







【ML】异常检测、二分类问题
1. 异常检测、二分类问题
异常检测(Anomaly Detection) 和 二分类问题(Binary Classification) 都是机器学习中的重要任务,它们在很多应用场景中都有广泛的应用。尽管它们有一些相似之处,但它们的目标、挑战和特点有所不同。
1.1 异常检测(Anomaly Detection)
定义:
- 异常检测是一种用于识别数据集中不同于正常模式的异常点或异常行为的方法。这些异常点通常是稀少的、未标注的,可能代表某种异常情况或错误。
特点:
-
数据不平衡:
- 在异常检测任务中,异常数据点通常只占数据集中的极少数,大部分数据都是正常的。这种数据不平衡是异常检测的主要挑战之一。
-
无监督学习为主:
- 异常检测通常采用无监督学习方法,因为异常点在数据集中较为稀少且难以标注。模型需要在没有标签或仅有少量标签的情况下识别异常。
-
复杂的异常模式:
- 异常可能表现为不同的模式或类型,比如离群点、趋势变化、异常的时间序列模式等。模型需要具备识别多种复杂异常的能力。
-
应用场景广泛:
- 异常检测在金融欺诈检测、网络安全、设备故障监测、健康监控等领域有广泛应用。这些领域中的异常通常代表潜在的风险或问题,因此准确识别异常非常重要。
-
可解释性要求高:
- 在某些应用中,理解和解释为什么某个数据点被认为是异常非常重要。例如,在医疗或金融领域,用户需要清楚地知道异常的原因,以便采取相应措施。
1.2 二分类问题(Binary Classification)
定义:
- 二分类问题是指将输入数据分为两个类别的分类任务。模型的目标是根据输入特征,将数据点分类到两个互斥的类别之一。
特点:
-
明确的标签:
- 在二分类问题中,通常有明确的标签数据,即每个数据点都标注为“正类”或“负类”。这使得监督学习方法可以直接应用。
-
平衡和不平衡问题:
- 二分类问题中,有时两个类别的数据量相对均衡,但在某些应用场景中(如欺诈检测),数据可能会严重不平衡。这时,正负类的比例失衡会影响模型的性能,需要特别处理。
-
多样的算法:
- 二分类问题可以使用多种机器学习算法来解决,如逻辑回归、支持向量机、决策树、随机森林、神经网络等。不同算法在不同数据集和任务上的表现各不相同。
-
评估指标:
- 常用的评估指标包括准确率、精确率、召回率、F1值、AUC-ROC等。这些指标帮助评估模型在二分类任务上的表现,并指导模型的改进。
-
广泛应用:
- 二分类问题应用广泛,包括垃圾邮件检测、肿瘤分类(良性与恶性)、情感分析(正面与负面)、信用评分(信用良好与不良)等。
1.3 异常检测与二分类问题的对比
| 特点 | 异常检测 | 二分类问题 |
|---|---|---|
| 数据分布 | 通常极度不平衡(异常样本极少) | 可以平衡,也可能不平衡 |
| 学习类型 | 通常为无监督或半监督学习 | 主要是监督学习 |
| 应用场景 | 异常识别,如欺诈检测、故障检测 | 分类任务,如垃圾邮件检测、情感分析 |
| 标签可用性 | 异常样本少且通常未标注 | 大多数样本都有明确标签 |
| 模型复杂性 | 需要复杂模型来识别多种异常模式 | 模型相对简单,常用线性或非线性模型 |
| 可解释性 | 高度重视异常原因的解释 | 可解释性依赖具体应用和需求 |
1.4 总结
- 异常检测 主要用于识别数据中的异常点或异常行为,通常涉及极端的数据不平衡和无监督学习方法。它在风险监控和问题预警领域非常重要。
- 二分类问题 是将数据点分类到两个类别的任务,通常使用监督学习方法,适用于需要明确分类结果的场景。
两者尽管在某些方面存在相似之处,但其应用场景和挑战有所不同。

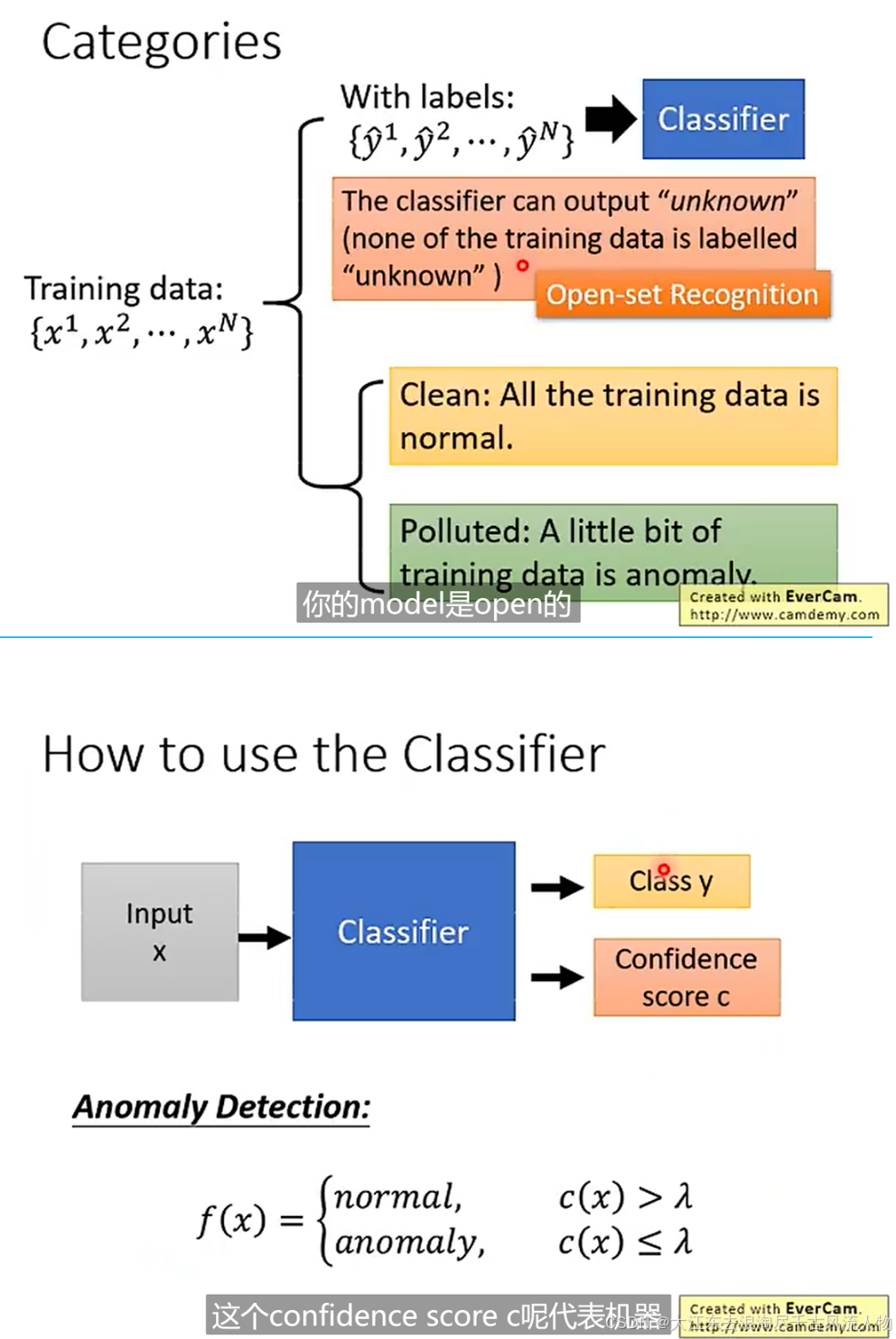

2. 模型额训练与评估

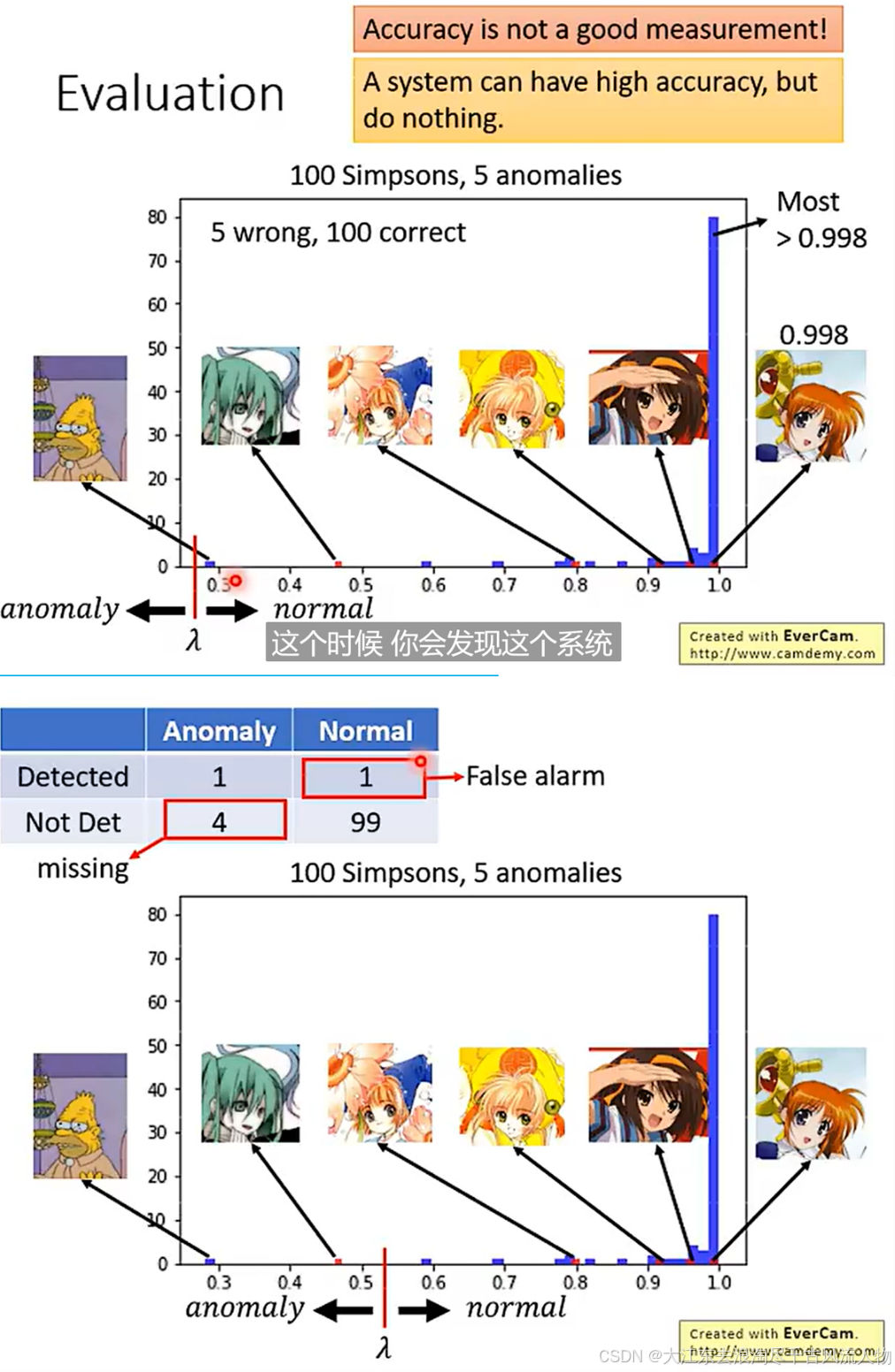
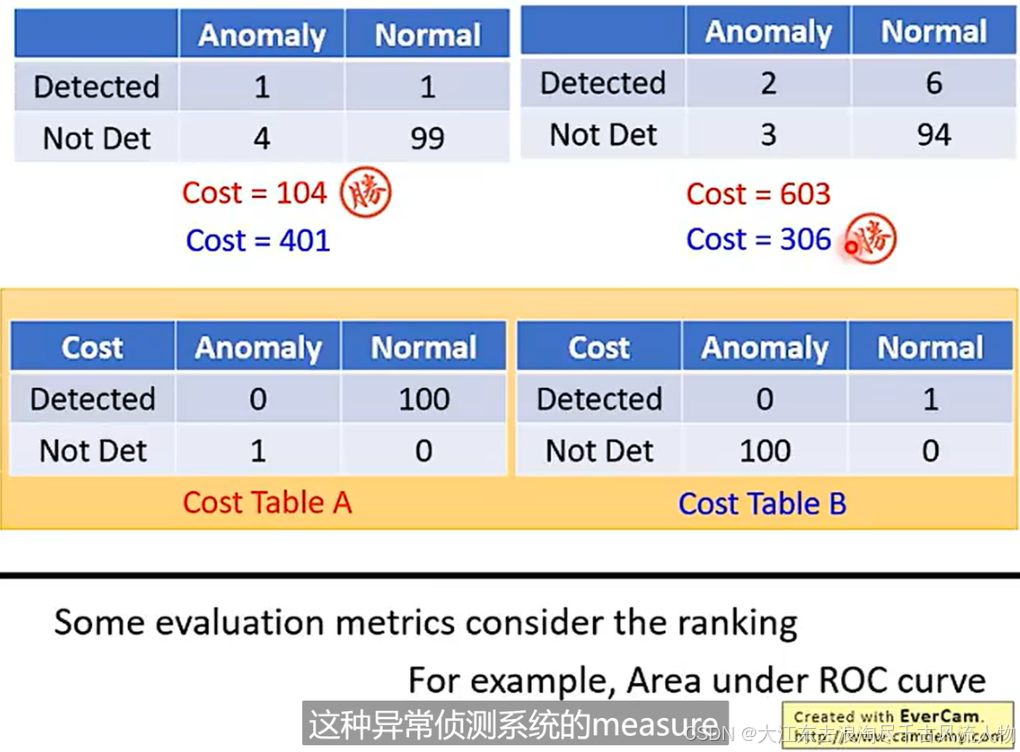
3. 为什么会出现比较高的误识别(导致假阳性、假阴性是识别结果的原因)
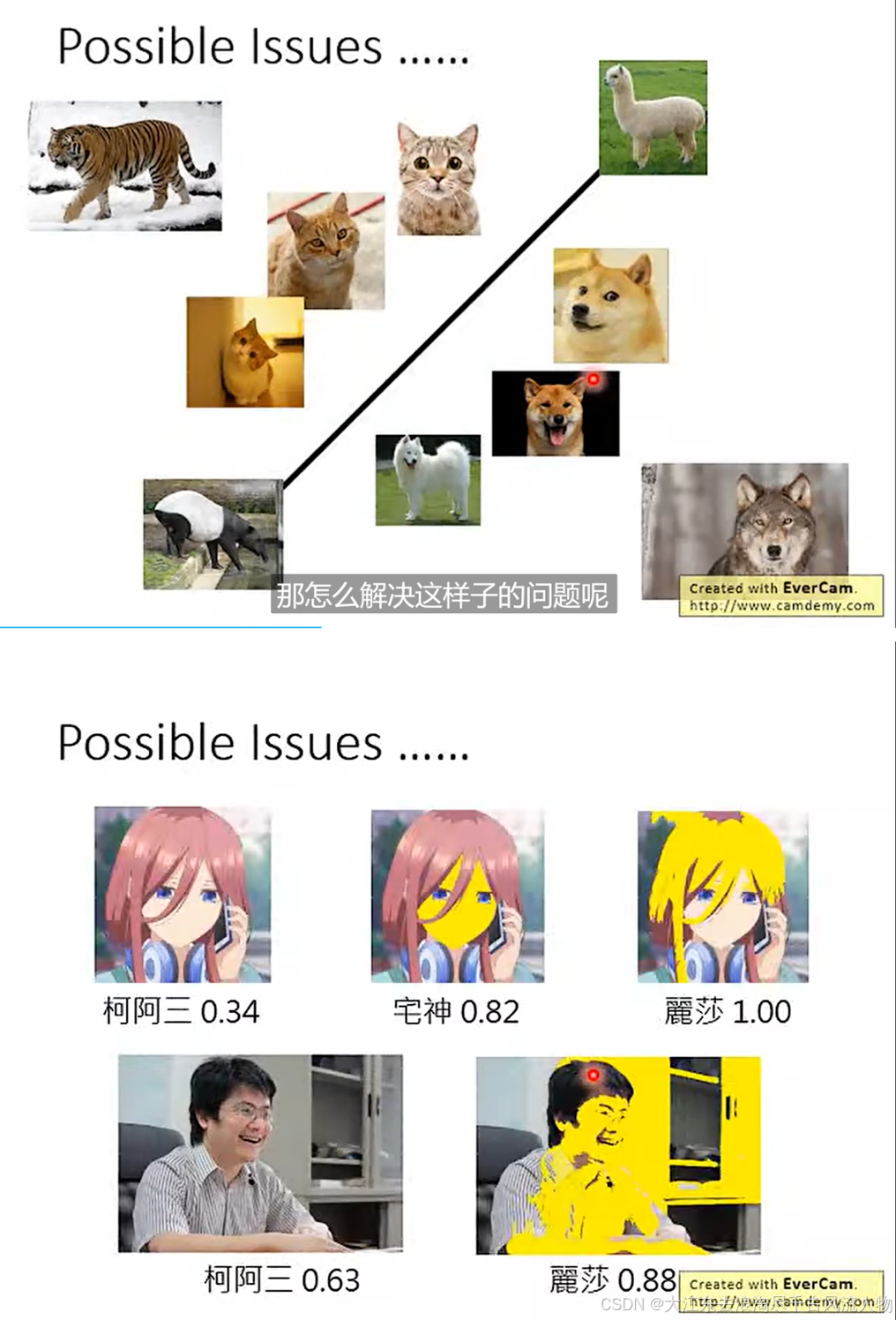
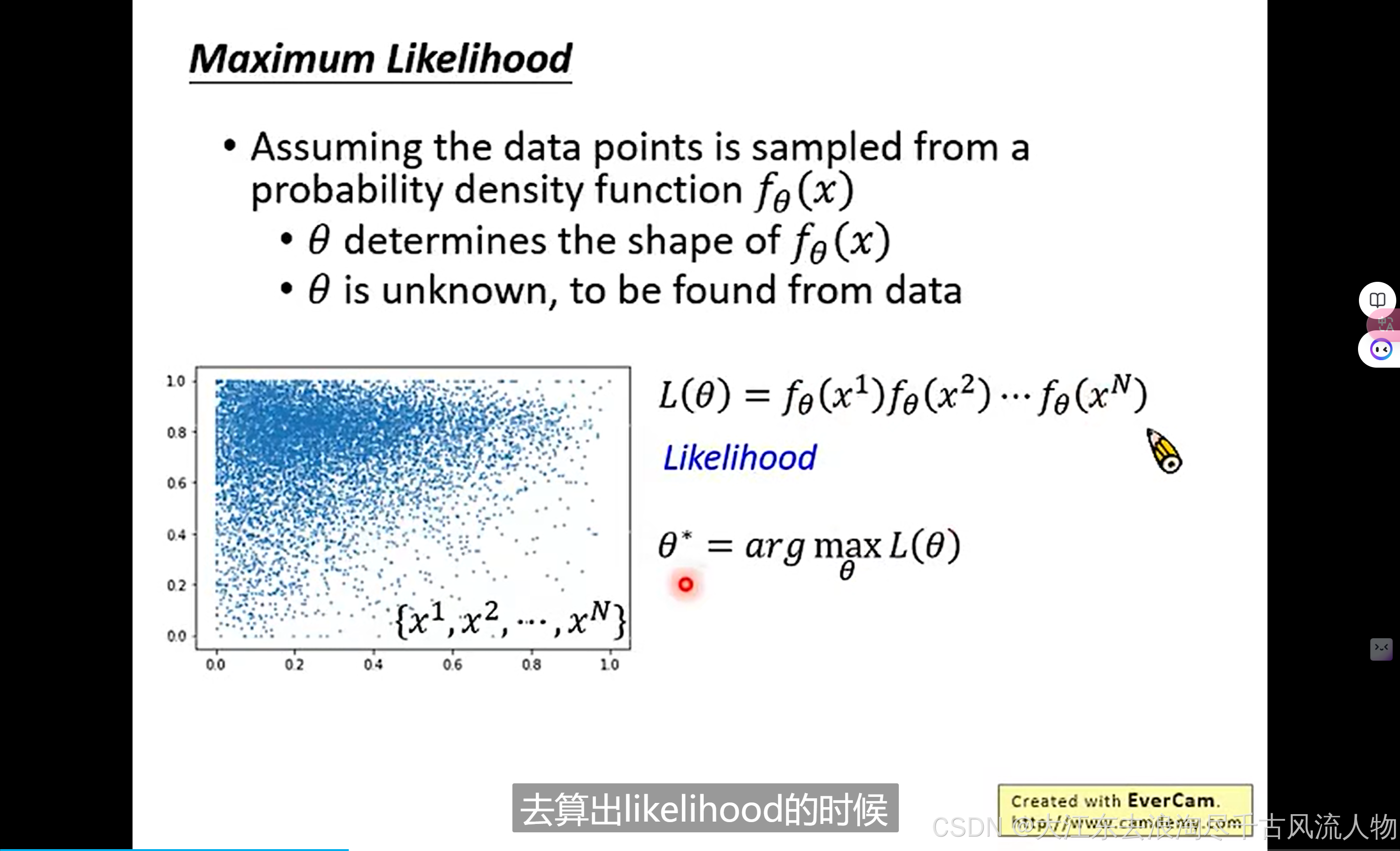
4. 基于gaussian假设下的异常行为检测


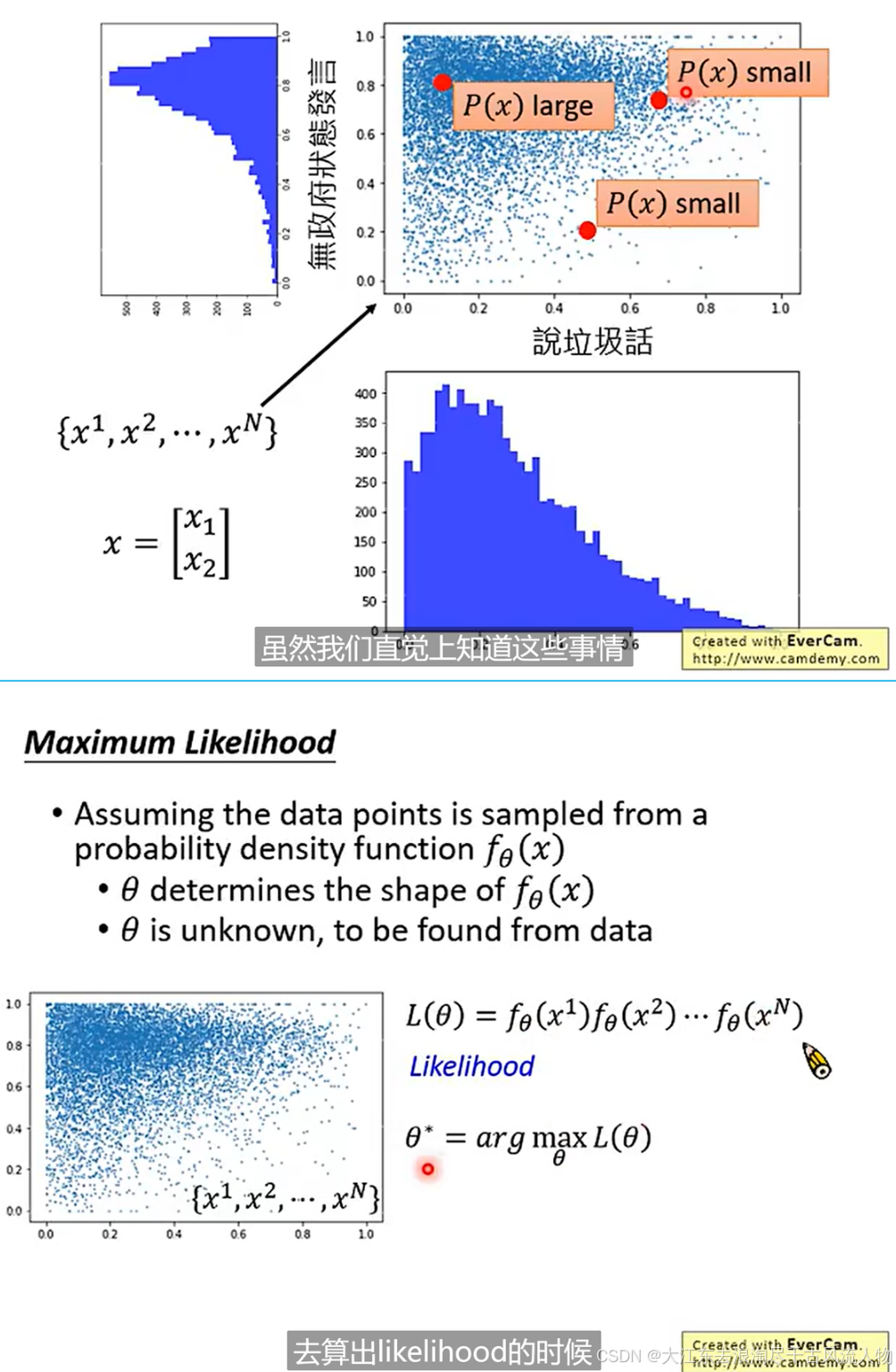
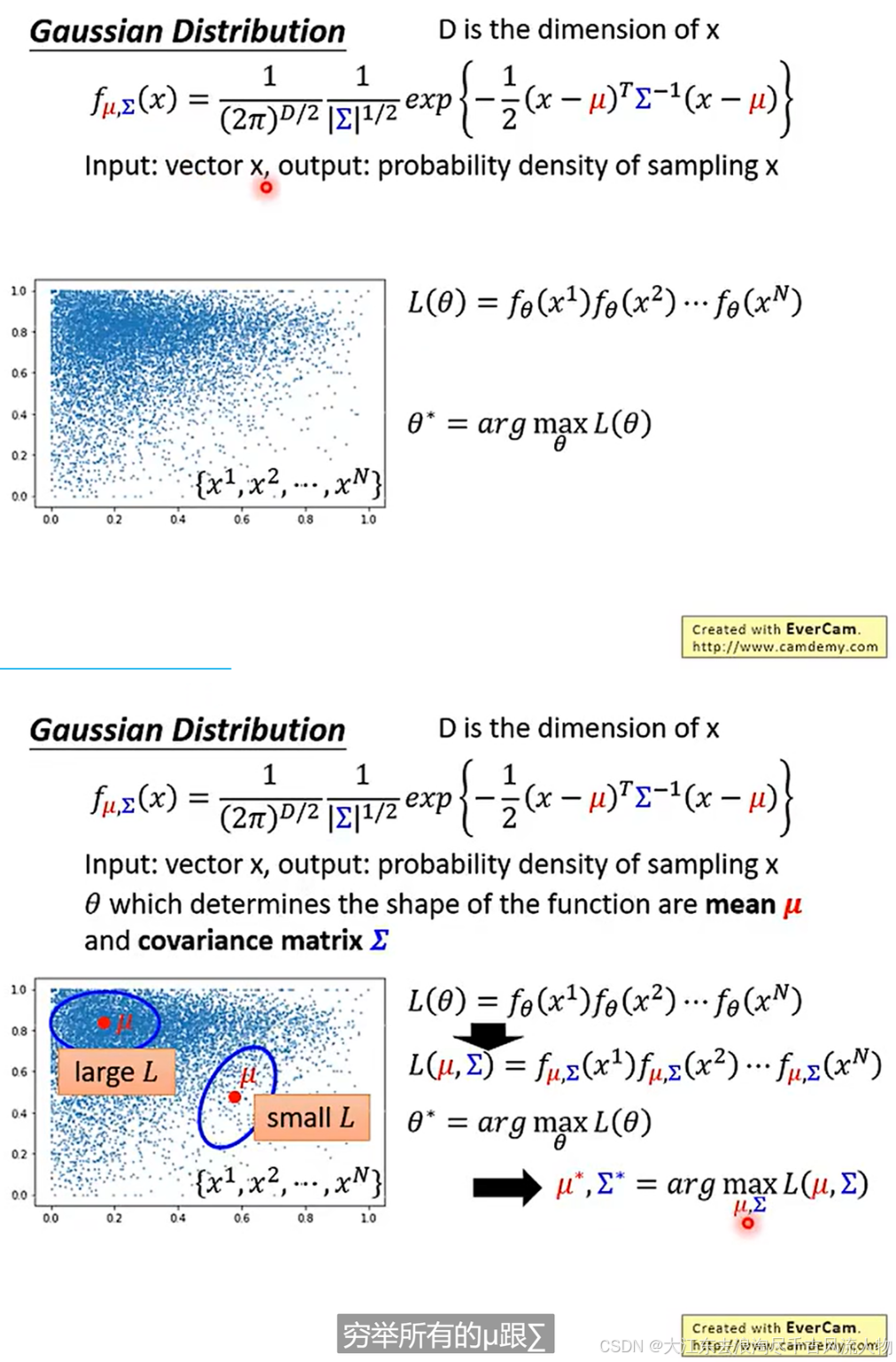
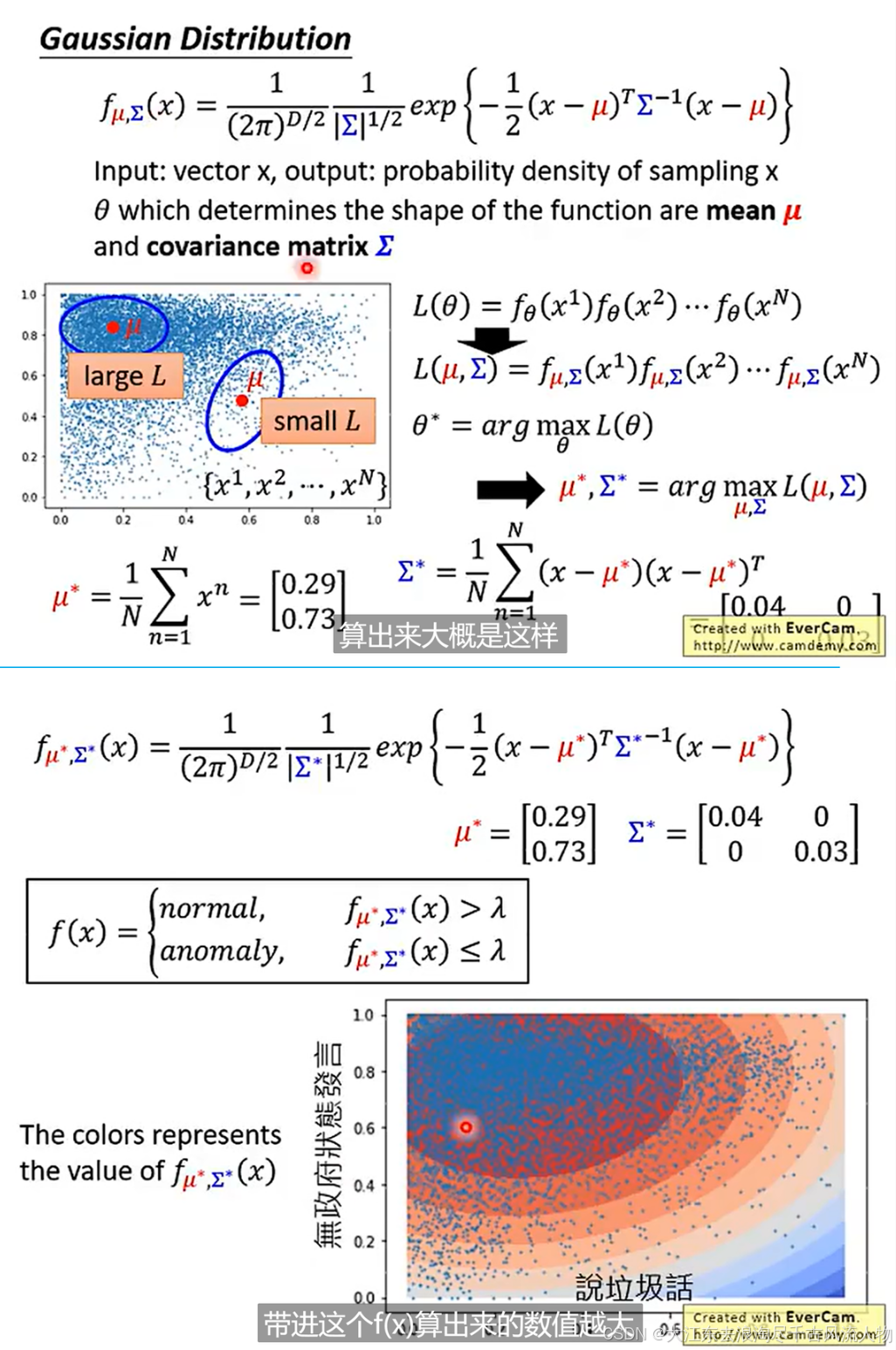

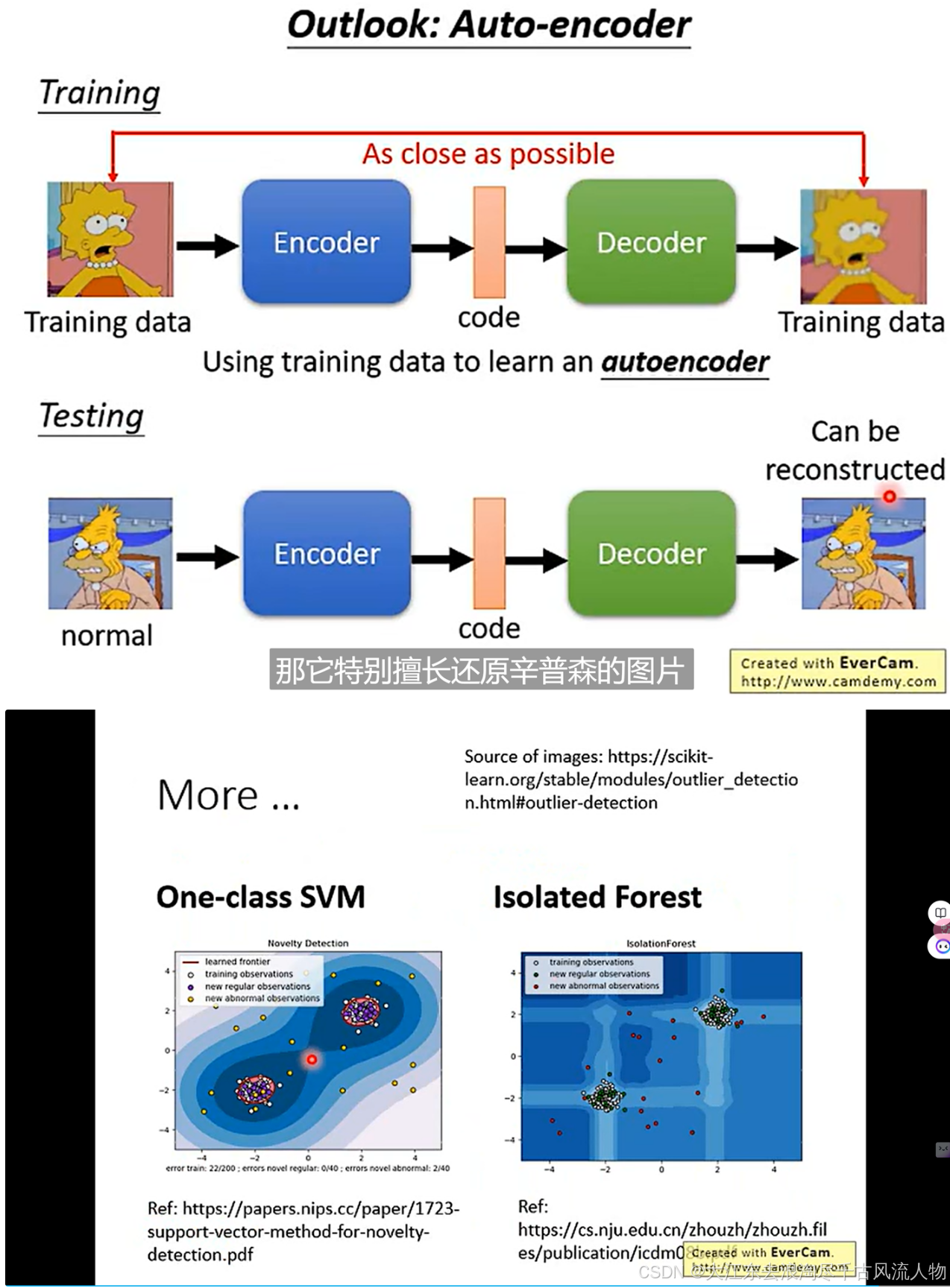
5. 基于 auto-encoder 深度模型训练、svm、随机森林 的 异常检测模型




















 5747
5747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











