








1.背景
2022年,AE Ezugwu等人受到土拨鼠觅食行为与自然行为启发,提出了土拨鼠优化算法(Prairie Dog Optimization algorithm, PDO)。
2.算法原理
2.1算法思想
PDO算法通过模拟草原土拨鼠的觅食和挖洞活动进行全局探索和局部开发,同时利用对特定警报声音的反应来调整搜索策略,从而有效地在解空间中进行勘探和开发。

2.2算法过程
探索阶段
草原土拨鼠的觅食和挖洞活动被用来探索优化问题空间。它们在丰富的食物源周围建立洞穴,当食物源耗尽后,会寻找新的食物源并在其周围建立新的洞穴,位置更新:
P
D
i
+
1
,
j
+
1
=
G
B
e
s
t
i
,
j
−
e
C
B
e
s
t
i
,
j
×
ρ
−
C
P
D
i
,
j
×
L
e
v
y
(
n
)
∀
i
t
e
r
<
M
a
x
i
t
e
r
4
(1)
\begin{aligned}PD_{i+1,j+1}=GBest_{i,j}-eCBest_{i,j}\times\rho-CPD_{i,j}\times Levy(n) \forall iter<\frac{Max_{iter}}{4}\end{aligned}\tag{1}
PDi+1,j+1=GBesti,j−eCBesti,j×ρ−CPDi,j×Levy(n)∀iter<4Maxiter(1)
P
D
i
+
1
,
j
+
1
=
G
B
e
s
t
i
,
j
×
r
P
D
×
D
S
×
L
e
v
y
(
n
)
∀
M
a
x
i
t
e
r
4
≤
i
t
e
r
<
M
a
x
i
t
e
r
2
(2)
\begin{aligned}PD_{i+1,j+1}=GBest_{i,j}\times rPD\times DS\times L\mathrm{e}vy(n) \forall \frac{Max_{iter}}{4}\leq iter<\frac{Max_{iter}}{2}\end{aligned}\tag{2}
PDi+1,j+1=GBesti,j×rPD×DS×Levy(n)∀4Maxiter≤iter<2Maxiter(2)
其中,Gbest为全局最优个体,eCBest为当前最优解,DS为挖掘强度,取决于食物来源质量:
e
C
B
e
s
t
i
,
j
=
G
B
e
s
t
i
,
j
×
Δ
+
P
D
i
,
j
×
m
e
a
n
(
P
D
n
,
m
)
G
B
e
s
t
i
,
j
×
(
U
B
j
−
L
B
j
)
+
Δ
C
P
D
i
,
j
=
G
B
e
s
t
i
,
j
−
r
P
D
i
,
j
G
B
e
s
t
i
,
j
+
Δ
D
S
=
1.5
×
r
×
(
1
−
i
t
e
r
M
a
x
i
t
e
r
)
(
2
i
t
a
r
M
a
x
i
t
e
r
)
(3)
\begin{aligned}&eCBest_{i,j}=GBest_{i,j}\times\Delta+\frac{PD_{i,j}\times mean\left(PD_{n,m}\right)}{GBest_{i,j}\times\left(UB_{j}-LB_{j}\right)+\Delta}\\&CPD_{i,j}=\frac{GBest_{i,j}-rPD_{i,j}}{GBest_{i,j}+\Delta}\\&DS=1.5\times r\times\left(1-\frac{iter}{Max_{iter}}\right)^{\left(2\frac{itar}{Max_{iter}}\right)}\end{aligned}\tag{3}
eCBesti,j=GBesti,j×Δ+GBesti,j×(UBj−LBj)+ΔPDi,j×mean(PDn,m)CPDi,j=GBesti,j+ΔGBesti,j−rPDi,jDS=1.5×r×(1−Maxiteriter)(2Maxiteritar)(3)
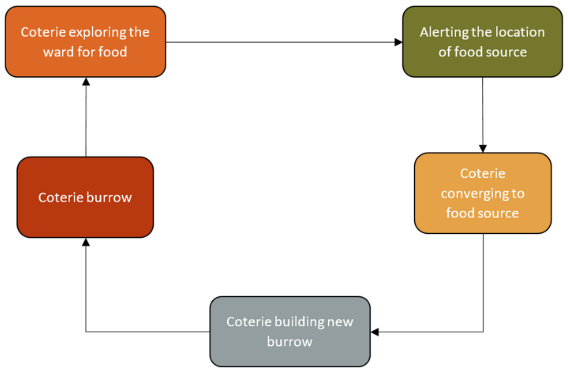
开发阶段
草原土拨鼠有不同的信号或声音,从捕食者的威胁到食物的供应。它们的沟通能力在满足草原土拨鼠的营养需求和反捕食能力方面起着重要作用:
P
D
i
+
1
,
j
+
1
=
G
B
e
s
t
i
,
j
−
e
C
B
e
s
t
i
,
j
×
ε
−
C
P
D
i
,
j
×
r
a
n
d
∀
M
a
x
i
t
e
r
2
≤
i
t
e
r
<
3
M
a
x
i
t
e
r
4
(4)
\begin{aligned}PD_{i+1,j+1}=GBest_{i,j}-eCBest_{i,j}\times\varepsilon-CPD_{i,j}\times rand \forall \frac{Max_{iter}}{2}\leq iter<3\frac{Max_{iter}}{4}\end{aligned}\tag{4}
PDi+1,j+1=GBesti,j−eCBesti,j×ε−CPDi,j×rand∀2Maxiter≤iter<34Maxiter(4)
P
D
i
+
1
,
j
+
1
=
G
B
e
s
t
i
,
j
×
P
E
×
r
a
n
d
∀
3
M
a
x
i
t
e
r
4
≤
i
t
e
r
<
M
a
x
i
t
e
r
(5)
\begin{aligned}PD_{i+1,j+1}&=GBest_{i,j}\times PE\times rand \forall 3\frac{Max_{iter}}{4}\leq iter<Max_{iter}\end{aligned}\tag{5}
PDi+1,j+1=GBesti,j×PE×rand∀34Maxiter≤iter<Maxiter(5)
其中,PE表示捕食者影响:
P
E
=
1.5
×
(
1
−
i
t
e
r
M
a
x
i
t
e
r
)
(
2
i
t
e
r
M
a
x
i
t
e
r
)
(6)
PE=1.5\times\left(1-\frac{iter}{Max_{iter}}\right)^{\left(2\frac{iter}{Max_{iter}}\right)}\tag{6}
PE=1.5×(1−Maxiteriter)(2Maxiteriter)(6)
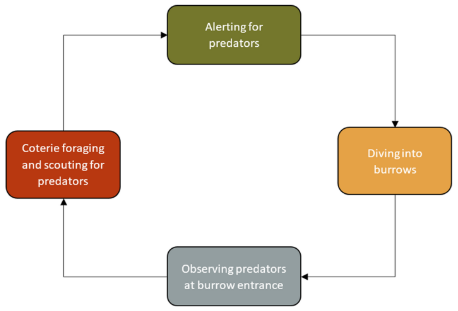
流程图
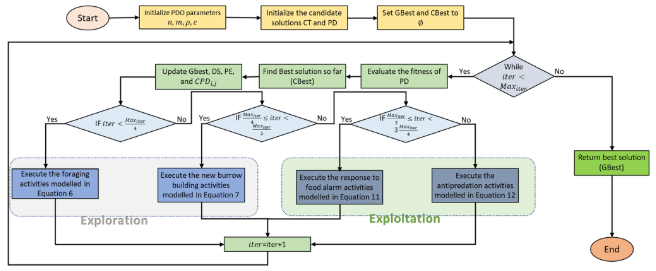
伪代码

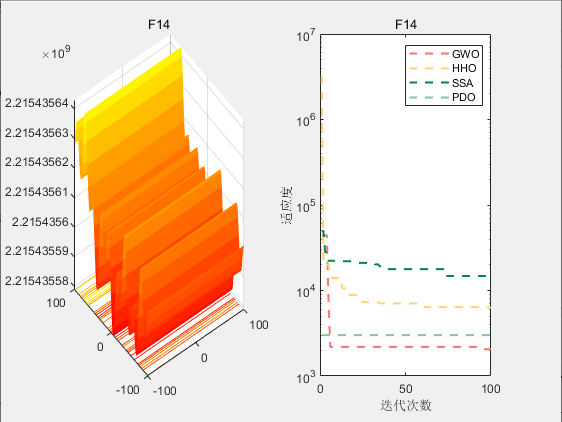
3.结果展示
使用测试框架,测试PDO性能 一键run.m
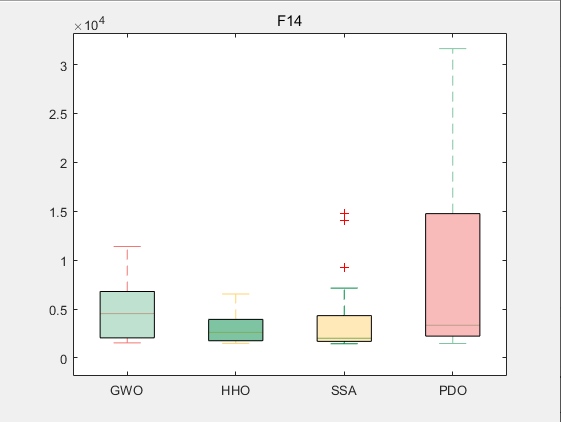
CEC2017-F14

4.参考文献
[1] Ezugwu A E, Agushaka J O, Abualigah L, et al. Prairie dog optimization algorithm[J]. Neural Computing and Applications, 2022, 34(22): 20017-20065.
















 383
383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











