






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
模拟风电不确定性的拉丁超立方抽样生成及缩减场景研究
拉丁超立方抽样(Latin Hypercube Sampling, LHS)作为一种统计抽样技术,广泛应用于不确定性分析和风电模拟领域。该方法通过高效生成样本空间内的代表点,能够有效模拟和研究风电输出的不确定性。下面,我们将通过几个步骤解释如何使用拉丁超立方抽样(LHS)来模拟风电的不确定性,并介绍场景缩减技术以提高计算效率。
一、研究背景与核心问题
风电出力受风速随机性、预测误差等因素影响,具有显著的不确定性。为量化这种不确定性,需通过场景分析法生成大量可能的风电出力场景,并缩减为典型场景集,以优化电力系统规划和运行。拉丁超立方抽样(Latin Hypercube Sampling, LHS)因其分层抽样特性,能够高效覆盖样本空间,成为风电不确定性模拟的核心方法。
二、拉丁超立方抽样的基本原理
1. 与蒙特卡洛抽样的对比
- 蒙特卡洛:简单随机抽样,样本易聚集,需大量样本才能覆盖分布范围,计算成本高。
- 拉丁超立方:分层抽样,将变量范围划分为等概率区间,每个区间仅抽取一个样本,保证均匀覆盖。相比蒙特卡洛,LHS能以更少样本准确反映分布特性,减少计算时间和存储需求。
2. LHS的数学步骤
- 分层划分:将预测误差的概率分布分为NN个等概率区间(如正态分布分为N=1000N=1000个区间)。
- 区间内采样:对每个区间随机抽取一点
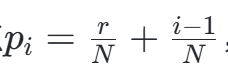 ,其中r∈[0,1]为随机数。
,其中r∈[0,1]为随机数。 - 反函数变换:通过累积分布函数(CDF)的反函数F−1(pi)生成服从目标分布的样本值。
- 随机排列:对各维样本独立排序后组合,避免维度间相关性导致的偏差。
三、风电不确定性建模与场景生成
1. 预测误差分布假设

2. 场景生成参数设置
- 典型参数:时间周期Z=24Z=24小时,抽样次数iterations=1000iterations=1000,代表性场景数S=5S=5(缩减后)。
- 多维扩展:考虑多风电场相关性时,采用Sobol序列增强的LHS(SaLHS)或Copula函数处理时空相关性。
四、场景缩减技术
1. 主要方法分类
| 方法类型 | 算法示例 | 特点与适用场景 |
|---|---|---|
| 概率距离法 | 快速前代消除法(FFS) | 基于Kantorovich距离,合并概率相近场景 |
| 聚类法 | K-means | 按几何相似性聚类,保留簇中心作为典型场景 |
| 同步回代法 | SBR | 迭代合并最小概率距离的场景,全局最优性高 |
| 混合方法 | K-means + SBR | 结合聚类和概率距离,兼顾效率与精度 |
2. 改进方向
- 三维距离度量:在SBR中引入相关性、量级和形态的三维距离,提升相似性评估全面性。
- 趋势拟合:提取场景的时间趋势特征,减少随机噪声干扰,适用于风资源分析。
五、案例分析与应用
1. 综合能源系统调度
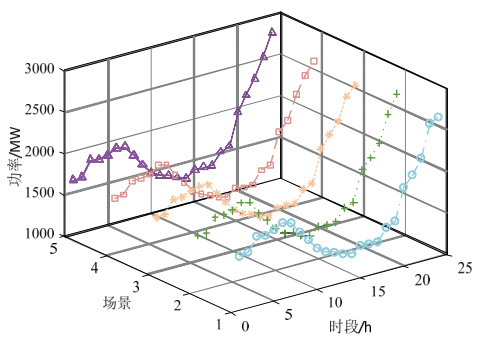
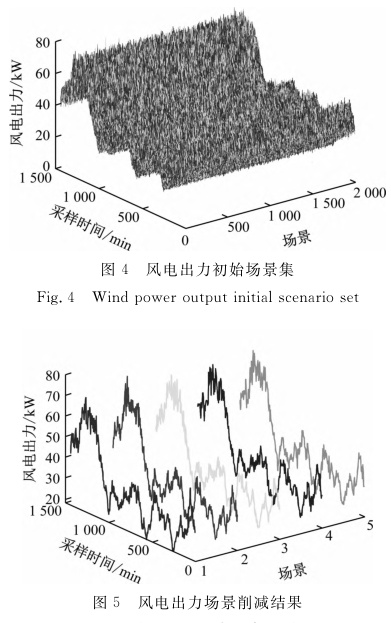
- 场景生成:基于LHS生成1000个风电出力场景,假设服从正态分布,缩减至5个典型场景(图C3)。
- 优化效果:典型场景覆盖实际出力波动范围,支撑系统低碳经济调度。
2. 风储混合系统优化
- 风速建模:ARMA模型预测风速,LHS生成误差场景,缩减后得到有限出力场景及概率。
- 结果验证:LHS场景分布均匀,显著优于蒙特卡洛的样本聚集问题(图3 vs. 图2)。
六、研究进展与挑战
- 多维度相关性处理:SaLHS结合D-vine Copula,提升多风电场时空相关性建模精度。
- 问题驱动缩减:将随机优化目标融入场景缩减,通过MILP最小化优化差距。
- 评估指标创新:引入覆盖性指标(PA、PB)和形态相似性度量,量化场景代表性。
七、核心复现文档撰写规范
- 方法描述:明确分布假设(如正态分布参数σ=10%Pforecastσ=10%Pforecast)、LHS分层步骤、缩减算法(如SBR迭代过程)。
- 代码与数据:提供Matlab/Python代码(含注释)、输入数据格式(如24小时预测值)、关键参数设置(如N=1000N=1000)。
- 可复现性:附数据集、反函数计算细节(如威布尔参数c,kc,k公式)及缩减过程日志文件。
- 结果对比:展示初始场景与缩减场景的分布对比图(如2000→5场景),量化覆盖性指标。
八、结论
拉丁超立方抽样结合场景缩减技术,为风电不确定性建模提供了高效解决方案。未来研究需进一步探索多维相关性建模、动态趋势适应性及与优化模型的深度耦合。复现研究需注重方法透明性、代码可读性及结果验证,以支撑电力系统的高效决策。
📚2 运行结果
研究表明,风电出力的不确定性主要源于预测误差。据分析,这种误差(通常用符号 e 表示)服从正态分布,并且大致相当于预测出力的10%。为了更好地理解和应对这一不确定性,我们采用了拉丁超立方抽样方法实现了场景生成[1],同时借助基于概率距离的快速前代消除法进行了场景缩减[2]。这样的操作使我们能够更有效地模拟风电出力的不确定性,并为相关决策提供更可靠的依据。
2.1 场景生成
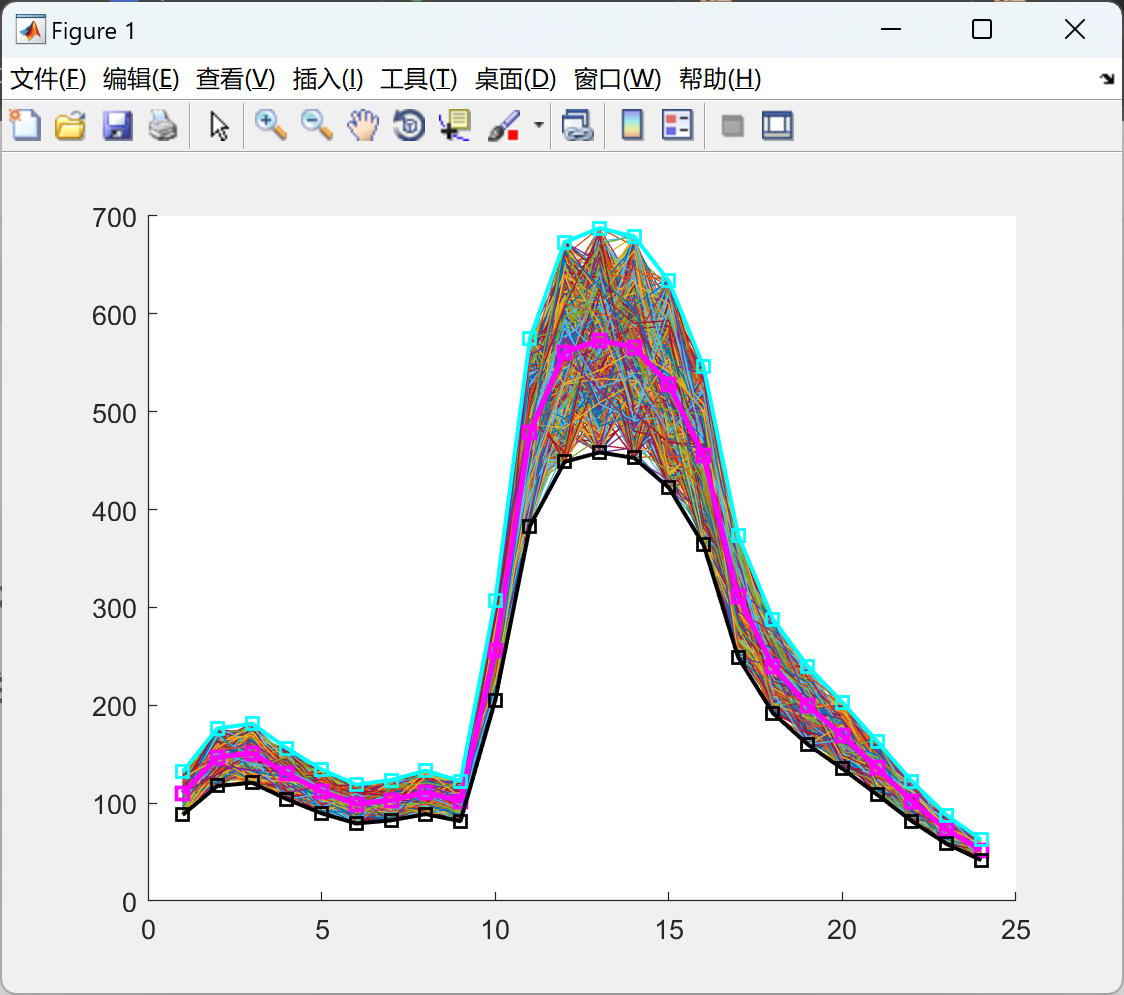
2.2 场景削减
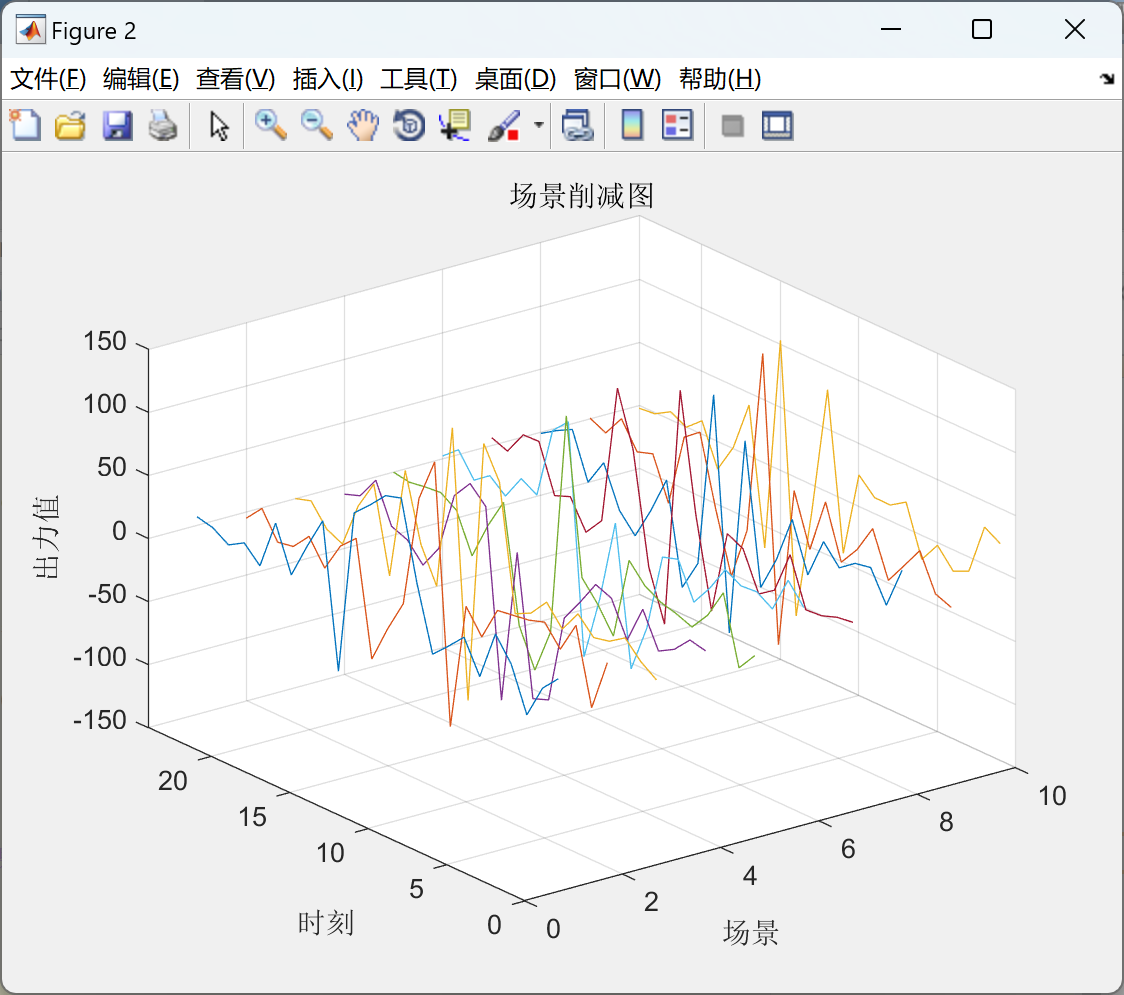
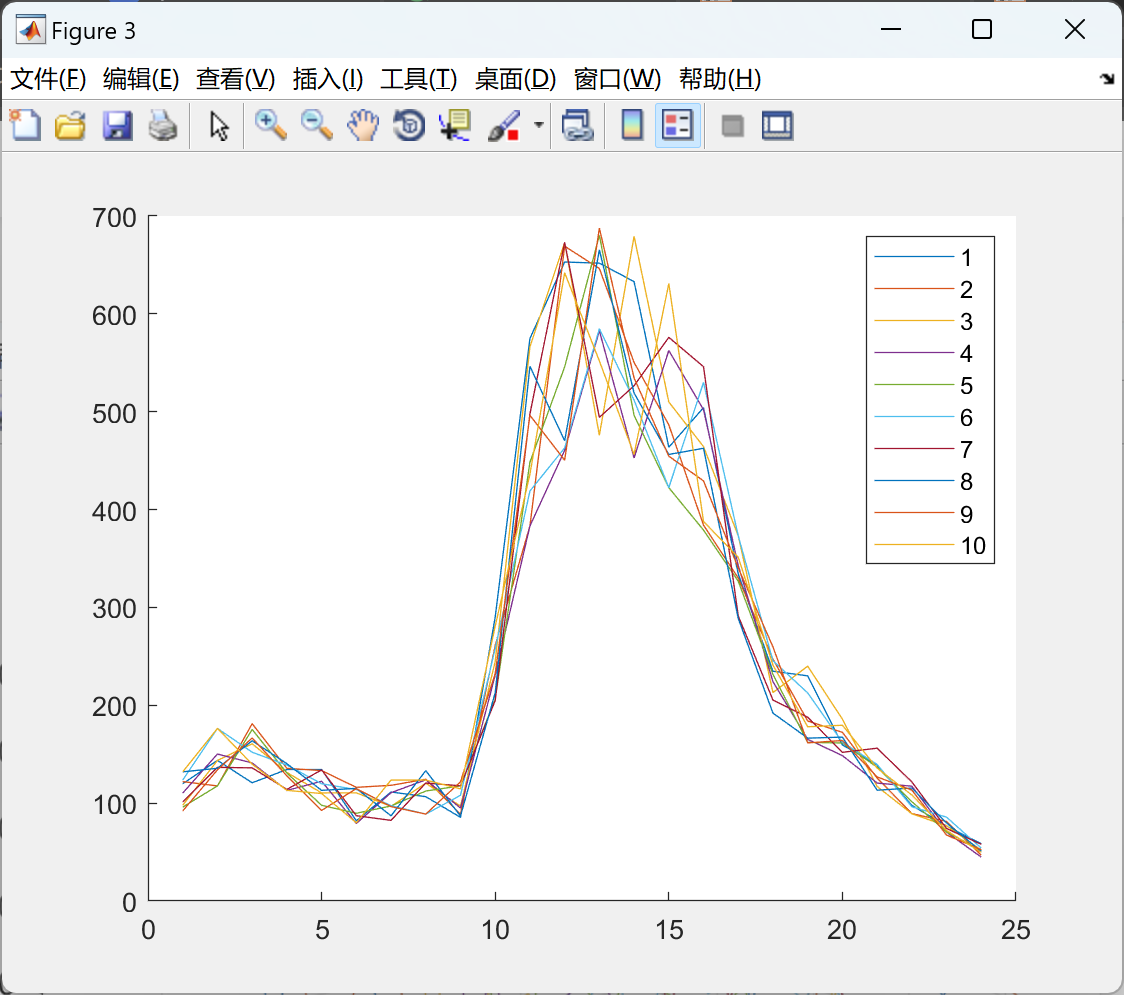
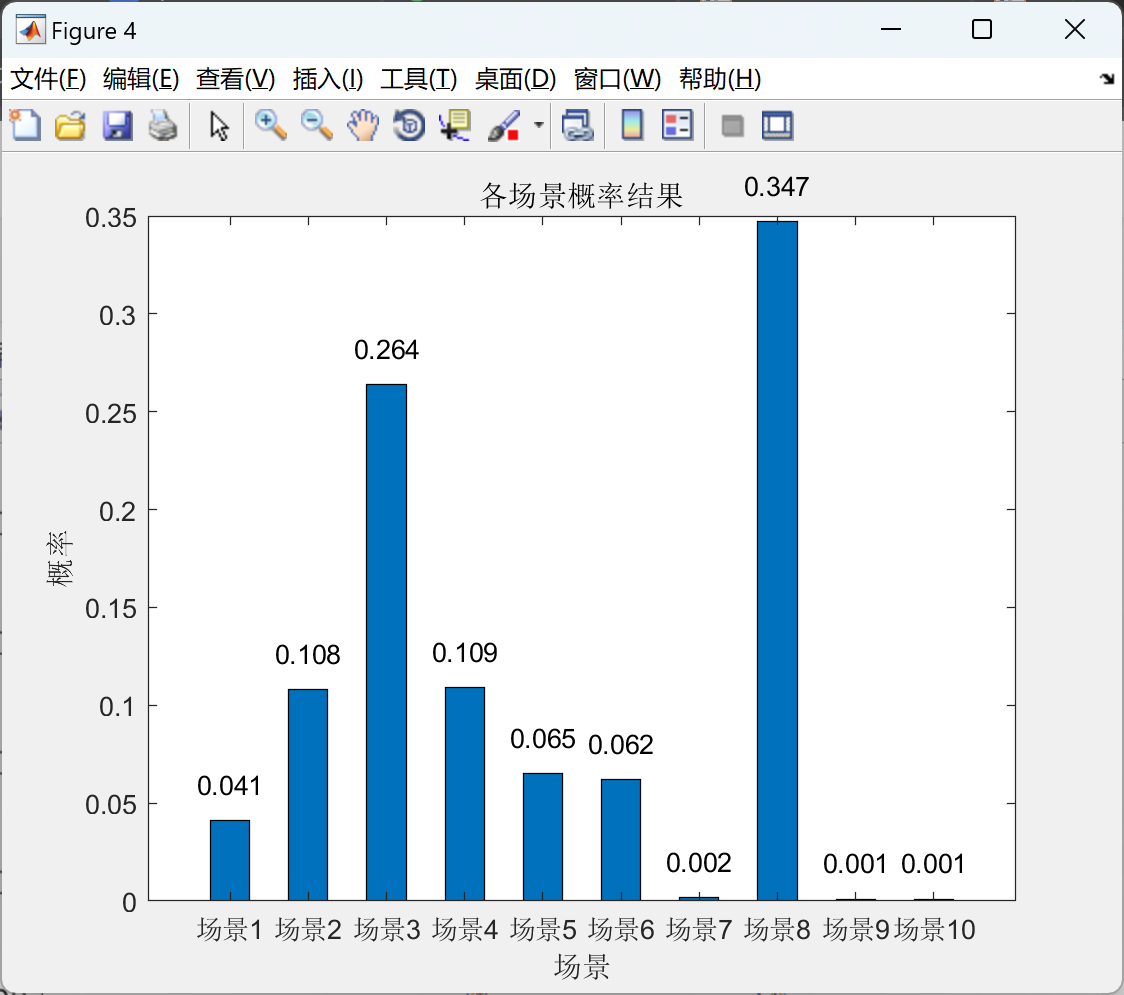
部分代码:
%% 场景生成
% 概率密度函数
y1 = @(x) exp(-(x-mu)^2/(2*sigma^2))/(sigma*(2*pi)^0.5);
% 累计分布函数
CDF = @(x)@(mu)@(sigma) normcdf(x,mu,sigma);
x = leng : 0.1 : leng;
y2 = CDF(x);
% 拉丁超立方抽原始样本
segmentSize = 1 / iterations; % 每层大小
for j = 1:Z
for i = 0 : iterations-1 % 逐层随机抽样
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]蒋程,王硕,王宝庆,等.基于拉丁超立方采样的含风电电力系统的概率可靠性评估[J].电工技术学报,2016,31(10):193-206.DOI:10.19595/j.cnki.1000-6753.tces.2016.10.023.
[2]董文略,王群,杨莉.含风光水的虚拟电厂与配电公司协调调度模型[J].电力系统自动化,2015,39(09):75-81+207.

















 6108
6108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









