







ADAPT: Action-aware Driving Caption Transformer 是清华AI Industry Research(AIR 团队)在ICRA 2023发表的一篇自动驾驶领域的文章。
本文提出了一个基于Transformer端到端的框架,能够对于输入的自动驾驶场景流提供比较友好的自然语言描述,以及对自动驾驶车辆控制和行动的推理。ADAPT通过共享输入视频的表达,联合训练驾驶场景描述任务和车辆控制预测任务。
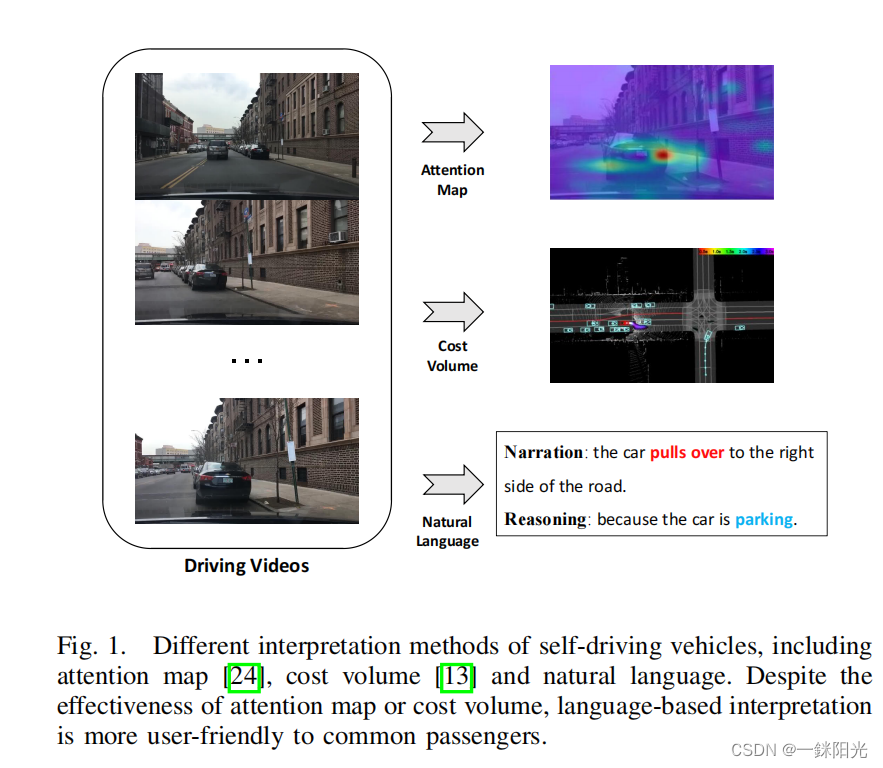
可解释的决策过程对于自动驾驶技术是非常重要的,自动驾驶汽车对乘客而言是一项较为激进的技术,需要非常高的信任度,如果乘客不能确认自己的安全问题,自动驾驶汽车就很难推广。
解释的形式有很多,如视觉注意图(Attention Map)(Kim, Jinkyu et al., 2017)或者成本量图(cost volume)( Zeng, Wenyuan et al.2019)等,
- 如视觉注意图可以过滤非显著的图像区域,保留对输出有潜在因果影响的注意区域,但由于用户对于智能系统的不熟悉,注意图等方法很容易导致用户的误解。
- 而文本解释却可以解决这个问题,自然语言的优势在于其本质上易于理解,即使用户不熟悉自动驾驶算法的设计,也能理解车辆执行决策的原因,例如,“[描述]:the car pulls over to the right side of the road,[解释]:because the car is parking”。将视频输入与车辆行为通过语言联系起来,让整个系统更加透明,便于理解,这对提升用户接受度具有重要作用。
因此本文提出了ADAPT(Action-awareDriving cAPtionTransformer),这是目前一个基于Transformer的驾驶行为描述架构,它可以为乘客提供自然语言形式的车辆决策描述和原因解释。为了减少车辆决策任务和文本描述任务之间的差异,我们使用多任务学习的方法来联合训练这两个任务,这种多任务框架可以通过加入额外的文本生成模块来方便的集成到自动驾驶系统中。我们在包含控制信号和车辆视频的大规模数据集BDD-X(Kim, Jinkyu et al., 2018)上验证了ADAPT的有效性,并在实车测试中取得了优异成果。
模型架构
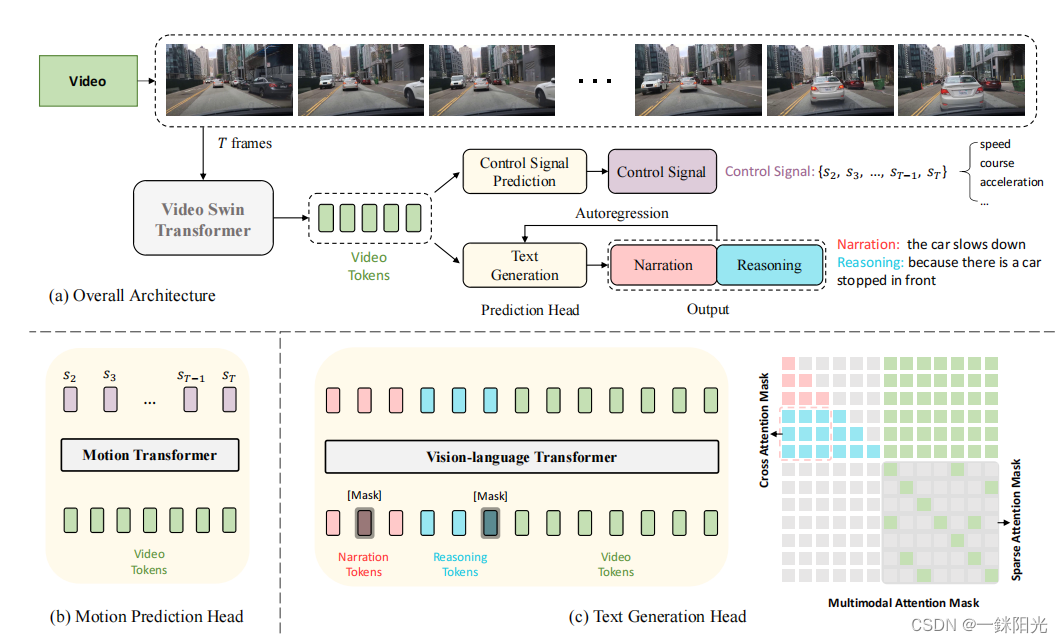
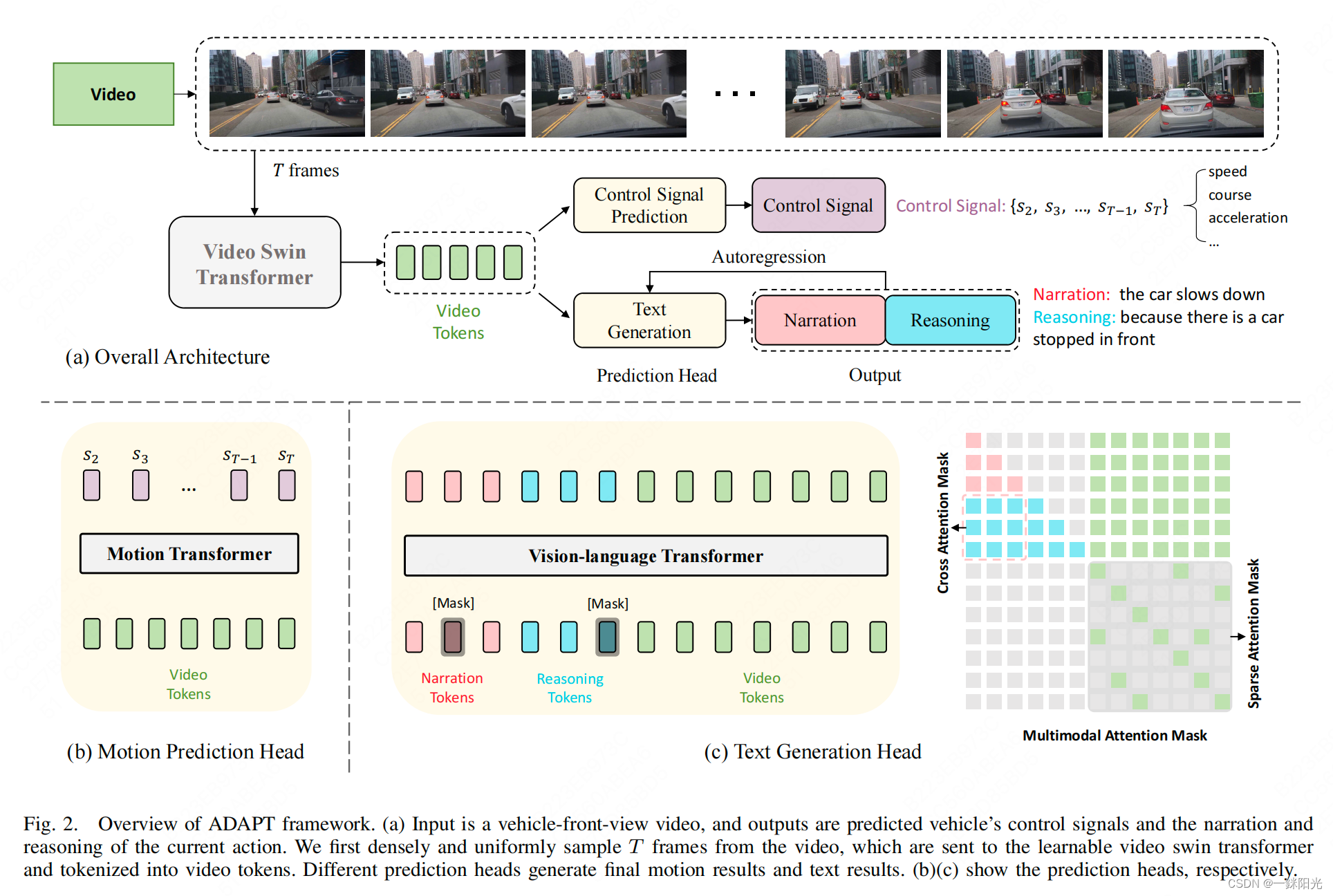
ADAPT可以同时完成两个任务:
- 车辆控制信号预测任务(Control Signal Prediction)
- 车辆控制信号预测任务将车辆第一视角视频作为输入,然后输出车辆的控制信号序列,如一段时间内的方向或加速度等。
- 车辆行为描述任务(Driving Caption Generation)
- 车辆行为描述任务采用相同的视频帧作为输入,并输出两个自然语言语句:一个描述车辆的动作(如:the car is accelerating),另一个解释采取该动作的原因(如:because the traffic lights turn green)
两个任务使用同一个视频编码器对车辆视频进行编码,本文使用Video Swin Transformer(Vidswin)作为视觉编码器,将视频帧编码为视频特征。然后通过不同的任务模块来获得不同的预测结果。
Video Encoder
假设输入为车辆第一视角视频,首先对其进行均匀采样,得到 T 帧大小为H × W × 3的视频帧。这些帧作为输入传递给Vidswin,可以得到大小为Fv = 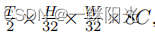
的视频特征 ,其中C是Vidswin中定义的通道维度。然后,视频特征被输入到各个任务的不同预测模块中。
Prediction Heads
本文假设车辆控制信号预测任务和行为描述任务在视频编码时具有语义一致性。直观来讲,车辆动作的文本描述和车辆的控制信号是自动驾驶车辆动作的不同表达形式,因此在单个网络中联合训练两个任务可以有效利用不同任务之间的归纳偏差,从而提高最终性能。
A: Text Generation Head
文本生成模块的目标是生成两个自然语言语句:车辆行为描述和原因解释。我们使用Vision-Language Transformer来实现文本生成。
在训练阶段,我们使用掩码语言建模(Mask Language Modeling)的方法对文本进行建模。对于输入的两个句子(动作叙述和推理),我们首先将每个句子填充到固定长度,然后在这两个句子的起始位置和终止位置分别插入[CLS]和[SEP],再将两者拼接起来,得到预处理后的句子。随后,将连接起来的句子输入到词嵌入层(Word Embedding)中。与常规图像描述任务不同的是:在ADAPT中,我们需要生成两个句子。为了识别动作描述和原因解释之间的差异,我们利用段嵌入(Segment Embedding)方法来区分它们。对于视频来说,我们使用跟控制信号预测模块相同的方法,将视频特征标记化。最后,文本标记和视频标记被送入Vision-Language Transformer中进行建模。
在推理阶段,ADAPT以自回归方式进行文本生成。具体来讲,我们将一个[CLS]符号(起始符)输入到模型中,生成一个单词,然后将起始符和生成的词组合起来继续输入到模型中,直到模型输出结束标记[SEP]或达到单句最大长度阈值结束。然后,我们将第一个句子填充到最大长度,再连接另一个[CLS],重复上述过程以生成第二个句子。
Control Signal Prediction Head
控制信号预测模块控制信号预测模块的目标是根据输入的视频预测车辆的控制信号(例如加速度、方向等)。如上所述,视频帧被编码为视频特征 ,大小为 。然后,我们沿着频道维度对视频特征进行标记化(tokenize),得到数目为 的视频标记,其大小为 ,然后我们使用一个Motion Transformer生成这些控制信号序列的预测值 。 最后,根据车辆真实的控制信号序列 以及模型预测的控制信号序列 ,我们用两者的均方误差作为该模块的损失函数 :
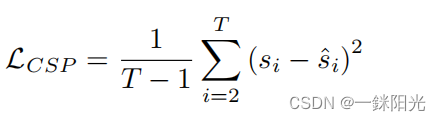
实验结果
本文通过多重指标测试了ADAPT的有效性,包括机器评测和人工评测。
- 在机器评测上,采用了BLEU4、METEOR、ROUGE-L和CIDEr(在后面的表格中缩写为B4、M、R和C)等多种语言任务常用的指标。此外,由于语言模型并没有完美的的机器评测方案,因此本文还为生成文本的主观正确性进行了人工评测,以使得生成的文本对乘客更加友好。
与state-of-the-art方法的比较
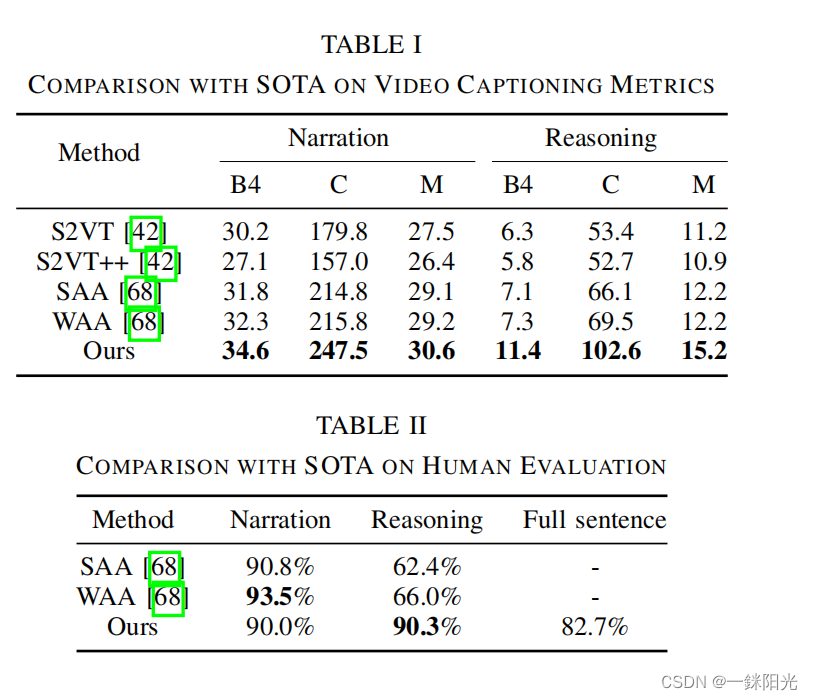
对于机器评测,我们将ADAPT与现有的先进方法在进行了比较。可以看到,ADAPT在机器评测上达到了SOTA的结果,如在Cider指标上,ADAPT在动作描述方面比先前的最先进方法高了31.7,在原因解释方面高了33.1。
对于人工评测,我们将整个评估过程分为三个部分:
- 动作描述/Narration
- 原因解释/Reasoning
- 动作描述+原因解释/Full Sentence
在人工评测的第一部分,标注员需要根据车辆视频判断生成的动作叙述是否符合车辆的动作。在第二部分,我们展示了车辆视频以及视频自带的动作叙述,让标注员判断模型生成的原因解释是否合理。最后,我们仅展示车辆视频,然后将模型生成的动作描述和原因解释合成一句话,让标注员判断这个长句子的准确性。人工评测结果如下表所示,可以看到,在人工评测方面,ADAPT在原因解释的正确率上显著优于先前的工作,同时在动作描述方面保持了较高的精度,这足以说明ADAPT的有效性。
虽然ADAPT的最终任务是生成自然语言语句,但我们也测试了其控制信号预测的性能。我们使用均方根误差(RMSE)和容差精度 来对控制信号的准确性进行衡量,其中容差精度的定义为控制信号截断值的准确率。例如,模型生成的预测方向 的截断值定义为:
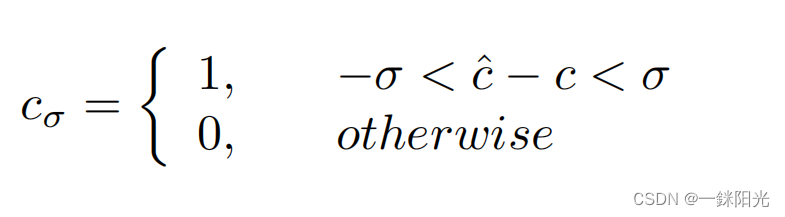
其中, 表示车辆真实的方向, 是容差阈值,在本工作中取了0.1、0.5、1.0、5.0、10.0五个值。 当然表示以百分比形式记录的 的精度,速度的 类似。
从表格中可以看到,ADAPT可以进一步提高控制信号预测的准确率,这也证明了多任务联合训练的有效性。

如下展示了ADAPT的一些可视化结果:

可以看到,ADAPT可以准确地识别车辆的行为以及决策的原因,比如在第一个例子中,车辆由于当前车道拥堵需要转到左侧车道。 从后两个例子中可以看到,对于黑夜、阴雨天等复杂场景,模型仍然能给出流畅准确的描述和解释,比如在最后一个例子中,即使有雨刷器这种“视觉干扰”,模型也能识别到场景中的信号标志"STOP Sign",这也证明了ADAPT算法的鲁棒性和泛化性。
- ADAPT代码仓库 https://github.com/jxbbb/ADAPT
- ADAPT 论文链接:https://arxiv.org/abs/2302.00673















 159
159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











