







混合高斯模型的例子
混合高斯模型
混合高斯模型(Mixture of Gaussians,简称GMM)是一种概率模型,用于对复杂的数据分布进行建模。它是由多个高斯分布组合而成的混合模型,每个高斯分布(称为组件)对应数据的一个子群体。混合高斯模型的概率密度函数可以表示为多个高斯分布的线性组合,即每个分布乘以一个相应的权重。数学形式如下:
P ( x ) = ∑ i = 1 K π i ⋅ N ( x ∣ μ i , Σ i ) P(x) = \sum_{i=1}^{K} \pi_i \cdot \mathcal{N}(x | \mu_i, \Sigma_i) P(x)=i=1∑Kπi⋅N(x∣μi,Σi)
其中,K是高斯分布的数量, π i \pi_i πi是对应于第 i 个高斯分布的权重, N ( x ∣ μ i , Σ i ) \mathcal{N}(x | \mu_i, \Sigma_i) N(x∣μi,Σi) 是第i个高斯分布的概率密度函数,由均值 μ i \mu_i μi和协方差矩阵 Σ i \Sigma_i Σi参数化。
问题
假设有一堆数据 X = { x 1 , … , x N } X=\{x_1,…,x_N\} X={x1,…,xN},并且假设其采样自一个高斯混合分布,那么如何判断该高斯混合分布中的K值为多少?
最大似然估计(Maximum Likelihood Estimation,MLE) 一种解法是采用最大似然估计,将K作为分布的参数,选择使得观测数据出现的概率最大的参数值。最大似然估计的步骤如下:
-
建立似然函数: 根据模型和观测数据建立似然函数。
-
对似然函数取对数: 为了方便计算,通常对似然函数取自然对数。
-
求导数并令其为零: 对取对数后的似然函数关于参数进行求导,并令导数为零,解得似然方程。
-
求解似然方程: 解似然方程得到参数的估计值。
-
检验估计的合理性: 通过检验估计的标准误差、置信区间等来评估估计的精确性和可靠性。

但是这种方法会得到平凡解 K = N K=N K=N,均值为数据的值,方差为0。

思考
如果
K
=
N
K=N
K=N,那么聚类就没有意义了,假设
K
=
f
(
N
)
K=f(N)
K=f(N),那么函数f应该是什么形式?
答:
K
∝
l
o
g
(
N
)
K \propto log(N)
K∝log(N),N增加K也增加,但是K增加的度远小于N。
另一个例子
假设有一堆数据
X
=
{
x
1
,
…
,
x
N
}
X=\{x_1,…,x_N\}
X={x1,…,xN},并且假设每个数据都对应一个参数为
θ
i
\theta _i
θi的分布并由其产生。
θ
i
\theta_i
θi 也是从某个分布生成的
θ
i
∼
H
(
θ
)
\theta_i \sim H(\theta)
θi∼H(θ)。如果H是连续的,那么会有以下的情况出现(红线标注处,如果
θ
1
,
θ
2
\theta_1,\theta_2
θ1,θ2采用自一个连续的分布,那么二者相等的概率为0,那么所有的几个
θ
\theta
θ值都不相等,K还是等于N,所以H是非连续分布。

假设
θ
\theta
θ从G中产生,
θ
i
∼
G
\theta _i\sim G
θi∼G,但是G和H是有联系的,
G
∼
D
P
(
α
,
H
)
\color{red} G\sim DP(\alpha,H)
G∼DP(α,H),其中
α
\alpha
α是一个程度标量,描述G的离散程度,
α
\alpha
α越小G越离散,
α
\alpha
α越大,G越连续。
α
=
0
\alpha=0
α=0时G只有一个点,
α
=
∞
\alpha=\infty
α=∞时
G
=
H
G=H
G=H。


狄利克雷过程
从 G ∼ D P ( α , H ) \color{red} G\sim DP(\alpha,H) G∼DP(α,H)中每次采样得到的都是一个分布,但是这些分布是有某种特性的。

迪利克雷分布DIR
G的划分性质 假设将分布的定义域进行划分,划分成d个区域,在第i个区域 a i a_i ai,G在 a i a_i ai上权重的总和 G ( a i ) G(a_i) G(ai)有如下性质(红线部分):
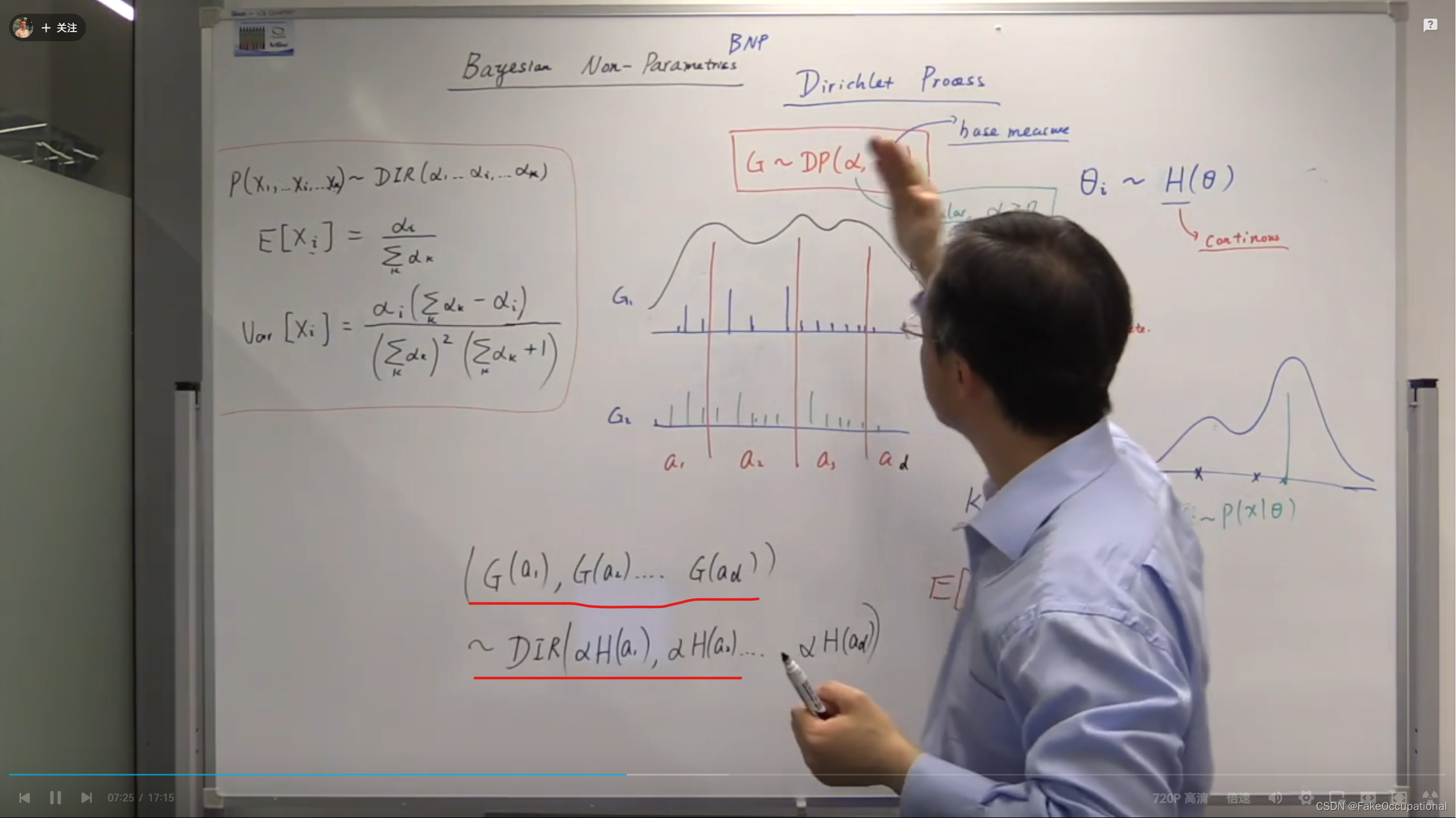
其中DIR为狄利克雷分布(Dirichlet distribution,红框中为DIR分布的特性):
f ( x ; α ) = 1 B ( α ) ∏ i = 1 K x i α i − 1 f(\mathbf{x};\boldsymbol{\alpha}) = \frac{1}{B(\boldsymbol{\alpha})} \prod_{i=1}^{K} x_i^{\alpha_i - 1} f(x;α)=B(α)1i=1∏Kxiαi−1
其中:
- x = ( x 1 , x 2 , … , x K ) \mathbf{x} = (x_1, x_2, \ldots, x_K) x=(x1,x2,…,xK) 是一个K维随机变量,满足 0 ≤ x i ≤ 1 0 \leq x_i \leq 1 0≤xi≤1 和 ∑ i = 1 K x i = 1 \sum_{i=1}^{K} x_i = 1 ∑i=1Kxi=1。
- α = ( α 1 , α 2 , … , α K ) \boldsymbol{\alpha} = (\alpha_1, \alpha_2, \ldots, \alpha_K) α=(α1,α2,…,αK) 是分布的参数,其中每个 α i > 0 \alpha_i > 0 αi>0。狄利克雷分布的参数 α \boldsymbol{\alpha} α 可以影响分布的形状。当所有的 α i \alpha_i αi 都相等时,分布是均匀的;当某些 α i \alpha_i αi大于1而其他的小于1时,分布会偏向于在对应的维度上取较大的值。
- B ( α ) B(\boldsymbol{\alpha}) B(α) 是多元Beta函数,定义为 B ( α ) = ∏ i = 1 K Γ ( α i ) Γ ( ∑ i = 1 K α i ) B(\boldsymbol{\alpha}) = \frac{\prod_{i=1}^{K} \Gamma(\alpha_i)}{\Gamma(\sum_{i=1}^{K} \alpha_i)} B(α)=Γ(∑i=1Kαi)∏i=1KΓ(αi),其中 Γ \Gamma Γ 是伽玛函数。

因为G在划分上服从迪利克雷分布,又因为红框中的性质:
E [ G ( a i ) ] = α H ( a i ) ∑ k α H ( a k ) = α H ( a i ) α ∑ k H ( a k ) = α H ( a i ) α ⋅ 1 = H ( a i ) E[G(a_i)]=\frac{\alpha H(a_i)}{\sum_k \alpha H(a_k)} = \frac{\alpha H(a_i)}{ \alpha \sum_kH(a_k)} = \frac{\alpha H(a_i)}{ \alpha \cdot 1} = H(a_i) E[G(ai)]=∑kαH(ak)αH(ai)=α∑kH(ak)αH(ai)=α⋅1αH(ai)=H(ai)
V a r [ G ( a i ) ] = H ( a i ) ( 1 − H ( a i ) ) α + 1 Var[G(a_i)]=\frac{H(a_i)(1-H(a_i))}{\alpha+1} Var[G(ai)]=α+1H(ai)(1−H(ai))
-
α → ∞ , V a r [ G ( a i ) ] = 0 \alpha\rightarrow \infty ,Var[G(a_i)]=0 α→∞,Var[G(ai)]=0
-
α → 0 , V a r [ G ( a i ) ] = H ( a i ) ( 1 − H ( a i ) ) , 二 项 分 布 \alpha\rightarrow 0, Var[G(a_i)]={H(a_i)(1-H(a_i))},二项分布 α→0,Var[G(ai)]=H(ai)(1−H(ai)),二项分布
G的折棍构造 stick-breaking constructin
如何从分布中采样G?G长什么样? G = ∑ i = 0 ∞ π i δ θ i G=\sum_{i=0}^{\infty}\pi_i\delta\theta_i G=∑i=0∞πiδθi
- 采样第一个点


- 采样第二个点, ( 1 − π 1 ) (1-\pi_1) (1−π1)为第一次采样后剩下的,者剩下的
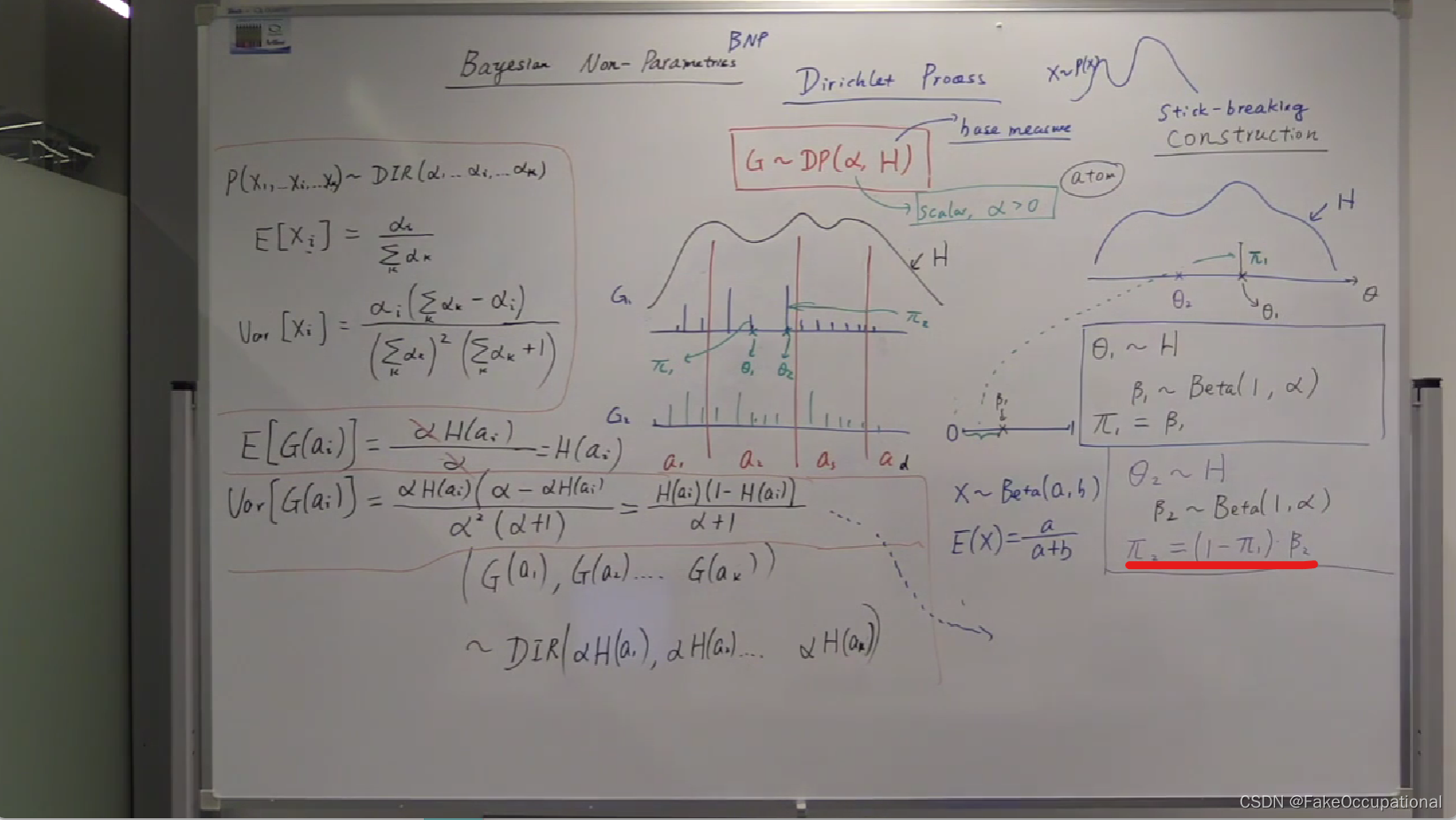
在采样完所有这些点之后就得到一个G的visualization。因为 β i ∼ B e t a ( 1 , α ) , 所 以 E [ β i ] = 1 1 + α \beta_i\sim Beta(1,\alpha),所以E[\beta_i]=\frac{1}{1+\alpha} βi∼Beta(1,α),所以E[βi]=1+α1。当 α = 0 , E [ β i ] = 1 \alpha=0,E[\beta_i]=1 α=0,E[βi]=1。当 α = ∞ , E [ β i ] = 0 \alpha=\infty,E[\beta_i]=0 α=∞,E[βi]=0,即产生了0各权重给每个 θ \theta θ用。
小结



G的后验
假设已经知道了了
θ
1
,
θ
2
,
…
…
,
θ
N
\theta_1,\theta_2,……,\theta_N
θ1,θ2,……,θN。
P
(
G
∣
θ
1
,
θ
2
,
…
…
,
θ
N
)
=
P
(
θ
1
,
θ
2
,
…
…
,
θ
N
∣
G
)
×
P
(
G
)
=
G
×
P
(
G
)
P(G|\theta_1,\theta_2,……,\theta_N) = P(\theta_1,\theta_2,……,\theta_N|G)\times P(G) = G\times P(G)
P(G∣θ1,θ2,……,θN)=P(θ1,θ2,……,θN∣G)×P(G)=G×P(G)
和多项式分布的关系
如果将狄利克雷分布的参数α 视为多项式分布中的概率参数p 的先验分布,那么在贝叶斯统计学中,给定观测数据,通过贝叶斯公式可以更新参数的后验分布。这个后验分布将是一个狄利克雷分布。这表明狄利克雷分布是多项式分布的共轭先验。
多项式分布
多项式分布(Multinomial Distribution)是概率论和统计学中的一种离散概率分布,它是二项分布的推广。在多项式分布中,试验的结果有两个以上的分类,每个分类有一个概率,且这些概率之和为1。与二项分布不同,多项式分布描述的是多个试验中各个分类的次数。
考虑一个试验,将一个对象放入多个互不相交的类别中,每个类别发生的概率为 p 1 , p 2 , … , p k p_1, p_2, \ldots, p_k p1,p2,…,pk,其中 p i p_i pi 表示对象属于第 i i i 个类别的概率。试验进行了 n n n 次,我们想知道每个类别发生的次数。
多项式分布的概率质量函数为:
P ( X 1 = x 1 , X 2 = x 2 , … , X k = x k ) = n ! x 1 ! ⋅ x 2 ! ⋅ … ⋅ x k ! ⋅ p 1 x 1 ⋅ p 2 x 2 ⋅ … ⋅ p k x k P(X_1 = x_1, X_2 = x_2, \ldots, X_k = x_k) = \frac{n!}{x_1! \cdot x_2! \cdot \ldots \cdot x_k!} \cdot p_1^{x_1} \cdot p_2^{x_2} \cdot \ldots \cdot p_k^{x_k} P(X1=x1,X2=x2,…,Xk=xk)=x1!⋅x2!⋅…⋅xk!n!⋅p1x1⋅p2x2⋅…⋅pkxk
其中:
- n n n 是试验次数。
- k k k 是类别的个数。
- x 1 , x 2 , … , x k x_1, x_2, \ldots, x_k x1,x2,…,xk 分别是每个类别发生的次数。
- p 1 , p 2 , … , p k p_1, p_2, \ldots, p_k p1,p2,…,pk 分别是每个类别发生的概率,且 ∑ i = 1 k p i = 1 \sum_{i=1}^{k} p_i = 1 ∑i=1kpi=1。
多项式分布常常用于描述具有多个离散类别的随机试验,例如扔骰子、抽取彩球等。
似然为多项式分布




中国餐馆过程
predictive distribution






CG
- https://github.com/sakshamgarg/Dirichlet-Out-of-Distribution-Detection
- https://www.cs.princeton.edu/courses/archive/fall07/cos597C/scribe/20070921.pdf
SAM
安装
- https://github.com/facebookresearch/segment-anything#model-checkpoints
$ pip install git+https://github.com/facebookresearch/segment-anything.git
Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
Collecting git+https://github.com/facebookresearch/segment-anything.git
Cloning https://github.com/facebookresearch/segment-anything.git to /tmp/pip-req-build-3od4d54t
Running command git clone --filter=blob:none --quiet https://github.com/facebookresearch/segment-anything.git /tmp/pip-req-build-3od4d54t
Resolved https://github.com/facebookresearch/segment-anything.git to commit 6fdee8f2727f4506cfbbe553e23b895e27956588
Preparing metadata (setup.py) ... done
Building wheels for collected packages: segment-anything
Building wheel for segment-anything (setup.py) ... done
Created wheel for segment-anything: filename=segment_anything-1.0-py3-none-any.whl size=36589 sha256=b23a3b85adc5d579423f8ef9a218af802032d60d6aa3706d67f87dbe48d70fd5
Stored in directory: /tmp/pip-ephem-wheel-cache-119odynp/wheels/b0/7e/40/20f0b1e23280cc4a66dc8009c29f42cb4afc1b205bc5814786
Successfully built segment-anything
Installing collected packages: segment-anything
Successfully installed segment-anything-1.0
使用
- 从给定的提示中获取掩码
from segment_anything import SamPredictor, sam_model_registry
sam = sam_model_registry["vit_l"](checkpoint="sam_vit_l_0b3195.pth")
predictor = SamPredictor(sam)
predictor.set_image(<your_image>)
masks, _, _ = predictor.predict(<input_prompts>)
- 为整个图像生成蒙版
from segment_anything import SamAutomaticMaskGenerator, sam_model_registry
sam = sam_model_registry["vit_l"](checkpoint="sam_vit_l_0b3195.pth")
mask_generator = SamAutomaticMaskGenerator(sam)
masks = mask_generator.generate(<your_image>)

















 5509
5509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









