







Deep Incomplete Multi-View Clustering via Mining Cluster Complementarity
原文链接
以往的IMVC方法存在以下问题:(1)缺失数据的不准确输入或填充会影响聚类性能;(2)低质量视图,特别是输入视图不准确会影响融合后的特征质量。
为了避免这些问题,本工作提出了一个无输入和无融合的深度IMVC框架。
首先,该方法为每个视图分别建立深度嵌入特征学习和聚类模型;然后,本文的方法将完整数据的嵌入特征非线性映射到高维空间中,以发现线性可分性。具体来说,本文给出了一种高维映射的实现方法,并给出了挖掘多视图集群互补性的机制。然后将该互补信息转换为高置信度的监督信息,以实现完整数据和不完整数据的多视图聚类一致性。此外,设计了一种类似EM的优化策略来交替促进特征学习和聚类。
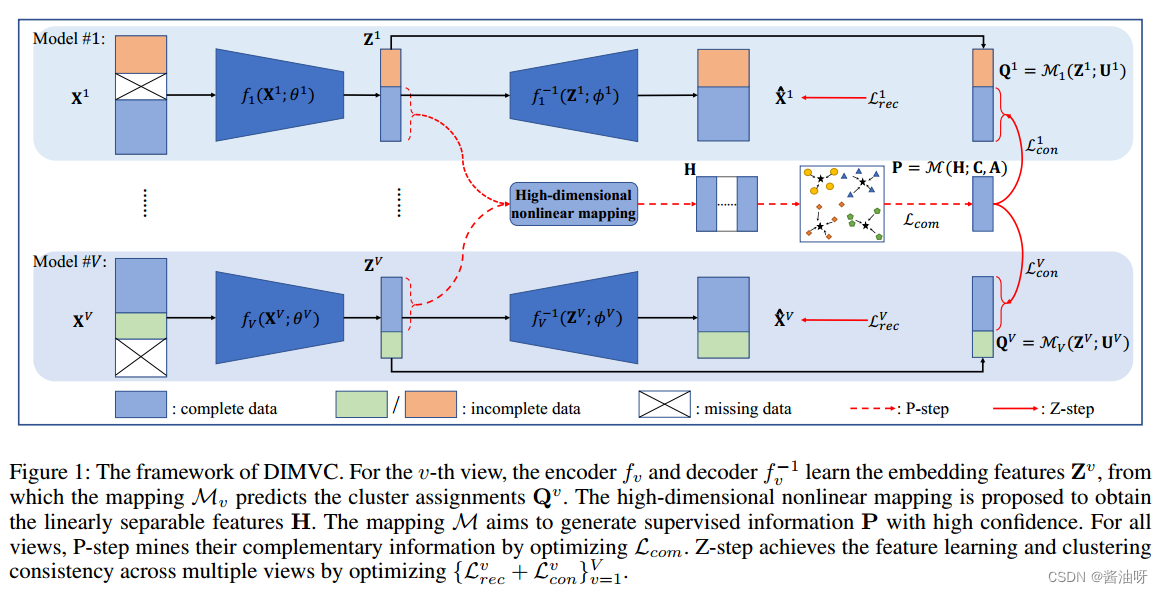
Fig1:DIMVC的框架。对于第v视图,编码器和解码器学习嵌入特征zv,映射Mv从中预测聚类分配Qv。提出了高维非线性映射来获得线性可分特征h,映射M旨在生成高置信度的监督信息P。对于所有视图,P-step通过优化Lcom来挖掘它们的互补信息。z步通过优化{Lv rec + Lv con} v v=1来实现跨多个视图的特征学习和聚类一致性
更具体地说,在每个视图的所有观测数据上构建一个单独的模型。每个模型由一个自动编码器和一个聚类映射组成。跨多个视图的互补信息可以用非线性映射来描述,通过高维映射来解决挑战(i)。具体而言,将完整的多视图数据的嵌入特征非线性投影到一个串联的加权特征空间中,其中高可分性视图被赋予高权重。直观地说,高可分离性视图意味着特征中存在分离良好的簇结构。此外,还证明了线性可分的聚类信息可以转换为高维特征,称为多视图聚类互补。然后将这些互补的聚类信息转换为高置信度的监督信息,旨在对所有视图进行一致的聚类分配,即解决挑战(ii)。此外,提出了一种类似EM的优化策略,包括p步和z步,交替促进特征学习和聚类。
方法
特征学习与聚类的深度模型
每个视图的特征学习和聚类模型,即图1中的模型#1、#2、::::、#V。
所有视图的Xv和X^ v之间的重构损失为:
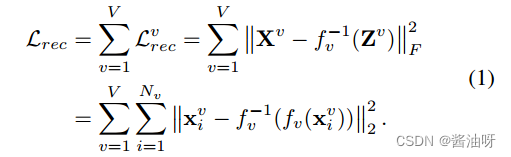
为了获得聚类预测,对于每个视图,利用参数化映射来获得软聚类分配Qv:
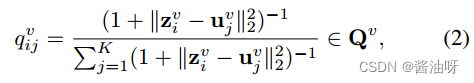
在这个过程中,是对单个试图进行编码和聚类,未体现出缺失视图的问题,这个过程是无输入学习的过程,在接下来过程中来挖掘视图见的互补信息。
多视图集群互补性
由于多个视图共享共同的语义信息,因此每个视图都可以看作是其他视图的映射。
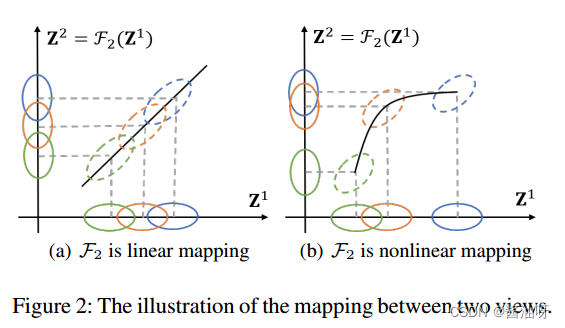
如图2(a)所示,如果一个视图是其他视图的线性映射,则它们之间没有互补信息。
如果多个视图之间存在互补关系,例如,一个视图中不可分割的簇在其他视图中是可分离的,这种互补性可以用非线性映射来描述**,如图2(b)所示。
基于上述观察结果,将聚类分配作为样本的伪标签,将聚类问题视为分类问题。
假设1。Cover定理(Cover 1965):当一个复杂的分类问题被非线性地投射到高维空间时,它更有可能是线性可分的。
基于假设1,通过非线性映射h将多视图嵌入映射到高维空间,将嵌入映射到一个串联加权特征空间(CWFS):
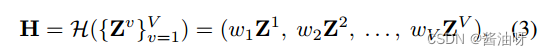
H是获得的高维特征,Wv是权重计算如下。
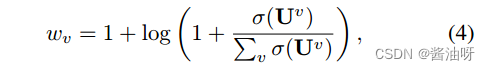
簇质心{U1;U2;:::;UV}可以通过K-means初始化。σ(Uv)是第v个视图的聚类质心Uv的方差
定理1:H是{zv} v v=1的高维非线性映射。对于v∈{1,2;:::;V},高维特征H比任何Zv更可能是线性可分的。
通过以下目标函数来探索互补聚类信息:
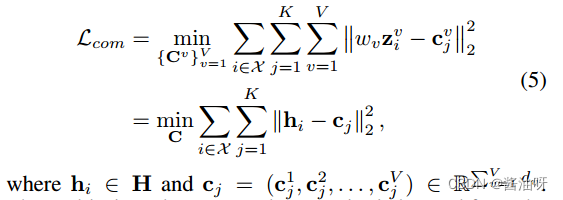
多视图聚类互补性是从完整数据X中学习的。
多视图聚类一致性
将高维特征映射为P:
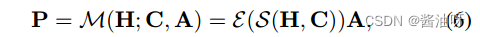
用函数S测量第i个样本分配给第j个质心的置信度sij:
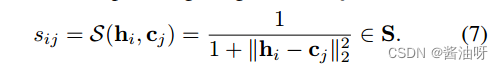
函数E(S)将每个样本的置信度缩放为[0,1],同时增强最大时的置信度:
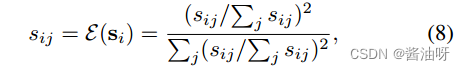
A满足AAT = IK, AAT = IK是一个布尔矩阵,用于调整s的排列。
所有视图的P与Qv之间的交叉熵损失:
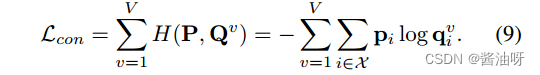
对观测数据的聚类分配进行平均,得到鲁棒性结果。具体来说,第i个样本的聚类预测为:
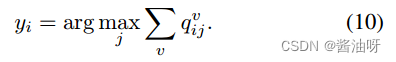
损失函数
提出的框架的损失函数由三部分组成:
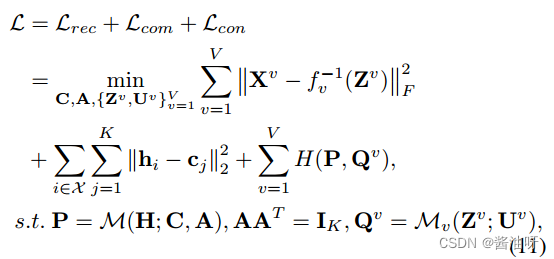
本文提出了一种无输入、无融合的深度不完全多视图聚类框架。首先,提出了一种挖掘多视图间互补信息的新策略,即将所有视图的嵌入特征映射到连接加权特征空间(CWFS)中。因此,由于多视图集群的互补性,CWFS中的新特性更有可能是线性可分的。在此基础上,采用一种替代(EM-like)优化策略进行特征学习和聚类,将互补信息转化为监督信息,实现多视图的一致性。综上所述,方法可以有效地从完整数据中挖掘出多视图互补信息,并且对不完整数据具有鲁棒的泛化能力。大量的实验表明,本文的方法可以达到最先进的聚类性能。

















 1057
1057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









