






在当前的人工智能研究中,结合大模型的深度学习能力和小模型的效率成为了一个热门话题。但如何巧妙地将庞大的模型和轻量级的模型集成在一起,以期在保持性能的同时降低计算成本呢?
今天就整理了几种大模型与小模型结合的策略,以及相关研究论文,大家一起学习一下吧!
策略一:知识蒸馏 (Knowledge Distillation)
知识蒸馏是一种将大模型(教师模型)的知识迁移到小模型(学生模型)的技术。通常,小模型在训练过程中尝试模仿大模型的输出或特征表示。
具体步骤
-
训练大模型(教师模型),使其对目标任务有非常高的性能。
-
设计小模型(学生模型)的架构,小模型的参数量明显少于大模型。
-
使用教师模型的输出来训练学生模型,不是简单地使用标签信息,而是使学生模型的输出尽可能接近教师模型的输出。
-
学生模型可以学习到教师模型的软标签上的信息,这通常比硬标签(真实标签)包含更多的信息。
相关论文
1)Distilling the Knowledge in a Neural Network
在神经网络中提炼知识
简述:本文提出通过将模型集合中的知识提炼到单个模型中,可以显著改进大量使用的商业系统的声学模型,并引入了一种由一个或多个完整模型和许多专业模型组成的新型集成,这些模型学习区分完整模型混淆的细粒度类别。
2)Knowledge Distillation with the Reused Teacher Classifier
使用重用教师分类器进行知识提炼
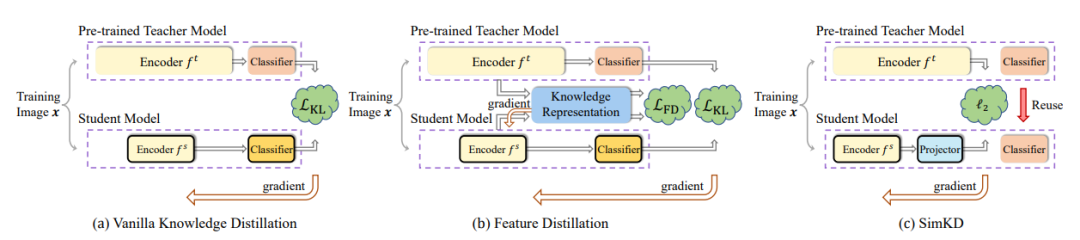
简述:本文中重用预训练教师模型的判别分类器于学生推理,并通过l2损失训练学生编码器实现特征对齐。学生模型性能与教师模型相同,前提是特征完全对齐。研究人员开发了投影仪帮助学生编码器与教师分类器匹配,使技术适用于各种架构。
3)Distilling Holistic Knowledge with Graph Neural Networks
使用图神经网络提炼整体知识
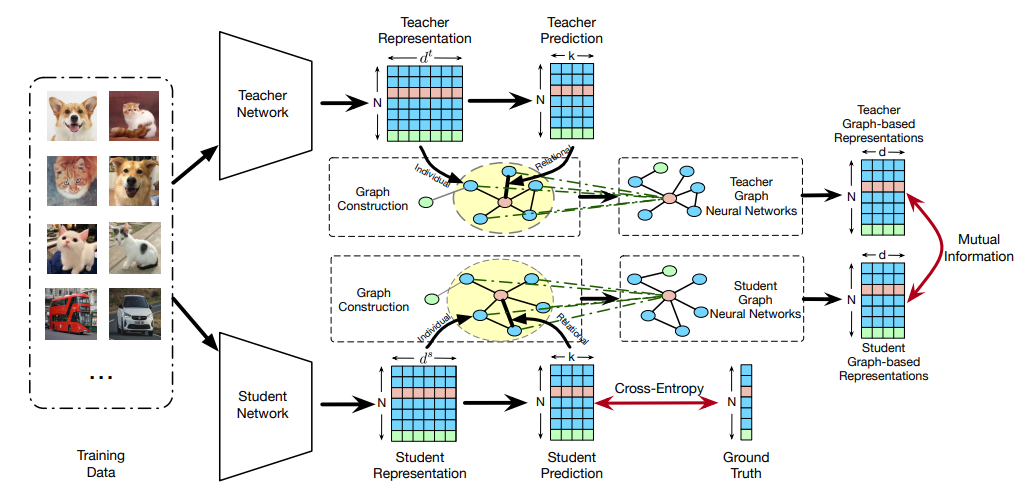
简述:本文提出基于实例间构建的属性图来提炼新颖的整体知识,整体知识通过图神经网络聚合来自关系邻域样本的单个知识来表示为统一的基于图的嵌入,学生网络是通过以对比方式提炼整体知识来学习的。实验和消融研究在基准数据集上验证了所提方法的有效性。
4)Confidence-Aware Multi-Teacher Knowledge Distillation
自信感知的多教师知识提炼
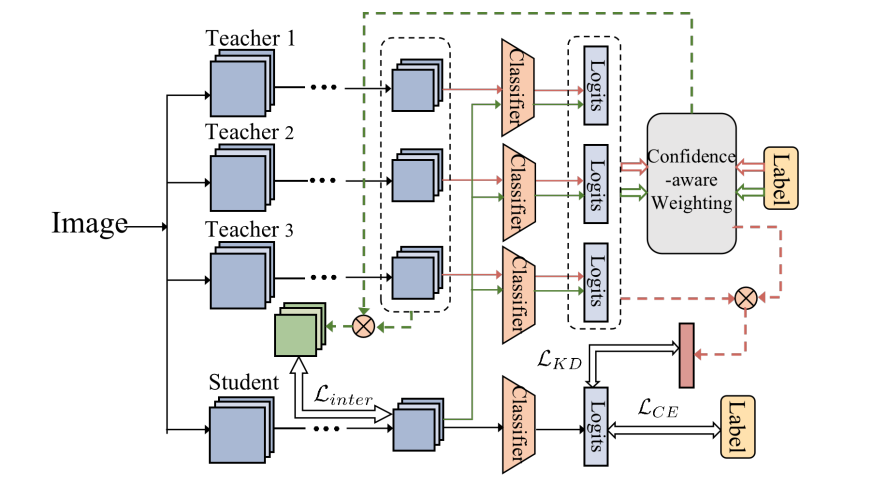
简述:本文提出了一种新的多教师知识蒸馏方法——CA-MKD,该方法能根据样本可靠性为每个教师预测分配权重,确保更接近单热标签的预测获得更大权重。此外,CA-MKD在中间层加入功能,以稳定知识转移过程。大量实验表明,CA-MKD在各种师生架构中均优于其他先进方法。
策略二:模型剪枝 (Model Pruning)
模型剪枝是一种优化技术,旨在通过移除一些不太重要的参数(如权重),来缩减模型的大小,这样可以得到一个体积更小、运行更快的模型。
具体步骤
-
首先训练一个大模型至最佳性能。
-
对模型的权重进行分析,去除那些对模型输出影响最小的权重。
-
对经过剪枝的模型重新进行微调,以恢复因剪枝造成的性能下降。
相关论文
1)LLM-Pruner: On the Structural Pruning of Large Language Models
LLM-Pruner:关于大型语言模型的结构剪枝
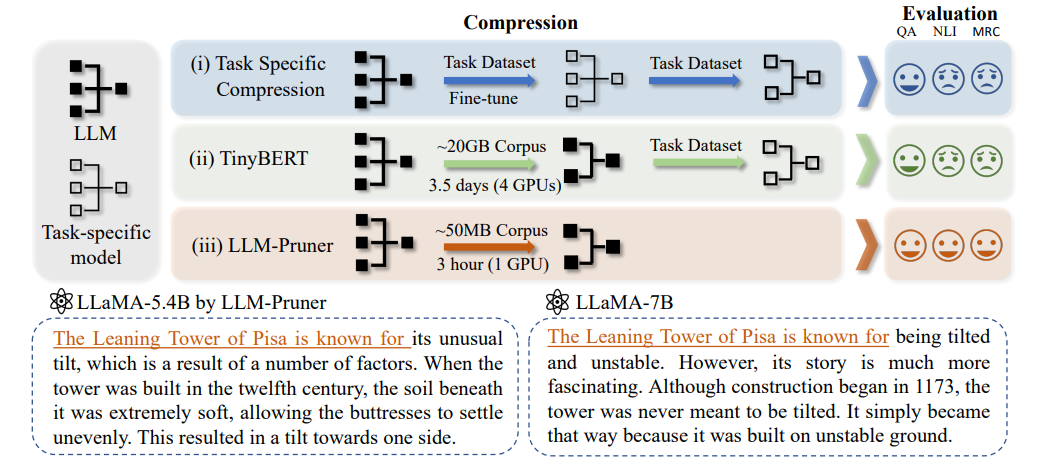
简述:本文提出了是用于大型语言模型的结构剪枝方法LLM-Pruner,它根据梯度信息选择性地剪枝非关键结构,以最大程度地保留LLM功能。通过使用LoRA技术,可以在3小时内恢复修剪模型的性能,仅需50K数据。在LLaMA、Vicuna和ChatGLM等LLM上验证了LLM-Pruner,并证明了压缩模型在零样本分类和生成方面的能力。
2)R-TOSS: A Framework for Real-Time Object Detection using Semi-Structured Pruning
R-TOSS:使用半结构化剪枝进行实时目标检测的框架
简述:本文提出了一种称为R-TOSS的新型半结构化修剪框架,该框架克服了最先进模型修剪技术的缺点,并与各种最先进的修剪技术相比表现出显著改进。
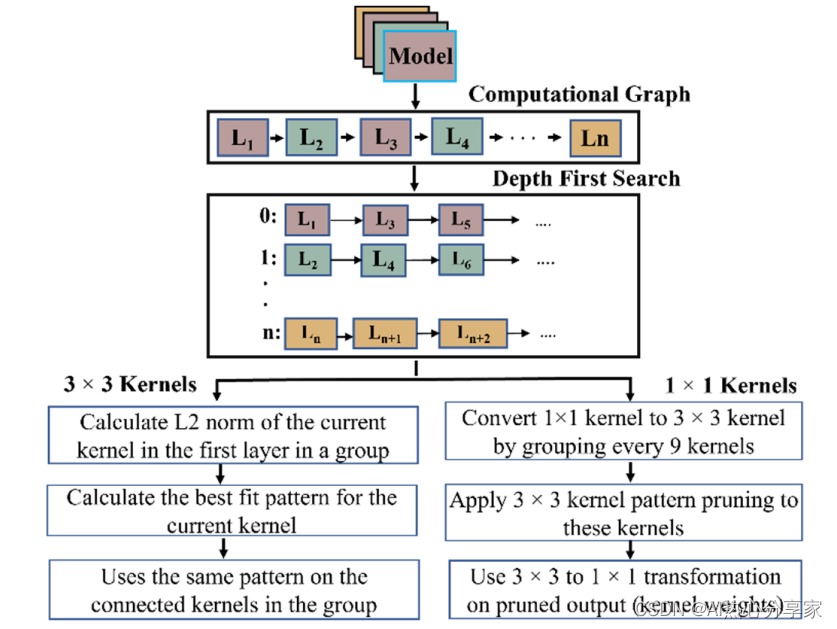
3)Structured Pruning Learns Compact and Accurate Models
结构化剪枝学习紧凑而准确的模型
简述:本文提出了一种特定于任务的结构化剪枝方法CoFi(粗粒度和细粒度剪枝),它结合了粗细粒度剪枝以提高模型并行性,并保持高准确率和低延迟。同时采用分层蒸馏策略来转移知识,实验表明CoFi模型速度提高10倍以上,精度下降很小,比传统剪枝和蒸馏技术更高效。
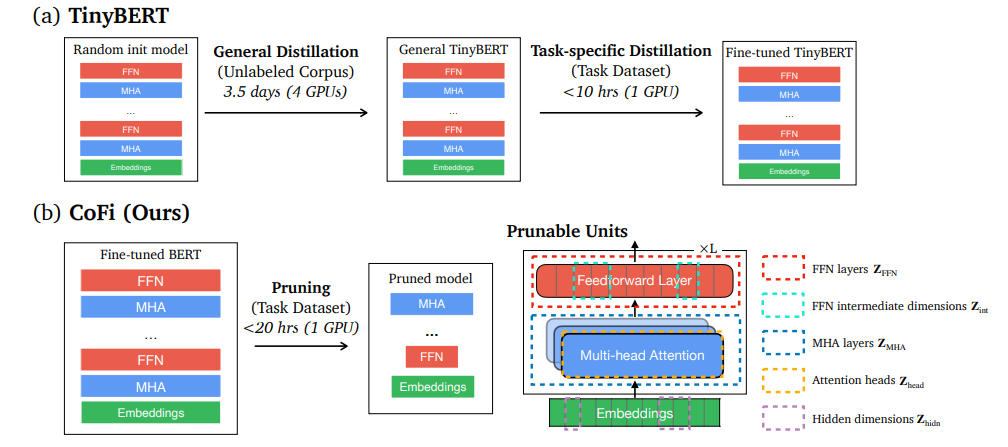
策略三:模型量化(Quantization)
模型量化可以将模型参数的数据类型从浮点数转换为整数,这能显著减小模型的内存占用并加速推理。
具体步骤
-
选择合适的量化方法,并准备所需的工具和库。
-
对模型进行实际的量化操作,包括权重和激活值的转换。
-
对量化后的模型进行验证,确保其性能与原始浮点数模型相当。
-
将量化后的模型部署到目标平台,并进行实际使用。
相关论文
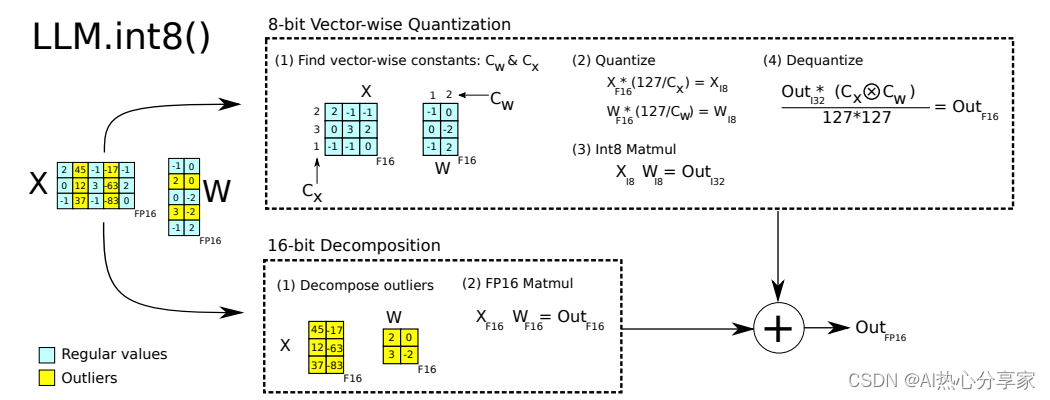
1)LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
LLM.int8():用于大规模转换器的 8 位矩阵乘法
简述:本文提出了一个量化过程LLM.int8(),包含向量量化和混合精度分解。对于大多数特征,使用向量量化进行量化;对于异常值,采用16位矩阵乘法,同时99.9%的值仍用8位乘法。使用LLM.int8,在175B参数的LLM中推理,性能不受影响。
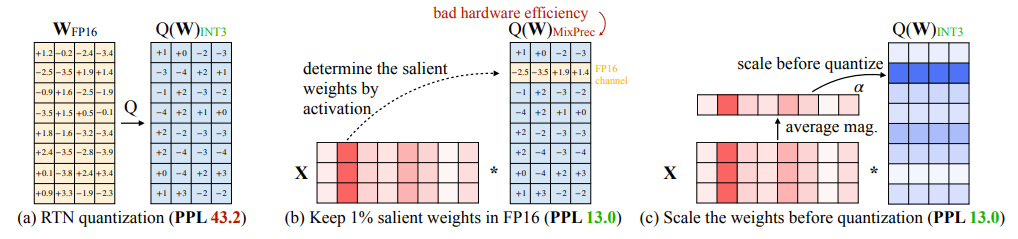
2)AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
AWQ:用于 LLM 压缩和加速的激活感知权重量化
简述:本文提出了一种新的量化方法AWQ,专门用于大型语言模型,它通过关注激活值来识别和保留关键权重,降低量化误差,无需反向传播或重训练。在多项任务中,AWQ显示出优异性能,尤其在指令调优和多模态模型中表现突出。还开发了一种高效推理框架,显著提升了模型在各种设备上的运行速度,能够在移动GPU上实现大规模模型部署。
3)OWQ: Lessons learned from activation outliers for weight quantization in large language models
OWQ:从大型语言模型中权重量化的激活异常值中吸取的经验教训
简述:本文提出了一种创新的PTQ方案,称为异常值感知权重量化(OWQ),该方案可以识别易受攻击的权重并为其分配高精度。广泛的实验表明,OWQ 生成的 3.01 位模型与 OPTQ 生成的 4 位模型具有相当的质量。
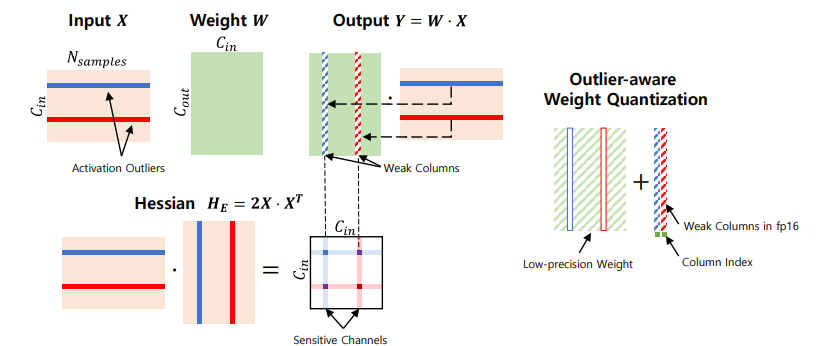
策略四:参数共享(Parameter Sharing)
在多个相关任务上训练的大模型中,很多底层特征是可以共享的,参数共享允许小模型重用大模型中的一部分权重,从而提高其性能。
具体方法
-
确定大模型中可以共享的参数部分。
-
创建一个新的小模型架构,将可共享参数集成进来。
-
在新模型上训练,固定共享的参数不变,仅训练剩余的参数。
相关论文
1)Learning Sparse Sharing: Architectures for Mltiple Tasks
学习多任务的稀疏共享架构
简述:本文提出了一种名为稀疏共享的新型多任务学习模型参数共享技术,通过从一个大型网络中为每个任务选择重叠的子网络并行训练,这种方法能够有效发现并利用任务间的稀疏连接结构。实验证明,在减少参数数量的同时,该方法能提高序列标记任务的性能,优于单任务模型和传统多任务学习方法。
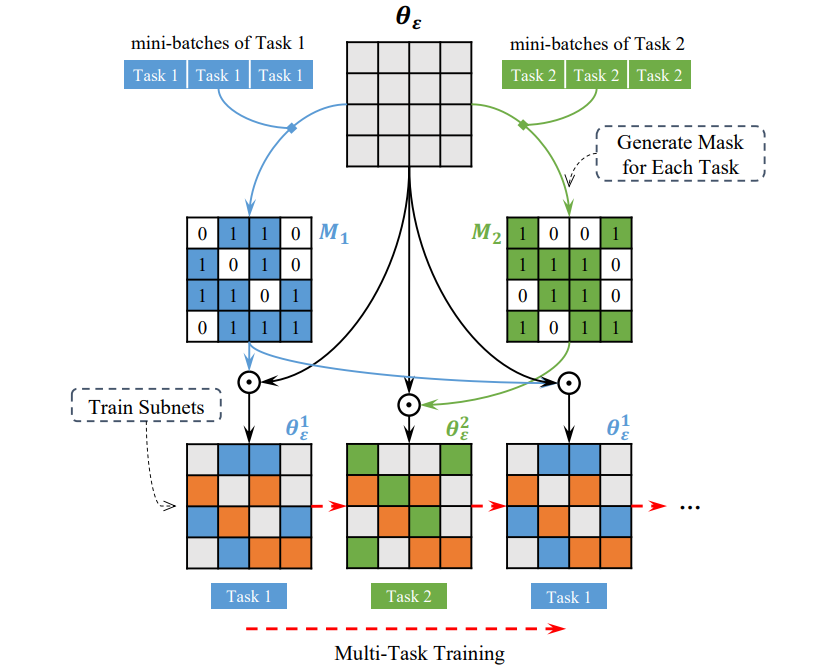
策略五:迁移学习 (Transfer Learning)
它的核心思想是将一个领域(源领域)学到的知识迁移到另一个领域(目标领域),帮助目标领域的学习任务,这种方法在数据稀缺或模型训练成本高昂的情况下特别有用。
具体步骤
-
选择合适的大模型作为预训练模型。
-
根据新任务的需求,可能需要更改模型的某些部分(例如输出层)。
-
使用新任务的数据集对模型进行微调,冻结一部分预训练的层,仅训练新加入的或需要根据新任务调整的层。
相关论文
1)TinyTL: Reduce Memory, Not Parameters for Efficient On-Device Learning
TinyTL:减少内存,而不是参数,以实现高效的设备端学习
简述:本文提出了一种叫Tiny-Transfer-Learning(TinyTL)的技术,它通过冻结预训练网络的权重,只更新一个新设计的、小型的lite残差模块,实现了高效的学习并大幅节省了内存。这种方法几乎不会损失精度,而且比起只微调最后一层,能显著提升精度,减少了内存消耗。
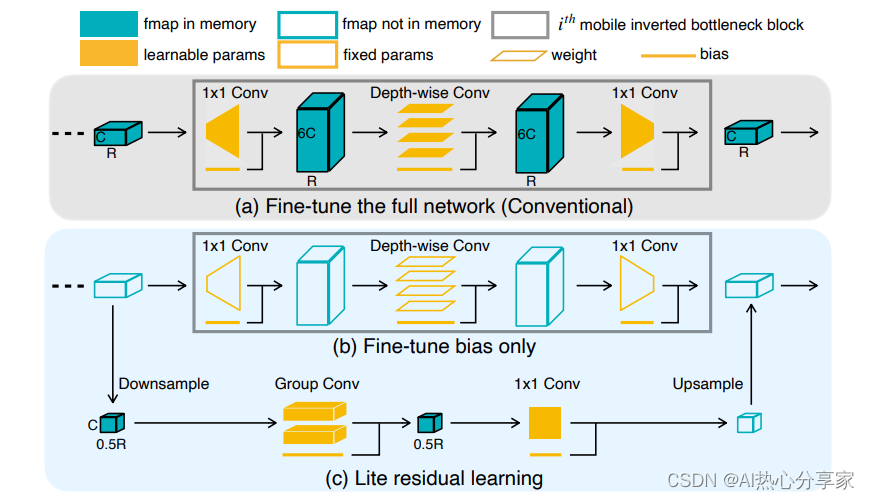
2)Effective Transfer Learning for Low-Resource Natural Language Understanding
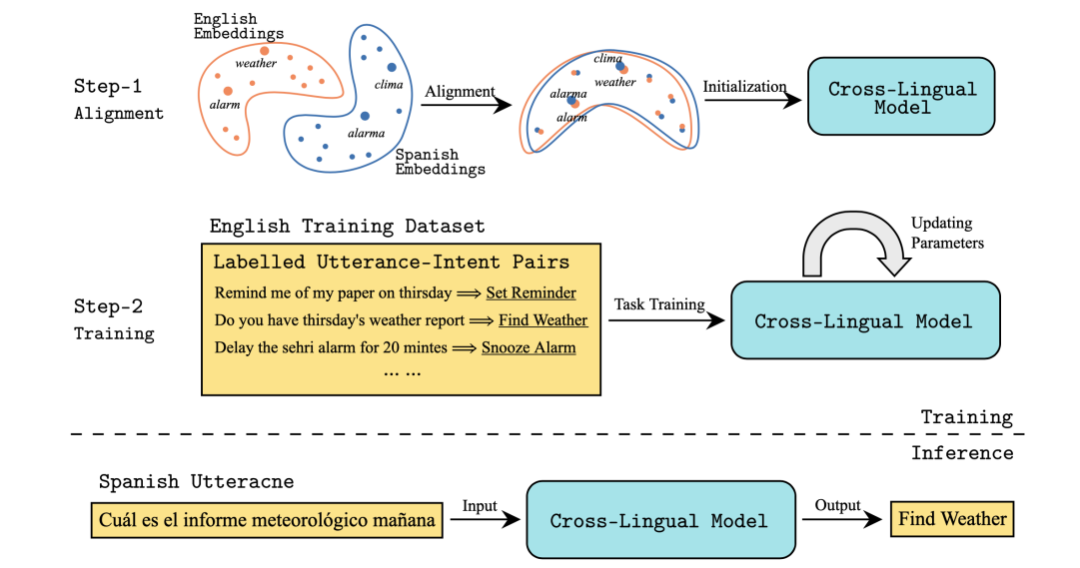
用于低资源自然语言理解的有效迁移学习
简述:本文发现,仅关注关键字可以很容易地大大改善低资源语言的表示,并提出了跨语言适应的降序建模方法,发现对部分词序而不是整个序列进行建模可以提高模型对语言间词序差异的鲁棒性。
这就是大模型小模型相结合的几种策略,结合大模型和小模型的目的是要在资源消耗和模型性能之间寻找一个平衡点,大模型提供了丰富的信息和先进的特征表示,而小模型则使得模型部署在资源有限的环境中成为可能。
通过这些技术,小模型可以在不丧失太多性能的情况下,实现快速、高效的推理,大家可以参考一下!
码字不易,欢迎大家点赞评论收藏!
关注下方《享享学AI》
回复【大小模型结合】获取完整相关论文
👇

















 4604
4604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









