






2025深度学习发论文&模型涨点之——多模态可解释性
多模态可解释性(Multimodal Interpretability)是指在多模态系统中,能够以人类可理解的方式解释系统的输出或决策过程。随着多模态大模型(MLLMs)的快速发展,其复杂性和规模带来了可解释性的挑战,但同时也推动了相关研究的进展。
-
Token 级别:研究视觉词元或视觉文本词元对模型决策的影响。
-
Embedding 级别:评估多模态嵌入(如视觉嵌入、文本嵌入、跨模态嵌入)如何在模型中融合信息。
-
神经元和网络层:分析个体神经元、神经元组以及不同网络层在决策中的作用。
- 架构设计:通过引入可解释模块或基于因果推理的方法,增强模型的透明度。
小编整理了一些多模态可解释性【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学扫码添加我
回复“多模态可解释性”即可全部领取

论文精选
论文1:
Explainable Multimodal Emotion Recognition
可解释的多模态情感识别
方法
-
多模态情感识别框架:提出了一种新的任务——可解释的多模态情感识别(EMER),通过整合视觉、音频和文本信息来识别情感,并为预测结果提供解释。
数据集构建:基于MER2023数据集,构建了一个新的标注数据集,包含332个样本,涵盖多模态线索(视觉、音频和文本)的情感标注。
基线模型与评估指标:建立了多模态大语言模型(MLLMs)的基线,并定义了评估指标,包括准确率、召回率和BLEU、METEOR等匹配度量。
多模态描述生成:利用大型语言模型(LLMs)对多模态线索进行消歧,并生成包含情感相关线索的多模态描述(EMER(Multi))。
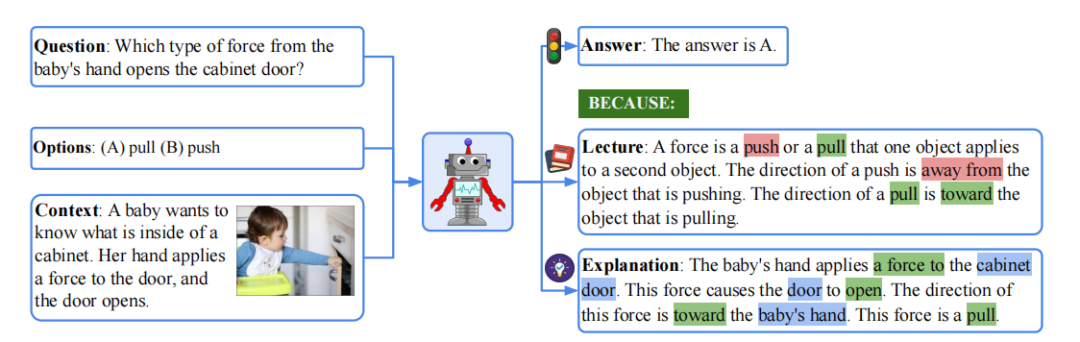
创新点
-
多模态情感识别的可解释性:首次提出为情感识别结果提供解释,增强了情感标签的可靠性和准确性。
开放词汇情感识别:通过LLMs生成的多模态描述,能够识别更丰富的情感标签,突破了传统情感分类的限制。
多模态线索整合:将视觉、音频和文本线索整合到一个统一的框架中,提高了情感识别的准确率。
性能提升:在多模态情感识别任务中,EMER(Multi)相比单模态方法(如EMER(Text)、EMER(Audio)和EMER(Video))显著提升了性能,准确率和召回率分别达到80.05%和80.07%。
论文2:
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering
通过思维链学习解释:科学问题回答中的多模态推理
方法
-
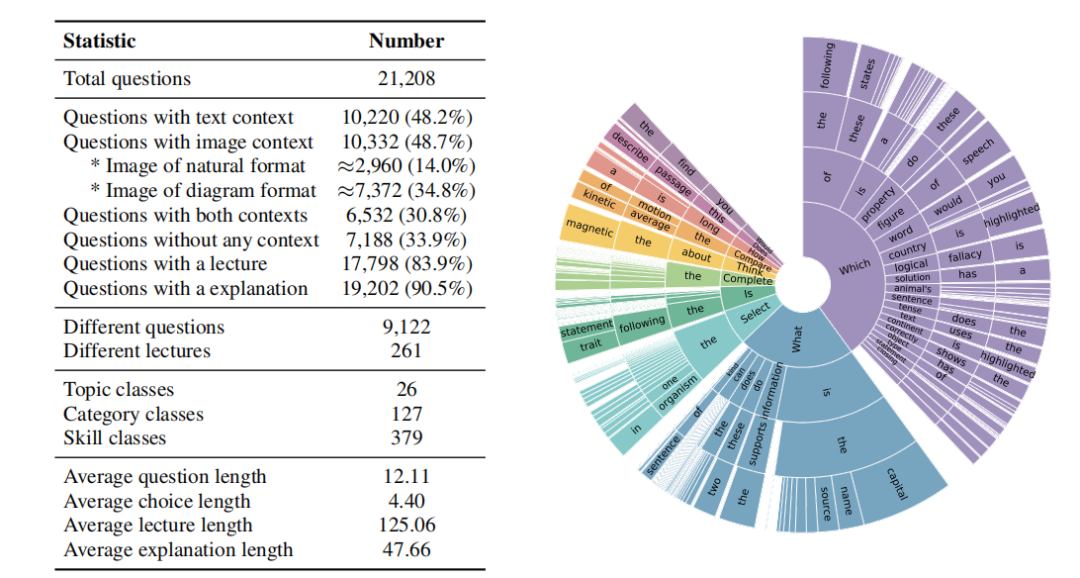
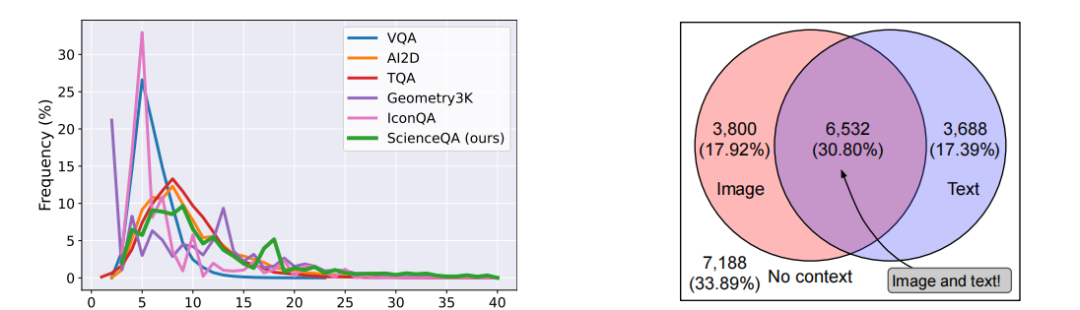
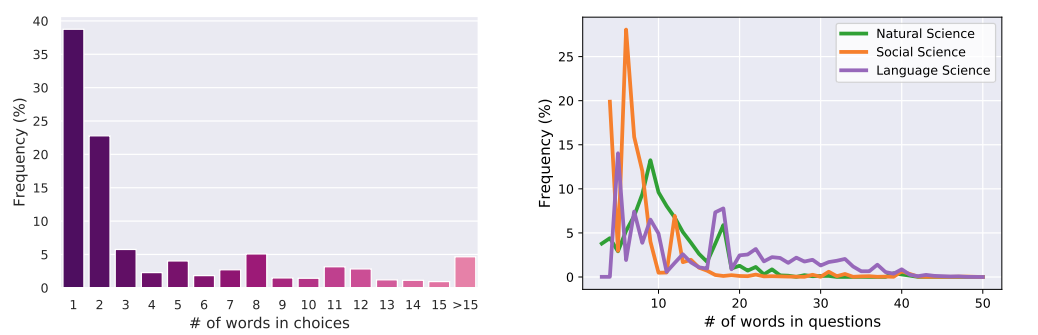
科学问题回答数据集(SCIENCEQA):构建了一个包含21,208个多模态选择题的大型数据集,涵盖自然科学、社会科学和语言科学等多个领域,并提供了详细的讲座和解释。
链式推理(Chain of Thought, CoT):设计了语言模型,使其能够生成讲座和解释作为思维链,以模拟人类在回答科学问题时的多步推理过程。
基线模型与评估:在SCIENCEQA上建立了多种基线模型,包括视觉问答(VQA)模型和大型语言模型(如UnifiedQA和GPT-3),并使用准确率和自动文本评估指标进行评估。
创新点
-
多模态科学问题数据集:SCIENCEQA是第一个大规模多模态科学问题数据集,包含丰富的领域多样性,并为答案提供了详细的讲座和解释。
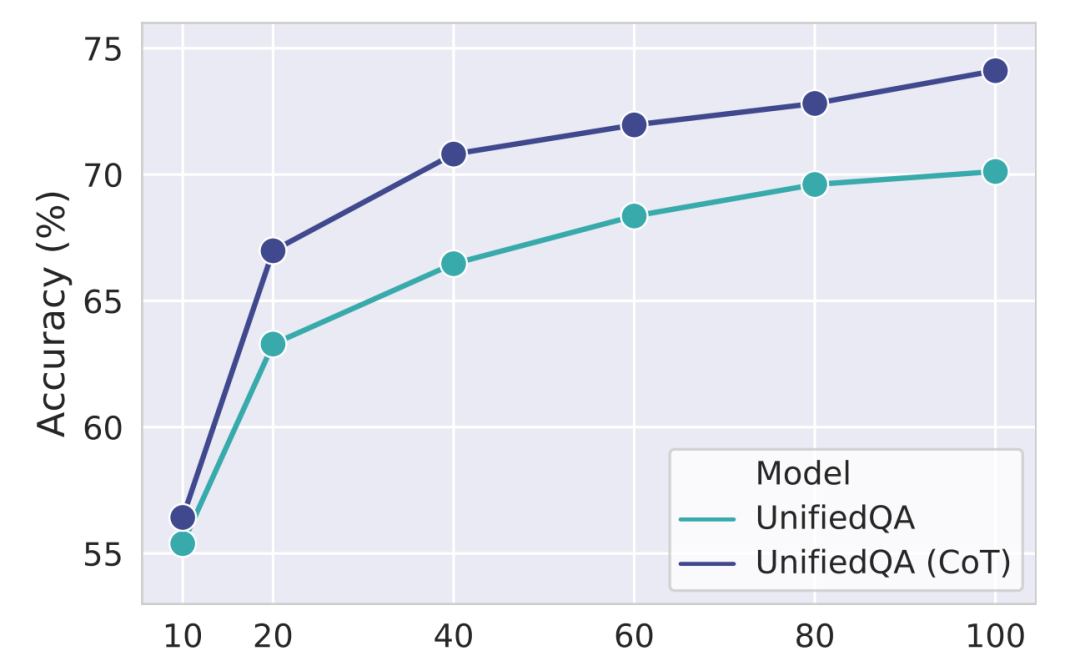
链式推理提升性能:通过生成解释,CoT显著提升了语言模型在少样本学习和微调设置下的性能。例如,GPT-3在少样本设置下通过CoT提升了1.20%的准确率,UnifiedQA通过CoT提升了3.99%。
数据效率提升:CoT帮助语言模型从更少的数据中学习,UnifiedQA在只有40%训练数据的情况下达到了与完整数据相同的性能。
性能提升:在SCIENCEQA基准测试中,使用CoT的GPT-3达到了75.17%的准确率,超过了人类表现(88.40%)。
论文3:
SCITUNE: Aligning Large Language Models with Scientific Multimodal Instructions
SCITUNE:将大型语言模型与科学多模态指令对齐
方法
-
科学多模态指令调优框架(SciTune):提出了一个两阶段的调优框架,包括科学概念对齐和科学指令调优,以提高大型语言模型(LLMs)对科学多模态指令的理解能力。
多模态指令模板:设计了包含视觉信号(如图表、方程)和文本信号(如标题、OCR和段落提及)的多模态指令模板,用于训练LLMs。
模型架构:基于LLaMA语言解码器和CLIP视觉编码器构建了多模态适配器,通过线性投影层将视觉编码器的输出转换为语言解码器的输入。
实验验证:在ScienceQA基准测试和多种科学图像理解任务上验证了SciTune模型的性能。
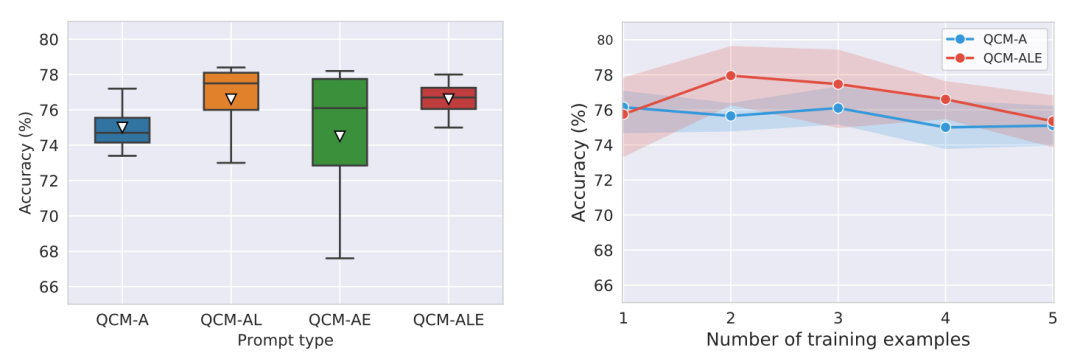
创新点
-
科学多模态指令调优:首次提出将LLMs与科学多模态指令对齐,提高了模型在科学任务中的性能。
多模态指令模板:通过引入科学图表、OCR和段落提及等多模态信号,丰富了指令调优的数据类型。
性能提升:在ScienceQA基准测试中,LLaMA-SciTune(13B)模型的准确率达到了90.03%,超过了人类表现(88.40%)。
少样本学习能力:LLaMA-SciTune在少样本情况下表现出色,对于训练中仅出现10次的讲座,模型的准确率迅速恢复到较高水平。
论文4:
MusicLIME: Explainable Multimodal Music Understanding
MusicLIME:可解释的多模态音乐理解
方法
-
多模态音乐模型:结合音频和歌词两种模态,使用基于Transformer的模型(ROBERTA和Audio Spectrogram Transformer)构建多模态音乐理解模型。
MUSICLIME解释方法:提出了一种模型不可知的特征重要性解释方法,通过分析音频和歌词特征的交互作用,提供模型决策的全面视图。
全局解释聚合:将局部解释聚合为全局解释,通过全局平均重要性和同质性加权重要性方法,提供模型行为的整体视图。
数据集构建:构建了两个多模态音乐数据集,包括Music4All和基于AudioSet的子集,用于情感和流派分类任务。
创新点
-
多模态解释方法:首次提出针对音乐领域的多模态解释方法,能够同时分析音频和歌词特征的交互作用。
全局解释聚合:通过聚合局部解释,提供了模型在不同类别上的全局行为视图,帮助用户更好地理解模型决策。
性能提升:多模态模型在音乐情感和流派分类任务中显著优于单模态模型,情感分类准确率提升至48.53%,流派分类准确率提升至57.34%。
数据集贡献:构建了两个高质量的多模态音乐数据集,为音乐信息检索领域的研究提供了新的资源。
小编整理了多模态可解释性论文代码合集
需要的同学扫码添加我
回复“ 多模态可解释性”即可全部领取


















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









