







发表于2022年7月26日
摘要
机器人导航的目标条件策略可以在大规模、无注释的数据集上进行训练,从而能够很好地泛化到现实世界场景中。然而,特别是在基于视觉的场景中,指定目标需要图像,这就导致了一个不自然的交互界面。语言为与机器人通信提供了一种更方便的方式,但当代方法通常需要昂贵的监督,形式为带有语言描述注释的轨迹。我们提出了一个名为LM-Nav的机器人导航系统,它既享受在无注释的大规模轨迹数据集上训练的好处,同时又为用户提供了一个高级交互界面。我们没有使用带有标签的指令跟随数据集,而是展示了这样一个系统可以完全由预训练的导航模型(ViNG)、图像 - 语言关联模型(CLIP)和语言模型(GPT-3)构建而成,无需任何微调或带有语言注释的机器人数据。我们在一个现实世界的移动机器人上实现了LM-Nav,并展示了它能够根据自然语言指令在复杂的户外环境中进行长距离导航。
关键词
指令跟随;语言模型;基于视觉的导航
1 引言
机器人学习的核心挑战之一是使机器人能够根据人类的高级指令,按命令执行各种各样的任务。这要求机器人能够理解人类指令,并具备大量不同的行为方式,以便在现实世界中执行这些指令。先前关于导航中指令跟随的工作主要集中在从带有文本指令注释的轨迹中学习[1-5]。这使得机器人能够理解文本指令,但数据注释的成本阻碍了其广泛应用。另一方面,最近的研究表明,通过使用事后重标记的目标条件策略进行自我监督训练,学习强大的导航能力是可能的。这些方法利用大规模的无标签数据集,通过事后重标记来训练基于视觉的控制器[6-11]。它们具有可扩展性、泛化性和鲁棒性,但通常涉及使用位置或图像来指定目标的笨拙机制。在这项工作中,我们旨在结合这两种方法的优点,通过利用预训练模型的能力,实现一个无需任何用户注释的导航数据的机器人导航自我监督系统(完全自监督),以执行自然语言指令。我们的方法使用这些模型构建一个 “界面”,人类可以使用该界面将所需任务传达给机器人。这个系统具有预训练的语言和视觉 - 语言模型令人印象深刻的泛化能力,使机器人系统能够接受复杂的高级指令。
我们的主要发现是,我们可以利用在大量视觉和语言数据集上训练的现成预训练模型(这些模型广泛可用并且具有很强的少样本泛化能力)来创建这个用于具身指令跟随的界面。为了实现这一点,我们将两个与机器人无关的预训练模型的优势与一个预训练的导航模型相结合。我们使用视觉导航模型(VNM:ViNG[11]),根据机器人的观察创建环境的拓扑 “心智地图”。给定自由形式的文本指令,我们使用预训练的大语言模型(LLM:GPT-3[12])将指令解码为一系列文本地标。然后,我们使用视觉 - 语言模型(VLM:CLIP[13]),通过推断地标和节点之间的联合似然,将这些文本地标在拓扑地图中进行定位。然后,使用一种新颖的搜索算法来最大化概率目标,并为机器人找到一个计划,该计划随后由VNM执行。
我们的主要贡献是大型模型导航(Large Model Navigation,LM-Nav),这是一个具身指令跟随系统,它结合了三个独立预训练的大型模型:一个利用视觉观察和物理动作的自我监督机器人控制模型(VNM)、一个将图像与文本关联但没有具身上下文的视觉 - 语言模型(VLM),以及一个可以解析和翻译文本但没有视觉定位或具身感知的大语言模型(LLM),以实现复杂现实世界环境中的长距离指令跟随。我们展示了第一个将预训练的视觉 - 语言模型与目标条件控制器相结合的机器人系统实例,能够在目标环境中无需任何微调就得出可行的计划。值得注意的是,所有这三个模型都是在大规模数据集上进行自我监督训练的,并且可以直接使用,无需微调——训练LM-Nav不需要对机器人导航数据进行人工注释。我们展示了LM-Nav能够在复杂的郊区环境中成功跟随自然语言指令,在数百米的行程中,通过细粒度的命令消除路径歧义。
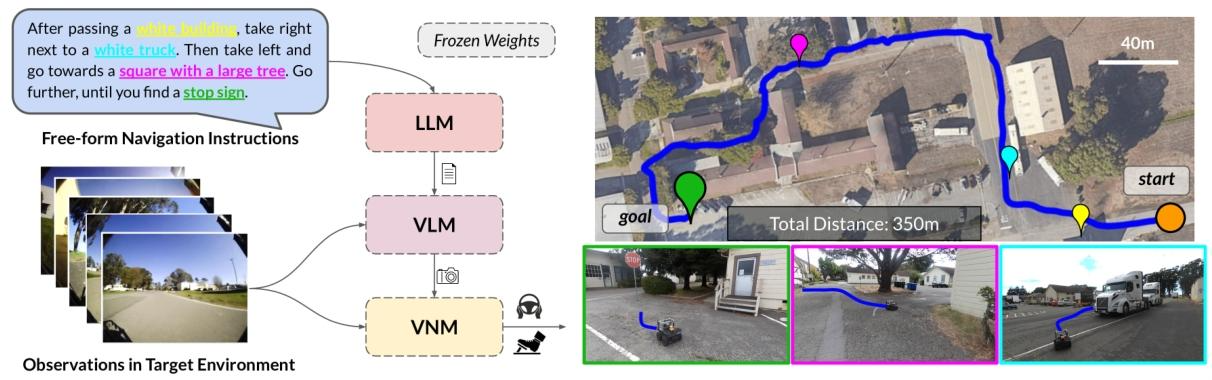
图1:使用LM-Nav进行具身指令跟随:我们的系统将来自目标环境的一组原始观察数据和自由形式的文本指令作为输入(左图),利用三个预训练模型生成可执行的计划:一个用于提取地标的大语言模型(LLM)、一个用于定位的视觉 - 语言模型(VLM)以及一个用于执行的视觉导航模型(VNM)。这使得LM-Nav能够仅从视觉观察中在复杂环境中遵循文本指令(右图),且无需任何微调。
这张图展示了LM - Nav(Large Model Navigation)系统的工作流程及一个实际导航示例。
左侧部分
自由形式导航指令(Free - form Navigation Instructions:给出了一段自然语言导航指令“After passing a white building, take right next to a white truck. Then take left and go towards a square with a large tree. Go further, until you find a stop sign.” ,即经过一栋白色建筑后,在一辆白色卡车旁右转,然后左转,前往有一棵大树的广场,继续前进,直到看到停车标志。
目标环境中的观察(Observations in Target Environment:展示了一系列目标环境中的图像,代表机器人在环境中获取的视觉观察信息。
模型模块:
大语言模型(LLM,Large Language Model ):接收自由形式导航指令,负责将指令解析为地标列表 。
视觉 - 语言模型(VLM,Vision - Language Model) :结合LLM输出和目标环境中的观察图像,推断文本地标和图像观察之间的关联 。
视觉导航模型(VNM,Vision Navigation Model ):利用VLM的输出和图像信息,为机器人规划并执行导航路径。并且图中注明这些模型的权重都是固定的(Frozen Weights),即无需在目标环境中微调。
右侧部分
地图及导航路径:展示了实际环境的鸟瞰图,标注了起始点(start,橙色圆点 )和目标点(goal,绿色圆点 ),蓝色线条表示机器人实际行驶的导航路径,总距离为350米。
地标定位及机器人行驶图像:鸟瞰图上用不同颜色的图钉标记了几个地标位置,下方对应的小图展示了机器人在这些地标位置附近行驶的实际场景,分别对应指令中的地标,如停车标志(绿色框 )、大树所在广场(粉色框 )、白色卡车(蓝色框 ) 。
2 相关工作
早期用自然语言命令增强导航策略的工作使用统计机器翻译[14]来发现数据驱动的模式,将自由形式的命令映射到由语法定义的形式语言[15-19]。然而,这些方法往往在结构化状态空间中运行。我们的工作受到了将此任务简化为序列预测问题的方法的启发[1, 20, 21]。值得注意的是,我们的目标与视觉语言导航(VLN)的任务类似——利用细粒度的指令仅从视觉观察中控制移动机器人[1, 2]。
然而,最近大多数VLN方法使用大量模拟轨迹数据集(超过100万个演示),这些数据集在室内[1, 3-5, 22]和驾驶场景[23-28]中都带有细粒度的语言标签注释,并依赖于从模拟到现实的迁移,以便在简单的室内环境中部署[29, 30]。然而,这需要构建一个与目标环境相似的逼真模拟器,这对于非结构化环境来说可能具有挑战性,特别是对于户外导航任务。相比之下,LM-Nav利用自由形式的文本指令在复杂的户外环境中导航机器人,而无需访问任何模拟数据或任何轨迹级别的注释。
最近,在各种数据上训练的大规模自然语言和图像模型取得了进展,这使得它们在各种文本[31-33]、视觉[13, 34-38]和具身领域[39-44]都有应用。在后一类中,Shridhar等人[39]、Khandelwal等人[44]和Jang等人[40]在带有语言标签的机器人数据上微调预训练模型的嵌入,Huang等人[41]假设低级智能体可以执行文本指令(未涉及控制问题),Ahn等人[42]假设机器人具有一组可以跟随原子文本命令的文本条件技能。所有这些方法都需要访问能够跟随基本文本命令的低级技能,这反过来又需要对机器人的经验进行语言注释,并对机器人的能力有很强的假设。相比之下,我们将这些预训练的视觉和语言模型与不使用任何语言注释的预训练视觉策略相结合[11, 45],并且在目标环境中或针对VLN任务时无需对这些模型进行微调。
基于视觉的移动机器人导航的数据驱动方法通常使用逼真的模拟器[46-49]或监督数据收集[50],直接从原始观察中学习到达目标的策略。导航的自我监督方法[6-11, 51]则可以通过使用车载传感器自动生成标签和事后重标记,使用无标签的轨迹数据集。值得注意的是,这样的策略可以在大量不同的数据集上进行训练,并泛化到以前未见过的环境[45, 52]。由于是自我监督的,这样的策略擅长导航到由GPS位置或图像指定的期望目标,但无法解析高级指令,如自由形式的文本。LM-Nav使用在大量先前环境中训练的自我监督策略,并通过预训练的视觉和语言模型来解析自然语言指令,然后在新颖的现实世界环境中部署,无需任何微调。
3 预备知识
LM-Nav由三个大型预训练模型组成,分别用于处理语言、关联图像与语言以及视觉导航。
大语言模型是基于Transformer架构[53]的生成模型,在大量互联网文本语料库上进行训练。LM-Nav使用GPT-3大语言模型[12],将文本指令解析为一系列地标。
视觉 - 语言模型是指能够关联图像和文本的模型,例如图像字幕生成、视觉问答等[54-56]。我们使用CLIP视觉 - 语言模型[13],该模型将图像和文本联合编码到一个嵌入空间中(这个可以做多模态的融合),使其能够确定某个字符串与给定图像关联的可能性。我们可以联合编码从大语言模型获得的一组地标描述\(t\)和一组图像\(i_{k}\),以获得它们的视觉 - 语言模型嵌入\(\{T, I_{k}\}\)(见图3)。计算这些嵌入之间的余弦相似度,然后进行softmax操作,得到概率\(P(i_{k} | t)\),该概率对应于图像\(i_{k}\)与字符串\(t\)对应的可能性。LM-Nav使用这个概率来对齐地标描述和图像。
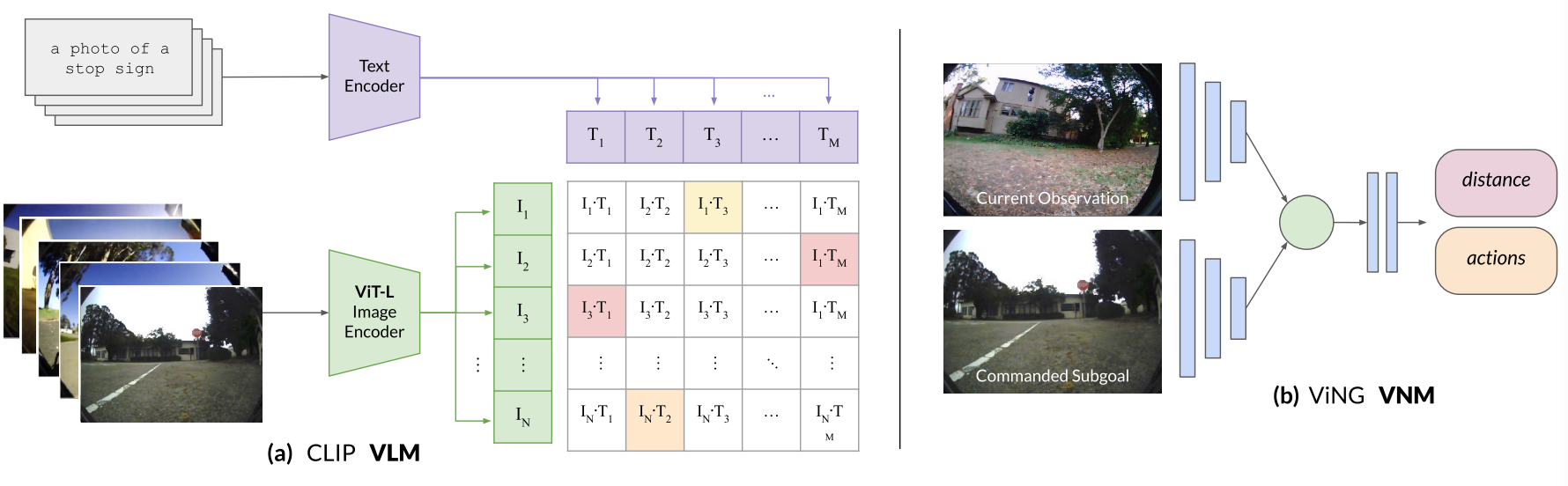
图2:LM-Nav使用视觉 - 语言模型推断文本地标和图像观察之间的联合概率分布。视觉导航模型构成了一个基于图像的距离函数和策略,可以控制机器人。
这张图片展示了两个模型的工作原理,分别是CLIP视觉 - 语言模型(VLM)和ViNG视觉导航模型(VNM)。
左侧(a)CLIP VLM
输入:
文本输入:“a photo of a stop sign”(一张停车标志的照片),通过“Text Encoder”(文本编码器)进行编码。
图像输入:一组不同的图像,通过“ViT - L Image Encoder”(基于Vision Transformer - Large的图像编码器 )进行编码。
编码与计算:
文本编码器将文本编码为特征向量\(T_{i}\)(\(i = 1,2,\cdots,N\) ),图像编码器将图像编码为特征向量\(I_{j}\)(\(j = 1,2,\cdots,M\) )。
然后计算图像特征向量和文本特征向量之间的点积\(I_{j}^{T}T_{i}\) ,形成一个矩阵,矩阵中的每个元素表示某一图像特征与某一文本特征的关联程度,用于衡量图像和文本之间的相似性或对应概率 。
右侧(b)ViNG VNM
输入:
当前观察(Current Observation):机器人当前获取的环境图像信息。
指令子目标(Commanded Subgoal):给定的导航子目标相关信息。
处理与输出:
这些输入信息经过模型处理(图中用几个模块表示处理过程 )。
最终输出两个结果:“distance”(距离),表示当前位置与目标位置的距离估计;“actions”(动作 ),即机器人为了接近目标应该执行的动作 。
视觉导航模型直接从视觉观察中学习导航行为和导航可供性[11, 51, 57-59],通过时间关联图像和动作。我们使用ViNG视觉导航模型[11],这是一个目标条件模型,它预测图像对之间的时间距离以及相应要执行的动作(见图3)。这提供了图像和实体之间的接口。视觉导航模型有两个作用:(i)给定目标环境中的一组观察,视觉导航模型的距离预测可以用于构建一个拓扑图\(G(V, E)\),该图代表了环境的 “心智地图”;(ii)给定一个 “行走路径”,即由一系列连接到目标节点的子目标组成,视觉导航模型可以沿着这个计划导航机器人。拓扑图\(G\)是一个重要的抽象概念,它为在环境中基于过去的经验进行规划提供了一个简单的接口,并且在先前的工作中已成功用于执行长距离导航[52, 60, 61]。为了推断图\(G\)中的连通性,我们结合了学习到的距离估计、时间接近度(在数据收集期间)和空间接近度(使用GPS测量)。对于每一对连接的顶点\(\{v_{i}, v_{j}\}\),我们将这个距离估计分配给相应的边权重\(D(v_{i}, v_{j})\)。关于这个图的构建的更多细节,请参见附录B。
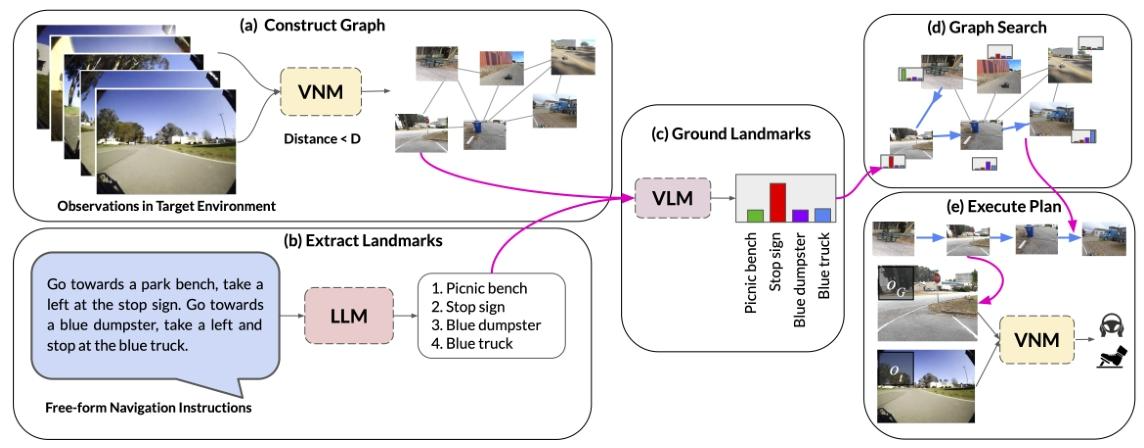
图3:系统概述:(a)视觉导航模型使用目标条件距离函数推断原始观察集之间的连通性,并构建一个拓扑图。(b)大语言模型将自然语言指令转换为一系列文本地标。(c)视觉 - 语言模型推断地标描述和图中节点之间的联合概率分布,(d)图搜索算法使用该分布得出通过图的最优行走路径。(e)机器人使用视觉导航模型策略在现实世界中沿着行走路径行驶。
这张图展示了LM-Nav系统基于自由形式导航指令进行机器人导航的工作流程,主要分为以下几个步骤:
a)构建图(Construct Graph)
输入为目标环境中的观察图像(Observations in Target Environment) 。
利用视觉导航模型(VNM),根据图像间的距离关系(Distance < D ),推断原始观察集之间的连通性,构建一个拓扑图。图中展示了不同图像节点以及它们之间的连接关系。
b)提取地标(Extract Landmarks)
输入是自由形式的导航指令(Freeform-Navigation Instructions),例如“Go towards a park bench, take a left at the stop sign. Go towards a blue dumpster, take a left and stop at the blue truck.” 。
通过大语言模型(LLM)对指令进行解析,提取出一系列地标,如图中所示的“1. Picnic bench 2. Stop sign 3. Blue dumpster 4. Blue truck” 。
c)定位地标(Ground Landmarks)
将步骤(a)中构建的图和步骤(b)中提取的地标,输入到视觉-语言模型(VLM) 。
VLM推断文本地标和图中节点之间的联合概率分布,确定每个地标在图中的对应位置或可能性,图中以不同颜色的柱状图表示不同地标对应的概率情况。
d)图搜索(Graph Search)
基于步骤(c)中VLM得到的地标与图节点的关联信息,在构建好的拓扑图中进行搜索 。
通过搜索算法寻找一条最优的行走路径,这条路径既要符合指令要求,又要最小化遍历成本。图中展示了在图节点间搜索路径的过程。
e)执行计划(Execute Plan)
将步骤(d)中找到的最优行走路径输入到视觉导航模型(VNM) 。
VNM根据路径信息生成相应动作,控制机器人在现实世界中沿着该路径行驶,实现导航任务。图中展示了机器人按照规划路径移动的过程。
4 LM-Nav:使用预训练模型的指令跟随
LM-Nav结合了前面讨论的组件,以在现实世界中跟随文本指令。大语言模型将自由形式的指令解析为地标列表\(\bar{\ell}\)(4.2节),视觉-语言模型通过估计每个节点\(\bar{v}\)与每个\(\bar{\ell}\)对应的概率\(P(\bar{v} | \bar{\ell})\),将这些地标与图中的节点相关联(4.3节),然后视觉导航模型用于推断机器人在图中每对节点之间导航的有效性,我们将其转换为从估计的时间距离得出的概率\(P(\overline{v_{i}, v_{j}})\)。为了找到图上既(i)符合提供的指令,又(ii)最小化遍历成本的最优 “行走路径”,我们推导了一个概率目标(4.1节),并展示了如何使用图搜索算法对其进行优化(4.4节)。然后,这个最优行走路径在现实世界中通过使用视觉导航模型生成的动作来执行。
4.1 问题公式化
给定大语言模型从语言命令中提取的一系列地标描述\(\bar{\ell}=\ell_{1}, \ell_{2}, ..., \ell_{n}\),我们的方法需要确定一系列要发送给机器人的路标点\(\bar{v}=v_{1}, v_{2}, ..., v_{k}\)(通常,\(k ≥n\),因为每个地标都需要被访问,但在遍历过程中可能还需要经过地标之间的其他路标点)。我们可以将其表述为一个概率推断问题。这个表述中的一个关键元素是对于每个图顶点\(v_{\bar{z}}\)和地标描述\(\ell_{j}\),能够访问分布\(p(v_{i} | \ell_{j})\)。回想一下,图顶点对应于机器人观察到的图像,因此,\(p(v_{i} | \ell_{i})\)表示给定语言描述时图像的分布。这可以直接从视觉 - 语言模型中获得。直观地说,我们为了确定机器人的计划而需要优化的完整似然性现在将取决于两个项:形式为\(p(v_{t_{i}} | \ell_{i})\)的似然性,它描述了对于一个分配\(t_{1}, t_{2}, ..., t_{n}\),\(v_{t_{i}}\)与\(\ell_{i}\)对应的可能性;以及可遍历性似然性\(p(\overline{v_{i}, v_{i+1}})\),它描述了机器人从\(v_{i}\)到达\(v_{i+1}\)的可能性,这可以通过视觉导航模型确定。
虽然我们可以使用多种可遍历性似然函数,但一个简单的选择是使用折扣马尔可夫模型,其中折扣因子\(\gamma\)模拟了每个时间步的退出概率,导致每个步骤的终止概率为\(1-\gamma\),到达\(v_{i+1}\)的概率由\(\gamma^{D(v_{i}, v_{i+1})}\)给出,其中\(D(v_{i}, v_{i+1})\)是机器人从\(v_{i}\)到\(v_{i+1}\)所需的估计时间步数,由视觉导航模型预测。虽然也可以使用其他可遍历性似然性,但这个选择是目标条件强化学习公式[62, 63]的一个方便结果,因此,对数似然对应于\(D(v_{i}, v_{i+1})\)。我们可以使用这些似然性来推导给定序列\(\bar{v}\)可以成功遍历的概率,我们用辅助伯努利随机变量\(c_{\bar{v}}\)表示(即,\(c_{\bar{v}} = 1\)意味着\(\bar{v}\)被成功遍历):
\[P\left(c_{\overline{v}}=1 | \overline{v}\right)=\prod_{1 \leq i<T} P\left(\overline{v_{i}, v_{i+1}}\right)=\prod_{1 \leq i<T} \gamma^{D\left(v_{i}, v_{i+1}\right)}\]
然后,用于规划的完整似然性由下式给出:
\[P(success | \overline{v}, \overline{\ell}) \propto P\left(c_{\overline{v}}=1 | \overline{v}\right) P(\overline{v} | \overline{\ell})=\prod_{1 \leq j<k} \gamma^{D\left(v_{j}, v_{j+1}\right)} \max _{1 \leq t_{1} \leq \ldots \leq t_{n} \leq k} \prod_{1 \leq i \leq n} P\left(v_{t_{i}} | \ell_{i}\right)\]
4.2 解析自由形式的文本指令
用户使用自然语言指定他们希望机器人采取的路线,而上面的目标是根据一系列期望的地标来定义的。为了从用户的自然语言指令中提取这个序列,我们使用一个标准的大语言模型,在我们的原型中是GPT-3[12]。我们使用了一个包含3个正确地标提取示例的提示,然后是要由大语言模型翻译的描述。这种方法在我们测试的指令上有效。指令示例以及模型提取的地标可以在图4中找到。对于更细致的情况,需要适当选择提示,包括这3个示例。关于 “提示工程” 的详细信息,请参见附录A。
4.3 视觉定位地标描述
如4.1节所述,选择通过图的行走路径的一个关键元素是计算\(P(v_{i} | \ell_{j})\),即地标描述\(v_{i}\)指的是节点\(\ell_{j}\)的概率(见公式2)。由于每个节点都包含在初始数据收集期间拍摄的图像,因此可以使用CLIP[13]按照3节中描述的检索任务的方式来计算概率。如图2所示,我们将CLIP应用于节点\(v_{i}\)处的图像和形式为 “这是一张[\(\ell_{j}\)]的照片” 的字幕提示。为了将CLIP模型的输出(即logits)转换为概率,我们使用\(P(v_{i} | \ell_{j})=\frac{\exp CLIP(v_{i}, \ell_{j})}{\sum_{v \in V} \exp CLIP(v, \ell_{j})}\)。得到的概率\(P(v_{i} | \ell_{j})\)以及推断出的边的距离将用于选择最优行走路径。
4.4 图搜索最优行走路径
如4.1节所述,LM-Nav旨在找到一个行走路径\(\bar{v}=(v_{1}, v_{2}, \ldots, v_{k})\),该路径最大化遵循给定地标列表\(\bar{\ell}\)成功执行\(\bar{v}\)的概率。我们可以为单调递增的索引序列\(\bar{t}=(t_{1}, t_{2}, \ldots, t_{n})\)定义一个函数\(R(\bar{v}, \bar{t})\):
\[R(\overline{v}, \overline{t}):=\sum_{i=1}^{n} CLIP\left(v_{t_{i}}, \ell_{i}\right)-\alpha \sum_{j=1}^{T-1} D\left(v_{j}, v_{j+1}\right), \text{其中} \alpha=-\log\]
\(R\) 具有这样的性质:\(\bar{v}\) 最大化公式(2)中定义的 \(P(\text{success}|\bar{v},\bar{\ell})\),当且仅当存在 \(\bar{t}\) 使得 \((\bar{v},\bar{t})\) 最大化 \(R\)。为了找到这样的 \((\bar{v},\bar{t})\),我们采用动态规划方法。特别地,我们为 \(i\in\{0,1,\ldots,n\}\),\(v\in V\) 定义一个辅助函数 \(Q(i,v)\):
\[Q(i,v)=\max_{\substack{\bar{v}=(v_1,v_2,\ldots,v_j),v_j = v\\\bar{t}=(t_1,t_2,\ldots,t_i)}}R(\bar{v},\bar{t})\]
\(Q(i,v)\) 表示以 \(v\) 为终点且访问了索引为 \(i\) 之前所有地标的行走路径的 \(R\) 的最大值。基础情况 \(Q(0,v)\) 表示没有访问任何地标,此时 \(R\) 的值等于从起始节点 \(S\) 到 \(v\) 的最短路径长度的相反数。对于 \(i>0\),我们有:
\[Q(i,v)=\max\left(Q(i - 1,v)+CLIP(v,\ell_i),\max_{w\in\text{neighbors}(v)}Q(i,w)-\alpha\cdot D(v,w)\right)\]
动态规划的基础情况是计算 \(Q(0,V)\)。然后,在动态规划的每一步 \(i = 1,2,\ldots,n\) 中,我们计算 \(Q(i,v)\)。这个计算过程类似于迪杰斯特拉算法(Dijkstra algorithm)[64]。在每次迭代中,我们选择 \(Q(i,v)\) 值最大的节点 \(v\),并根据公式(5)更新其邻居节点。算法1总结了这个搜索过程。该算法的结果是一个行走路径 \(\bar{v}=(v_1,v_2,\ldots,v_k)\),它最大化了成功执行指令的概率。这样的行走路径可以由视觉导航模型(VNM)执行,利用其动作估计依次导航到这些节点。
算法1:图搜索
1. 输入:地标(\(\ell_1,\ell_2,\ldots,\ell_n\))
2. 输入:图 \(G(V,E)\)
3. 输入:起始节点 \(S\)
4. 对于所有 \(i = 0,\ldots,n\),\(Q[i,v]=-\infty\),其中 \(v\in V\)
5. \(Q[0,S]=0\)
6. 执行迪杰斯特拉算法(\(G\),\(Q[0, *]\))
7. 对于 \(i\) 从 \(1\) 到 \(n\) 循环:
8. 对于所有 \(v\in V\),\(Q[i,v]=Q[i - 1,v]+CLIP(v,\ell_i)\)
9. 执行迪杰斯特拉算法(\(G\),\(Q[i, *]\))
10. 结束循环
11. 目的地 = \(\arg\max(Q[n, *])\)
12. 返回回溯(目的地,\(Q[n, *]\))
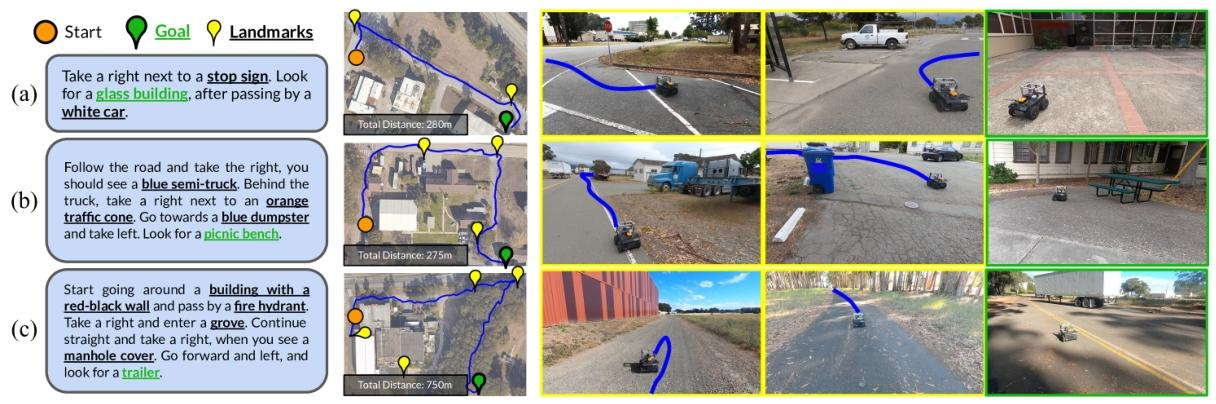
图4:LM-Nav在现实世界环境中执行文本指令的定性示例(左)。大语言模型(LLM)提取的地标(文本中突出显示)由视觉语言模型(VLM)定位到视觉观察中(中;机器人无法获取俯瞰图像)。图的最终行走路径由视觉导航模型(VNM)执行(右)。
5 系统评估
我们现在描述在各种户外场景中部署LM-Nav的实验,使用小型地面机器人跟随高级自然语言指令。在所有实验中,大语言模型(LLM)、视觉语言模型(VLM)和视觉导航模型(VNM)的权重都是固定的——在目标环境中没有进行微调或注释。我们评估整个系统以及LM-Nav的各个组件,以了解其优势和局限性。我们的实验展示了LM-Nav跟随高级指令、消除路径歧义以及到达距离高达800米目标的能力。
5.1 移动机器人平台
我们在Clearpath Jackal无人地面车辆(UGV)平台上实现LM-Nav(见图1(右))。传感器套件包括一个6自由度惯性测量单元(IMU)、一个用于近似定位的GPS单元、用于本地里程计的车轮编码器,以及视野为170°的前向和后向RGB摄像头,用于捕获视觉观察并在拓扑图中进行定位。大语言模型和视觉语言模型的查询在远程工作站上预先计算,计算出的路径通过无线方式发送给机器人。视觉导航模型在板上运行,仅使用前向RGB图像和未过滤的GPS测量数据。
5.2 使用LM-Nav跟随指令
在每个评估环境中,我们首先通过手动驾驶机器人并收集图像和GPS观察数据来构建图。视觉导航模型根据这些数据自动构建图,原则上,这些数据也可以从过去的遍历中获取,甚至可以通过自主探索方法[45]获得。一旦图构建完成,机器人就可以在该环境中执行指令。我们在不同难度的环境中对20个查询进行了测试,总行程长度超过6公里。指令中包括环境中可以从机器人观察中识别的一组显著地标,例如交通锥、建筑物、停车标志等。
图4展示了机器人所走路径的定性示例。请注意,机器人无法获取地标上方的俯瞰图像和空间定位信息,这些仅用于可视化。在图4(a)中,LM-Nav能够成功地从先前的遍历中定位简单地标,并找到一条通往目标的短路径。尽管环境中有多个停车标志,但公式(2)中的目标使机器人能够在上下文中选择正确的停车标志,以最小化总体行驶距离。图4(b)突出了LM-Nav解析包含多个地标以指定路线的复杂指令的能力——尽管存在一条直接到达最终地标但忽略指令的更短路径的可能性,机器人还是找到了一条按正确顺序访问所有地标的路径。
指令歧义消除。由于LM-Nav的目标是跟随指令,而不仅仅是到达最终目标,不同的指令可能会导致不同的遍历路径。图5展示了一个示例,修改指令可以消除通往目标的多条路径的歧义。给定较短的提示(蓝色),LM-Nav更喜欢更直接的路径。当指定更细粒度的路线(品红色)时,LM-Nav会选择一条经过不同地标集的替代路径。
地标缺失。虽然LM-Nav在从指令中解析地标、在图上定位地标以及找到通往目标的路径方面非常有效,但它依赖于地标(i)存在于环境中,以及(ii)可以被视觉语言模型识别的假设。图4(c)说明了一种情况,即执行的路径未能访问其中一个地标——消防栓,而是采取了一条绕过建筑物顶部而不是底部的路径。这种失败模式归因于视觉语言模型无法从机器人的观察中检测到消防栓。在独立评估我们的视觉语言模型检索地标的功效时(见5.4节),我们发现,尽管CLIP是我们任务中最好的现成模型,但它无法检索到少数 “困难” 地标,包括消防栓和水泥搅拌车。在许多实际情况下,机器人仍然能够成功找到一条访问其余地标的路径。
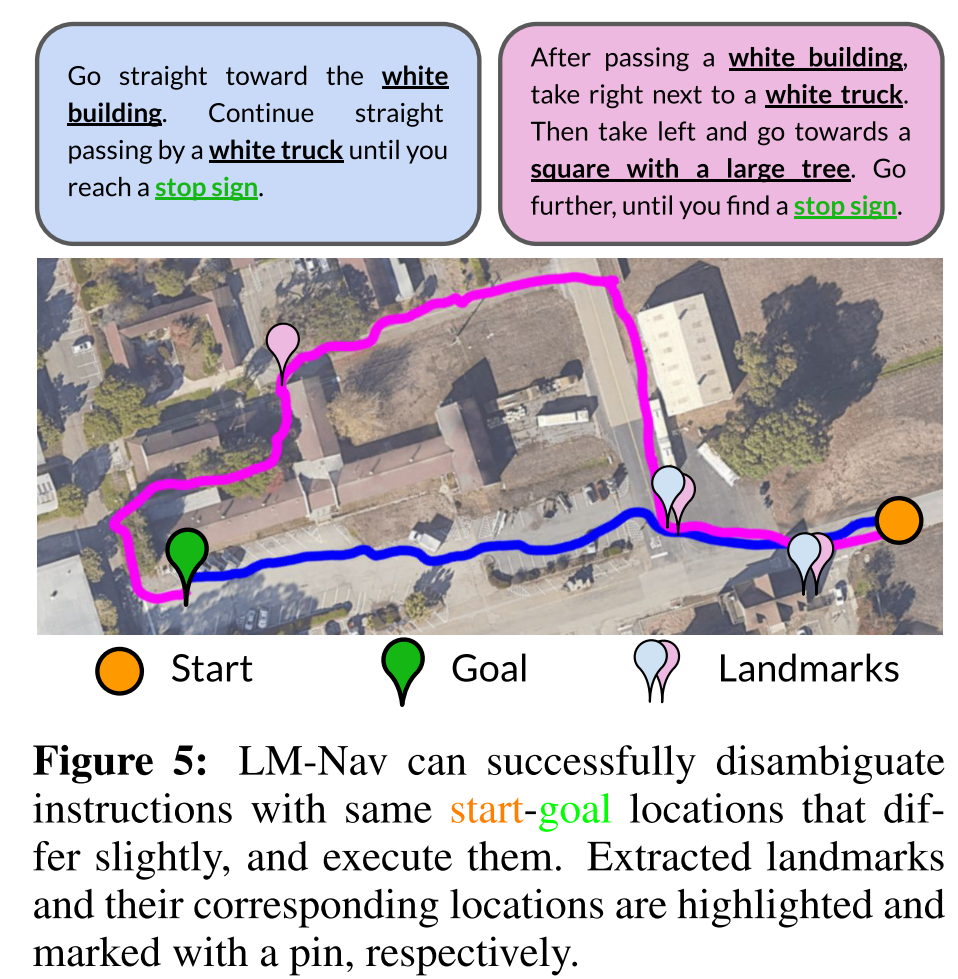
图5:LM-Nav能够成功消除起始 - 目标位置相同但略有不同的指令的歧义,并执行这些指令。提取的地标及其相应位置分别突出显示并用图钉标记。
5.3 定量分析
为了量化LM-Nav的性能,我们引入了一些性能指标。如果图搜索生成的行走路径(1)与用户预期的路径匹配,或者(2)搜索算法提取的地标图像确实包含所述地标(即,即使路径不完全相同,但生成的路径是有效的),则认为该行走路径是成功的。图搜索算法生成的成功行走路径的比例定义为规划成功率。对于在现实世界中成功执行的计划,我们将效率定义为:
\[\min\left(1,\frac{\text{描述路线的长度}}{\text{执行路线的长度}}\right)\]
第二项——对应于执行路线的最优性——在最大值为1处截断,以考虑视觉导航模型偶尔执行比用户预期更短、更直接路径的情况。对于一组查询,我们报告成功实验的平均效率。规划效率的定义类似:
\[\min\left(1,\frac{\text{描述路线的长度}}{\text{规划行走路径的长度}}\right)\]
另一个指标——脱离次数——计算每个实验中由于碰撞或掉下路边等不安全操作所需的平均人工干预次数。
表1总结了系统在20个指令上的定量性能。LM-Nav在85%的实验中能够始终如一地跟随指令,没有碰撞或脱离情况(平均每6.4公里遍历1次干预)。与去除导航模型的基线(见5.4节)相比,LM-Nav在执行高效、无碰撞的目标路径方面表现始终更好。在所有不成功的实验中,失败都可以归因于规划阶段的问题——搜索算法无法在图中视觉定位某些 “困难” 地标,导致指令执行不完整。对这些失败模式的调查表明,我们系统中最关键的组件是视觉语言模型检测不熟悉地标(例如消防栓)的能力,以及在具有挑战性的光照条件下(例如曝光不足的图像)的检测能力。
表1:在20个实验中量化LM-Nav的导航指令跟随性能。LM-Nav能够成功规划通往目标的路径,并在数百米的距离内高效地跟随该路径。去除视觉导航模型(GPS-Nav)会严重损害性能,因为频繁脱离以及无法考虑与障碍物的碰撞。
5.4 剖析LM-Nav
为了了解LM-Nav每个组件的影响,我们进行实验单独评估这些组件。有关这些实验的更多详细信息,请参见附录C。
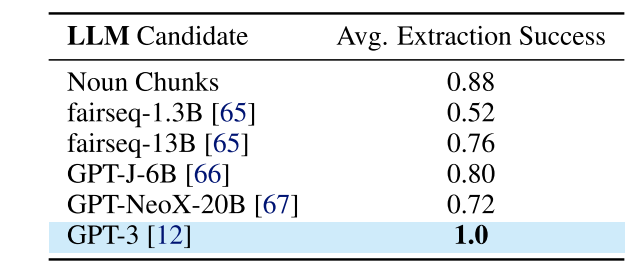
为了评估大语言模型候选者在将指令解析为有序地标列表方面的性能,我们将LM-Nav中使用的GPT-3与其他最先进的预训练语言模型(如fairseq[65]、GPT-J-6B[66]和GPT-NeoX-20B[67])以及使用spaCy自然语言处理库[69]提取基本名词短语并进行过滤的简单基线进行比较。在表2中,我们报告了所有方法在5.3节中使用的20个提示上的平均提取成功率。GPT-3由于其卓越的表示能力和上下文学习能力[70],显著优于其他模型。名词短语提取的表现出人意料地可靠,能够正确解决许多简单提示。有关这些实验的更多详细信息,请参见附录C.2。
为了评估视觉语言模型将这些文本地标定位到视觉观察中的能力,我们设置了一个目标检测实验。给定机器人车载摄像头的未标记图像和一组文本地标,任务是检索相应的标签。我们在前面讨论的环境中的100张图像和30个常见地标上进行了这个实验。这些地标是我们在5.2节实验中由大语言模型检索到的地标和手动策划的地标的组合。如果前3个预测中的任何一个与图像内容相符,我们就报告检测成功。我们将我们的视觉语言模型(CLIP)的检索成功率与一些可靠的目标检测替代方法进行比较——Faster-RCNN-FPN[68, 71],这是一个在MS-COCO[72, 73]上预训练的最先进目标检测模型,以及ViLD[36],这是一个基于CLIP和Mask-RCNN[74]的开放词汇目标检测器。为了与封闭词汇基线进行评估,我们通过将地标投影到MS-COCO类标签集来修改设置。我们发现CLIP在很大程度上优于基线,这表明其视觉模型能够很好地迁移到机器人观察中(见表3)。尽管ViLD基于CLIP,但在检测复杂地标(如 “井盖” 和 “玻璃建筑”)时仍存在困难。Faster RCNN无法检测到MS-COCO中的常见对象(如 “交通灯”、“人” 和 “停车标志”),这可能是因为车载图像与该模型的训练数据分布不同。
为了了解视觉导航模型的重要性,我们进行了一个去除导航模型的LM-Nav消融实验。使用基于GPS的距离估计和拓扑图节点之间的简单直线控制器。表1总结了这些结果——没有视觉导航模型考虑障碍物和可遍历性的能力,系统经常会遇到树木和路边等小障碍物,导致失败。图6说明了这样一种情况——虽然这种控制器在开阔道路上效果很好,但它无法考虑建筑物或障碍物周围的连通性,在三次单独尝试中分别与路边、树木和墙壁发生碰撞。这表明使用从视觉导航模型中学习到的策略和距离函数对于使LM-Nav在复杂环境中无碰撞导航至关重要。

图6:GPS-Nav(红色)由于无法考虑通过障碍物的可遍历性而无法执行计划,而LM-Nav(蓝色)成功执行。
最后,为了了解图搜索目标(公式(3))中两个组件的重要性,我们进行了一组消融实验,其中图搜索仅依赖于 \(P_{l}\),即最大似然规划,它只选择每个地标最可能的节点,而不考虑它们的相对拓扑位置和可遍历性。表4显示,这种规划器在效率方面表现很差,因为它没有利用节点的空间组织及其连通性。有关这些实验的更多详细信息和定性示例,请参见附录C。
6 讨论
我们提出了大型模型导航(Large Model Navigation,LM-Nav),这是一个用于从文本指令进行机器人导航的系统,它可以控制移动机器人,而无需任何导航数据的用户注释。LM-Nav结合了三个预训练模型:大语言模型将用户指令解析为地标列表;视觉语言模型估计从环境先前探索构建的 “心智地图” 中的每个观察与这些地标的匹配概率;视觉导航模型估计导航可供性(地标之间的距离)和机器人动作。每个模型都在其自己的数据集上进行预训练,我们展示了整个系统可以在现实世界的户外环境中执行各种用户指定的指令——通过语言和空间上下文的结合选择正确的地标序列——并处理错误(如地标缺失)。我们还分析了每个预训练模型对整个系统的影响。
局限性和未来工作。LM-Nav最突出的局限性是它对地标依赖:虽然用户可以指定任何他们想要的指令,但LM-Nav只关注地标,而忽略任何动词或其他命令(例如,“直走三个街区” 或 “慢慢开过那只狗”)。对动词和其他细微命令进行定位是未来工作的一个重要方向。此外,LM-Nav使用的视觉导航模型是特定于使用Clearpath Jackal机器人进行户外导航的。未来工作的一个令人兴奋的方向是设计一个更通用的 “大型导航模型”,可以广泛应用于任何机器人,类似于大语言模型和视觉语言模型处理任何文本或图像的方式。然而,我们相信,以其目前的形式,LM-Nav为如何结合预训练模型来解决复杂的机器人任务提供了一个简单而有吸引力的原型,并说明了这些模型可以作为与未经任何语言注释训练的机器人控制器的 “接口”。这个结果的一个意义是,自我监督机器人策略(例如,目标条件策略)的进一步进展可以直接使指令跟随系统受益。更广泛地说,理解现代预训练模型如何实现机器人控制的有效分解,可能会在未来实现广泛可泛化的系统,我们希望我们的工作将朝着这个方向迈出一步。
附录
A 提示工程
为了将大语言模型用于特定任务,而不是一般的文本完成,需要将任务编码为模型文本输入的一部分。创建这种编码有很多方法,这种表示优化的过程有时被称为提示工程[13]。在本节中,我们讨论用于大语言模型和视觉语言模型的提示。
A.1 大语言模型提示工程
我们所有的实验都使用GPT-3[12]作为大语言模型,可通过OpenAI的API访问:https://openai.com/api/。我们使用这个模型从自由形式的指令中提取地标列表。该模型的输出非常可靠,并且对输入提示的小变化具有很强的鲁棒性。对于解析简单查询,GPT-3在使用单个零样本提示时出奇地有效。见下面的例子,模型输出部分被突出显示:
- 首先,你需要找到一个停车标志。然后向左转再向右转,一直走到一个有树的广场。
- 继续直走,然后右转,直到找到一辆白色卡车。最终目的地是一座白色建筑物。
- 地标:
1. 停车标志
2. 有树的广场
3. 白色卡车
4. 白色建筑物
虽然这个提示对于简单指令已经足够,但更复杂的指令需要模型对重新排序等情况进行推理,例如 “在经过一辆白色汽车后寻找一座玻璃建筑”。我们利用GPT-3的上下文学习能力[70],在提示中添加三个示例:
- 在雕像旁边右转后寻找一个图书馆。地标:
1. 一座雕像
2. 一个图书馆
- 寻找一座雕像。然后寻找一个图书馆。然后前往一座粉色房子。地标:
1. 一座雕像
2. 一个图书馆
3. 一座粉色房子
- 地标:[指令]
我们在所有实验(5.2节、5.3节)中都使用上述提示,GPT-3成功地提取了所有地标。与其他提取方法的比较在5.4节和附录C.2中描述。
A.2 视觉语言模型提示工程
对于我们的视觉语言模型——CLIP[13],我们使用一组简单的提示:“这是一张 的照片”,后面加上地标描述。这个简单的提示足以检测出我们实验中遇到的95%以上的地标。虽然我们的实验不需要更精细的提示工程,但Radford等人[13]和Zeng等人[43]报告说,使用一组略有变化的提示的集合可以提高鲁棒性。
B 使用视觉导航模型构建拓扑图
本节概述了使用视觉导航模型构建拓扑图的更详细信息。我们结合学习到的距离估计(来自视觉导航模型)、空间接近度(来自GPS)和时间接近度(在数据收集期间)来推断边的连通性。如果两个

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









