






多模态对齐是多模态学习中的一个核心概念,它涉及到如何在不同的数据模态之间发现和建立对应关系。这种对应关系可以是时间维度的(如视频中的画面与声音的时间同步),也可以是空间维度的(如图像中的区域与文本描述的对应)。对齐技术的目标是使不同模态的信息能够相互补充和增强,从而提高整体的学习效果。
今天就这两种技术整理出了13篇论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
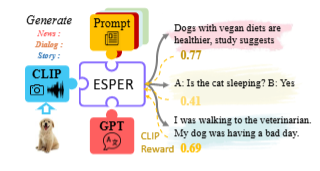
Multimodal Knowledge Alignment with Reinforcement Learning
多模态知识对齐与强化学习
方法:
-
ESPER模型:提出了ESPER(ExtraSensory PErception with Reinforcement learning),一个将语言模型扩展到多模态输入(如图像和音频描述)的零样本模型。
-
多模态提示调整:结合了多模态提示调整和强化学习奖励优化的见解,使用预训练的语言模型(如GPT-2)并训练少量适配器参数以将视觉特征映射到语言模型的词汇空间。
-
强化学习(RL):在训练期间,首先根据视觉特征请求模型完成,然后使用近端策略优化(PPO)更新轻量级视觉到文本转换的参数,以最大化由CLIP计算的相似度得分。
创新点:
-
无监督对齐:ESPER通过仅依赖于CLIP的余弦相似度来优化奖励,无需额外的显式配对(图像,描述)数据,实现了多模态输入与语言模型生成的对齐。
-
零样本泛化能力:由于语言模型参数保持不变,模型保持了零样本泛化的能力,实验表明ESPER在多种零样本任务上超越了基线和先前的工作。
-
性能提升:在COCO未配对描述任务中,ESPER相比于先前最先进的方法在CIDEr上有14.6点的改进,并且在推理速度上比基于每个令牌梯度优化的部分解码方法快102倍。
-
新基准测试:ESPER在一个新的基准测试集ESP数据集上展现了强大的零样本适应性,该数据集测试模型为同一图像生成不同风格的文本的能力。
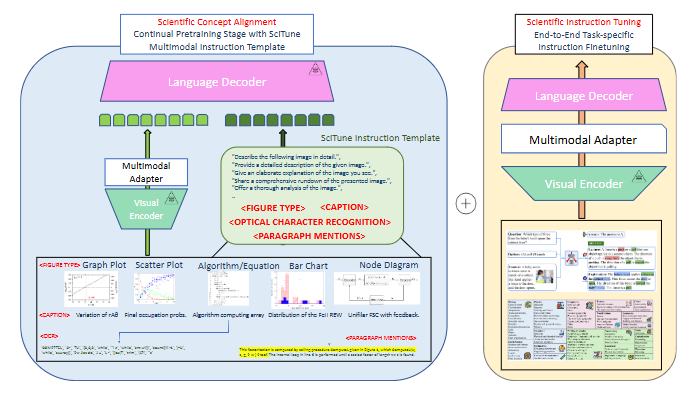
SCITUNE Aligning Large Language Models with Scientific Multimodal Instructions
SCITUNE:使大型语言模型与科学多模态指令对齐
方法:
-
SciTune框架:提出了SciTune,一个用于提升大型语言模型(LLM)遵循科学多模态指令能力的调整框架。
-
科学概念对齐:通过学习各种科学视觉信号(如图表、方程、图解等)和文本信号(如标题、光学字符识别(OCR)和段落提及)来进行科学概念对齐。
-
科学指令调整:在多模态科学推理任务上进行微调,以提高模型在科学环境中的应用能力。
创新点:
-
科学多模态指令调整:SciTune通过科学概念对齐和科学指令调整两个阶段,提高了模型在科学领域内理解和执行复杂程序、协议和指南的能力。
-
人类生成的科学指令:与使用机器生成内容的模型不同,SciTune专注于人类生成的多模态指令,以更好地符合科学社区的标准和期望。
-
性能提升:在ScienceQA基准测试中,与仅使用机器生成数据进行微调的模型相比,LLaMA-SciTune在平均表现和许多子类别上超越了人类表现。
-
零示范推理:LLaMA-SciTune在推理期间无需示范即可在各种科学图像理解任务中表现显著优于最先进的视觉-语言模型。
论文3
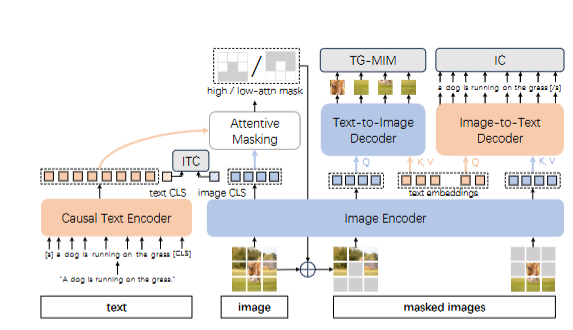
SyCoCa: Symmetrizing Contrastive Captioners with Attentive Masking for Multimodal Alignment
SyCoCa:通过关注掩蔽实现对比性描述符的对称化以进行多模态对齐
方法:
-
对比性描述符(CoCa):整合了对比性语言-图像预训练(CLIP)和图像描述(IC)到一个统一框架中。
-
双向交互:提出了Symmetrizing Contrastive Captioners(SyCoCa),引入了图像和文本之间的双向交互,包括全局和局部表示层面。
-
文本引导的遮蔽图像建模(TG-MIM):基于ITC和IC头扩展了TG-MIM头,利用文本线索重建上下文图像和视觉线索预测文本内容。
-
关注掩蔽策略:为了实现双向局部交互,采用了关注掩蔽策略来选择有效的图像块进行交互。
创新点:
-
双向全局和局部交互:SyCoCa通过引入TG-MIM头,实现了图像到文本和文本到图像的双向局部交互,提升了细粒度的多模态对齐能力。
-
关注掩蔽策略:通过计算图像令牌和文本令牌之间的相似度来选择相关的图像块,提高了模型对图像和文本之间相关性的理解,例如在Flickr-30k数据集上的图像-文本检索任务中,mTR/mIR性能提升了+5.1%/3.7%。
-
多模态任务性能提升:在五个视觉-语言任务中验证了SyCoCa的有效性,包括图像-文本检索、图像描述、视觉问答以及零样本/微调图像分类任务。
-
细粒度对齐能力:SyCoCa通过TG-MIM头和关注掩蔽策略,增强了模型在细粒度层面上对图像和文本的对齐能力,从而在多模态任务中取得了更好的性能。
论文4
ZeroNLG: Aligning and Autoencoding Domains for Zero-Shot Multimodal and Multilingual Natural Language Generation
ZeroNLG:对齐和自动编码领域以实现零样本多模态和多语言自然语言生成
方法:
-
零样本学习框架:提出了ZeroNLG框架,用于处理包括图像到文本(图像描述)、视频到文本(视频描述)和文本到文本(神经机器翻译)在内的多个NLG任务。
-
跨域对齐预训练目标:采用均方误差(MSE)和信息噪声对比估计(InfoNCE)损失,预训练视觉编码器和多语言编码器,以对齐和桥接不同领域。
-
去噪语言重建(DLR):通过DLR目标,使用多语言自动编码器学习通过重建给定其在共享潜在空间中的坐标的输入文本来生成文本。
创新点:
-
跨模态和语言的零样本NLG:ZeroNLG是第一个在统一框架内尝试进行零样本多模态和多语言自然语言生成的方法,无需任何下游训练对。
-
跨域对齐:通过在共同潜在空间中对齐不同领域,ZeroNLG能够桥接视觉和语言领域,以及英语和非英语领域,如中文、德文和法文。
-
性能提升:在十二个NLG任务上的广泛实验表明,ZeroNLG在没有任何标记的下游数据对训练的情况下,生成了高质量和“可信”的输出,并显著优于现有的零样本方法。
-
易于扩展:ZeroNLG可以轻松扩展到其他语言(例如瑞典语和意大利语),通过对齐和桥接英语和目标语言领域,证明了其在多语言NLG任务中的潜力和效果。

更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









