









原文链接:https://arxiv.org/abs/2403.16440
简介:为减小成本,实践中往往使用多视角摄像头进行3D目标检测,但仅依赖摄像头难以达到高精度和鲁棒性。本文将毫米波雷达与摄像头结合,提出RCBEVDet,进行BEV下的多模态3D目标检测。首先,设计RadarBEVNet提取雷达BEV特征,包含双分支雷达主干和RCS感知的BEV编码器。前者使用基于点的编码器和基于Transformer的编码器,并使用注射和提取模块进行编码器之间的交互。后者使用RCS作为物体大小的先验,以将点特征分散到BEV。基于可变形注意力机制的交叉注意力多层融合模块包含通道和空间融合层,能自动对齐多模态BEV特征。实验表明,本文的方法可以在NuScenes和VoD数据集上达到SotA性能,且有更快的速度。
0. 概述
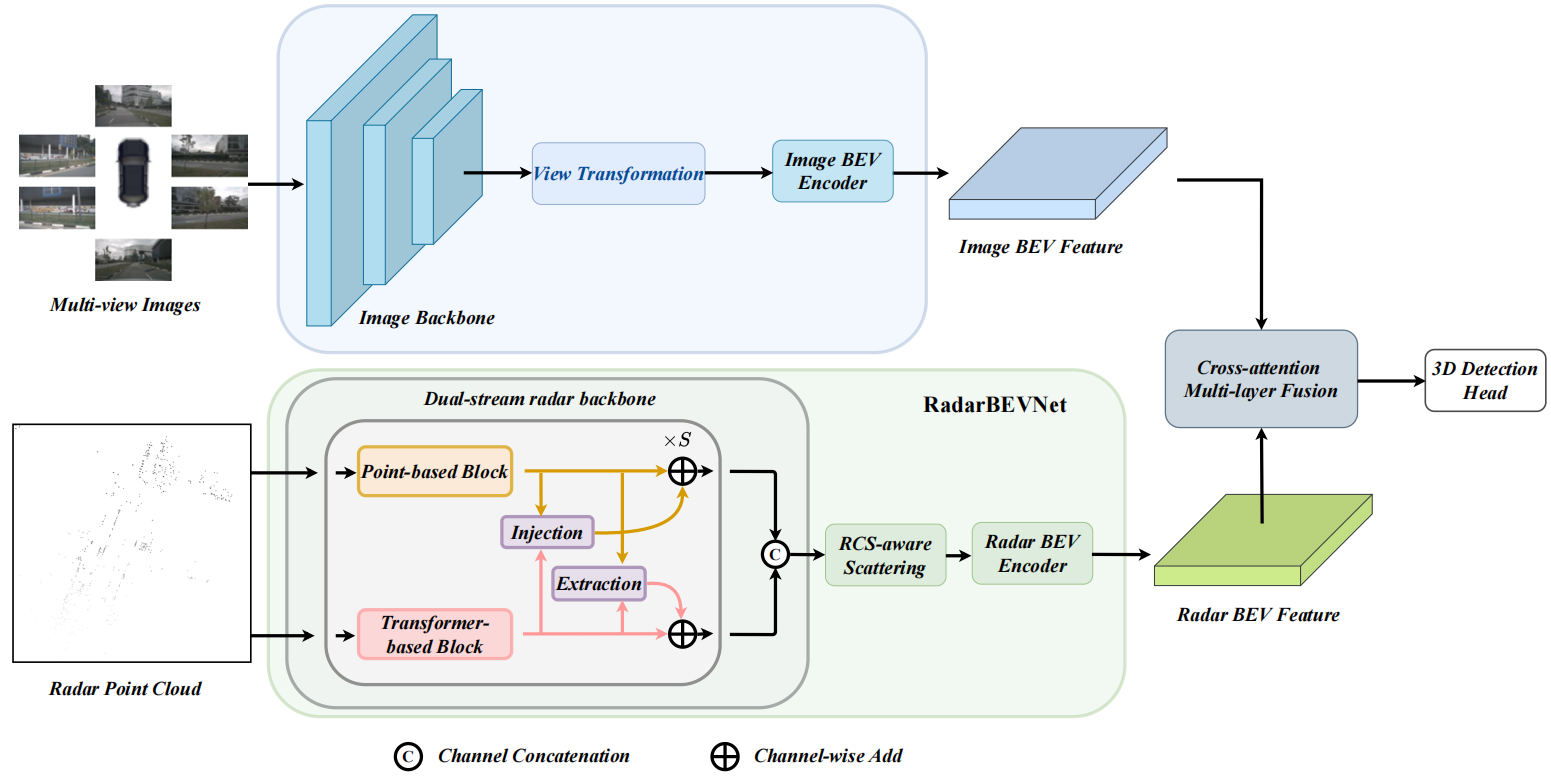
如图所示,图像分支包含图像编码器、视图变换和BEV编码器,输出图像BEV特征。
1. RadarBEVNet
传统雷达-摄像头融合的方法主要采用针对激光雷达点云设计的雷达编码器。本文提出RadarBEVNet,进行高效的雷达BEV特征提取。
1.1 双分支雷达主干
包含基于点的主干和基于Transformer的主干。

基于点的主干提取局部特征,其基本结构单元类似PointNet(MLP+最大池化得到全局特征,然后与逐点特征拼接):
f = Concat [ MLP ( f ) , MaxPool ( MLP ( f ) ) ] f=\text{Concat}[\text{MLP}(f),\text{MaxPool}(\text{MLP}(f))] f=Concat[MLP(f),MaxPool(MLP(f))]
基于Transformer的主干提取全局特征,其基本结构单元为标准Transformer块(注意力+前馈网络+归一化层)。考虑到自动驾驶场景范围较广,本文提出距离调制的自注意力(DMSA)机制,在早期聚合邻域信息,以促进模型收敛。
具体来说,给定 N N N个雷达点的坐标,首先计算逐对距离 D ∈ R N × N D\in\mathbb R^{N\times N} D∈RN×N,并生成类高斯状的权重图 G G G:
G i , j = exp ( − D i , j 2 / σ 2 ) G_{i,j}=\exp(-D^2_{i,j}/\sigma^2) Gi,j=exp(−Di,j2/σ2)
其中 σ \sigma σ为可学习参数,控制类高斯分布的带宽。该权重图会为近距离的位置分配高权重,对应的注意力机制如下:
DMSA ( Q , K , V ) = Softmax ( Q K T d + log G ) V = Softmax ( Q K T d − D 2 σ 2 ) V \begin{aligned}\text{DMSA}(Q,K,V)=&\text{Softmax}(\frac{QK^T}{\sqrt{d}}+\log G)V\\ =&\text{Softmax}(\frac{QK^T}{\sqrt{d}}-\frac{D^2}{\sigma^2})V\end{aligned} DMSA(Q,K,V)==Softmax(dQKT+logG)VSoftmax(dQKT−σ2D2)V
在训练期间,本文将 β = 1 / σ 2 \beta=1/\sigma^2 β=1/σ2看作可学习参数,且当 β = 0 \beta=0 β=0时,DMSA退化为自注意力。多头DMSA的每个头部有不同的 β i \beta_i βi值:
MultiHeadDMSA ( Q , K , V ) = Concat [ h e a d 1 , ⋯ , h e a d H ] , h e a d i = DMSA ( Q i , K i , V i ) = Softmax ( Q i K i T d i − β i D 2 ) V i \text{MultiHeadDMSA}(Q,K,V)=\text{Concat}[head_1,\cdots,head_H],\\ head_i=\text{DMSA}(Q_i,K_i,V_i)=\text{Softmax}(\frac{Q_iK_i^T}{\sqrt{d_i}}-\beta_iD^2)V_i MultiHeadDMSA(Q,K,V)=Concat[head1,⋯,headH],headi=DMSA(Qi,Ki,Vi)=Softmax(diQiKiT−βiD2)Vi
此外,本文还提出基于交叉注意力的注射与提取模块,以进行不同主干的交互。记 f p i f_p^i fpi与 f t i f_t^i fti分别为两个主干第 i i i层的输出特征,则在注射阶段, f p i f_p^i fpi会作为查询、 f t i f_t^i fti作为键与值,将Transformer特征“注射”到点特征中:
f p i = f p i + γ × CrossAttn ( LN ( f p i ) , LN ( f t i ) ) f_p^i=f_p^i+\gamma\times\text{CrossAttn}(\text{LN}(f_p^i),\text{LN}(f_t^i)) fpi=fpi+γ×CrossAttn(LN(fpi),LN(fti))
其中 LN \text{LN} LN为层归一化, γ \gamma γ为可学习缩放参数。
类似地,提取操作会使用交叉注意力提取点特征:
f
t
i
=
FFN
(
f
t
i
+
CrossAttn
(
LN
(
f
t
i
)
,
LN
(
f
p
i
)
)
)
f_t^i=\text{FFN}(f_t^i+\text{CrossAttn}(\text{LN}(f_t^i),\text{LN}(f_p^i)))
fti=FFN(fti+CrossAttn(LN(fti),LN(fpi)))

1.2 RCS感知的BEV编码器
目前的雷达BEV编码器通常根据坐标将点特征分散到体素空间,并压缩高度得到BEV特征。但这样得到的BEV特征很稀疏。堆叠更多的BEV编码层会导致小物体特征被平滑到背景区域。
本文提出RCS感知的BEV编码器,其中RCS反应了雷达检测某物体的能力。通常,大型物体有更强的雷达波反射,从而有更大的RCS。因此,RCS粗略反映了物体的大小。
本文RCS感知的BEV编码器关键在于RCS感知的分散操作,根据RCS值将一个点分散到多个BEV像素中。

给定某雷达点的坐标
c
=
(
c
x
,
c
y
)
c=(c_x,c_y)
c=(cx,cy)、RCS值
v
R
C
S
v_{RCS}
vRCS、特征
f
f
f和BEV像素坐标
p
=
(
p
x
,
p
y
)
p=(p_x,p_y)
p=(px,py),本文将
f
f
f分散到
p
p
p及其周围
(
c
x
2
+
c
y
2
)
×
v
R
C
S
(c_x^2+c_y^2)\times v_{RCS}
(cx2+cy2)×vRCS距离内的像素上。若某像素被分配了多个特征,则进行求和池化。这样可得到BEV特征
f
R
C
S
f_{RCS}
fRCS。
此外,对每个点,还引入类高斯的BEV权重图:
G x , y = exp ( − ( c x − p x ) 2 + ( c y − p y ) 2 1 3 ( c x 2 + c y 2 ) × v R C S ) G_{x,y}=\exp(-\frac{(c_x-p_x)^2+(c_y-p_y)^2}{\frac13(c_x^2+c_y^2)\times v_{RCS}}) Gx,y=exp(−31(cx2+cy2)×vRCS(cx−px)2+(cy−py)2)
所有点的BEV权重图求取最大值后,可得最终的BEV权重图 G R C S G_{RCS} GRCS。RCS感知的BEV特征可按下式获得:
f R C S ′ = MLP ( Concat [ f R C S , G R C S ] ) f'_{RCS}=\text{MLP}(\text{Concat}[f_{RCS},G_{RCS}]) fRCS′=MLP(Concat[fRCS,GRCS])
最后,该特征与原始BEV特征(应为按常规方案分散点特征得到的BEV特征)拼接,送入BEV编码器中。
2. 交叉注意力多层融合模块

2.1 使用交叉注意力进行多模态特征对齐
由于雷达点云的水平角误差较大,可能导致点落在物体外部,从而导致雷达与图像的BEV特征不对齐。本文使用交叉注意力动态对齐多模态特征。
本文使用可变形交叉注意力来捕捉雷达特征的位置偏差并减小计算。
给定图像和雷达的BEV特征
F
c
∈
R
C
c
×
H
×
W
,
F
r
∈
R
C
×
H
×
W
F_c\in\mathbb R^{C_c\times H\times W},F_r\in\mathbb R^{C\times H\times W}
Fc∈RCc×H×W,Fr∈RC×H×W,首先添加位置编码,然后将雷达特征转化为查询
z
q
r
z_{q_r}
zqr和参考点
p
q
r
p_{q_r}
pqr,图像特征视为键与值,进行可变形交叉注意力(图中绿色分支),更新
F
r
F_r
Fr:
DefromAttn ( z q r , p q r , F c ) = ∑ m = 1 M W m [ ∑ k = 1 K A m q k ⋅ W m ′ F c ( p q r + Δ p m q k ) ] \text{DefromAttn}(z_{q_r},p_{q_r},F_c)=\sum_{m=1}^MW_m[\sum_{k=1}^KA_{mqk}\cdot W'_mF_c(p_{q_r}+\Delta p_{mqk})] DefromAttn(zqr,pqr,Fc)=m=1∑MWm[k=1∑KAmqk⋅Wm′Fc(pqr+Δpmqk)]
其中 M M M为注意力头部的数量, K K K为采样位置数, Δ p m q k \Delta p_{mqk} Δpmqk为采样偏移量, A m q k A_{mqk} Amqk为注意力权重,根据 z q r z_{q_r} zqr和 F c F_c Fc计算。
类似地,交换
F
r
F_r
Fr与
F
c
F_c
Fc,再进行一次可变形交叉注意力,更新
F
c
F_c
Fc(图中蓝色分支)。
2.2 通道和空间融合
如图中棕色分支所示。
总结:本文的主要创新在于针对雷达模态的特点,利用RCS值改进了激光雷达点云的特征提取器。
















 97
97











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











