






编辑 | 自动驾驶之心
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
原标题:The 1st-Place Solution for CVPR 2024 Autonomous Grand Challenge Track on Predictive World Model
论文链接:https://opendrivelab.github.io/Challenge%202024/predictive_USTC_IAT_United.pdf
作者单位:中国科技大学 慕尼黑工业大学 西安交通大学
Verified as the Outstanding Champion in the Predictive World Model by the Organizing Committee.

论文思路:
本文描述了团队 USTC IAT United 在 CVPR 2024 自动驾驶大挑战赛预测世界模型赛道中获得第一名的解决方案。本次挑战的目标是引入一个能够基于当前状态预测未来状态的世界模型。为实现这一目标,本文首先利用高质量的多相机视角自动驾驶数据集进行自监督训练。接着,本文改进了比赛的基线模型以预测未来的点云。具体来说,本文使用预训练的 BEV 编码器作为特征提取器,并增强 BEV 编码器中的时间对齐模块。然后,本文使用 Latent Rendering 操作符提取更具辨识度和代表性的特征,并改进 Transformer 解码器中的注意力机制。最终,本文输出预测的未来点云。本文的 ViDAR++ 在 OpenScene 私有测试集上达到了 0.6615 的 CD@overall(Chamfer Distance)。
论文设计:
自动驾驶应用 [11, 17] 需要集成感知、预测和规划,这涉及语义特征、三维几何特征和时间信息。然而,传统的预训练方法面临显著挑战,因为它们依赖于昂贵的人工标注(如语义类别标签、边界框和轨迹)或需要高精度的城市高清地图,从而限制了它们在大规模未标注数据集上的可扩展性。为了解决这些问题,研究人员提出了一种新的预训练任务:视觉点云预测(visual point clouds forecasting) [16],其目标是从历史视觉输入预测未来的点云。这对于自动驾驶系统中的规划和决策至关重要。视觉点云预测提供了两个主要优势:(1)协同学习 [6]:该任务要求模型同时学习语义、三维结构和时间动态。这种协同学习使模型在各种下游任务中表现更好。(2)自监督训练 [1]:视觉点云预测不需要昂贵的标注数据,而是使用未标注 LiDAR [9] 序列进行自监督训练,使其更具可扩展性。
本次挑战的目的是利用世界模型预测未来帧。作为现实的抽象时空表示,世界模型可以基于当前状态预测未来状态。世界模型的学习过程有可能为自动驾驶提供一个预训练的基础模型。在仅有视觉输入的情况下,神经网络输出未来的点云,以验证其对世界的预测能力。如图 1 所示,给定过去 3 秒的视觉观测,基于指定的未来自车位姿预测未来 3 秒的点云。
在这项工作中,本文提出了一个包含两个阶段的多阶段框架:自监督训练和点云预测。本文的贡献如下:
多视角自监督训练。本文认为,对于视觉 BEV 提取器,对比学习方法可以初步从多视角图像中捕捉潜在特征。为了增强 BEV 特征提取,本文提出了一种多视角自监督训练方法。
时间注意力。本文通过基于空间位置对齐和融合两个不同时间的 BEV 特征图,改进了传统的时间交叉注意力机制。
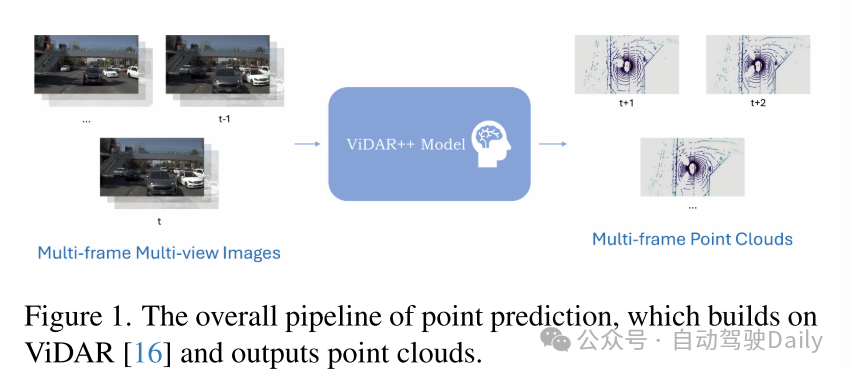
图 1. 点云预测的整体流程,该流程基于 ViDAR [16] 构建并输出点云。
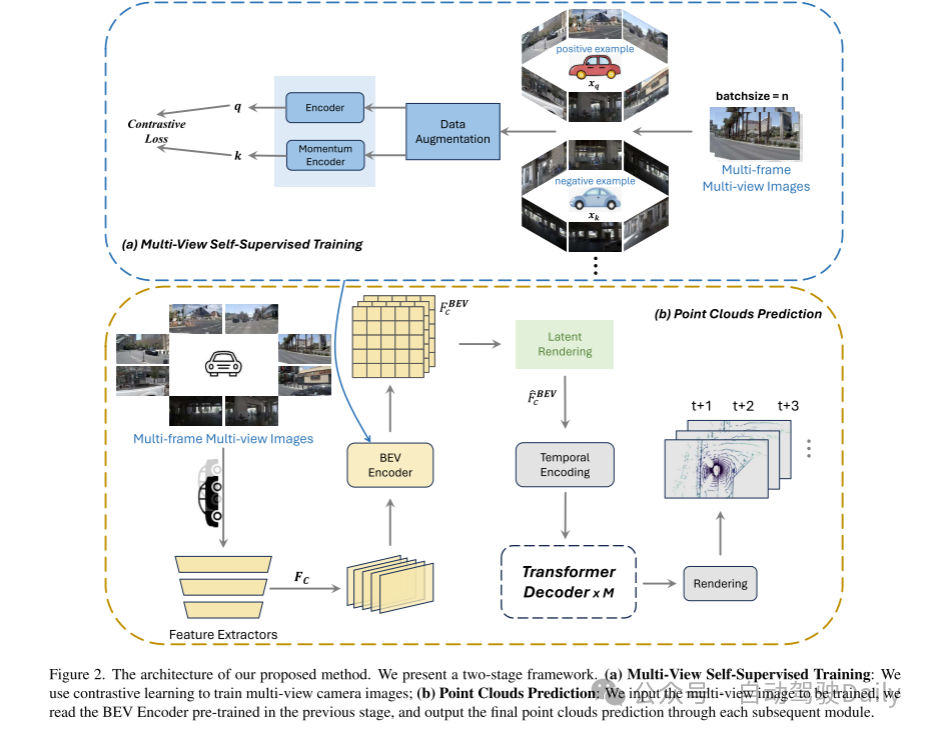
图 2. 本文提出的方法的架构。本文呈现了一个两阶段的框架。(a) 多视角自监督训练:本文使用对比学习来训练多视角相机图像;(b) 点云预测:本文输入待训练的多视角图像,读取在前一阶段预训练的 BEV 编码器,并通过每个后续模块输出最终的点云预测。
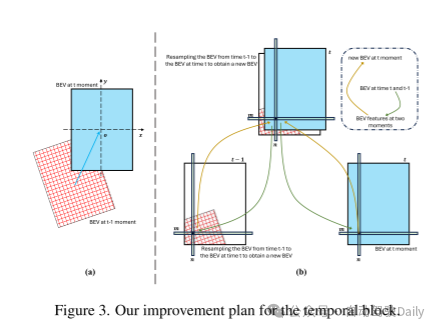
图 3. 本文对时间模块的改进方案。
方法
本节介绍了本文获得第一名的方法的详细内容。整体架构如图 2 所示。首先,本文介绍自监督训练过程,详细说明本文的训练方法以及对编码器内各个模块所做的改进。这些增强措施帮助模型更好地提取 BEV 特征。接下来,本文描述点云预测过程,重点介绍在各个模块中对基线模型 ViDAR [16] 所做的改进。本文的方法基于基线方法进行了改进,命名为 ViDAR++。更详细的技术细节将在本节中呈现。
自监督训练
详细说明。为了更好地提取 BEV 特征,本文为本次比赛提出了一种多视角自监督训练方法。类似于 MoCo [7],本文认为对比学习可以初步捕捉多视角图像的潜在特征。与随机初始化的网络相比,这种方法使得网络更加稳定,并且收敛速度更快。
本文的预训练框架如图 2 (a) 所示。首先,本文对输入的未标注图像应用数据增强技术,包括 RandomResizedCrop、ColorJitter、RandomGrayscale 和 GaussianBlur [13]。此外,本文的训练编码器(training encoder)和动量编码器(momentum encoder)都使用本文提出的 BEV 编码器。本文将训练批次大小设置为 8 的倍数。在对比学习中,正样本是同一帧中由八个相机从不同角度拍摄的图像,而负样本是批次中的其余样本,即来自不同帧的多视角图像。正样本和负样本经过两种不同的数据增强处理,分别得到 和 。然后,将 和 输入编码器和动量编码器,以获取特征 和 。随后,计算正样本和负样本特征之间的相似性。最后,根据这些相似性更新网络。在整个训练过程中,本文使用噪声对比估计 (NCE) [5] 损失来确保每个图像与其增强版本之间的输出相似性最大化。
BEV 编码器。类似于 BEVFormer [10],本文的 BEV 编码器由六层组成,每层遵循传统的 Transformer 结构,但具有三种自定义设计:BEV 查询、空间交叉注意力和时间自注意力。具体来说,BEV 查询是网格状的可学习参数,旨在通过注意力机制从多相机视图中查询 BEV 空间中的特征。空间交叉注意力和时间自注意力是与 BEV 查询结合使用的注意力层,分别用于定位和聚合来自多相机图像的空间特征和来自历史 BEV 的时间特征。本文主要改进了时间注意力模块,以实现 BEV 的时间对齐和融合。
时间注意力模块。图 3 (a) 显示了时间 和时间 的 BEV 图,其中两个 BEV 图在角度上有所不同,并且存在空间位移。图 3 (b) 说明了时间对齐的原理。具体来说,将时间 的 BEV 图在时间 的 BEV 图的空间位置上进行重新采样,以获得一个新的时间 的 BEV 图,对应于时间 的空间位置。然后,将新的时间 的 BEV 图和时间 的 BEV 图在通道维度上进行拼接,得到一个拼接后的 BEV 图。这个拼接后的 BEV 图完成了时空对齐。接下来,更新每个空间位置的通道向量值,以获得时间 的新的融合 BEV 图。例如,在空间位置 ,为了找到时间 新的 BEV 图中 的通道向量值,首先从拼接后的 BEV 图中获取 的通道向量值。然后,计算 个相对特征索引位置和权重。在第二步中,根据相对特征索引位置和权重,直接在时间 的 BEV 特征图的 处获得所需的特征 1。在第三步中,根据相对特征索引位置和权重,在时间 的新的 BEV 特征图的 处获得所需的特征 2。最后,将两个特征取平均值,得到时间 的新的 BEV 图中 的通道向量值。这样就完成了 BEV 的时间对齐和融合。
点云预测
点云预测阶段是一个端到端的训练过程。在完成自监督训练后,本文利用预训练权重来初始化 BEV 编码器。接下来,本文使用有标签的数据进行监督的端到端训练。本文的方法基于 ViDAR [16],并对 Future Decoder 进行了改进,这些改进增强了预测点云的时间一致性。整体架构包括三个组件:
(a) BEV 编码器,它作为预训练的目标结构,从视觉序列输入 中提取 BEV 嵌入 。本文使用的编码器参考了 BEVFormer [10] 的结构;
(b) 潜在渲染操作符,这一组件与 ViDAR 中的结构相同,在潜在空间中模拟体积渲染过程,从 中导出几何嵌入 ;
(c) Transformer 解码器,以自回归的方式在时间戳 预测未来的 BEV 特征 。随后,使用预测头将 投射到 3D 占据体积 ,以确保环境的准确空间表示。在 Transformer 编码器中的时间交叉注意力中,本文也应用了之前对时间模块的改进,以更好地整合时间关系。
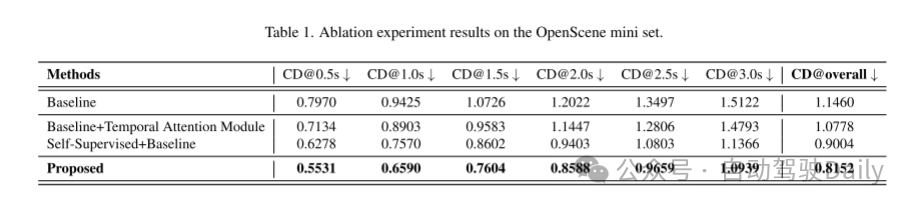
实验结果:

引用:
https://opendrivelab.github.io/Challenge%202024/predictive_USTC_IAT_United.pdf
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵

















 2091
2091

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









