







 本文介绍了受北方苍鹰捕食行为启发的NGO算法,包括其识别与攻击和追逐逃避的策略,以及如何通过代码实现。算法通过模拟苍鹰搜索空间并调整位置来优化问题。以CEC2005测试函数为例展示了其在求解优化问题的应用。
本文介绍了受北方苍鹰捕食行为启发的NGO算法,包括其识别与攻击和追逐逃避的策略,以及如何通过代码实现。算法通过模拟苍鹰搜索空间并调整位置来优化问题。以CEC2005测试函数为例展示了其在求解优化问题的应用。

1.背景
2022年,Mohammad等人受到北方苍鹰捕食自然行为影响,提出了北方苍鹰优化算法(Northern Goshawk Optimization,NGO)。
2.算法原理
2.1算法思想
北方苍鹰在捕猎过程中两个主要行为:识别和攻击以及追逐和逃避。
2.2算法过程
群体位置初始化:
x
=
l
b
+
r
a
n
d
∗
(
u
b
−
l
b
)
x=lb+rand*(ub-lb)
x=lb+rand∗(ub−lb)
其中,
u
b
,
l
b
ub,lb
ub,lb分别代表北方苍鹰上下位置边界。
识别与攻击:
识别与攻击阶段通过在搜索空间中随机选择猎物以增强算法的探索能力,旨在全局搜索搜索空间,以确定最佳区域。
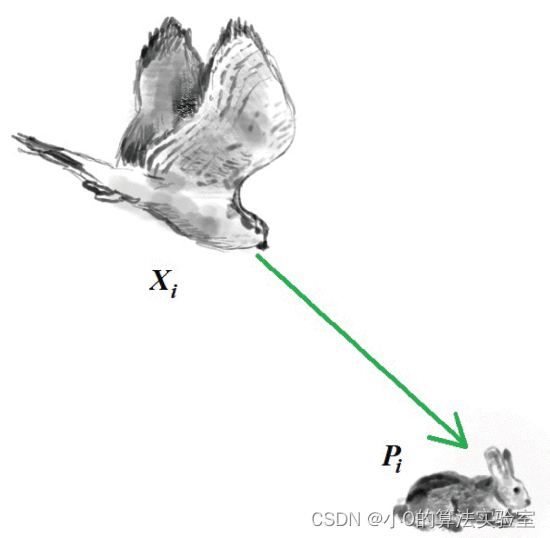
x
i
,
j
n
e
w
,
P
1
=
{
x
i
,
j
+
r
(
p
i
,
j
−
I
x
i
,
j
)
,
F
P
i
<
F
i
x
i
,
j
+
r
(
x
i
,
j
−
p
i
,
j
)
,
F
P
i
≥
F
i
x_{i,j}^{new,P1}=\begin{cases}x_{i,j}+r\left(p_{i,j}-Ix_{i,j}\right),&F_{P_i}<F_i\\x_{i,j}+r\left(x_{i,j}-p_{i,j}\right),&F_{P_i} \geq F_i\end{cases}
xi,jnew,P1={xi,j+r(pi,j−Ixi,j),xi,j+r(xi,j−pi,j),FPi<FiFPi≥Fi
其中,
r
,
I
r,I
r,I是识别与攻击阶段随机数。接下来,根据适应度是否减少判断更新位置:
X
i
=
{
X
i
n
e
w
,
P
1
,
F
i
n
e
w
,
P
1
<
F
i
X
i
,
F
i
n
e
w
,
P
1
≥
F
i
X_i=\begin{cases}X_i^{new,P1},&F_i^{new,P1}<F_i\\X_i,&F_i^{new,P1}\geq F_i\end{cases}
Xi={Xinew,P1,Xi,Finew,P1<FiFinew,P1≥Fi
追逐和逃避:
北方苍鹰对猎物发起攻击后,猎物试图逃脱。因此,在一系列追逐和逃避的过程中,北方苍鹰持续追逐猎物。由于北方苍鹰的高速机动性,它们几乎可以在任何情况下追捕猎物,并最终捕获。这种行为模拟增强了算法对搜索空间中局部搜索的利用能力,这种捕猎行为与半径
R
R
R内的攻击位置密切相关。
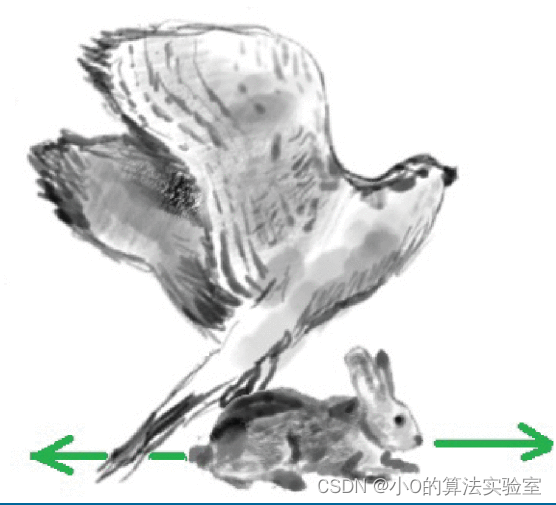
x
i
,
j
n
e
w
,
P
2
=
x
i
,
j
+
R
(
2
r
−
1
)
x
i
,
j
R
=
0.02
(
1
−
t
T
)
X
i
=
{
X
i
n
e
w
,
P
2
,
F
i
n
e
w
,
P
2
<
F
i
X
i
,
F
i
n
e
w
,
P
2
≥
F
i
x_{i,j}^{new,P2}=x_{i,j}+R(2r-1)x_{i,j} \\ R=0.02\left(1-\frac tT\right) \\ X_i=\begin{cases}X_i^{new,P2},&F_i^{new,P2}<F_i\\X_i,&F_i^{new,P2}\geq F_i\end{cases}
xi,jnew,P2=xi,j+R(2r−1)xi,jR=0.02(1−Tt)Xi={Xinew,P2,Xi,Finew,P2<FiFinew,P2≥Fi
这里,半径
R
R
R随着迭代次数
t
t
t增加从而逐渐减小,使得算法不断迭代直到收敛。
伪代码:

3.代码实现
% 北方苍鹰优化算法
function [Best_pos, Best_fitness, Iter_curve, History_pos, History_best] = NGO(pop, maxIter, lb, ub, dim,fobj)
%input
%pop 种群数量
%dim 问题维数
%ub 变量上边界
%lb 变量下边界
%fobj 适应度函数
%maxIter 最大迭代次数
%output
%Best_pos 最优位置
%Best_fitness 最优适应度值
%Iter_curve 每代最优适应度值
%History_pos 每代种群位置
%History_best 每代最优个体位置
%% 记录
X_new=[];
fit=[];
fit_new=[];
Iter_curve=zeros(1,maxIter);
%% 初始化种群
X = zeros(pop, dim);
for i = 1:pop
for j = 1:dim
X(i,j) = (ub(j) - lb(j)) * rand() + lb(j);
end
end
%% 计算适应度
for i =1:pop
L=X(i,:);
fit(i)=fobj(L);
end
%% 迭代
for t=1:maxIter
[best , blocation]=min(fit);
if t==1
xbest=X(blocation,:);
fbest=best;
elseif best<fbest
fbest=best;
xbest=X(blocation,:);
end
for i=1:pop
%% 识别与攻击
I=round(1+rand);
k=randperm(pop,1);
P=X(k,:); % Eq. (3)
F_P=fit(k);
if fit(i)> F_P
X_new(i,:)=X(i,:)+rand(1,dim) .* (P-I.*X(i,:)); % Eq. (4)
else
X_new(i,:)=X(i,:)+rand(1,dim) .* (X(i,:)-P); % Eq. (4)
end
% 边界约束
X_new(i,:) = max(X_new(i,:),lb);
X_new(i,:) = min(X_new(i,:),ub);
% Eq (5)
L=X_new(i,:);
fit_new(i)=fobj(L);
if(fit_new(i)<fit(i))
X(i,:) = X_new(i,:);
fit(i) = fit_new(i);
end
% 追逐和逃避
R=0.02*(1-t/maxIter);% Eq.(6)
X_new(i,:)= X(i,:)+ (-R+2*R*rand(1,dim)).*X(i,:);% Eq.(7)
X_new(i,:) = max(X_new(i,:),lb);X_new(i,:) = min(X_new(i,:),ub);
% update position based on Eq (8)
L=X_new(i,:);
fit_new(i)=fobj(L);
if(fit_new(i)<fit(i))
X(i,:) = X_new(i,:);
fit(i) = fit_new(i);
end
end
best_so_far(t)=fbest;
average(t) = mean (fit);
Best_fitness=fbest;
Best_pos=xbest;
Iter_curve(t)=Best_fitness;
History_pos{t} = X;
History_best{t} = Best_pos;
end
end
优化问题
以CEC2005测试函数为例
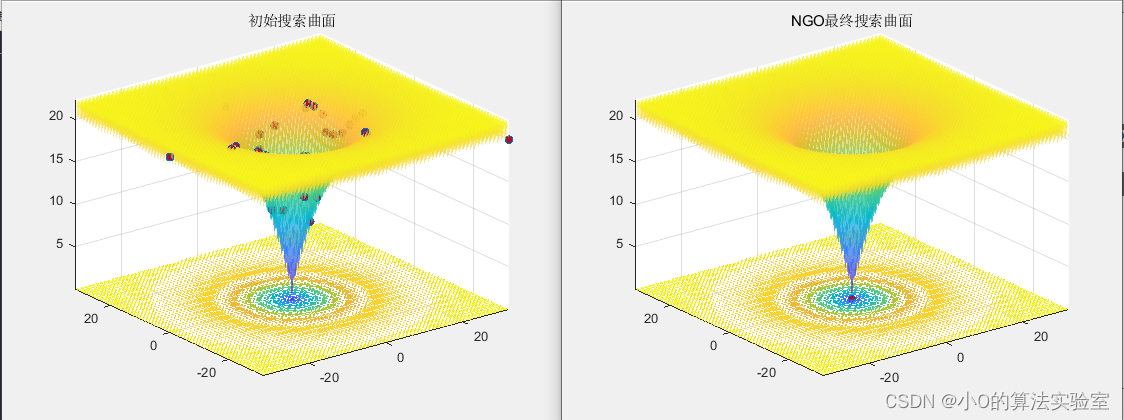
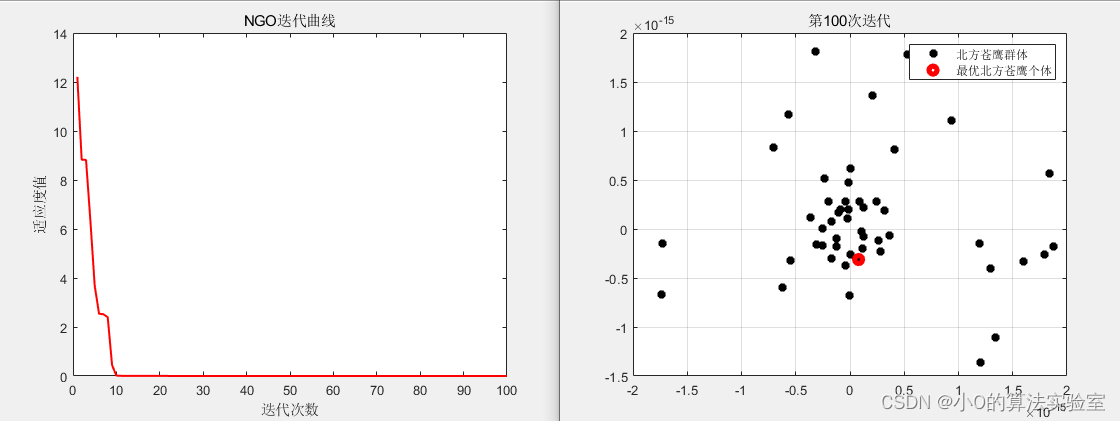
4.参考文献
[1] Dehghani M, Hubálovský Š, Trojovský P. Northern goshawk optimization: a new swarm-based algorithm for solving optimization problems[J]. Ieee Access, 2021, 9: 162059-162080.


















 1058
1058

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











