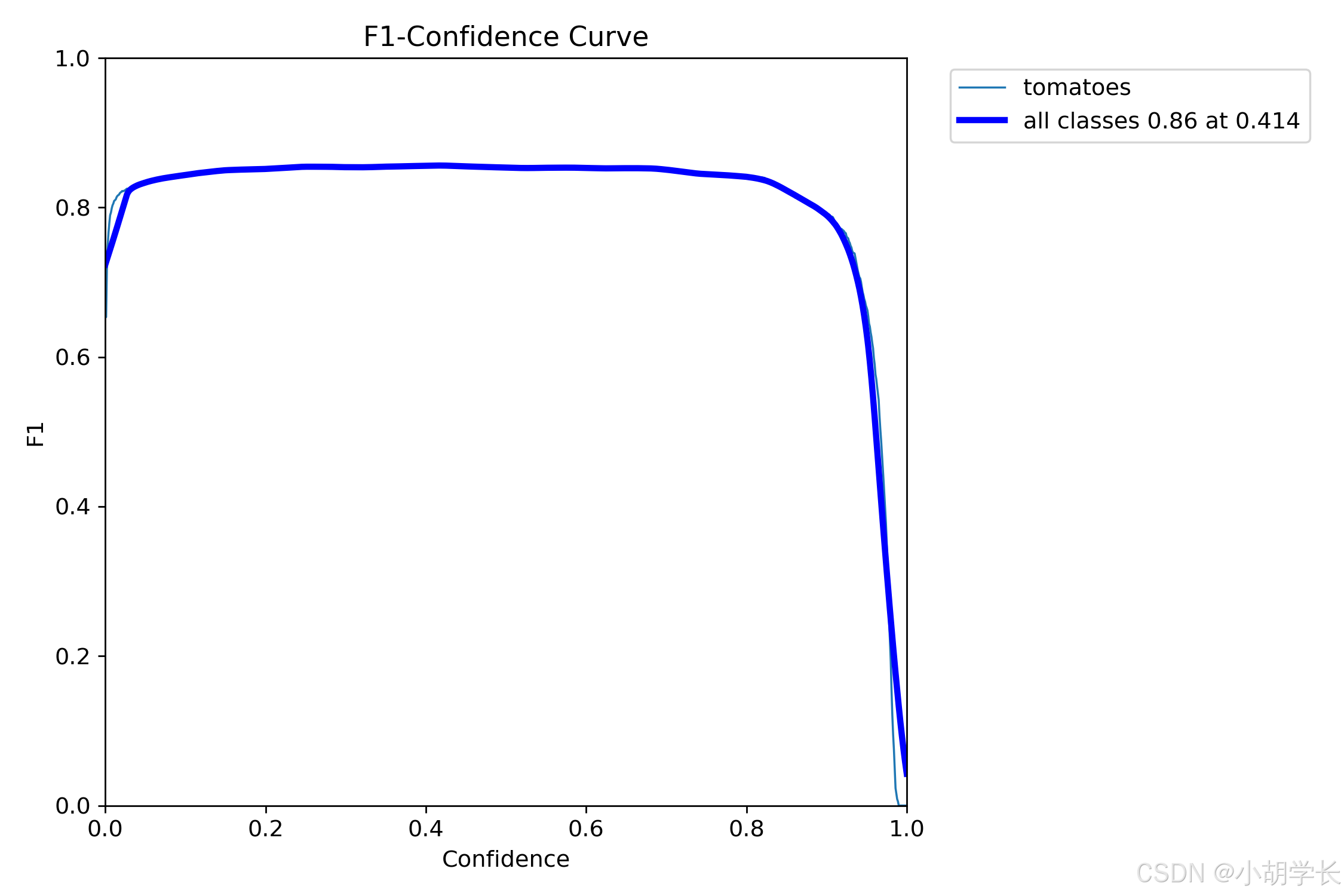
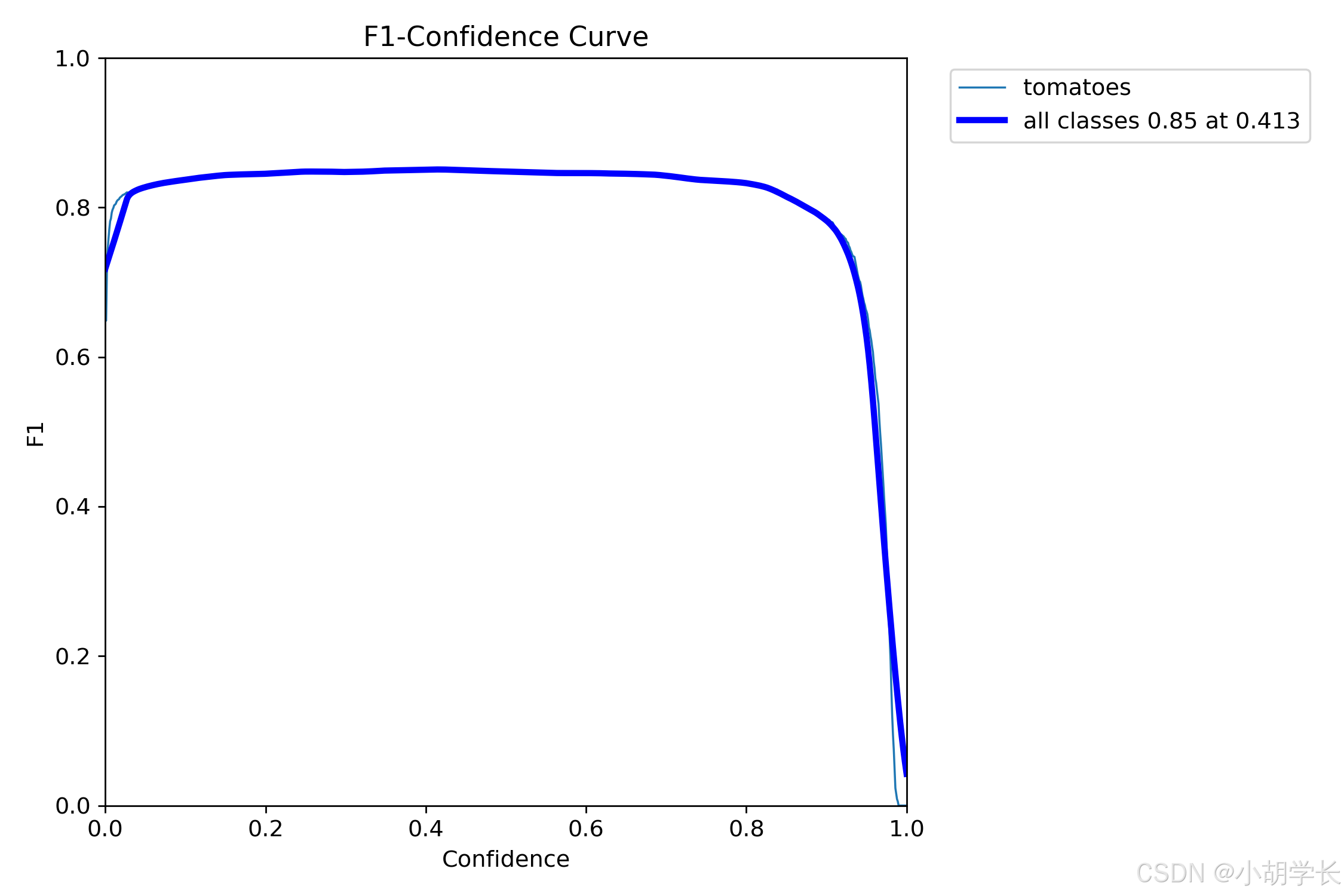
F1-置信度曲线 (BoxF1_curve.png)
- 这张图片展示了一张 F1 - Confidence Curve(F1 - 置信度曲线)图。图中有两条曲线,分别代表不同的类别。
- 这张图主要用于分析模型在不同置信度下的 F1 分数表现,特别是比较所有类别和番茄类别之间的性能差异。通过观察曲线,可以了解模型在不同置信度下的综合性能,以及不同类别之间的性能平衡情况。
-
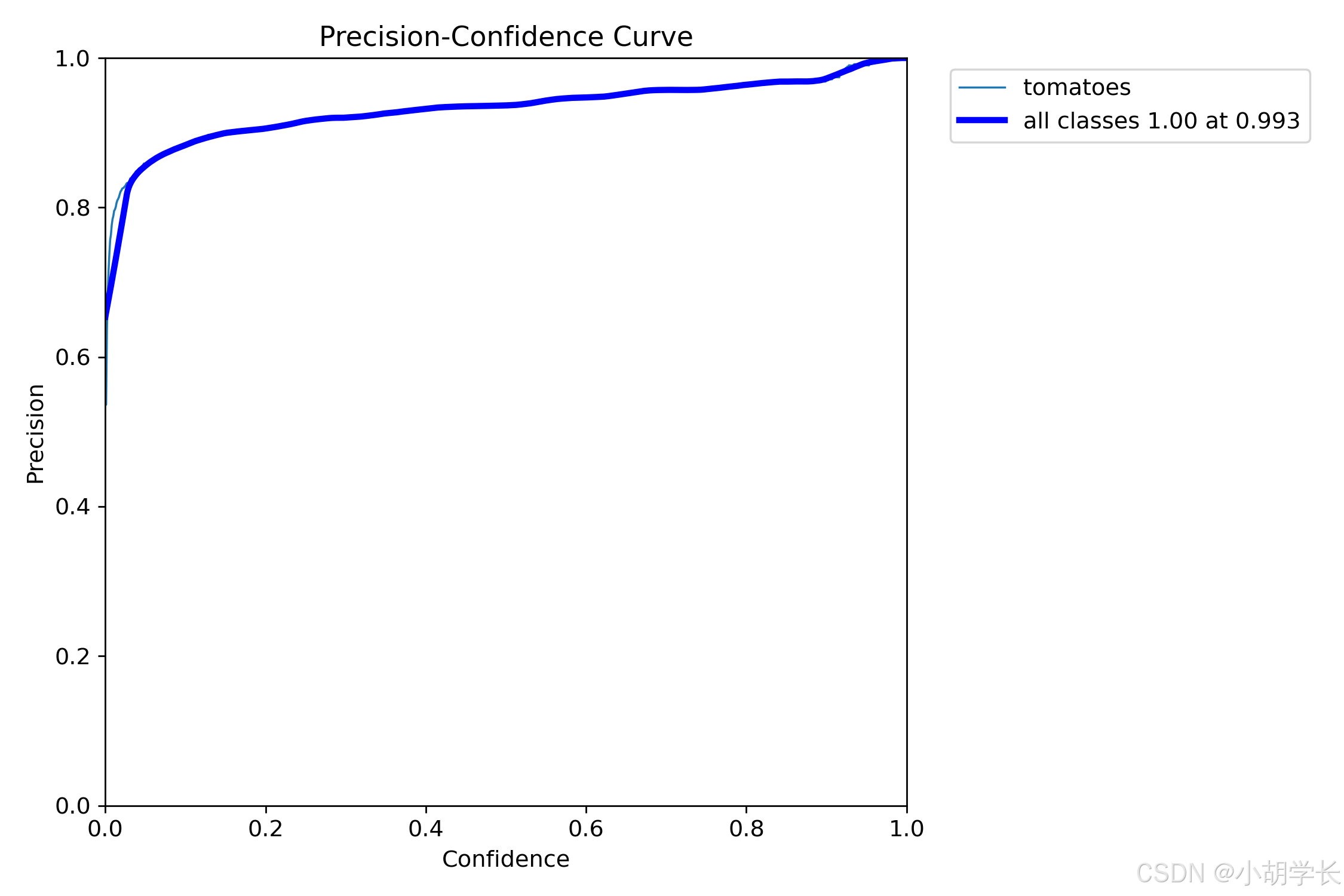
精确度-置信度曲线 (BoxP_curve.png)
- 这是一张 Precision - Confidence Curve(精确率 - 置信度曲线)图,用于展示模型在不同置信度下的精确率表现。
- 从图中可以看出,所有类别的精确率随着置信度的增加而提高,并且在高置信度时达到了完美的精确率(1.00)。这表明模型在高置信度下对所有类别的预测非常准确。
- 对于番茄类别,虽然精确率在开始时较低且波动较大,但随着置信度的增加也逐渐上升到接近 1.0 的水平,这意味着模型对番茄类别的预测在高置信度下也变得非常准确。
- 观察方法: F1分数是模型准确度的度量,结合了精确度和召回率。在这个图表中,您应该寻找F1分数最高的点,该点对应的置信度阈值通常是模型最佳的工作点。
- 观察方法: 精确度代表了模型预测为正类的样本中实际为正类的比例。在该曲线中,应关注随置信度增加,精确度如何提高,以及在哪个置信度水平上精确度开始下降,这有助于确定阈值设定。
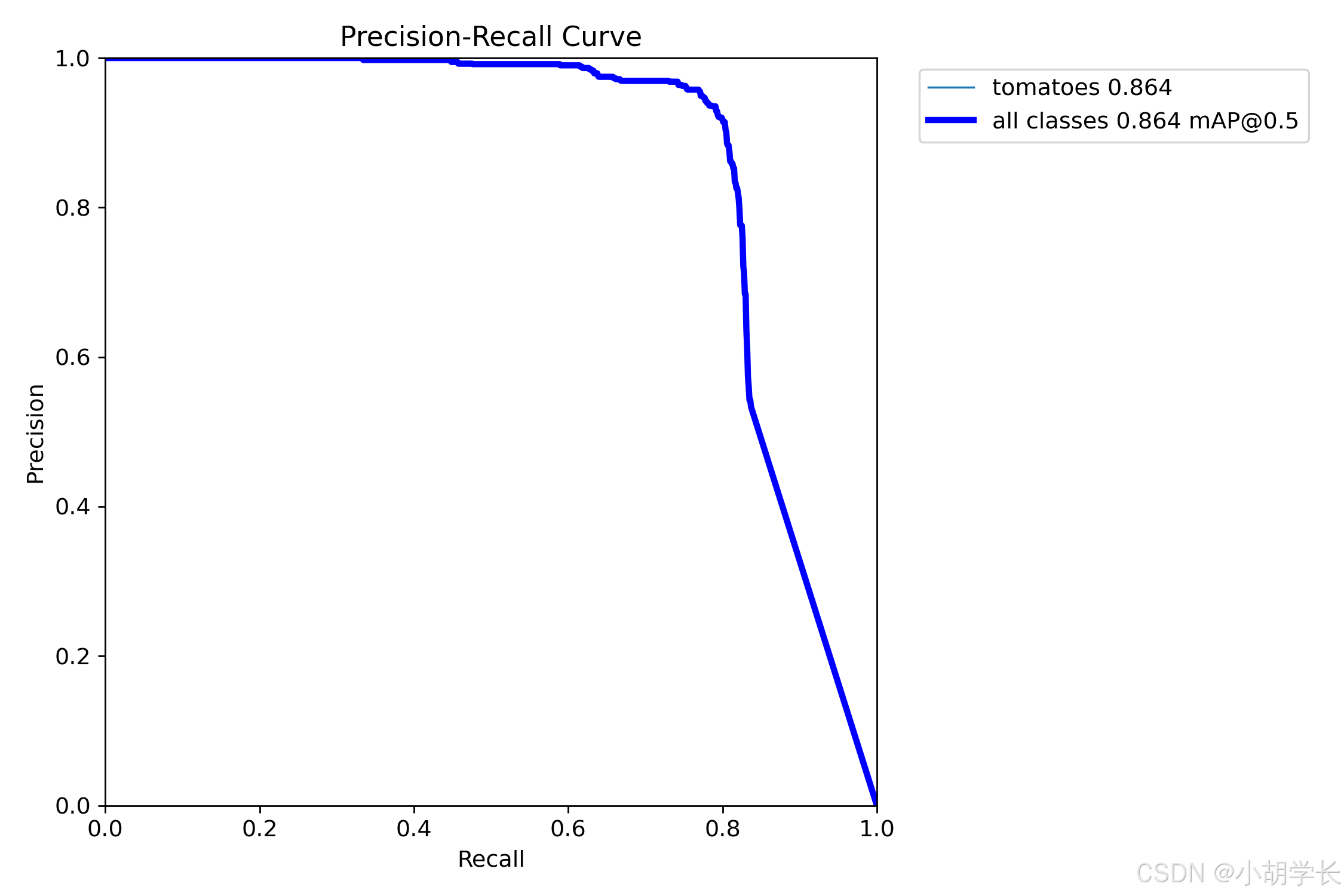
精确度-召回率曲线 (BoxPR_curve.png)
- 这是一张 Precision - Recall Curve(精确率 - 召回率曲线)图。
- 从图中可以看出,在召回率较低时,精确率较高,随着召回率的增加,精确率逐渐下降。这是典型的精确率 - 召回率权衡现象。
- 两条曲线的平均精度均值(mAP)相同,均为 0.864,说明在该模型下,所有类别和番茄类别在不同召回率下的综合精确率表现相同。
- 观察方法: 该曲线展示了精确度与召回率之间的权衡。理想的模型应在高精确度和高召回率处达到平衡。通常查看曲线下面积来评估模型整体性能。
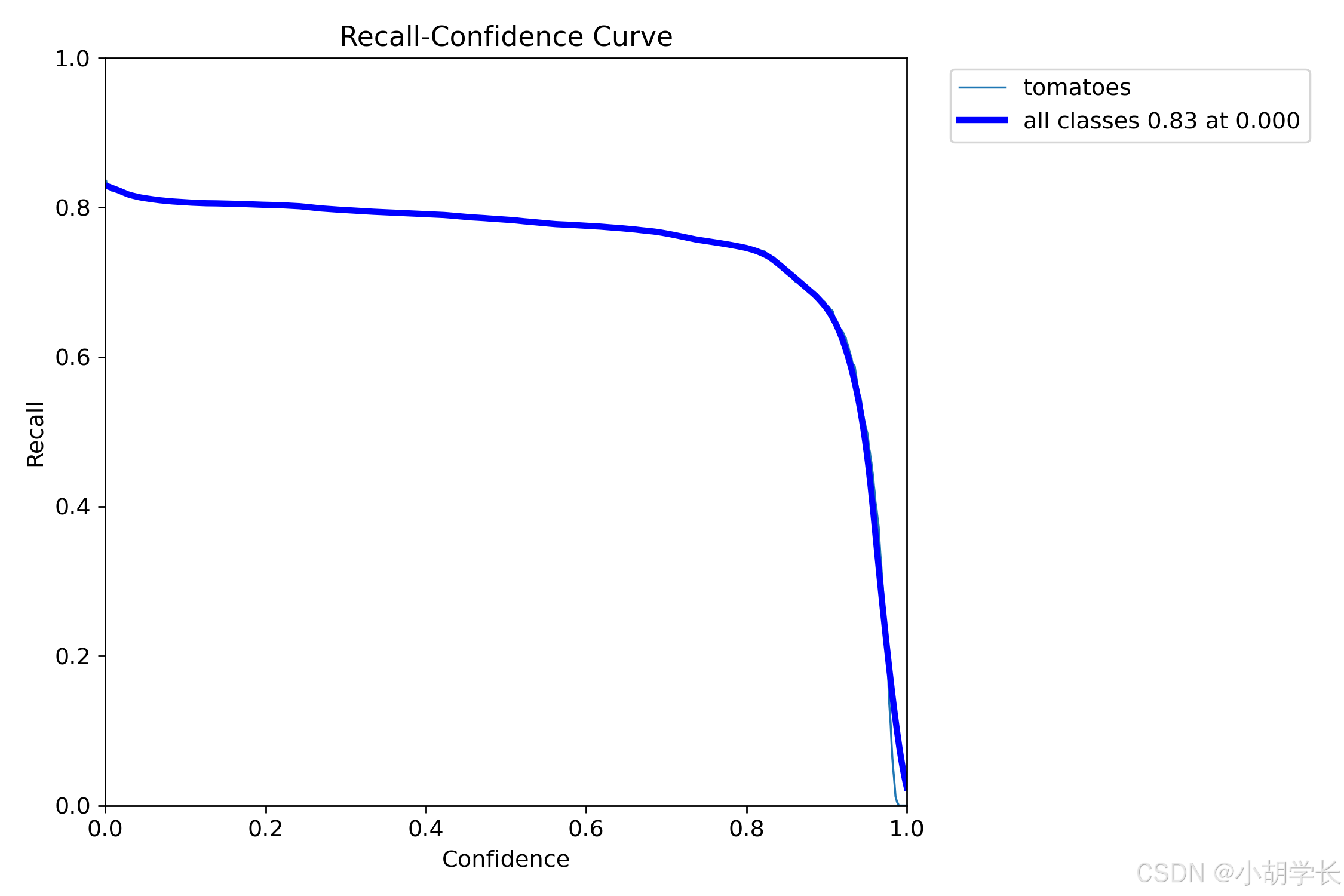
召回率-置信度曲线 (BoxR_curve.png)
- 这是一张 Recall - Confidence Curve(召回率 - 置信度曲线)图。
- 从图中可以看出,所有类别的召回率在低置信度时达到最高值 0.83,随着置信度的增加,召回率逐渐下降。这表明模型在低置信度下能够更好地召回正例样本,但随着对预测结果的自信要求提高(即置信度增加),召回的正例样本比例逐渐减少。
- 对于番茄类别,召回率在开始时较高,但波动较大,且随着置信度增加也逐渐下降。这意味着模型对番茄类别的召回能力在高置信度下有所减弱。
- 观察方法: 与非标准化混淆矩阵类似,但通过标准化可以更容易地比较不同类别之间的分类准确率,特别是在类别样本量不均匀的情况下。
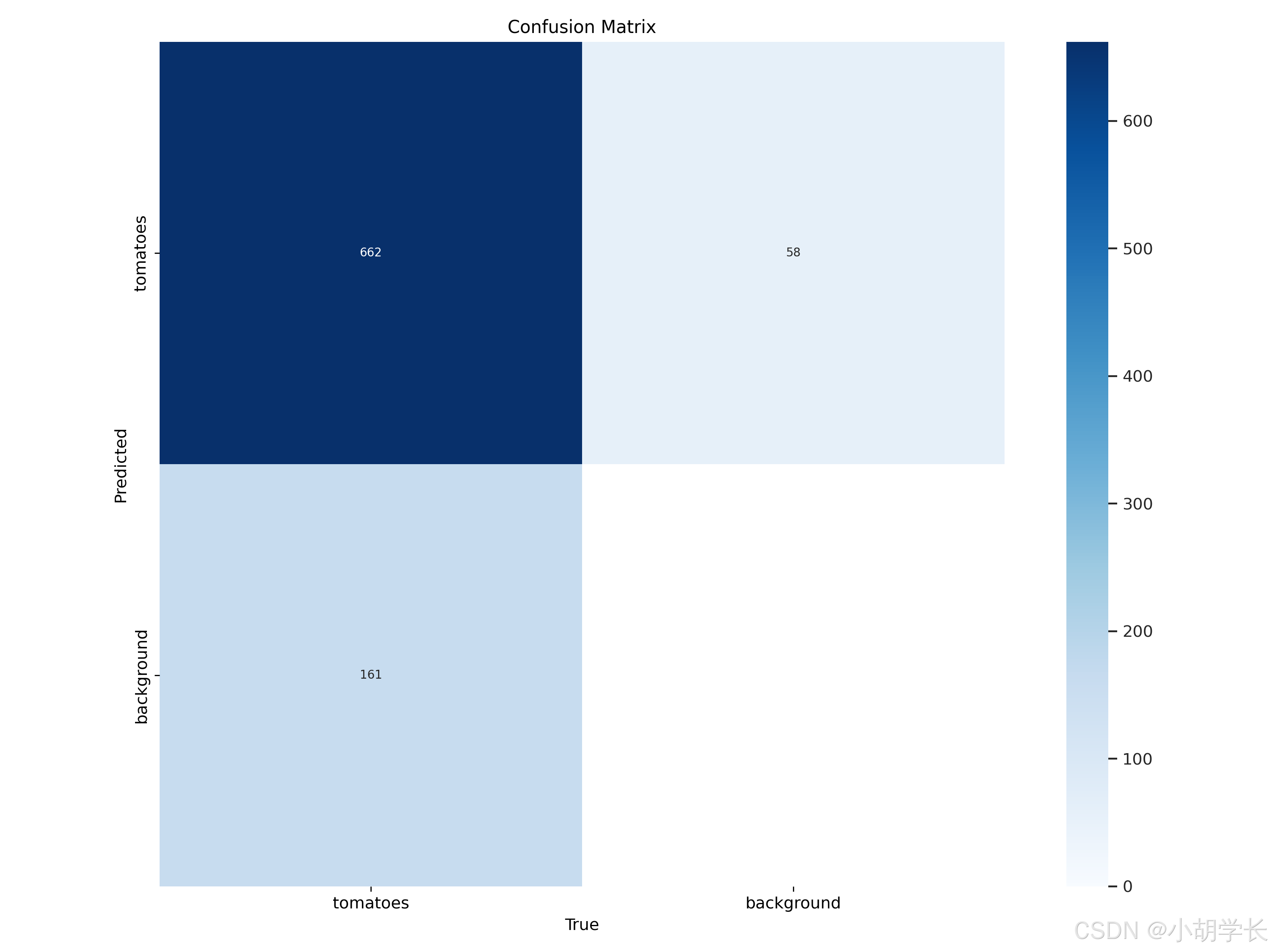
- 这是一张混淆矩阵(Confusion Matrix)图,用于评估分类模型的性能。混淆矩阵展示了模型预测结果与实际真实结果之间的对应关系。
从图中可以看出:
- 真正例(True Positives, TP):模型正确预测为 “tomatoes” 的数量为 662,这是左上角的值。
- 假正例(False Positives, FP):模型错误地将 “background” 预测为 “tomatoes” 的数量为 161,这是左下角的值。
- 假反例(False Negatives, FN):模型错误地将 “tomatoes” 预测为 “background” 的数量为 58,这是右上角的值。
- 真反例(True Negatives, TN):模型正确预测为 “background” 的数量没有在图中直接标注,但可以推测是较大的数值。
基于这些数据,可以进一步计算模型的评估指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数等:
- 准确率 = (TP + TN) / (TP + FP + FN + TN)
- 精确率 = TP / (TP + FP)
- 召回率 = TP / (TP + FN)
- F1 分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
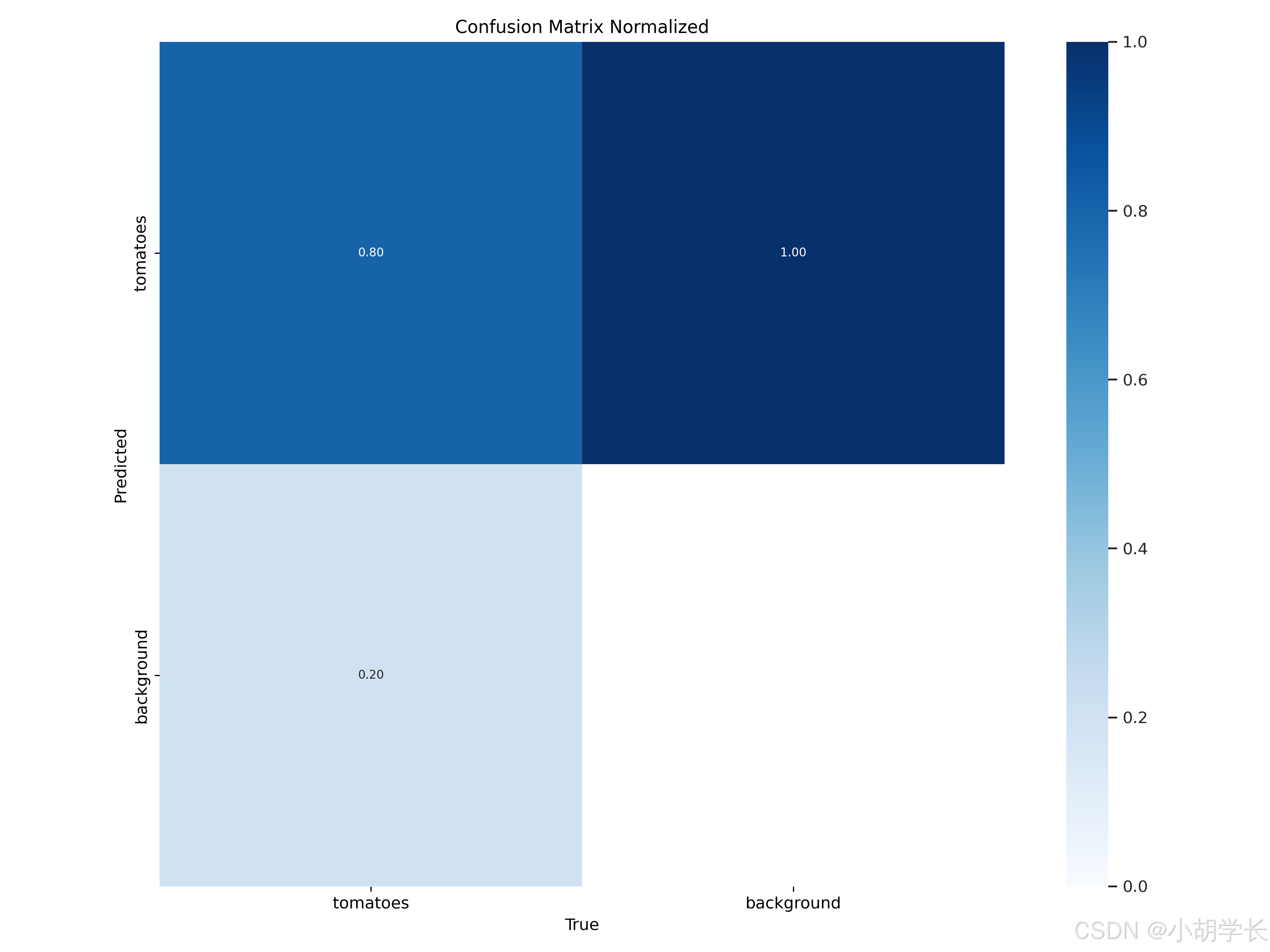
- 这是一张归一化混淆矩阵(Confusion Matrix Normalized)图,用于评估分类模型的性能。归一化混淆矩阵将每个单元格中的数值归一化到 0 到 1 之间,表示比例。
从图中可以看出:
- 真正例(True Positives, TP):模型正确预测为 “tomatoes” 的比例为 0.80,这是左上角的值。
- 假正例(False Positives, FP):模型错误地将 “background” 预测为 “tomatoes” 的比例为 0.20,这是左下角的值。
- 假反例(False Negatives, FN):模型错误地将 “tomatoes” 预测为 “background” 的比例为 1.00,这是右上角的值。
- 真反例(True Negatives, TN):模型正确预测为 “background” 的比例未在图中直接标注,但可以推测是较高的比例。
基于这些数据,可以进一步计算模型的评估指标,如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和 F1 分数等:
- 准确率 = (TP + TN) / (TP + FP + FN + TN)
- 精确率 = TP / (TP + FP) 召回率 = TP / (TP + FN)
- F1 分数 = 2 * (精确率 * 召回率) / (精确率 + 召回率)
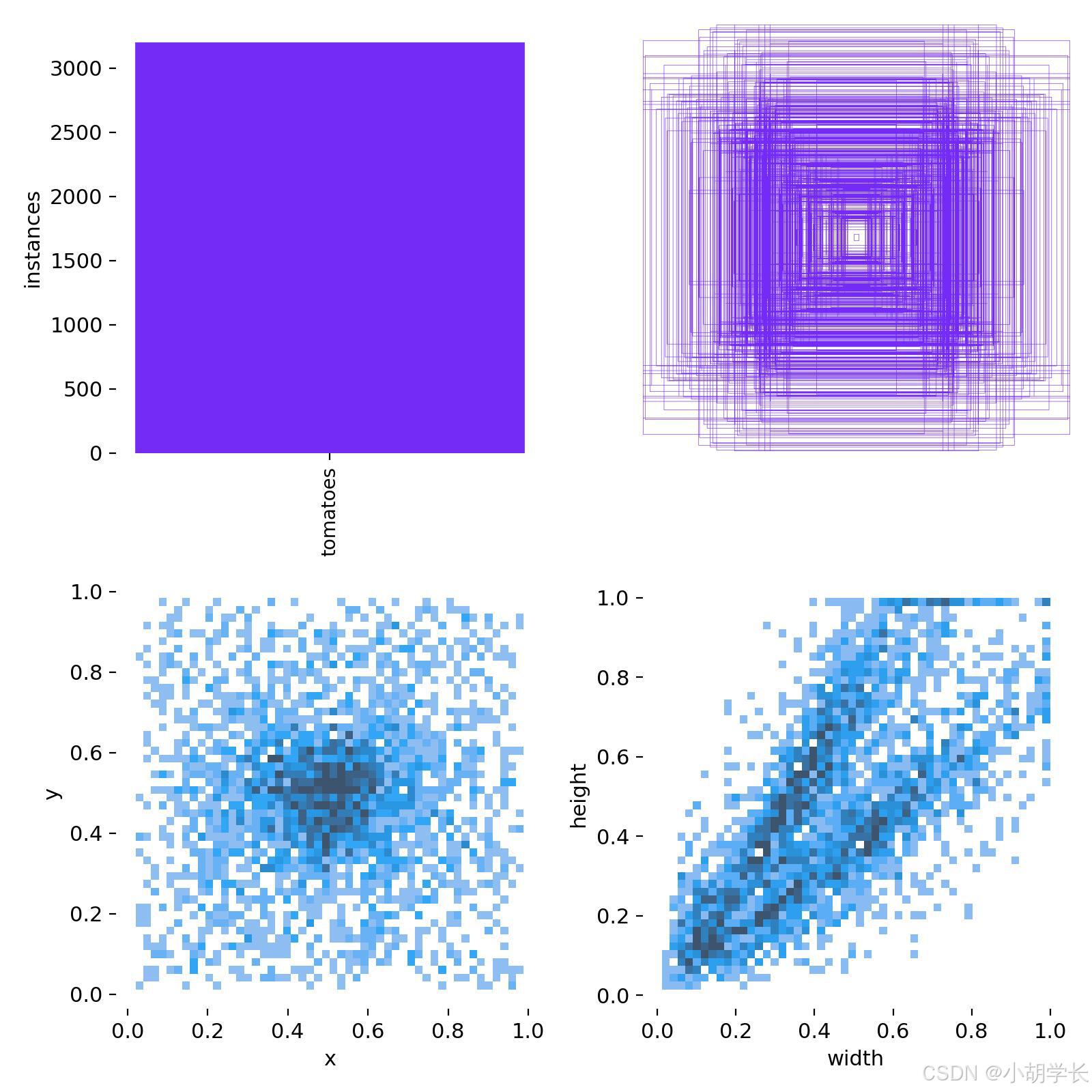
标签分布 (labels.jpg)
- 这张图片包含四个子图,展示了不同类型的数据可视化。
- 观察方法: 柱状图部分显示了每个类别的实例数量,有助于了解数据集中各类别的分布情况。散点图部分可以显示样本的位置分布,有助于了解样本在输入空间的分布特性。
-
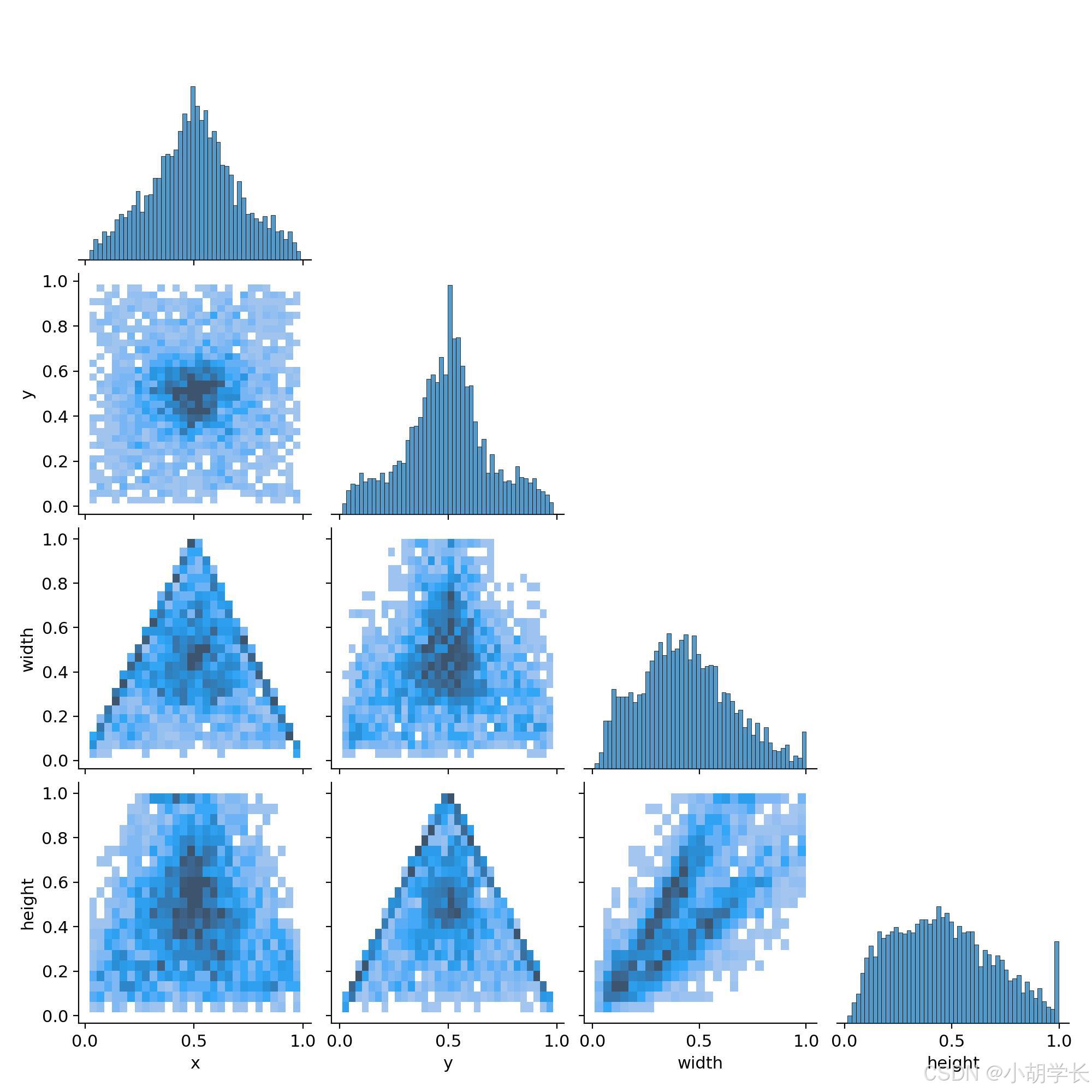
标签相关图 (labels_correlogram.jpg)
- 这张图片展示了多个数据分布的可视化图,具体包括散点图、直方图和二维直方图。
- 这些图主要用于展示数据在不同变量上的分布情况。二维直方图用于展示两个变量之间的联合分布,直方图用于展示单个变量的分布。通过这些图,可以直观地看到数据的集中趋势和离散程度,有助于分析数据的特征和模式。
- 观察方法: 相关图显示了数据标签之间的相关性,深色的格子表示较高的正相关,浅色表示较低的相关或负相关。这有助于了解不同类别之间的关系。
掩膜F1-置信度曲线 (MaskF1_curve.png)
- 这是一张 F1 - Confidence Curve(F1 - 置信度曲线)图。图中有两条曲线,分别代表不同的类别。
- 观察方法: 类似于F1-置信度曲线,但特别用于评估模型在像素级分类或分割任务中的性能。寻找曲线中F1得分最高的点来确定最佳的置信度阈值。
(剩下三张图的意思跟上面的差不多,就不过多解释了)

最后的最后再解释一下这些图片怎么理解它的意思
| train_batch1.jpg | 训练集第一个批次的数据 |
| val_batch0_labels | 在验证集上评估模型的验证数据 |
| val_batch1_pred.jpg | 验证集(validation set)中第一个批次(batch)的预测结果 |


















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











