






世界模型(World Model)是一种用于模拟环境的模型,它能够根据当前状态和动作预测未来的状态和相关奖励。具体来说,世界模型的主要功能包括:
-
状态预测:世界模型接收当前的世界状态(例如,图像观察)和代理的动作,然后预测未来的状态。这种预测可以是确定性的或随机的,具体取决于模型的设计和应用场景。
-
奖励预测:除了预测未来的状态,世界模型还可以预测与这些状态相关的奖励。奖励通常用于强化学习中,以指导代理的行为。
-
环境模拟:世界模型能够模拟环境的动力学,即环境如何响应代理的动作。这种模拟能力使得代理可以在虚拟环境中进行训练和规划,而无需在真实环境中执行动作。
-
多样性和泛化:世界模型通常在多样化的环境和主体上进行训练,以便能够适应不同的场景和任务。例如,导航世界模型(NWM)在来自人类和机器人代理的多样化第一人称视频上进行训练,以捕捉复杂的环境动态。
-
规划和策略优化:通过模拟未来的状态和奖励,世界模型可以用于规划和优化代理的策略。例如,NWM可以模拟导航轨迹并评估它们是否达到预期目标,从而进行导航轨迹规划。
世界模型是一种强大的工具,能够帮助代理理解和预测环境的行为,从而在各种任务中进行有效的规划和决策。这篇文章介绍了一种名为导航世界模型(Navigation World Model, NWM)的新型可控视频生成模型,旨在预测基于过去观察和导航动作的未来视觉观察。NWM采用了一种条件扩散变换器(Conditional Diffusion Transformer, CDiT),并在多样化的第一人称视频数据上进行训练,扩展到10亿参数。其主要内容包括:
-
模型架构:NWM使用CDiT架构,能够在多样环境和主体上进行训练,并有效扩展到大规模参数。
-
训练数据:模型在来自人类和机器人代理的多样化第一人称视频上进行训练,利用广泛的环境和主体数据。
-
应用场景:在熟悉的环境中,NWM可以模拟导航轨迹并评估它们是否达到预期目标,从而进行导航轨迹规划。在不熟悉的环境中,NWM可以从单张输入图像中想象出轨迹。
-
实验结果:实验表明,NWM在规划轨迹和增强现有导航策略方面表现出色,特别是在已知环境中独立规划或对现有策略采样的轨迹进行排序时。
-
泛化能力:通过在无标签、无动作和无奖励的视频数据上训练,NWM在不熟悉环境中的视频预测和生成性能有所提高。
总的来说,NWM提供了一种可扩展的、数据驱动的方法来学习导航策略,能够在多样化的环境中灵活适应,并具有强大的规划和生成能力。这里是自己的论文阅读记录,感兴趣的话可以参考一下,如果需要阅读原文的话可以看这里,如下所示:

摘要
导航是具有视觉运动能力的代理的基本技能。我们引入了一种导航世界模型(NWM),这是一种可控的视频生成模型,它基于过去的观察和导航动作预测未来的视觉观察。为了捕捉复杂的环境动态,NWM采用了一种条件扩散变换器(CDiT),该模型在来自人类和机器人代理的多样化第一人称视频上进行训练,并扩展到10亿参数。在熟悉的环境中,NWM可以通过模拟导航轨迹并评估它们是否达到预期目标来进行导航轨迹规划。与行为固定的监督导航策略不同,NWM可以在规划过程中动态地纳入约束条件。实验证明了其在从头规划轨迹或通过外部策略采样的轨迹排序方面的有效性。此外,NWM利用其学习的视觉先验,可以从单张输入图像中想象出不熟悉环境中的轨迹,使其成为下一代导航系统的灵活而强大的工具。
项目地址在这里,如下所示:
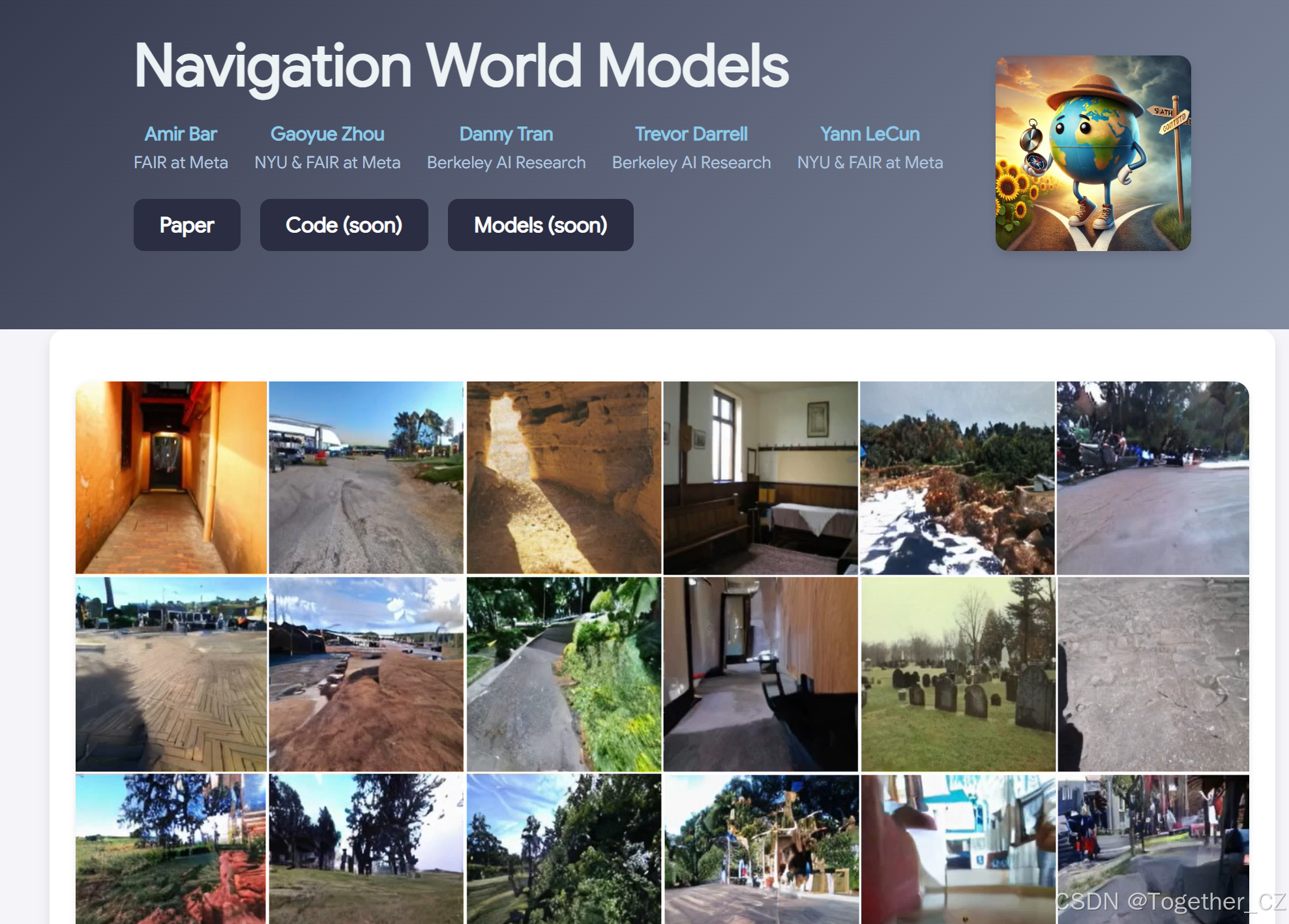

图1:我们训练了一个导航世界模型(NWM),从机器人及其相关导航动作的视频片段中进行训练(a)。训练后,NWM可以通过合成视频并评估最终帧与目标的相似性来评估轨迹(b)。我们使用NWM来从头规划或对专家导航轨迹进行排序,从而提高下游视觉导航性能。在不熟悉的环境中,NWM可以从单张图像中模拟想象的轨迹(c)。在所有上述示例中,模型的输入是第一张图像和动作,然后模型自回归地合成未来的观察结果。点击图像以在浏览器中查看示例。
1 引言
导航是任何具有视觉能力的生物的基本技能,通过允许代理定位食物、避难所和避免捕食者,在生存中起着至关重要的作用。为了成功导航环境,智能代理主要依赖视觉,使它们能够构建周围环境的表示,评估距离并捕捉环境中的地标,这些都对规划导航路线有用。
当人类代理规划时,他们通常会想象未来的轨迹,考虑约束条件和反事实情况。另一方面,当前最先进的机器人导航策略(Sridhar et al., 2024; Shah et al., 2023)是“硬编码”的,训练后无法轻易引入新的约束条件(例如,“禁止左转”)。当前监督视觉导航模型的另一个局限性是,它们无法动态分配更多计算资源来解决难题。我们的目标是设计一种新的模型,能够缓解这些问题。
在这项工作中,我们提出了一种导航世界模型(NWM),该模型经过训练,可以根据过去帧表示和动作预测未来视频帧的表示(见图1(a))。NWM在从各种机器人代理收集的视频片段和导航动作上进行训练。训练后,NWM用于通过模拟潜在导航计划并验证它们是否达到目标来规划新的导航轨迹(见图1(b))。为了评估其导航技能,我们在已知环境中测试NWM,评估其独立规划新轨迹或在现有导航策略的帮助下规划新轨迹的能力。在规划设置中,我们在模型预测控制(MPC)框架中使用NWM,优化使NWM达到目标的动作序列。在排序设置中,我们假设可以访问现有的导航策略,例如NoMaD(Sridhar et al., 2024),这使我们能够采样轨迹,使用NWM模拟它们,并选择最佳轨迹。我们的NWM在独立性能上具有竞争力,并与现有方法结合时达到最先进的结果。
NWM在概念上类似于最近的基于扩散的离线模型强化学习世界模型,例如DIAMOND(Alonso et al.)和GameNGen(Valevski et al., 2024)。然而,与这些模型不同,NWM在广泛的环境和主体上进行训练,利用来自机器人和人类代理的多样化导航数据。这使我们能够训练一个能够随模型大小和数据有效扩展的大规模扩散变换器模型,以适应多个环境。我们的方法还与Novel View Synthesis(NVS)方法(如NeRF(Mildenhall et al., 2021)、Zero-1-2-3(Liu et al., 2023)和GDC(Van Hoorick et al., 2024))有相似之处,从中我们获得了灵感。然而,与NVS方法不同,我们的目标是训练一个单一模型,用于跨多样环境的导航,并从自然视频中建模时间动态,而不依赖于3D先验。
为了学习NWM,我们提出了一种新颖的条件扩散变换器(CDiT),该模型经过训练,可以根据过去的图像状态和动作作为上下文来预测下一个图像状态。与DiT(Peebles and Xie, 2023)不同,CDiT的计算复杂度与上下文帧的数量呈线性关系,并且在跨多样环境和主体训练的模型中,其扩展性良好,最多可达10亿参数,与标准DiT相比,所需的FLOPs减少了4倍,同时实现了更好的未来预测结果。
在不熟悉的环境中,我们的结果表明,NWM受益于在Ego4D上训练的无标签、无动作和无奖励的视频数据。定性上,我们观察到在单张图像上的视频预测和生成性能有所提高(见图1(c))。定量上,在额外的无标签数据上训练的NWM在保留的Stanford Go(Hirose et al., 2018)数据集上进行评估时,产生了更准确的预测。
我们的贡献如下。我们引入了一种导航世界模型(NWM),并提出了一种新颖的条件扩散变换器(CDiT),该模型能够高效扩展到10亿参数,与标准DiT相比显著减少了计算需求。我们在来自多样化机器人代理的视频片段和导航动作上训练CDiT,通过独立模拟导航计划或与外部导航策略结合进行规划,实现了最先进的视觉导航性能。最后,通过在无动作和无奖励的视频数据(如Ego4D)上训练NWM,我们展示了在不熟悉环境中的视频预测和生成性能的提高。
2 相关工作
目标条件视觉导航是机器人学中的一个重要任务,需要感知和规划技能(Sridhar et al., 2024; Shah et al.; Pathak et al., 2018; Mirowski et al., 2022; Chaplot et al.; Fu et al., 2022)。给定上下文图像和指定导航目标的图像,目标条件视觉导航模型(Sridhar et al., 2024; Shah et al.)旨在生成一条可行的路径,如果环境已知则朝向目标,否则则进行探索。最近的视觉导航方法,如NoMaD(Sridhar et al., 2024),通过行为克隆和时间距离目标训练扩散策略,以在条件设置中跟随目标或在无条件设置中探索新环境。之前的研究,如Active Neural SLAM(Chaplot et al.),使用神经SLAM与分析规划器结合,在3D环境中规划轨迹,而其他方法(如Chen et al.)则通过强化学习学习策略。在这里,我们展示了世界模型可以使用探索性数据来规划或改进现有的导航策略。
与学习策略不同,世界模型的目标是模拟环境,例如,给定当前状态和动作来预测下一个状态和相关奖励(Ha and Schmidhuber, 2018)。之前的研究表明,联合学习策略和世界模型可以提高Atari(Hafner et al., b.a; Alonso et al.)、模拟机器人环境(Seo et al., 2023)甚至应用于真实世界机器人(Wu et al., 2023)的样本效率。最近,Hansen et al.提出使用单个世界模型,通过引入动作和任务嵌入来跨任务共享,而Yang et al.; Lin et al. ()提出用语言描述动作,Bruce et al. (2024)提出学习潜在动作。世界模型也在游戏模拟的背景下进行了探索。DIAMOND(Alonso et al.)和GameNGen(Valevski et al., 2024)提出使用扩散模型来学习像Atari和Doom这样的电脑游戏的游戏引擎。我们的工作受到这些工作的启发,旨在学习一个可以在许多环境和不同主体之间共享的通用扩散视频变换器,用于导航。
在计算机视觉中,生成视频一直是一个长期存在的挑战(Kondratyuk et al.; Blattmann et al., 2023; Girdhar et al., 2023; Yu et al., 2023; Ho et al., 2022; Tulyakov et al., ; Bar-Tal et al., 2024)。最近,随着Sora(Brooks et al., 2024)和MovieGen(Polyak et al., 2024)等方法的出现,文本到视频合成的进展巨大。过去的研究提出了在给定结构化动作-对象类别(Tulyakov et al., )或动作图(Bar et al., 2021)的情况下控制视频合成。视频生成模型之前在强化学习中用作奖励(Escontrela et al., 2024),预训练方法(Tomar et al., 2024),用于模拟和规划操作动作(Finn and Levine, 2017; Liang et al., 2024),以及在室内环境中生成路径(Hirose et al., ; Koh et al., 2021)。有趣的是,扩散模型(Sohl-Dickstein et al., 2015; Ho et al., 2020)在视频任务(如生成(Voleti et al., 2022)和预测(Lin et al., ))以及视图合成(Chan et al., 2023; Poole et al.; Tung et al., 2025)中都很有用。不同地,我们使用条件扩散变换器来模拟轨迹进行规划,而不需要显式的3D表示或先验。
3 导航世界模型
公式化
接下来,我们将描述我们的NWM公式。直观地说,NWM是一个模型,它接收世界的当前状态(例如,图像观察)和描述移动位置和旋转方式的导航动作。然后,模型根据代理的视角生成下一个世界状态。


由于这个公式的简单性,它可以自然地在环境和主体之间共享,并且可以轻松扩展到更复杂的动作空间,例如控制机械臂。与Hafner et al. ()不同,我们的目标是在环境和主体之间训练一个单一的世界模型,而不像Hansen et al.那样使用任务或动作嵌入。

这个公式允许学习导航动作和环境时间动态。在实践中,我们允许时间偏移最多为±16秒。
可能出现的一个挑战是动作和时间的纠缠。例如,如果到达特定位置总是在特定时间发生,模型可能会学会仅依赖时间而忽略后续动作,反之亦然。在实践中,数据可能包含自然的反事实情况——例如在不同时间到达同一区域。为了鼓励这些自然的反事实情况,我们在训练期间为每个状态采样多个目标。我们进一步在第4节中探讨这种方法。
作为世界模型的扩散变换器
如前一节所述,我们将 Fθ 设计为随机映射,以便它可以模拟随机环境。这是通过使用条件扩散变换器(CDiT)模型实现的,接下来将进行描述。
条件扩散变换器架构。我们使用的架构是一个时间自回归变换器模型,利用高效的CDiT块(见图2),该块在输入序列的潜在表示上应用了×N次,并带有输入动作条件。
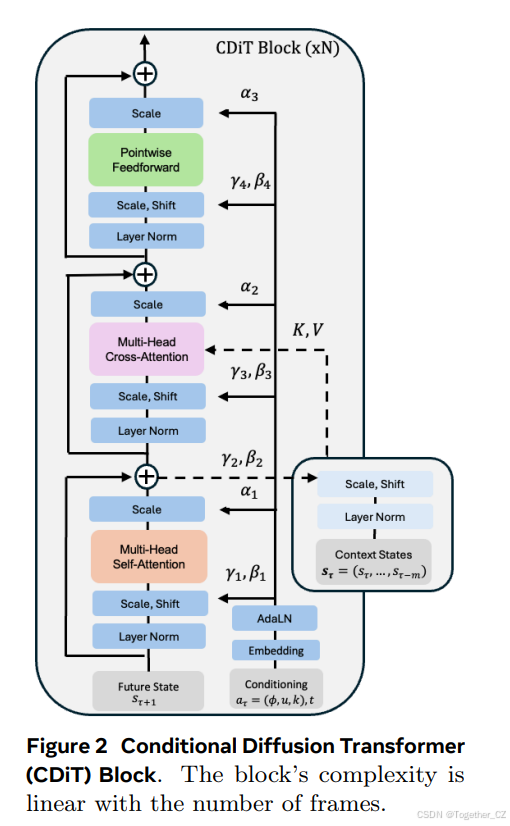
图2 条件扩散变换器(CDiT)块。该块的复杂度与帧数呈线性关系
CDiT通过将第一个注意力块中的注意力仅限于正在去噪的目标帧的标记来实现时间高效的自回归建模。为了对过去帧的标记进行条件化,我们引入了一个交叉注意力层,使得当前目标的每个查询标记都关注过去帧的标记,这些标记用作键和值。交叉注意力然后使用跳连接层对表示进行上下文化。


使用世界模型进行导航规划
在这里,我们将描述如何使用训练好的NWM来规划导航轨迹。直观地说,如果我们的世界模型熟悉一个环境,我们可以使用它来模拟导航轨迹,并选择那些达到目标的轨迹。在未知、分布外的环境中,长期规划可能依赖于想象。

图3 在已知环境中跟随轨迹。我们包含了不同模型跟随真实轨迹的定性视频生成比较。点击图像以在浏览器中播放视频片段


表1 每个样本的预测目标数量、上下文大小以及动作和时间条件使用的消融实验。我们在RECON上报告了未来4秒的预测结果
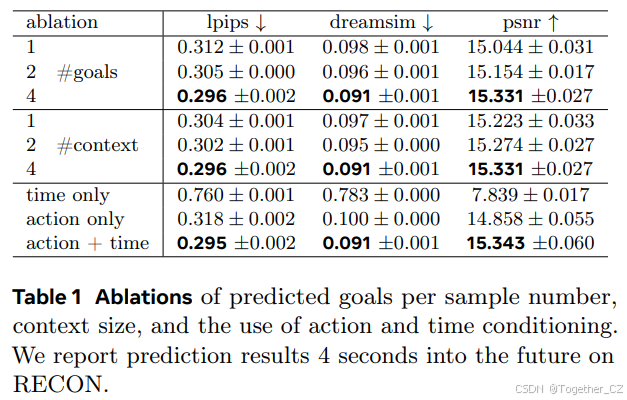
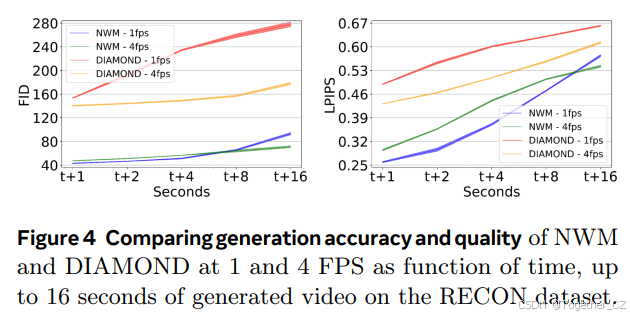
图4 在RECON数据集上,比较NWM和DIAMOND在1 FPS和4 FPS下的生成准确性和质量随时间变化,最多16秒的生成视频
4 实验和结果
我们描述了实验设置、设计选择,并将NWM与之前的方法进行了比较。附加结果包含在补充材料中。
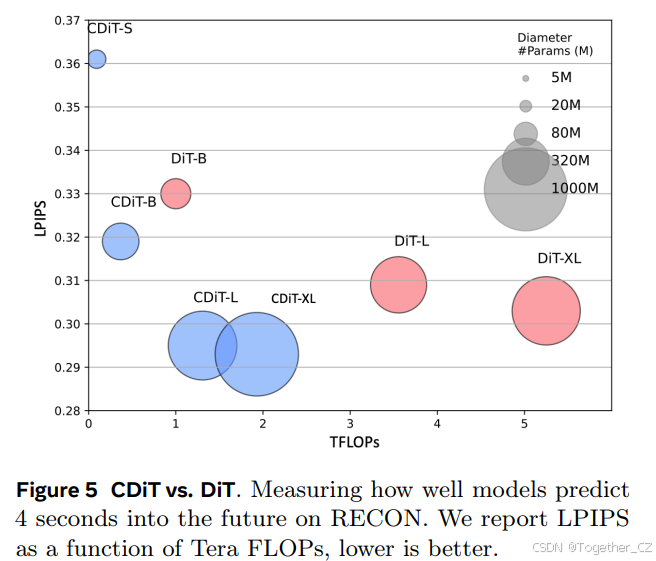
图5:CDIT vs. DIT。在RECON上测量模型在未来4秒的预测效果。我们报告了LPIPS随Tera FLOPs的变化,越低越好。

图6:视频合成质量比较。在RECON上生成的16秒视频,4 FPS。
实验设置
数据集。对于所有机器人数据集(SCAND(Karnan et al., 2022)、TartanDrive(Triest et al., 2022)、RECON(Shah et al., 2021)和HuRoN(Hirose et al., 2023)),我们可以访问机器人的位置和旋转,这使我们能够推断相对于当前位置的动作(见公式2)。为了标准化不同代理的步长,我们将代理在帧之间移动的距离除以其平均步长(以米为单位),确保不同代理的动作空间相似,此外我们还过滤掉向后移动,遵循NoMaD(Sridhar et al., 2024)。此外,我们使用无标签的Ego4D(Grauman et al., 2022)视频,其中我们仅考虑时间偏移作为动作。SCAND提供了在多样环境中社会合规导航的视频片段,TartanDrive专注于越野驾驶,RECON涵盖开放世界导航,HuRoN捕捉社会互动。我们在无标签的Ego4D视频和GO Stanford(Hirose et al., 2018)上进行训练,并作为未知环境的评估。有关完整细节,请参见附录B.1。
评估指标。我们使用绝对轨迹误差(ATE)和相对姿态误差(RPE)来评估预测的导航轨迹的准确性和一致性(Sturm et al., 2012)。为了检查世界模型预测与真实图像在语义上的相似性,我们应用LPIPS(Zhang et al., )和DreamSim(Fu et al., 2024),通过比较深度特征来测量感知相似性,并使用PSNR来评估像素级质量。对于图像和视频合成质量,我们使用FID(Heusel et al., 2017)和FVD(Unterthiner et al., 2019),它们评估生成数据分布的质量。有关更多细节,请参见附录B.1。
基线。我们考虑以下所有基线。
-
*DIAMOND(Alonso et al.)是一种基于UNet(Ronneberger et al., 2015)架构的扩散世界模型。我们按照其公开代码在离线强化学习设置中使用DIAMOND。扩散模型经过训练,以56x56分辨率自回归预测,并使用上采样器达到224x224分辨率的预测。我们更改了其动作嵌入以使用线性层来处理我们的连续动作。
-
*GNM(Shah et al., 2023)是一种在机器人导航数据集的混合数据上训练的通用目标条件导航策略,具有完全连接的轨迹预测网络。GNM在多个数据集上进行训练,包括SCAND、TartanDrive、GO Stanford和RECON。
-
*NoMaD(Sridhar et al., 2024)通过使用扩散策略扩展GNM,用于预测机器人探索和视觉导航的轨迹。NoMaD在GNM使用的相同数据集以及HuRoN上进行训练。
实现细节。在默认实验设置中,我们使用10亿参数的CDiT-XL,上下文为4帧,总批量大小为1024,4个不同的导航目标,最终总批量大小为4096。我们使用与DiT(Peebles and Xie, 2023)类似的Stable Diffusion(Blattmann et al., 2023)VAE标记器。我们使用AdamW(Loshchilov, 2017)优化器,学习率为 8e−5。训练后,我们从每个模型中采样5次以报告均值和标准差结果。XL大小的模型在8台H100机器上进行训练,每台机器有8个GPU。除非另有说明,我们使用与DiT-*/2模型相同的设置。
消融实验
模型在已知环境RECON的验证集轨迹上进行单步4秒未来预测,并通过测量LPIPS、DreamSim和PSNR与真实帧的性能进行评估。我们在图3中提供了定性示例。
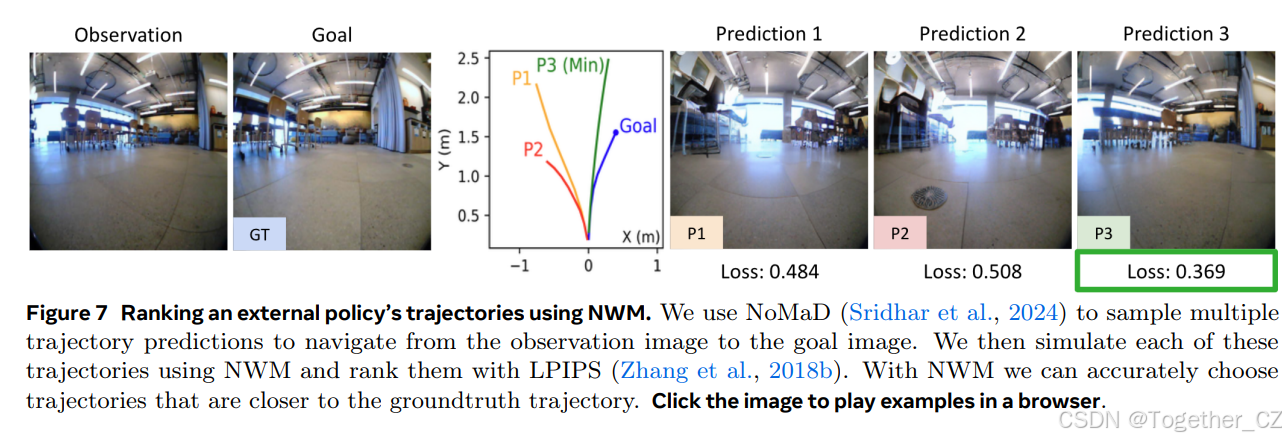
图7 使用NWM对现有策略的轨迹进行排序。我们使用NoMaD(Sridhar et al., 2024)从观察图像到目标图像采样多个轨迹预测。然后我们使用NWM模拟这些轨迹,并使用LPIPS(Zhang et al., 2018b)对它们进行排序。通过NWM,我们可以准确选择更接近真实轨迹的轨迹。点击图像以在浏览器中播放示例
模型大小和CDiT。我们比较了CDiT(见第3.2节)与标准DiT,其中所有上下文标记都作为输入。我们假设对于已知环境的导航,模型的容量是最重要的,图5中的结果表明,CDiT在最多10亿参数的模型中确实表现更好,同时消耗的FLOPs不到2倍。令人惊讶的是,即使参数数量相等(例如,CDiT-L与DiT-XL相比),CDiT的速度快4倍且性能更好。
目标数量。我们在固定上下文的情况下训练具有可变目标状态数量的模型,将目标数量从1变为4。每个目标在当前状态周围的±16秒窗口内随机选择。表1中报告的结果表明,使用4个目标显著提高了所有指标的预测性能。
上下文大小。我们在1到4个条件帧的情况下训练模型(见表1)。不出所料,更多的上下文有助于提高性能,而上下文较短的模型往往会“失去跟踪”,导致预测效果不佳。
时间和动作条件。我们在同时使用时间和动作条件的情况下训练模型,并测试每个输入对预测性能的贡献(我们在表1中包含了结果)。我们发现仅使用时间会导致性能不佳,而不使用时间条件也会导致性能略有下降。这证实了两个输入对模型都有益。
视频预测和合成
我们评估模型如何遵循真实动作并预测未来状态。模型以第一张图像和上下文帧为条件,然后自回归地使用真实动作预测下一个状态,反馈每个预测。我们比较了在1、2、4、8和16秒时的预测与真实图像,报告了RECON数据集上的FID和LPIPS。图4显示了与DIAMOND在4 FPS和1 FPS下的性能随时间变化,表明NWM的预测显著更准确。最初,NWM 1 FPS变体表现更好,但在8秒后,由于累积误差和上下文丢失,预测质量下降,4 FPS变得更好。请参见图3中的定性示例。
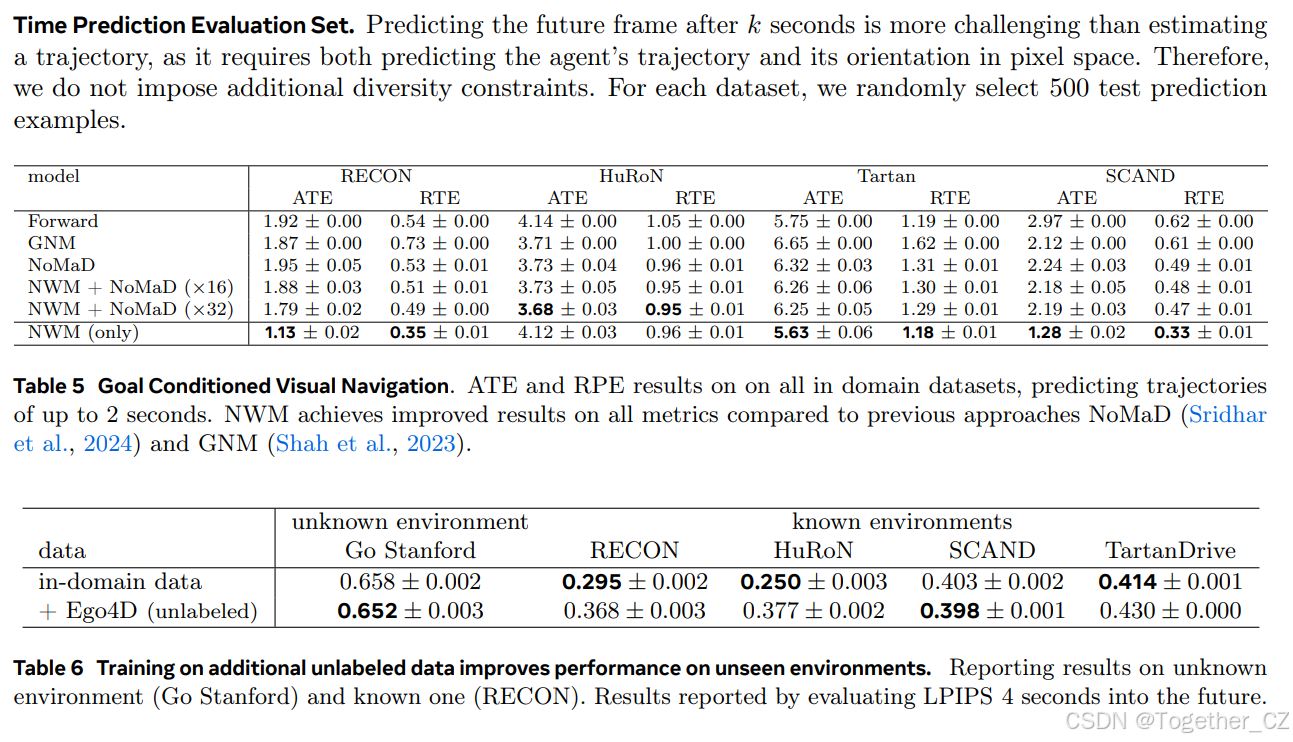
表2 目标条件视觉导航。在RECON上预测2秒轨迹的ATE和RPE结果。与之前的NoMaD(Sridhar et al., 2024)和GNM(Shah et al., 2023)方法相比,NWM在所有指标上均取得了改进的结果
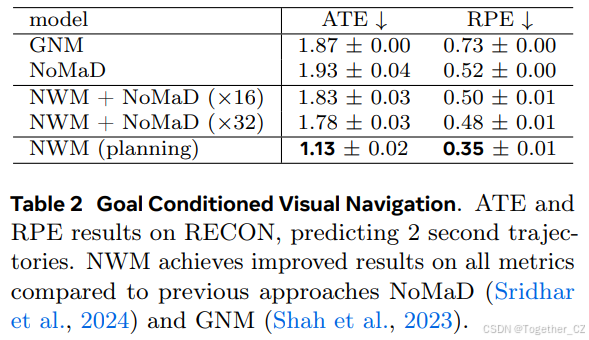
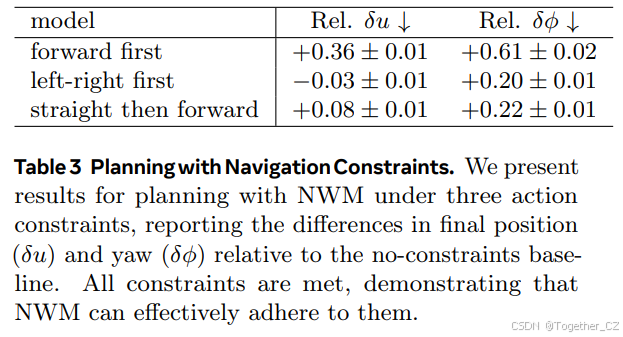
表3 规划导航约束。我们在三种动作约束下使用NWM进行规划的结果,报告了相对于无约束基线的最终位置(δu)和偏航(δϕ)的差异。所有约束条件均得到满足,表明NWM能够有效地遵守这些约束
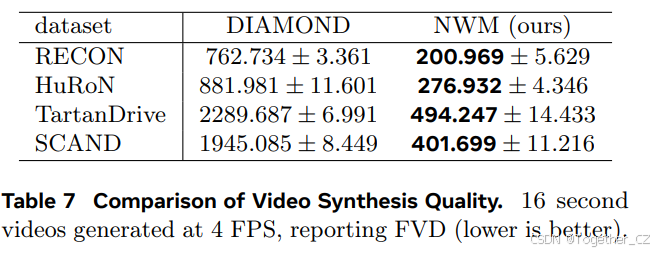
生成质量。为了评估视频质量,我们自回归地以4 FPS预测16秒的视频,同时以真实动作为条件。然后我们使用FVD评估生成的视频质量,与DIAMOND(Alonso et al.)进行比较。图6中的结果表明,NWM生成的视频质量更高。
使用导航世界模型进行规划
接下来,我们将描述实验,测量我们使用NWM导航的效果。我们在附录B.2中包含了实验的完整技术细节。

图8 在不熟悉的环境中导航。NWM以单张图像为条件,并自回归地预测给定相关动作(标记为黄色)的下一个状态。点击图像以在浏览器中播放视频片段
独立规划。我们展示了我们的世界模型可以有效地独立用于目标条件导航。我们以过去的观察和目标图像为条件,并使用交叉熵方法找到最小化最后一个预测图像与目标图像的LPIPS相似性的轨迹(见公式5)。为了对动作序列进行排序,我们执行NWM并测量最后一个状态与目标之间的LPIPS 3次以获得平均分数。我们生成长度为8的轨迹,时间偏移为 k=0.25 。我们在表2中评估了模型性能。我们发现使用NWM进行规划在与其他方法相比时表现出色,特别是与之前的硬编码策略相比。
表4 在额外的无标签数据上训练提高了在不熟悉环境中的性能。报告了未知环境(Go Stanford)和已知环境(RECON)的结果。结果通过评估未来4秒进行报告

规划约束。在世界模型中规划允许纳入约束条件。例如,代理可能被限制沿直线移动或只进行一次转弯。我们展示了我们可以在满足约束条件的情况下使用NWM进行规划。在“先向前”中,代理先向前移动5步,然后向左或向右移动3步。在“先左右”中,代理先向左或向右移动3步,然后向前移动5步。在“先直后前”中,代理在任何方向上直线移动3步,然后向前移动。为了设置这些约束,我们可以简单地将相应的动作硬编码为零,例如,在“先左右”中,我们将前3个动作的向前移动设置为零,并运行独立规划以优化剩余的动作。请参见附录B.2中的完整细节。最后,我们报告每个设置下最终位置和偏航的差异范数,相对于无约束规划,代理沿任何方向直线移动。
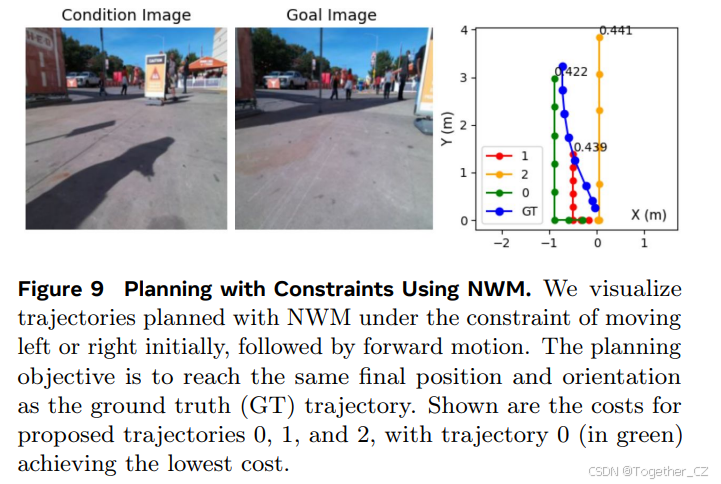
图9 使用NWM进行约束规划。我们在NWM下可视化了在初始向左或向右移动后向前移动的约束下规划的轨迹。规划目标是达到与真实轨迹(GT)相同的最终位置和方向。显示了提议轨迹0、1和2的成本,其中轨迹0(绿色)的成本最低
表3中的结果表明,NWM可以在满足约束条件的情况下有效地进行规划,观察到的规划性能差异很小。我们在图9中包含了在“先左右”约束下规划的轨迹示例。
使用导航世界模型进行排序。NWM可以增强现有的目标条件导航策略。以过去的观察和目标图像为条件,我们从NoMaD中采样 n∈{16,32} 条长度为8的轨迹,并使用NWM自回归地跟随动作进行评估。最后,我们通过测量LPIPS与目标图像的相似性对每个轨迹的最终预测进行排序(见图7)。我们在所有域内数据集上报告了ATE和RPE(见表2),发现使用NWM从16条轨迹池中选择时,性能有所提高,从更大池中选择时进一步提高。
泛化到未知环境
在这里,我们实验了添加无标签数据,并询问NWM是否可以使用想象在新环境中进行预测。显然,在这个实验中,我们在所有域内数据集上训练模型,以及Ego4D的一个子集的无标签视频,我们只能访问时间偏移动作。我们训练了一个CDiT-XL模型,并在Go Stanford数据集以及其他随机图像上进行测试。我们在表4中报告了结果,发现训练无标签数据显著提高了所有指标的视频预测质量,包括生成质量的提高。我们在图8中包含了定性示例。与域内数据(图3)相比,模型更快地崩溃,并预期地生成想象环境的遍历路径。
5 局限性
我们确定了多个局限性。首先,当应用于分布外数据时,我们注意到模型倾向于逐渐失去上下文并生成类似于训练数据的下一个状态,这种现象在图像生成中被称为模式崩溃[25, 26]。我们在图10中包含了这样一个示例。其次,虽然模型可以进行规划,但在模拟时间动态(如行人运动)方面存在困难(尽管在某些情况下确实可以模拟)。这两个局限性可能通过更长的上下文和更多的训练数据来解决。此外,该模型目前使用3自由度导航动作,但扩展到6自由度导航以及可能更多(如控制机械臂的关节)也是可能的,我们将其留待未来的工作。

图10 局限性和失败案例。在不熟悉的环境中,一个常见的失败案例是模式崩溃,其中模型的输出逐渐变得与训练数据中的数据更相似。点击图像以在浏览器中播放视频片段
6 结论
我们提出的导航世界模型(NWM)提供了一种可扩展的、数据驱动的方法来学习导航策略。NWM通过我们的CDiT架构在多样化的环境中进行训练,并能够灵活地适应各种场景。NWM可以独立规划或通过模拟导航结果对现有策略进行排序,这也使它能够纳入新的约束条件。这种方法将视频学习、视觉导航和基于模型的规划结合起来,可能会为不仅感知而且行动的自监督系统打开大门。
致谢。我们感谢Noriaki Hirose在设置HuRoN数据集和分享他的见解方面的帮助,以及Manan Tomar、David Fan和Sonia Joseph对稿件的有益评论。最后,我们感谢Angjoo Kanazawa、Ethan Weber和Nicolas Ballas的有益讨论和反馈。
图10:局限性和失败案例。在不熟悉的环境中,一个常见的失败案例是模式崩溃,其中模型的输出逐渐变得与训练数据中的数据更相似。点击图像以在浏览器中播放视频片段。
附录
附录的结构如下:我们首先在第A节中描述如何通过独立规划来规划导航轨迹,然后在第B节中包含更多实验和结果。
附录A 独立规划优化
如第3.3节所述,我们使用预训练的NWM通过优化公式5来独立规划目标条件导航轨迹。在这里,我们提供了使用交叉熵方法(Rubinstein, 1997)进行优化的额外细节和使用的超参数。完整的独立导航规划结果在第B.2节中展示。
我们使用交叉熵方法优化轨迹,这是一种无梯度的随机优化技术,用于连续优化问题。该方法通过迭代更新概率分布来提高生成更好解的可能性。在无约束的独立规划场景中,我们假设轨迹是一条直线,并仅优化其终点,由三个变量表示:单个平移 u 和偏航旋转 ϕ。然后我们将这个元组映射到八个均匀间隔的增量步长,在最后一步应用偏航旋转。步长之间的时间间隔固定为 k=0.25 秒。我们优化过程的主要步骤如下:

附录B 实验和结果
实验研究
我们详细描述了使用的指标和数据集。
评估指标。我们描述了用于评估预测导航轨迹和NWM生成的图像质量的评估指标。
对于视觉导航性能,绝对轨迹误差(ATE)通过计算估计轨迹和真实轨迹中对应点之间的欧几里得距离来评估轨迹估计的总体准确性。相对姿态误差(RPE)通过计算连续姿态之间相对变换的误差来评估连续姿态的一致性(Sturm et al., 2012)。
为了更严格地评估世界模型输出的语义,我们使用学习到的感知图像块相似性(LPIPS)和DreamSim(Fu et al., 2024),通过比较神经网络的深度特征来评估感知相似性(Zhang et al., )。特别是,LPIPS使用AlexNet(Krizhevsky et al., 2012)来关注人类对结构差异的感知。此外,我们使用峰值信噪比(PSNR)来量化生成图像的像素级质量,通过测量最大像素值与误差的比率,值越高表示质量越好。
为了研究图像和视频合成质量,我们使用Fréchet Inception Distance(FID)和Fréchet Video Distance(FVD),它们比较真实和生成图像或视频的特征分布。较低的FID和FVD分数表示较高的视觉质量(Heusel et al., 2017; Unterthiner et al., 2019)。

数据集。对于所有机器人数据集,我们可以访问机器人的位置和旋转,并使用这些信息来推断相对于当前位置的动作。我们移除所有向后移动,这可能是抖动的,遵循NoMaD(Sridhar et al., 2024),从而将数据分割为向前行走的片段,用于SCAND(Karnan et al., 2022)、TartanDrive(Triest et al., 2022)、RECON(Shah et al., 2021)和HuRoN(Hirose et al., 2023)。我们还使用无标签的Ego4D视频,其中我们仅使用时间偏移作为动作。接下来,我们描述每个单独的数据集。


-
*SCAND(Karnan et al., 2022)是一个机器人数据集,包含使用轮式Clearpath Jackal和腿式Boston Dynamics Spot在UT Austin的室内和室外环境中进行的社会合规导航演示。该数据集包含8.7小时、138条轨迹、25英里的数据,我们使用相应的相机姿态。我们使用484个视频片段进行训练,121个视频片段进行测试。用于训练和评估。
-
*TartanDrive(Triest et al., 2022)是一个户外越野驾驶数据集,使用改装的Yamaha Viking ATV在匹兹堡收集。该数据集包含5小时和630条轨迹。我们使用1,000个视频片段进行训练,251个视频片段进行测试。
-
*RECON(Shah et al., 2021)是一个户外机器人数据集,使用Clearpath Jackal UGV平台收集。该数据集包含40小时,跨越9个开放世界环境。我们使用9,468个视频片段进行训练,2,367个视频片段进行测试。用于训练和评估。
-
*HuRoN(Hirose et al., 2023)是一个机器人数据集,包含使用Robot Roomba在UC Berkeley的室内环境中进行的社会互动。该数据集包含超过75小时,在5个不同环境中与4,000次人类互动。我们使用2,451个视频片段进行训练,613个视频片段进行测试。用于训练和评估。
-
*GO Stanford(Hirose et al., 2018, )是一个机器人数据集,捕捉了两个不同遥控机器人的鱼眼视频片段,在斯坦福大学的至少27个不同建筑中收集了大约25小时的视频片段。由于图像分辨率较低,我们仅将其用于域外评估。
-
*Ego4D(Grauman et al., 2022)是一个大规模以自我为中心的数据集,包含3,670小时,跨越74个地点。Ego4D包含各种场景,如手工艺、烹饪、建筑、清洁和洗衣以及杂货购物。我们仅使用涉及视觉导航的视频,如杂货购物和慢跑。我们总共使用1619个视频,超过908小时进行训练。仅用于无标签训练。我们使用的视频来自以下Ego4D场景:“滑板/滑板车”、“轮滑”、“足球”、“参加节日或集市”、“园丁”、“迷你高尔夫”、“骑摩托车”、“高尔夫”、“骑自行车/慢跑”、“在街上行走”、“遛狗/宠物”、“室内导航(行走)”、“在户外商店工作”、“衣服/其他购物”、“与宠物玩耍”、“室内杂货购物”、“户外锻炼”、“农民”、“骑自行车”、“摘花”、“参加体育赛事(观看和参与)”、“无人机飞行”、“参加讲座/课程”、“徒步旅行”、“篮球”、“园艺”、“雪橇”、“去公园”。


视觉导航评估集。我们在构建视觉导航评估集时的主要发现是,向前运动非常普遍,如果不仔细考虑,它可能会主导评估数据。为了创建多样化的评估集,我们根据它们通过简单向前移动的可预测性对潜在评估轨迹进行排序。对于每个数据集,我们选择最不容易通过这种启发式方法预测的100个示例,并使用它们进行评估。



















 2782
2782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











