






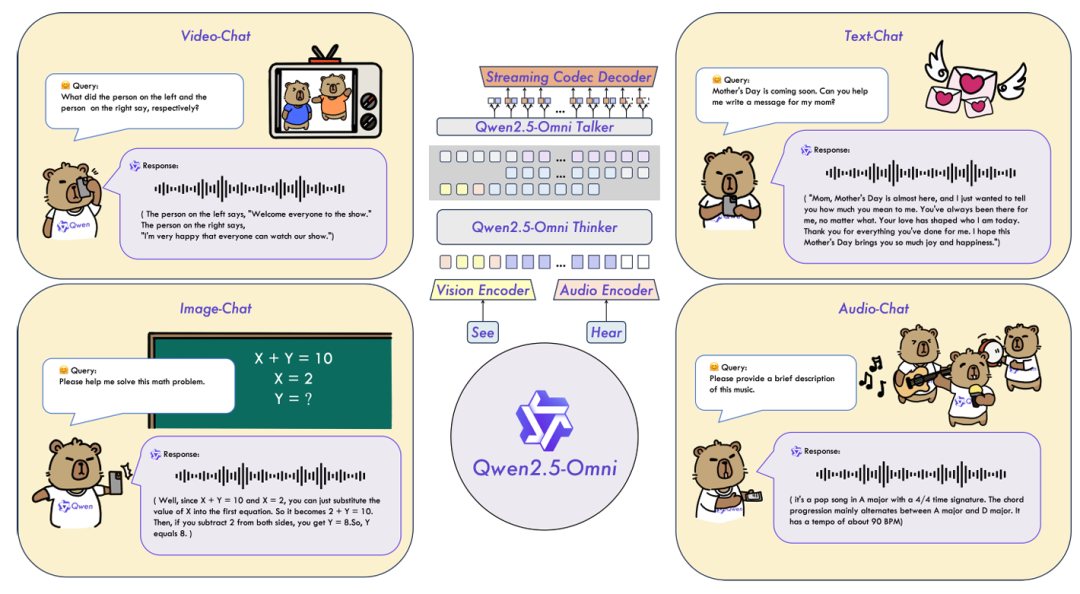
3月27日凌晨,阿里通义千问团队发布了其最新的技术成果——Qwen2.5-Omni,这是一个跨越音频、视频、图像和文本的全模态大模型。Qwen2.5-Omni不仅能够无缝地处理多模态输入,还能实时生成文本和自然语音响应,展现出前所未有的多模态理解和生成能力。作为Qwen系列的旗舰级产品,Qwen2.5-Omni集成了最先进的技术和创新架构,是人工智能领域的一项突破性进展。

模型亮点
创新架构:Thinker-Talker 双核设计
Qwen2.5-Omni 的核心架构是创新性的Thinker-Talker设计。Thinker模块如同大脑,负责理解并处理来自文本、图像、音频和视频等模态的信息,生成高级语义表示和对应文本。Talker模块则类似人类的发声器官,接收Thinker的输出,将其转化为流畅的语音Token并生成语音响应。
这种分工协作的架构使得Qwen2.5-Omni能够在多个任务中表现出色,从复杂的音视频推理到实时的语音交互都能高效完成。整个模型的训练和推理过程是端到端的,这意味着各个模块可以共享上下文信息,确保不同模态之间的高度协调。
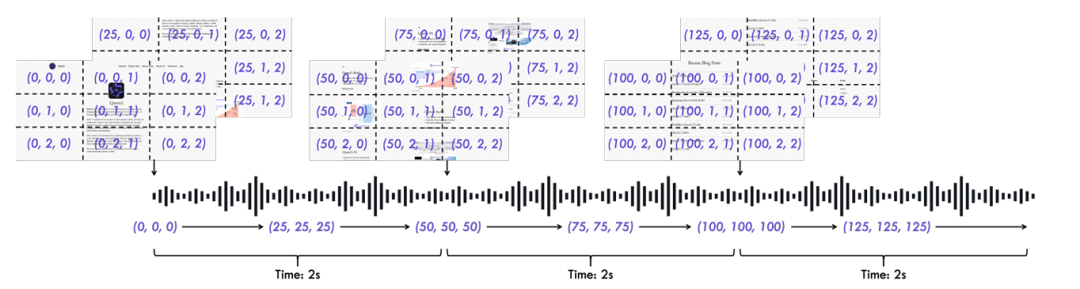
TMRoPE位置编码:精确同步视频与音频
为了精确同步视频和音频输入,Qwen2.5-Omni提出了TMRoPE(Time-aligned Multimodal RoPE)这一创新的位置编码方法。该方法通过对音频和视频的时间轴进行精确对齐,确保不同模态的信息能够有效融合。TMRoPE通过多维位置编码,增强了模型对时间相关性的建模能力,使得视频和音频的结合更加精准。
这一创新设计解决了多模态模型面临的时间同步问题,大大提升了模型对复杂场景的理解和生成能力,尤其是在涉及实时交互的任务中,Qwen2.5-Omni能够实现更自然流畅的表现。
流式编解码器生成
为了便于音频流式传输,特别是对于较长的序列,Qwen2.5-Omni提出了一种滑动窗口块注意力机制,限制当前标记对有限上下文的访问。具体来说,使用Flow-Matching(Lipman等)DiT模型。
输入代码通过Flow-Matching转换为梅尔频谱图,然后通过修改后的BigVGAN(Lee等)将生成的梅尔频谱图重新构造成波形。

卓越性能:Qwen2.5-Omni的强大能力
Qwen2.5-Omni的卓越性能是其最大的亮点之一。无论是在单模态还是多模态任务中,该模型都展现了超越同类的表现,尤其在多模态融合和实时语音生成领域,Qwen2.5-Omni更是取得了显著的突破。
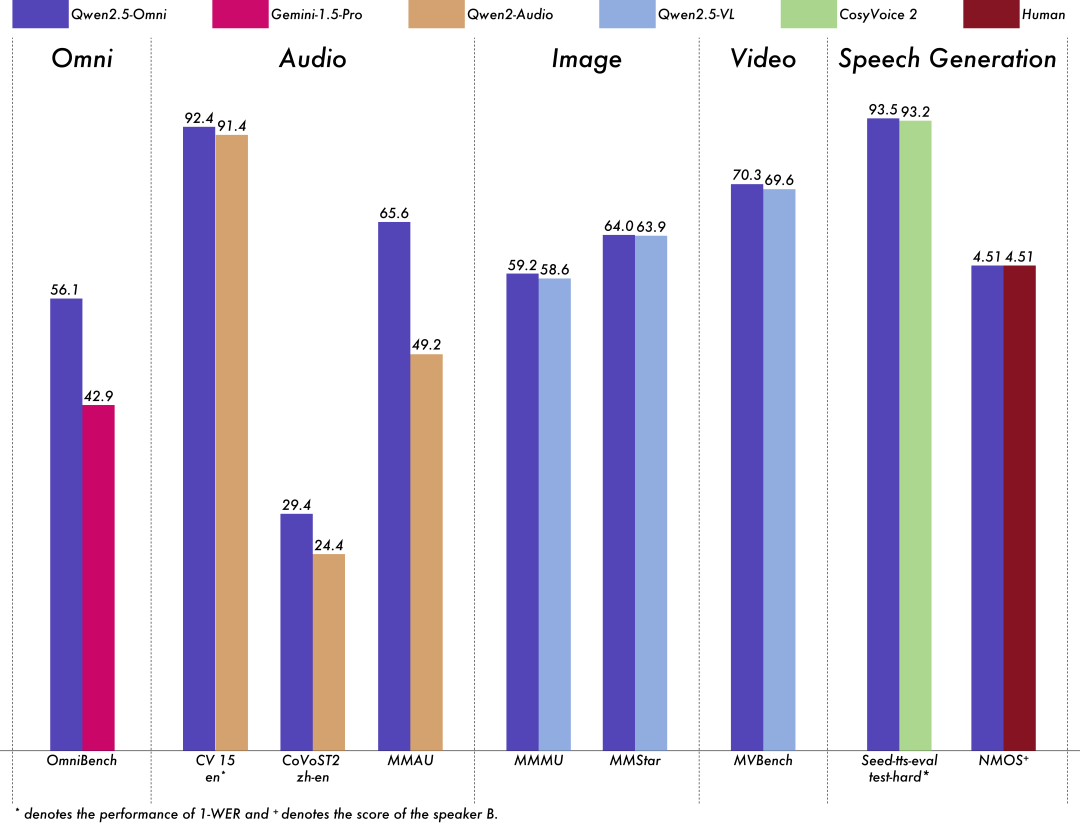
1. 多模态基准测试中的领先表现
在多模态任务的OmniBench等基准测试中,Qwen2.5-Omni表现出色,达到SOTA(state-of-the-art,最先进)的水平。该模型在音频、视频、图像等多个领域的理解能力远超同规模的单模态模型,并且在多模态任务中也具有无与伦比的优势。
2. 语音指令跟随能力:与文本输入相媲美
Qwen2.5-Omni在端到端语音指令跟随方面的能力表现也非常突出。与传统的语音识别系统不同,Qwen2.5-Omni不仅能够精准识别语音指令,还能理解复杂的上下文信息并作出回应。这种能力在MMLU(通用知识理解)和GSM8K(数学推理)等基准测试中得到了验证,其表现与基于文本输入的模型相当,甚至超越了其他同类模型。
3. 语音生成的自然性和稳定性
Qwen2.5-Omni在语音生成方面的表现也相当卓越。在实时流式语音生成任务中,Qwen2.5-Omni不仅能够流畅地生成自然语音,还在鲁棒性和稳定性上超越了现有的许多流式和非流式替代方案。通过独特的双轨自回归模型和优化的滑动窗口机制,Qwen2.5-Omni实现了低延迟的音频生成,能够快速响应用户指令。
4. 图像和视频理解的出色能力
Qwen2.5-Omni在图像和视频理解方面的能力也表现得相当出色。在与Qwen2.5-VL和其他视觉语言模型的对比中,Qwen2.5-Omni在多个视觉任务(如MMMU、MathVision、MMStar等)中均表现优异,尤其在处理复杂的图像和视频推理时,Qwen2.5-Omni展现出了出色的多模态融合能力。它能够理解视频中的动态内容,并在语音或文本响应中进行准确的推理。
5. 高效的音频理解和推理能力
在音频理解方面,Qwen2.5-Omni表现出了超越现有技术的强大能力。通过在音频-文本对齐、语音到文本翻译(S2TT)、语音实体识别(SER)等任务上的优化,Qwen2.5-Omni能够高效地处理多样化的音频输入。特别是在MMAU等音频推理基准测试中,Qwen2.5-Omni展现了最先进的性能,成为了音频理解领域的领军者。
下载链接
OpenCSG社区:https://opencsg.com/models/Qwen/Qwen2.5-Omni-7B
HF社区:https://huggingface.co/Qwen/Qwen2.5-Omni-7B

















 278
278

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









