






信息滤波(Information Filter)的推导过程
上一篇:Kalman滤波推导
介绍
Kalman Filter的对偶形式是信息滤波器(information filter或者IF)。和EKF一样,信息滤波器也是用高斯分布表示置信度(belief)。IF和Kalman Filter的主要区别是表达高斯分布的方式有区别。
在Kalman Filter族的算法中,高斯函数采用它们的矩来表示(均值和协方差)。而Information Filter采用正则参数(信息矩阵和信息向量)表示高斯函数。这两种表示形式互为对偶。
正则参数Canonical Parameterization
多维高斯的正则参数表示为一个矩阵
I
I
I(不是单位矩阵,本文单位矩阵是
I
\mathcal{I}
I)和一个向量
ξ
^
\hat{\xi}
ξ^。信息矩阵
I
I
I是协方差矩阵的逆:
I
=
Σ
−
1
I = \Sigma^{-1}
I=Σ−1
信息向量
ξ
^
\hat{\xi}
ξ^用矩表示为:
ξ
^
=
Σ
−
1
μ
\hat{\xi} = \Sigma^{-1}\mu
ξ^=Σ−1μ
易知
I
I
I和
ξ
^
\hat{\xi}
ξ^是高斯概率分布的完备参数。由正则参数推导矩参数的方程如下:
Σ
=
I
−
1
μ
=
I
−
1
ξ
^
\begin{aligned} \Sigma &= I^{-1} \\ \mu &= I^{-1}\hat{\xi} \end{aligned}
Σμ=I−1=I−1ξ^
多维高斯概率分布函数:
P
(
x
)
=
det
(
2
π
Σ
)
−
1
2
exp
{
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
}
=
det
(
2
π
Σ
)
−
1
2
exp
{
−
1
2
x
T
Σ
−
1
x
+
x
T
Σ
−
1
μ
−
1
2
μ
T
Σ
−
1
μ
}
=
det
(
2
π
Σ
)
−
1
2
exp
{
−
1
2
μ
T
Σ
−
1
μ
}
⏟
const
exp
{
−
1
2
x
T
Σ
−
1
x
+
x
T
Σ
−
1
μ
}
\begin{aligned} P\left(x\right) &= \det\left(2\pi\Sigma\right)^{-\frac{1}{2}}\exp\left\{-\frac{1}{2}\left(x - \mu\right)^T\Sigma^{-1}\left(x - \mu\right)\right\} \\ &= \det\left(2\pi\Sigma\right)^{-\frac{1}{2}}\exp\left\{-\frac{1}{2}x^T\Sigma^{-1}x + x^T\Sigma^{-1}\mu - \frac{1}{2}\mu^T\Sigma^{-1}\mu\right\} \\ &= \underbrace{\det\left(2\pi\Sigma\right)^{-\frac{1}{2}}\exp\left\{-\frac{1}{2}\mu^T\Sigma^{-1}\mu\right\}}_{\text{const}}\exp\left\{-\frac{1}{2}x^T\Sigma^{-1}x + x^T\Sigma^{-1}\mu\right\} \end{aligned}
P(x)=det(2πΣ)−21exp{−21(x−μ)TΣ−1(x−μ)}=det(2πΣ)−21exp{−21xTΣ−1x+xTΣ−1μ−21μTΣ−1μ}=const
det(2πΣ)−21exp{−21μTΣ−1μ}exp{−21xTΣ−1x+xTΣ−1μ}
标为
const
\text{const}
const的部分和
x
x
x无关,是一个常数。
注意:高斯概率分布函数中 Σ \Sigma Σ是协方差, μ \mu μ是期望;而在Kalman滤波器中 P k P_k Pk是协方差, x ^ k \hat{x}_k x^k类似于期望。
信息滤波的推导过程
和Kalman滤波器一样,系统的状态转移方程和测量方程如下:
x
k
=
A
k
x
k
−
1
+
B
k
u
k
+
C
k
w
k
y
k
=
H
k
x
k
+
v
k
\begin{aligned} x_{k} &= A_{k}x_{k-1} + B_{k}u_{k} + C_{k}w_{k} \\ y_{k} &= H_{k}x_{k} + v_{k} \end{aligned}
xkyk=Akxk−1+Bkuk+Ckwk=Hkxk+vk
因为信息滤波器是Kalman滤波器的对偶,我们可以从Kalman方程对应到信息滤波器方程。Kalman滤波器方程:
Predict
x
^
k
/
k
−
1
=
A
k
x
^
k
−
1
+
B
k
u
k
状态一步预测
(
先验
)
P
k
/
k
−
1
=
A
k
P
k
−
1
A
k
T
+
C
k
Q
k
C
k
T
状态一步预测均方误差阵
(
先验
)
\begin{aligned} \hat{x}_{k/k-1} &= A_{k}\hat{x}_{k-1} + B_{k}u_{k} &状态一步预测(先验) \\ P_{k/k-1} &= A_{k}P_{k-1}A_{k}^T + C_{k}Q_{k}C_{k}^{T} &状态一步预测均方误差阵(先验) \end{aligned}
x^k/k−1Pk/k−1=Akx^k−1+Bkuk=AkPk−1AkT+CkQkCkT状态一步预测(先验)状态一步预测均方误差阵(先验)
Update
K
k
=
P
k
/
k
−
1
H
k
T
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
滤波增益
x
^
k
=
x
^
k
/
k
−
1
+
K
k
(
y
k
−
H
k
x
^
k
/
k
−
1
)
状态估计
(
后验
)
P
k
=
(
I
−
K
k
H
k
)
P
k
/
k
−
1
状态估计均方误差阵
(
后验
)
\begin{aligned} K_{k} &= P_{k/k-1} H_{k}^T\left(H_{k}P_{k/k-1}H_{k}^T + R_{k}\right)^{-1} &滤波增益\\ \hat{x}_{k} &= \hat{x}_{k/k-1} + K_{k}\left(y_{k} - H_{k}\hat{x}_{k/k-1}\right) &状态估计(后验)\\ P_{k} &= \left(\mathcal{I} - K_{k}H_{k}\right)P_{k/k-1} &状态估计均方误差阵(后验) \end{aligned}
Kkx^kPk=Pk/k−1HkT(HkPk/k−1HkT+Rk)−1=x^k/k−1+Kk(yk−Hkx^k/k−1)=(I−KkHk)Pk/k−1滤波增益状态估计(后验)状态估计均方误差阵(后验)
在Kalman滤波中,状态估计的均方误差阵定义为
P
k
=
E
[
(
x
k
−
x
^
k
)
(
x
k
−
x
^
k
)
T
]
P_k=E[(x_k-\hat{x}_k)(x_k-\hat{x}_k)^{T}]
Pk=E[(xk−x^k)(xk−x^k)T],如果估计值
x
^
k
\hat{x}_k
x^k接近真实值
x
k
x_k
xk,则
P
k
P_k
Pk应当很小,对应于
P
k
−
1
→
∞
P_{k}^{-1} \to \infty
Pk−1→∞;反之,如果
x
^
k
\hat{x}_k
x^k远离真实值,则
P
k
P_{k}
Pk应当很大,对应于
P
k
−
1
→
O
P_{k}^{-1} \to O
Pk−1→O。这说明,
P
k
−
1
P_{k}^{-1}
Pk−1反映了估计值
x
^
k
\hat{x}_k
x^k与真实值
x
k
x_k
xk的接近程度,
P
k
−
1
P_{k}^{-1}
Pk−1越大则越接近,反之亦然。因此,可以将
P
k
−
1
P_{k}^{-1}
Pk−1看作是衡量估计值
x
^
k
\hat{x}_k
x^k中含有真实状态
x
k
x_k
xk信息量多少的指标,
P
k
−
1
P_{k}^{-1}
Pk−1越大则信息越多,即状态估计越准确,习惯上称
P
k
−
1
P_{k}^{-1}
Pk−1为信息矩阵,可重记为
I
k
=
P
k
−
1
I_{k}=P_{k}^{-1}
Ik=Pk−1。这就是信息滤波的由来。简单来说,信息滤波就是将常规kalman式子全部用
I
k
I_k
Ik表示。
信息滤波的推导过程如下:
根据正则参数和矩参数的关系,
I
=
Σ
−
1
ξ
^
=
Σ
−
1
μ
\begin{aligned} I &= \Sigma^{-1} \\ \hat{\xi} &= \Sigma^{-1}\mu \end{aligned}
Iξ^=Σ−1=Σ−1μ
可知
I
k
=
P
k
−
1
ξ
^
k
=
P
k
−
1
x
^
k
I_{k}=P_{k}^{-1} \\ \hat{\xi}_{k}=P_{k}^{-1}\hat{x}_{k}
Ik=Pk−1ξ^k=Pk−1x^k
对于信息滤波器,预测信息矩阵的方法如下:
I
k
/
k
−
1
−
1
=
A
k
I
k
−
1
−
1
A
k
T
+
C
k
Q
k
C
k
T
⇒
I
k
/
k
−
1
=
(
A
k
I
k
−
1
−
1
A
k
T
+
C
k
Q
k
C
k
T
)
−
1
\begin{aligned} I_{k/k-1}^{-1} &= A_{k}I_{k-1}^{-1}A_{k}^T + C_{k}Q_{k}C_{k}^{T} \\ \Rightarrow I_{k/k-1} &= \left(A_{k}I_{k-1}^{-1}A_{k}^T + C_{k}Q_{k}C_{k}^{T}\right)^{-1} \end{aligned}
Ik/k−1−1⇒Ik/k−1=AkIk−1−1AkT+CkQkCkT=(AkIk−1−1AkT+CkQkCkT)−1
预测信息向量的方法如下:
x
^
k
/
k
−
1
=
I
k
/
k
−
1
−
1
ξ
^
k
/
k
−
1
x
^
k
−
1
=
I
k
−
1
−
1
ξ
^
k
−
1
x
^
k
/
k
−
1
=
A
k
x
^
k
−
1
+
B
k
u
k
⇒
I
k
/
k
−
1
−
1
ξ
^
k
/
k
−
1
=
A
k
I
k
−
1
−
1
ξ
^
k
−
1
+
B
k
u
k
⇒
ξ
^
k
/
k
−
1
=
I
k
/
k
−
1
(
A
k
I
k
−
1
−
1
ξ
^
k
−
1
+
B
k
u
k
)
\begin{aligned} \hat{x}_{k/k-1} &= I_{k/k-1}^{-1}\hat{\xi}_{k/k-1} \\ \hat{x}_{k-1} &= I_{k-1}^{-1}\hat{\xi}_{k-1} \\ \hat{x}_{k/k-1} &= A_{k}\hat{x}_{k-1} + B_{k}u_{k} \\ \Rightarrow I_{k/k-1}^{-1}\hat{\xi}_{k/k-1} &= A_{k}I_{k-1}^{-1}\hat{\xi}_{k-1} + B_{k}u_{k} \\ \Rightarrow \hat{\xi}_{k/k-1} &= I_{k/k-1}\left(A_{k}I_{k-1}^{-1}\hat{\xi}_{k-1} + B_{k}u_{k}\right) \end{aligned}
x^k/k−1x^k−1x^k/k−1⇒Ik/k−1−1ξ^k/k−1⇒ξ^k/k−1=Ik/k−1−1ξ^k/k−1=Ik−1−1ξ^k−1=Akx^k−1+Bkuk=AkIk−1−1ξ^k−1+Bkuk=Ik/k−1(AkIk−1−1ξ^k−1+Bkuk)
下面来计算如何用正则参数表达
K
k
K_{k}
Kk。在计算用正则参数表达
K
k
K_{k}
Kk时,需要用到Matrix Inverse Lemma
(
A
+
B
C
D
)
−
1
=
A
−
1
−
A
−
1
B
(
C
−
1
+
D
A
−
1
B
)
−
1
D
A
−
1
\left(A + BCD\right)^{-1} = A^{-1} - A^{-1}B\left(C^{-1} + DA^{-1}B\right)^{-1}DA^{-1}
(A+BCD)−1=A−1−A−1B(C−1+DA−1B)−1DA−1
对于
K
k
=
P
k
/
k
−
1
H
k
T
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
K_{k} = P_{k/k-1} H_{k}^T\left(H_{k}P_{k/k-1} H_{k}^T + R_{k}\right)^{-1}
Kk=Pk/k−1HkT(HkPk/k−1HkT+Rk)−1中的
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
\left(H_{k}P_{k/k-1} H_{k}^T + R_{k}\right)^{-1}
(HkPk/k−1HkT+Rk)−1,我们可以用Matrix Inverse Lemma转化为:
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
=
R
k
−
1
−
R
k
−
1
H
k
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
H
k
T
R
k
−
1
\left(H_{k}P_{k/k-1} H_{k}^T + R_{k}\right)^{-1} = R_{k}^{-1} - R_{k}^{-1}H_{k}\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}H_{k}^TR_{k}^{-1}
(HkPk/k−1HkT+Rk)−1=Rk−1−Rk−1Hk(Pk/k−1−1+HkTRk−1Hk)−1HkTRk−1
那么
K
k
K_{k}
Kk
K
k
=
P
k
/
k
−
1
H
k
T
(
H
k
P
k
/
k
−
1
H
k
T
+
R
k
)
−
1
=
P
k
/
k
−
1
H
k
T
R
k
−
1
−
P
k
/
k
−
1
H
k
T
R
k
−
1
H
k
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
H
k
T
R
k
−
1
=
P
k
/
k
−
1
[
I
−
H
k
T
R
k
−
1
H
k
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
]
H
k
T
R
k
−
1
=
P
k
/
k
−
1
[
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
−
H
k
T
R
k
−
1
H
k
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
]
H
k
T
R
k
−
1
=
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
H
k
T
R
k
−
1
\begin{aligned} K_{k} &= P_{k/k-1} H_{k}^T\left(H_{k}P_{k/k-1} H_{k}^T + R_{k}\right)^{-1} \\ &= P_{k/k-1} H_{k}^T R_{k}^{-1} - P_{k/k-1} H_{k}^T R_{k}^{-1}H_{k}\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}H_{k}^T R_{k}^{-1} \\ &= P_{k/k-1}\left[\mathcal{I} - H_{k}^T R_{k}^{-1}H_{k}\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}\right]H_{k}^T R_{k}^{-1} \\ &= P_{k/k-1}\left[\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1} - H_{k}^T R_{k}^{-1}H_{k}\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}\right]H_{k}^T R_{k}^{-1} \\ &= \left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}H_{k}^T R_{k}^{-1} \end{aligned}
Kk=Pk/k−1HkT(HkPk/k−1HkT+Rk)−1=Pk/k−1HkTRk−1−Pk/k−1HkTRk−1Hk(Pk/k−1−1+HkTRk−1Hk)−1HkTRk−1=Pk/k−1[I−HkTRk−1Hk(Pk/k−1−1+HkTRk−1Hk)−1]HkTRk−1=Pk/k−1[(Pk/k−1−1+HkTRk−1Hk)(Pk/k−1−1+HkTRk−1Hk)−1−HkTRk−1Hk(Pk/k−1−1+HkTRk−1Hk)−1]HkTRk−1=(Pk/k−1−1+HkTRk−1Hk)−1HkTRk−1
可以进一步计算更新过程中的信息矩阵:
I
k
−
1
=
P
k
=
(
I
−
K
k
H
k
)
P
k
/
k
−
1
=
(
I
−
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
H
k
T
R
k
−
1
H
k
)
P
k
/
k
−
1
=
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
=
(
I
k
/
k
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
⇒
I
k
=
I
k
/
k
−
1
+
H
k
T
R
k
−
1
H
k
\begin{aligned} I_{k}^{-1} &= P_{k} = \left(\mathcal{I} - K_{k}H_{k}\right)P_{k/k-1} \\ &= \left(\mathcal{I} - \left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}H_{k}^T R_{k}^{-1} H_{k} \right)P_{k/k-1} \\ &= \left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1} \\ &= \left(I_{k/k-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1} \\ \Rightarrow I_{k} &= I_{k/k-1} + H_{k}^T R_{k}^{-1}H_{k} \end{aligned}
Ik−1⇒Ik=Pk=(I−KkHk)Pk/k−1=(I−(Pk/k−1−1+HkTRk−1Hk)−1HkTRk−1Hk)Pk/k−1=(Pk/k−1−1+HkTRk−1Hk)−1=(Ik/k−1+HkTRk−1Hk)−1=Ik/k−1+HkTRk−1Hk
所以
K
k
K_k
Kk还有另一种简单的形式如下:
K
k
=
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
H
k
T
R
k
−
1
=
I
k
−
1
H
k
T
R
k
−
1
\begin{aligned} K_{k}&=\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}H_{k}^T R_{k}^{-1}\\ &= I_{k}^{-1}H_{k}^T R_{k}^{-1} \end{aligned}
Kk=(Pk/k−1−1+HkTRk−1Hk)−1HkTRk−1=Ik−1HkTRk−1
现在来计算更新过程中的信息向量:
I
k
−
1
ξ
^
k
=
x
^
k
=
x
^
k
/
k
−
1
+
K
k
(
y
k
−
H
k
x
^
k
/
k
−
1
)
=
(
I
−
K
k
H
k
)
x
^
k
/
k
−
1
+
K
k
y
k
=
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
P
k
/
k
−
1
−
1
x
^
k
/
k
−
1
+
K
k
y
k
⇒
ξ
^
k
=
I
k
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
P
k
/
k
−
1
−
1
x
^
k
/
k
−
1
+
I
k
K
k
y
k
=
P
k
/
k
−
1
−
1
x
^
k
/
k
−
1
+
I
k
K
k
y
k
=
ξ
^
k
/
k
−
1
+
I
k
(
P
k
/
k
−
1
−
1
+
H
k
T
R
k
−
1
H
k
)
−
1
H
k
T
R
k
−
1
y
k
=
H
k
T
R
k
−
1
y
k
+
ξ
^
k
/
k
−
1
\begin{aligned} I_{k}^{-1}\hat{\xi}_{k} &= \hat{x}_{k} = \hat{x}_{k/k-1} + K_{k}\left(y_{k} - H_{k}\hat{x}_{k/k-1}\right) = \left(\mathcal{I} - K_{k} H_{k}\right)\hat{x}_{k/k-1} + K_{k}y_{k} \\ &= \left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}P_{k/k-1}^{-1}\hat{x}_{k/k-1} + K_{k}y_{k}\\ \Rightarrow\qquad \hat{\xi}_{k} &= I_{k}\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}P_{k/k-1}^{-1}\hat{x}_{k/k-1} + I_{k} K_{k}y_{k} \\ &= P_{k/k-1}^{-1}\hat{x}_{k/k-1} + I_{k} K_{k}y_{k} \\ &= \hat{\xi}_{k/k-1} + I_{k}\left(P_{k/k-1}^{-1} + H_{k}^T R_{k}^{-1}H_{k}\right)^{-1}H_{k}^T R_{k}^{-1}y_{k} \\ &= H_{k}^T R_{k}^{-1}y_{k} + \hat{\xi}_{k/k-1} \end{aligned}
Ik−1ξ^k⇒ξ^k=x^k=x^k/k−1+Kk(yk−Hkx^k/k−1)=(I−KkHk)x^k/k−1+Kkyk=(Pk/k−1−1+HkTRk−1Hk)−1Pk/k−1−1x^k/k−1+Kkyk=Ik(Pk/k−1−1+HkTRk−1Hk)−1Pk/k−1−1x^k/k−1+IkKkyk=Pk/k−1−1x^k/k−1+IkKkyk=ξ^k/k−1+Ik(Pk/k−1−1+HkTRk−1Hk)−1HkTRk−1yk=HkTRk−1yk+ξ^k/k−1
至此,我们已经全部推导出信息滤波器的公式。
(1) 用信息矩阵和信息向量递推
Predict
I
k
/
k
−
1
=
(
A
k
I
k
−
1
−
1
A
k
T
+
C
k
Q
k
C
k
T
)
−
1
一步预测信息矩阵
(
先验
)
ξ
^
k
/
k
−
1
=
I
k
/
k
−
1
(
A
k
I
k
−
1
−
1
ξ
^
k
−
1
+
B
k
u
k
)
一步预测信息向量
(
先验
)
\begin{aligned} I_{k/k-1} &= \left(A_{k}I_{k-1}^{-1}A_{k}^T + C_{k}Q_{k}C_{k}^{T}\right)^{-1} & 一步预测信息矩阵(先验)\\ \hat{\xi}_{k/k-1} &= I_{k/k-1}\left(A_{k}I_{k-1}^{-1}\hat{\xi}_{k-1} + B_{k}u_{k}\right) &一步预测信息向量(先验) \end{aligned}
Ik/k−1ξ^k/k−1=(AkIk−1−1AkT+CkQkCkT)−1=Ik/k−1(AkIk−1−1ξ^k−1+Bkuk)一步预测信息矩阵(先验)一步预测信息向量(先验)
Update
I
k
=
I
k
/
k
−
1
+
H
k
T
R
k
−
1
H
k
信息矩阵
(
后验
)
ξ
^
k
=
H
k
T
R
k
−
1
y
k
+
ξ
^
k
/
k
−
1
信息向量估计
(
后验
)
\begin{aligned} I_{k} &= I_{k/k-1} + H_{k}^T R_{k}^{-1}H_{k} &信息矩阵(后验)\\ \hat{\xi}_{k} &= H_{k}^T R_{k}^{-1}y_{k} + \hat{\xi}_{k/k-1} & 信息向量估计(后验)\end{aligned}
Ikξ^k=Ik/k−1+HkTRk−1Hk=HkTRk−1yk+ξ^k/k−1信息矩阵(后验)信息向量估计(后验)
仿真:(模型和Kalman的一样)
clear;clc;close all;
N=11;% 采样点数
n=2;% 本系统2维
%% 状态和测量值初始化
X=zeros(n,N);%各时刻真实值,初始值为0
X_kf=zeros(n,N);% 估计值(Kalman滤波处理的状态)
Y=zeros(2,N); %测量值
K=zeros(n,2,N);
I=eye(n);
%% 噪声
Q=1;%W(k)的方差
R1=1;%V1(k)的方差
R2=2;%V2(k)的方差
R=[R1 0;0 R2];
rng(4);%确定随机种子,防止每次W和V不同
W=sqrt(Q)*randn(1,N);
V1=sqrt(R1)*randn(1,N);
V2=sqrt(R2)*randn(1,N);
V=[V1;V2];
%% 赋初值
X(:,1)=[0;0];%系统初值
P(:,:,1)=I;%初始值的协方差
sigma_x1_fang(1)=P(1,1,1);
sigma_x2_fang(1)=P(2,2,1);
X_kf(:,1)=[0.5;0.2];%滤波器的初始估计状态,不知道,任意
%% 系统矩阵
A=[1 1;0 1];
B=[0;0];
u_k=0;
C=[1;1];
H=[1 0;0 1];
%% 将迭代使用的参数进行变换
I(:,:,1)=inv(P(:,:,1)); % 信息矩阵
Xtrans_kf(:,1)=I(:,:,1)*X_kf(:,1); % 将状态变换后的后验值
%% 模拟测量过程,并滤波
for k=2:N
X(:,k)=A*X(:,k-1)+B*u_k+C*W(k-1);
Y(:,k)=H*X(:,k)+V(:,k);
P_pre=A*inv(I(:,:,k-1))*A'+C*Q*C';
I_pre=inv(P_pre); % 先验信息矩阵
Xtrans_pre=I_pre*(A*inv(I(:,:,k-1))*Xtrans_kf(:,k-1)+B*u_k);
I(:,:,k)=I_pre+H'*inv(R)*H;% 后验信息矩阵
% K(:,:,k)=inv(I(:,:,k))*H'*inv(R);
Xtrans_kf(:,k)=Xtrans_pre+H'*inv(R)*Y(:,k);
P(:,:,k)=inv(I(:,:,k));% 这个P仅仅是绘图用的
sigma_x1_fang(k)=P(1,1,k);
sigma_x2_fang(k)=P(2,2,k);
X_kf(:,k)=inv(I(:,:,k))*Xtrans_kf(:,k);% 这个X_kf仅仅是绘图用的
end
%% 误差计算
Err_Kalman_x1=X(1,:)-X_kf(1,:);
Err_Kalman_x2=X(2,:)-X_kf(2,:);
%% 绘图
t=0:N-1;
figure('Name','信息滤波仿真')
plot(t,X_kf(1,:),'-.b','LineWidth',1.5);hold on
plot(t,X(1,:),'-ob','LineWidth',1.5);hold on
plot(t,X_kf(2,:),'-.k','LineWidth',1.5);hold on
plot(t,X(2,:),'-ok','LineWidth',1.5);
legend('kalman估计值x_1','真实值x_1','kalman估计值x_2','真实值x_2');
xlabel('采样时间');
ylabel('kalman估计值和真实值');
title('kalman估计值和真实值');
figure('Name','误差分析')
plot(t,Err_Kalman_x1,'-^b','LineWidth',1.5);
hold on
plot(t,Err_Kalman_x2,'-^k','LineWidth',1.5);
legend('x_1误差','x_2误差');
xlabel('采样时间');
ylabel('误差');
title('误差');
figure('Name','误差方差分析')
plot(t,sigma_x1_fang,'-*b','LineWidth',1.5);
hold on
plot(t,sigma_x2_fang,'-*k','LineWidth',1.5);
legend('x_1误差的方差','x_2误差的方差');
xlabel('采样时间');
ylabel('误差的方差');
title('状态估计误差的方差');
figure('Name','误差图')
sigma_x1=sigma_x1_fang.^0.5;
sigma_x2=sigma_x2_fang.^0.5;
errorbar(t, X_kf(1,:),3.*sigma_x1,'-ob','LineWidth',1.5);hold on
plot(t,X(1,:),'-.b','LineWidth',1.5);hold on
errorbar(t, X_kf(2,:),3.*sigma_x2,'-ok','LineWidth',1.5);hold on
plot(t,X(2,:),'-.k','LineWidth',1.5);hold on
legend('kalman估计值x_1误差线','真实值x_1','kalman估计值x_2误差线','真实值x_2');
xlabel('采样时间');
ylabel('kalman估计值误差线和真实值');
仿真结果:
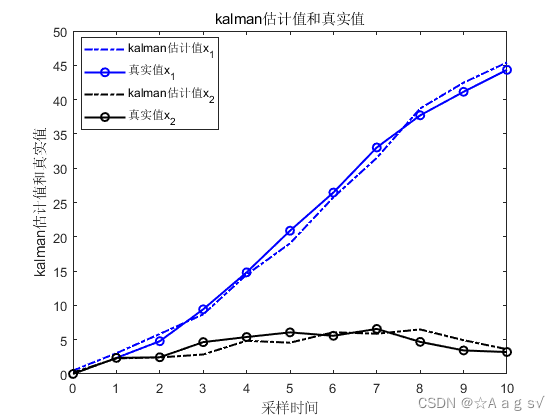
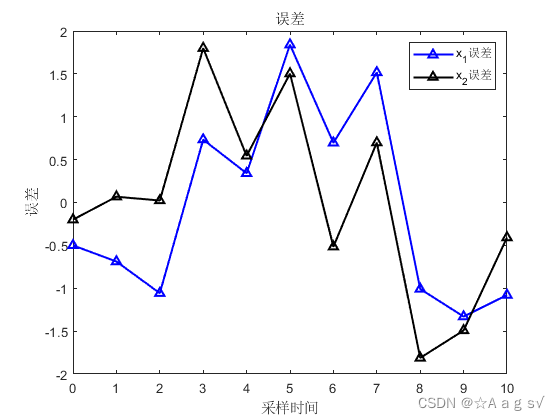
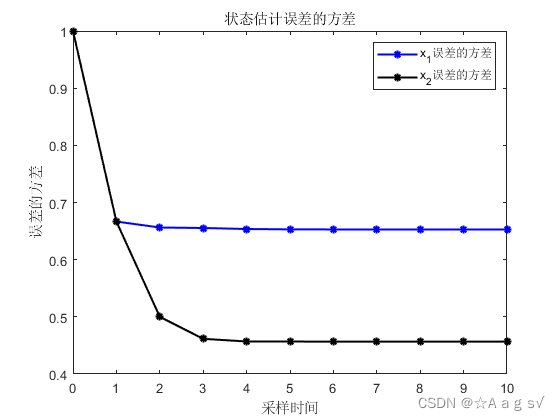
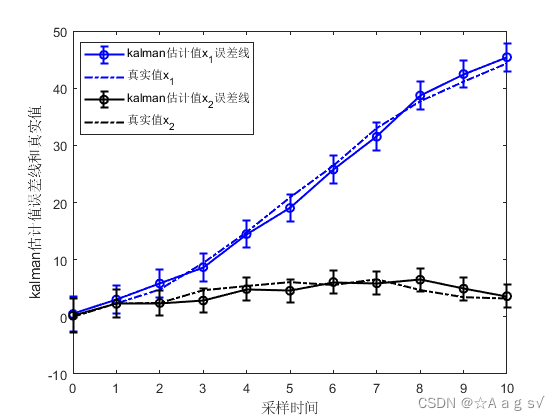
(2) 用信息矩阵和Kalman估计值递推
信息矩阵的先验和后验与上面(1)中的一样,如下所示:
I
k
/
k
−
1
=
(
A
k
I
k
−
1
−
1
A
k
T
+
C
k
Q
k
C
k
T
)
−
1
一步预测信息矩阵
(
先验
)
I
k
=
I
k
/
k
−
1
+
H
k
T
R
k
−
1
H
k
信息矩阵
(
后验
)
\begin{aligned} I_{k/k-1} &= \left(A_{k}I_{k-1}^{-1}A_{k}^T + C_{k}Q_{k}C_{k}^{T}\right)^{-1} & 一步预测信息矩阵(先验)\\ I_{k} &= I_{k/k-1} + H_{k}^T R_{k}^{-1}H_{k} &信息矩阵(后验)\end{aligned}
Ik/k−1Ik=(AkIk−1−1AkT+CkQkCkT)−1=Ik/k−1+HkTRk−1Hk一步预测信息矩阵(先验)信息矩阵(后验)
增益就是上面推导的,如下所示:
K
k
=
I
k
−
1
H
k
T
R
k
−
1
滤波增益
K_{k}= I_{k}^{-1}H_{k}^T R_{k}^{-1} \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ 滤波增益
Kk=Ik−1HkTRk−1 滤波增益
Kalman估计值和经典的Kalman滤波一样,如下所示:
x
^
k
/
k
−
1
=
A
k
x
^
k
−
1
+
B
k
u
k
状态一步预测
x
^
k
=
x
^
k
/
k
−
1
+
K
k
(
y
k
−
H
k
x
^
k
/
k
−
1
)
状态估计
\begin{aligned} \hat{x}_{k/k-1} &= A_{k}\hat{x}_{k-1} + B_{k}u_{k} & 状态一步预测\\ \hat{x}_{k} &= \hat{x}_{k/k-1} + K_{k}\left(y_{k} - H_{k}\hat{x}_{k/k-1}\right)&状态估计 \end{aligned}
x^k/k−1x^k=Akx^k−1+Bkuk=x^k/k−1+Kk(yk−Hkx^k/k−1)状态一步预测状态估计
仿真:(模型和Kalman的一样)
clear;clc;close all;
N=11;% 采样点数
n=2;% 本系统2维
%% 状态和测量值初始化
X=zeros(n,N);%各时刻真实值,初始值为0
X_kf=zeros(n,N);% 估计值(Kalman滤波处理的状态)
Y=zeros(2,N); %测量值
K=zeros(n,2,N);
I=eye(n);
%% 噪声
Q=1;%W(k)的方差
R1=1;%V1(k)的方差
R2=2;%V2(k)的方差
R=[R1 0;0 R2];
rng(4);%确定随机种子,防止每次W和V不同
W=sqrt(Q)*randn(1,N);
V1=sqrt(R1)*randn(1,N);
V2=sqrt(R2)*randn(1,N);
V=[V1;V2];
%% 赋初值
X(:,1)=[0;0];%系统初值
P(:,:,1)=I;%初始值的协方差
sigma_x1_fang(1)=P(1,1,1);
sigma_x2_fang(1)=P(2,2,1);
X_kf(:,1)=[0.5;0.2];%滤波器的初始估计状态,不知道,任意
%% 系统矩阵
A=[1 1;0 1];
B=[0;0];
u_k=0;
C=[1;1];
H=[1 0;0 1];
%% 模拟测量过程,并滤波
for k=2:N
X(:,k)=A*X(:,k-1)+B*u_k+C*W(k-1);
Y(:,k)=H*X(:,k)+V(:,k);
X_pre=A*X_kf(:,k-1)+B*u_k;
P_pre=A*inv(I(:,:,k-1))*A'+C*Q*C';
I_pre=inv(P_pre); % 先验信息矩阵
I(:,:,k)=I_pre+H'*inv(R)*H;% 后验信息矩阵
K(:,:,k)=inv(I(:,:,k))*H'*inv(R);
X_kf(:,k)=X_pre+K(:,:,k)*(Y(:,k)-H*X_pre);
P(:,:,k)=inv(I(:,:,k));% 这个P仅仅是绘图用的
sigma_x1_fang(k)=P(1,1,k);
sigma_x2_fang(k)=P(2,2,k);
end
%% 误差计算
Err_Kalman_x1=X(1,:)-X_kf(1,:);
Err_Kalman_x2=X(2,:)-X_kf(2,:);
%% 绘图
t=0:N-1;
figure('Name','信息滤波仿真')
plot(t,X_kf(1,:),'-.b','LineWidth',1.5);hold on
plot(t,X(1,:),'-ob','LineWidth',1.5);hold on
plot(t,X_kf(2,:),'-.k','LineWidth',1.5);hold on
plot(t,X(2,:),'-ok','LineWidth',1.5);
legend('kalman估计值x_1','真实值x_1','kalman估计值x_2','真实值x_2');
xlabel('采样时间');
ylabel('kalman估计值和真实值');
title('kalman估计值和真实值');
figure('Name','误差分析')
plot(t,Err_Kalman_x1,'-^b','LineWidth',1.5);
hold on
plot(t,Err_Kalman_x2,'-^k','LineWidth',1.5);
legend('x_1误差','x_2误差');
xlabel('采样时间');
ylabel('误差');
title('误差');
figure('Name','误差方差分析')
plot(t,sigma_x1_fang,'-*b','LineWidth',1.5);
hold on
plot(t,sigma_x2_fang,'-*k','LineWidth',1.5);
legend('x_1误差的方差','x_2误差的方差');
xlabel('采样时间');
ylabel('误差的方差');
title('状态估计误差的方差');
figure('Name','误差图')
sigma_x1=sigma_x1_fang.^0.5;
sigma_x2=sigma_x2_fang.^0.5;
errorbar(t, X_kf(1,:),3.*sigma_x1,'-ob','LineWidth',1.5);hold on
plot(t,X(1,:),'-.b','LineWidth',1.5);hold on
errorbar(t, X_kf(2,:),3.*sigma_x2,'-ok','LineWidth',1.5);hold on
plot(t,X(2,:),'-.k','LineWidth',1.5);hold on
legend('kalman估计值x_1误差线','真实值x_1','kalman估计值x_2误差线','真实值x_2');
xlabel('采样时间');
ylabel('kalman估计值误差线和真实值');
仿真结果:
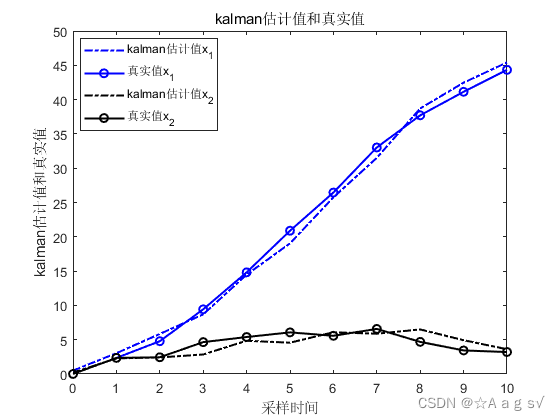
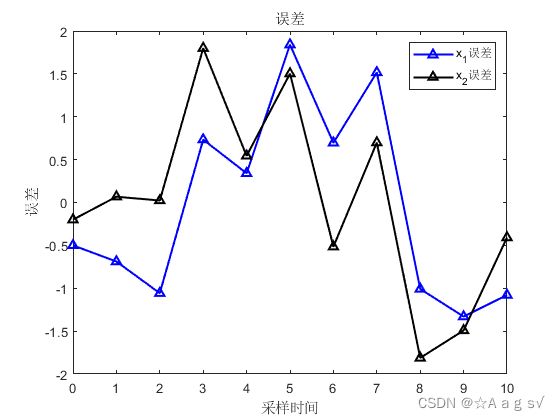
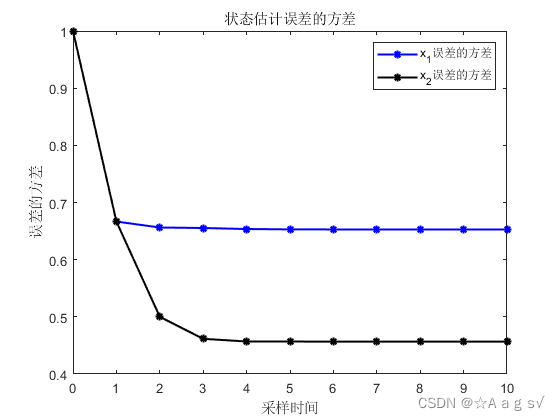
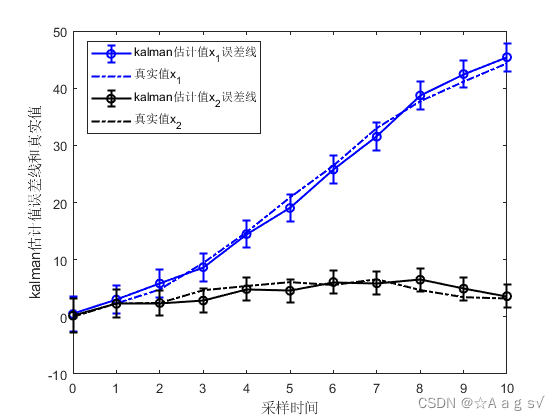
结论:三者仿真一模一样,所以说IF和Kalman滤波本质一样,形式互为对偶。
为了避免
I
k
/
k
−
1
,
I
k
I_{k/k-1},I_{k}
Ik/k−1,Ik存在不可逆的情况,利用矩阵求逆引理运算,进行如下转换:
I
k
/
k
−
1
=
(
A
k
I
k
−
1
−
1
A
k
T
+
C
k
Q
k
C
k
T
)
−
1
=
[
I
−
M
k
−
1
C
k
(
Q
k
−
1
+
C
k
T
M
k
−
1
C
k
)
−
1
C
k
T
]
A
k
−
T
I
k
−
1
A
k
−
1
=
(
I
−
N
k
−
1
)
M
k
−
1
\begin{aligned} I_{k/k-1} &= \left(A_{k}I_{k-1}^{-1}A_{k}^T + C_{k}Q_{k}C_{k}^{T}\right)^{-1} \\ &=[\mathcal{I}-M_{k-1}C_{k}(Q_{k}^{-1}+C_{k}^{T}M_{k-1}C_{k})^{-1}C_{k}^{T}]A_{k}^{-T}I_{k-1}A_{k}^{-1} \\ &= (\mathcal{I}-N_{k-1})M_{k-1} \end{aligned}
Ik/k−1=(AkIk−1−1AkT+CkQkCkT)−1=[I−Mk−1Ck(Qk−1+CkTMk−1Ck)−1CkT]Ak−TIk−1Ak−1=(I−Nk−1)Mk−1
其中
{
N
k
−
1
=
M
k
−
1
C
k
(
Q
k
−
1
+
C
k
T
M
k
−
1
C
k
)
−
1
C
k
T
(
正定可逆
)
M
k
−
1
=
A
k
−
T
I
k
−
1
A
k
−
1
(
非负正定
)
\begin{cases} N_{k-1}=M_{k-1}C_{k}(Q_{k}^{-1}+C_{k}^{T}M_{k-1}C_{k})^{-1}C_{k}^{T}&(正定可逆)\\ M_{k-1}=A_{k}^{-T}I_{k-1}A_{k}^{-1}&(非负正定) \end{cases}
{Nk−1=Mk−1Ck(Qk−1+CkTMk−1Ck)−1CkTMk−1=Ak−TIk−1Ak−1(正定可逆)(非负正定)
















 7065
7065











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









