







参考:张伟男(哈尔滨工业大学):具身大模型关键技术与应用
1 构建智能机器人


2 具身智能


2.1 具身感知
重点需要感知能力的机器人:服务机器人、人机协作场景下机器人、社交导航机器人、环境探索机器人
2.1.1 物体感知
物体感知:
PointNet、MeshNet、VoxelNet、DeepSDF、Occupancy Networks
几何形状感知的下游任务:物体位姿估计
构建同类别物体统一坐标空间
物体抓取
传统的物体抓取、基于深度学习的物体抓取、CoPA:结合大模型物体感知的抓取
2.1.2 场景感知
定义:场景感知是通过实现与场景的交互来理解现实世界场景
意义:赋予机器人理解周围环境并与之交互的能力
具体形式:点云、地标、拓扑图、场景图、隐表示

2.1.3 行为感知
人类行为理解:可理解人类动作和视频的大语言模型MotionLLM

2.1.4 表达感知

(1) 感知能力强 AND 有一定的推理能力,就可以成为一个很好的机器人落地产品
(2) 感知能力也可以为抓取、操作等执行任务提供帮助,在端到端执行模型性能达标前,抓取等任务更多依赖感知能力
(3) 多模态大模型处理语言、2D图片、3D数据都没有超出我们的想象。但能处理交互数据的大模型还没有出现在地平线上
(4) 基于已有大模型,依赖人类先验设计模型结构或训练算法来弥补这个缺陷?人类先验或许不那么有效
2.2 具身推理
① 任务规划

基于深度学习技术的任务规划:RPN网络
结合大模型的任务规划:大模型作为转换器
结合大模型的任务规划:大模型作为规划器

微调大模型用于任务规划
训练小模型检测可行性,与大模型结合
任务规划的评估

具身导航(Embodied Navigation):智能体在3D环境中移动完成导航目标
目标的形式可以是点、物体、图像、区域;目标可以结合声音、自然语言指令、人类先验

基于规则的导航
基于学习的导航


2.3 具身执行
具身感知根据感知对象的不同分为四大类
对非人的感知:物体感知、场景感知
对人的感知:行为感知、表达感知
具身推理:任务规划、导航、具身问答
具身执行:技能学习(以技能描述、环境观察为输入,输出完成技能所需的7Dof轨迹)
大模型用于具身执行会存在很多问题:推理速度慢、数量需求大、可解释性差
具身执行强调泛化性,对物体位置、形状、场景、技能、机器人类别各种维度上的泛化性,泛化性也是目前最主要的挑战
3 具身智能发展

(1)多模态具身智能大模型构建技术

(2)基于大模型的持续学习技术

(3)基于大模型的交互式学习技术

(4)仿真环境及世界模型的构建技术

4 具身智能导航大模型(自动驾驶)
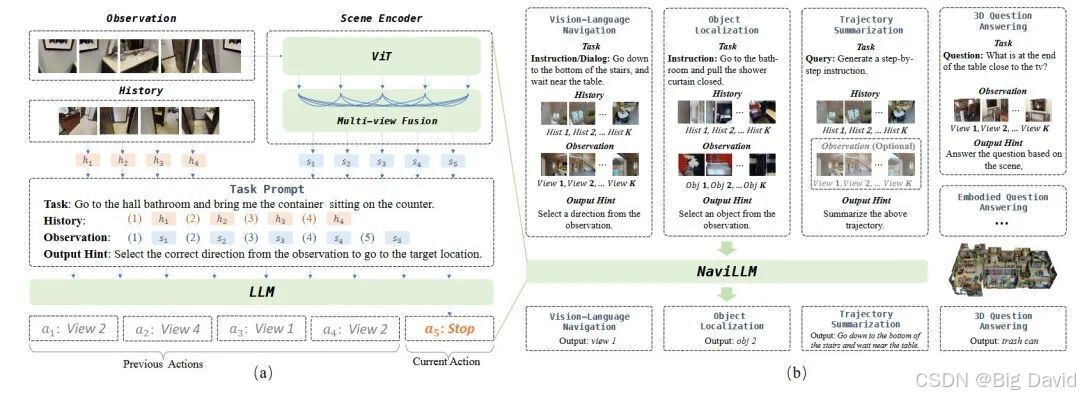
在具身智能系统的宏大架构里,导航大模型处于核心枢纽位置,它整合来自不同感知模态的信息,依据对环境的理解和任务指令,指挥机器人在复杂环境中灵活规划路径、执行操作以及做出决策。这一过程就像人类在陌生而复杂的空间里,依靠自身感官与认知,敏捷地避开障碍、寻找目标,完成各项任务。

















 1960
1960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









