







 3D-BoNet是一种新颖的框架,用于在3D点云上进行实例分割。它通过直接回归3D边界框和预测点级掩码,解决了点云无序性带来的挑战。该方法无需锚点或区域提议,避免了昂贵的后处理步骤,提高了计算效率。实验表明,3D-BoNet在ScanNet和S3DIS数据集上超越了现有工作,同时计算效率提高了约10倍。
3D-BoNet是一种新颖的框架,用于在3D点云上进行实例分割。它通过直接回归3D边界框和预测点级掩码,解决了点云无序性带来的挑战。该方法无需锚点或区域提议,避免了昂贵的后处理步骤,提高了计算效率。实验表明,3D-BoNet在ScanNet和S3DIS数据集上超越了现有工作,同时计算效率提高了约10倍。
Learning Object Bounding Boxes for 3D Instance Segmentation on Point Clouds
Abstract
- 提出了一种新颖的,概念上简单且通用的框架,用于在3D点云上进行实例分割。
- 称为3D-BoNet,遵循每点多层感知器(MLP)的简单设计原理。
- 该框架为点云中的所有实例直接回归3D边界框,同时为每个实例预测点级蒙版。
- 它由一个骨干网络和两个并行网络分支组成,用于边界框回归和点掩码预测。
- 由于与现有方法不同,它不需要任何后处理步骤,例如非最大抑制,特征采样,聚类或投票,因此它的计算效率非常高。
- 大量的实验表明,论文的方法超越了ScanNet和S3DIS数据集上的现有工作,同时其计算效率提高了约10倍。全面的消融研究证明了其设计的有效性。
(一) Introduction
- 使机器能够理解3D场景是自动驾驶,增强现实和机器人技术的基本必要条件。
- 3D几何数据(例如点云)的核心问题包括语义分割,对象检测和实例分割。
- 在这些问题中,实例分割仅在文献中才开始解决。主要的障碍是点云本质上是无序的,无结构的和不均匀的。广泛使用的卷积神经网络要求对3D点云进行体素化,从而导致高昂的计算和存储成本。
在这篇论文中,为3D实例分割提供了一种高效且新颖的框架,其中使用高效的MLP检测对象,然后通过简单的点级二进制分类器精确地分割每个实例。
- 引入了新的边界框预测模块以及一系列设计的损失函数,以直接学习物体边界。
- 框架与现有的 proposal-based and proposal-free的方法有很大不同,能够高效地分割所有具有高对象性的实例,而无需依赖昂贵且密集的object proposals。代码和数据可从https://github.com/Yang7879/3D-BoNet获得。
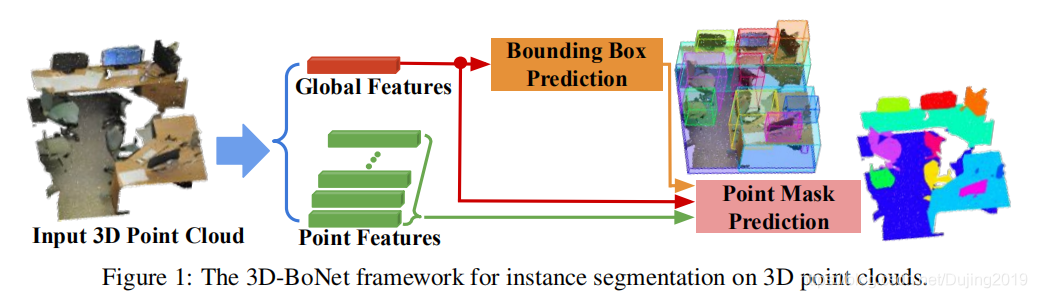
如图1所示,它首先使用现有的骨干网络为每个点提取局部特征向量,为整个输入点云提取全局特征向量。骨干后面有两个分支:实例级边界框预测,用于实例分割的点级掩码预测。
边界框预测分支是框架的核心。 该分支旨在单个前进阶段为每个实例预测一个唯一的,未定向的矩形边界框,而无需依赖预定义的空间锚点或区域提议网络。

如图2所示,认为可以大致实现一个实例的3D边界框,因为输入点云明确包含3D几何信息,而在处理点级实例分割之前这是非常有益的,因为合理的边界框可以保证学习的部分具有很高的客观性。
然而,学习实例盒涉及关键问题:
- 实例总数是可变的,即从1到很多。
- 所有实例没有固定的顺序。这些问题为正确优化网络提出了巨大挑战,因为没有信息可以直接将预测的盒子与groudtruth标签链接起来以监督网络。
但是,论文展示了如何解决这些问题:
- 该框预测分支仅将全局特征向量作为输入,并直接输出大量和固定数量的边界框以及置信度得分。这些分数用于指示该框是否包含有效实例。
- 为了监督网络,设计了一个新颖的边界框关联层,其后是一个多准则损失函数。
- 给定一组真实的实例,需要确定哪个预测框最适合它们。
- 将此关联过程公式化为现有求解器的最佳分配问题。
- 盒子被最佳地关联后,多准则损失函数不仅使配对盒子的欧几里得距离最小化,而且使预测盒子内部有效点的覆盖范围最大化。
然后将预测的框以及点和全局特征一起馈入后续的点掩码预测分支,以便为每个实例预测点级二进制掩码。
- 该分支的目的是对边界框内的每个点是属于有效实例还是属于背景进行分类。
- 假设估计的实例框相当好,则很有可能获得准确的点掩码,因为此分支只是拒绝不属于检测到的实例的点。
- 随机猜测可能会带来约50%的校正。
总体而言,论文框架在三个方面与所有现有3D实例分割方法有所不同。
- 与 the proposal-free pipeline相比,论文的方法通过显式学习3D对象边界来分割具有高对象性的实例。
- 与广泛使用的proposal-based的方法相比,论文的框架不需要昂贵且密集的proposals.。
- 框架非常有效,因为实例级掩码是通过单次转发学习的,而无需任何后处理步骤。
主要贡献:
- 提出了一个新的框架,用于在3D点云上进行实例分割。该框架是单阶段的,无需锚定并且可端到端训练,而无需任何后处理步骤。
- 设计了新颖的边界框关联层,然后设计了多准则损失函数来监督框预测分支。
- 证明了在基线之上的重大改进,并通过广泛的消融研究。
(二) 3D-BoNet
2.1 Overview

图释:
- 框架由骨干网顶部的两个分支组成。
- 给定一个总共有N个点的输入点云P,即 P ∈ R N × k 0 P∈R^{N×k_0} P∈RN×k0,其中 k 0 k_0 k0是通道数,例如每个点的位置{x,y,z}和颜色{r,g,b},骨干网络提取标记为 F l ∈ R N × k F_l∈R^{N×k } Fl∈RN×k的点局部特征,并聚合标记为 F g ∈ R 1 × k F_g∈R^{1×k } Fg∈R1×k的全局点云特征向量,其中k为特征向量的长度。
边界框预测分支仅获取全局特征向量 F g F_{g} Fg作为输入,并直接回归一组预定义和固定的边界框(表示为B)和相应的框分数(表示为 B s B_s Bs)。
使用groudtruth边界框信息来监督此分支。
- 在训练期间,将预测的边界框B和groudtruth框输入到框关联层中。
- 该层旨在将唯一且最相似的预测边界框自动关联到每个groudtruth框。
- 关联层的输出是关联索引A的列表。
- 这些索引重新组织了预测框,以使每个groudtruth框与唯一的预测框配对以进行后续损失计算。
- 在计算损失之前,也会对预测的边界框得分进行相应的重新排序。
- 然后将重新排序的预测边界框输入多准则损失函数。
损失函数的目的不仅是使每个地面真值框与关联的预测框之间的欧式距离最小,而且还要使每个预测框内的有效点的覆盖范围最大化。
边界框关联层和多准则丢失函数均仅用于网络训练。它们在测试期间被丢弃。最终,该分支能够直接为每个实例预测正确的边界框以及框分数。
为了预测每个实例的点级二进制掩码,将每个预测的框以及先前的局部和全局特征,即 F l F_l Fl和 F g F_g Fg,进一步馈送到点掩码预测分支中。该网络分支由不同类别的所有实例共享,因此非常轻巧紧凑。这种与类无关的方法本质上允许跨未被发现的类别进行常规分割。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









