






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
摘要
本文研究了离散时间非线性多智能体系统在切换通信拓扑下的共识问题,并采用模型预测控制(MPC)方法进行求解。对于遵循马尔可夫切换规律的系统,现有的MPC解决方案难以基于模型预测获得可靠的优化结果。为此,我们提出了一种新的基于神经网络的算法,通过实时近似和最小化MPC的成本函数,降低通信不足带来的影响。通过不同应用和场景的仿真验证了所提方法的有效性。
摘要
本文研究了离散时间非线性多智能体系统在切换通信拓扑下的共识问题,并采用模型预测控制(MPC)方法进行求解。对于遵循马尔可夫切换规律的系统,现有的MPC解决方案难以基于模型预测获得可靠的优化结果。为此,我们提出了一种新的基于神经网络的算法,通过实时近似和最小化MPC的成本函数,降低通信不足带来的影响。通过不同应用和场景的仿真验证了所提方法的有效性。
研究人员已成功将非线性多智能体系统(MAS)的协同控制应用于广泛的机器人应用领域,例如移动机器人(Han, 2018)、编队飞行(Floriano等,2021)和网络化机械臂(Liu等,2021),仅举几例。协同控制的一个重要研究特性是实现智能体的状态共识。此外,开发能够达成共识的协议需要一个实用的设计,以使所有智能体在其状态上达成一致(例如,Lewis等,2013;Wang等,2020;Ren等,2007)。
根据Li等(2019)的研究,为了达成一致的共识,必须确保可靠的通信系统。然而,在实时实验中,某些物理特性可能会降低通信拓扑的性能,从而在信息交换中产生不确定性(Savino等,2015)。在这种情况下,即使系统受到拓扑切换的影响,共识也应该能够正常工作(Olfati-Saber和Murray,2004)。研究表明,可以使用马尔可夫链来建模这种切换拓扑(Wang等,2020;Gao等,2020;Savino等,2015;Ming等,2016),尽管在切换拓扑是任意的情况下也可以保证达成共识(Valcher和Zorzan,2017;Sakthivel等,2019;Kaviarasan等,2018)。例如,Wang等(2020)研究了一类具有马尔可夫切换拓扑的多智能体系统,但仅限于线性动态。在这种情况下,共识被证明可以通过线性矩阵不等式来实现。在另一项研究中,Gao等(2020)针对具有干扰和非线性的系统取得了类似的成果。他们通过事件触发机制为这类系统提供了达成共识的充分条件。然而,这两项研究的解决方案都是基于离线策略的,可能无法反映运行过程中的未知因素。
与Gao等(2020)类似,其他研究也致力于研究具有切换拓扑的非线性MAS,因为非线性系统在重要的MAS应用中广泛存在。例如,Liu和Huang(2017)为一类受切换拓扑和外部干扰影响的非线性MAS的领导者-跟随者共识问题开发了一种自适应控制技术。尽管它为高阶非线性问题提供了很好的解决方案,但通信切换仍然使用确定性函数建模。另一项相关研究,Zou等(2019)研究了应用于具有非线性动态(包括机械臂)的MAS的随机切换,并成功证明了事件触发机制在无Zeno行为的情况下跟踪领导者的效果。然而,这种切换机制是应用于个体动态,而不是通信拓扑。
由于机器学习算法在处理未知参数方面的灵活性以及其估计非线性函数的显著能力,它们已被用于共识的在线策略(Li等,2020;Zhang等,2017;Zhao等,2017)。例如,Zhang等(2017)使用基于神经网络的自适应动态规划来解决具有未知动态的系统的共识问题。在另一项研究中,Zhao等(2017)为不确定MAS的有限时间共识问题创建了一个自适应神经网络控制器。需要注意的是,这两项研究的系统仅针对固定拓扑建模。相比之下,Li等(2020)考虑了时变拓扑。总之,所有这些研究都仅针对确定性拓扑设计了系统。
在另一方面,随机拓扑使研究人员能够扩展共识在多智能体系统中的应用。例如,基于神经网络的控制器在单智能体系统的马尔可夫跳跃中取得了显著成果。Zhong等(2015)提出了一种基于神经网络优化的自适应动态规划协议的在线系统,用于离散时间非线性马尔可夫跳跃系统(MJS)。在另一项研究中,Yang等(2020)将神经网络应用于容错MJS中的非线性估计。因此,将基于神经网络的方法应用于受随机拓扑影响的MAS是合理的。本文在这方面做出了贡献,详细内容如下。
回顾模型预测控制(MPC)由于其预测特性和在不同工作条件下工作的能力而受到工业应用的欢迎,提供了性能鲁棒性(Cheng等,2015;Han等,2015;McNamara等,2013)。最近,研究人员将MPC的知识扩展到处理神经网络和MAS(Wang等,2015;Chen等,2018;Xiao和Chen,2018)。尽管只有Xiao和Chen(2018)研究了具有切换拓扑的MAS,但共识问题仅针对特定系统(轮式机器人)解决,且拓扑之间的切换被建模为确定性的而非随机的。事实上,据作者所知,文献中没有任何工作将MPC技术应用于具有马尔可夫切换拓扑的非线性MAS的共识协议设计。研究马尔可夫模型的随机效应对基于MPC的MAS的影响特别具有实际应用价值,因为这些模型是表示真实通信不完美(例如断开连接、噪声和干扰,这是当前共识问题中面临的主要挑战)的便捷工具。
本文的主要贡献是展示了一种用于具有马尔可夫切换拓扑的非线性多智能体系统共识问题的新型基于神经网络的模型预测控制。在这种方法中,MPC的成本函数考虑了某个李雅普诺夫函数的期望值,而该函数又考虑了系统的误差。成本函数还权衡了通信拓扑的行为。使用前馈神经网络自适应近似MPC的成本函数,并通过最小化它来获得相应控制问题的解。通过不同系统的仿真来验证协议的有效性,并将其与其他现有方法(例如Wang等,2020;Gao等,2020开发的方法)进行比较。最后,通过在受干扰的系统以及一组四旋翼无人机和机器人汽车中验证所提出的方法,说明了该方法的实际相关性。
总结来说,本文的贡献如下:
• 对于基于MPC协议设计的非线性MAS,本研究扩展了文献中允许的拓扑类别。在这里,允许使用马尔可夫切换拓扑,与Xiao和Chen(2018)的确定性切换拓扑形成对比;
• 通过一种新的基于神经网络的在线算法解决了由随机过程引起的MPC优化难题,该算法减轻了通信故障的影响;
• 通过引入自适应神经网络,所开发的算法推进了Gao等(2020)关于具有随机切换拓扑的非线性多智能体共识的研究,提高了系统应对未知外部变化的能力;
• 由于神经网络的估计特性,所提出的协议可以应用于广泛的非线性系统类别。正如仿真所示,允许的非线性动态类别使我们能够处理重要的实际非线性系统,例如四旋翼无人机和机器人汽车,并涵盖了Xiao和Chen(2018)的工作中考虑的动态(仅限于轮式机器人)以及Gao等(2020)的工作,后者仅限于特定类别的非线性。
本文的结构如下:第2节介绍图论的预备知识并描述要解决的问题;第3节提出基于MPC和神经网络的共识协议;第4节通过线性和非线性系统说明所提方法的结果;第5节为最终总结。
本研究提出了一种基于神经网络的新型模型预测控制(MPC)算法,使非线性多智能体系统能够在随机切换拓扑下达成共识。该方法通过采用自适应策略脱颖而出,能够使系统根据环境中的实时变化以及随机通信切换进行调整。
该方法旨在每个时间点 𝑘 找到一个反馈控制矩阵,以最小化模型预测的二次型代价函数,从而使智能体达到稳定。MPC方法基于对未来状态的预测,直到给定的预测范围,并考虑通信限制带来的不确定性。通过这种方式,基于预测状态的期望值构建了一个二次型代价函数,并可以将其作为反馈控制矩阵的函数进行最小化。
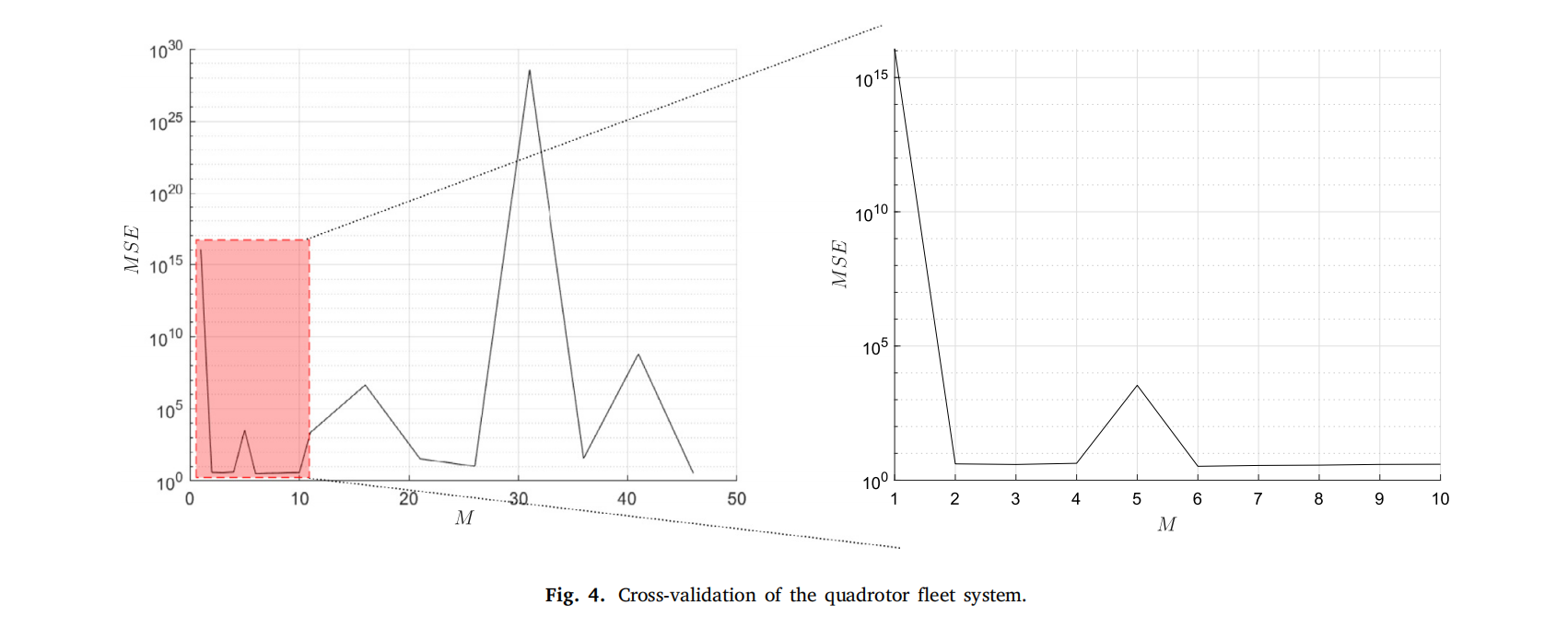
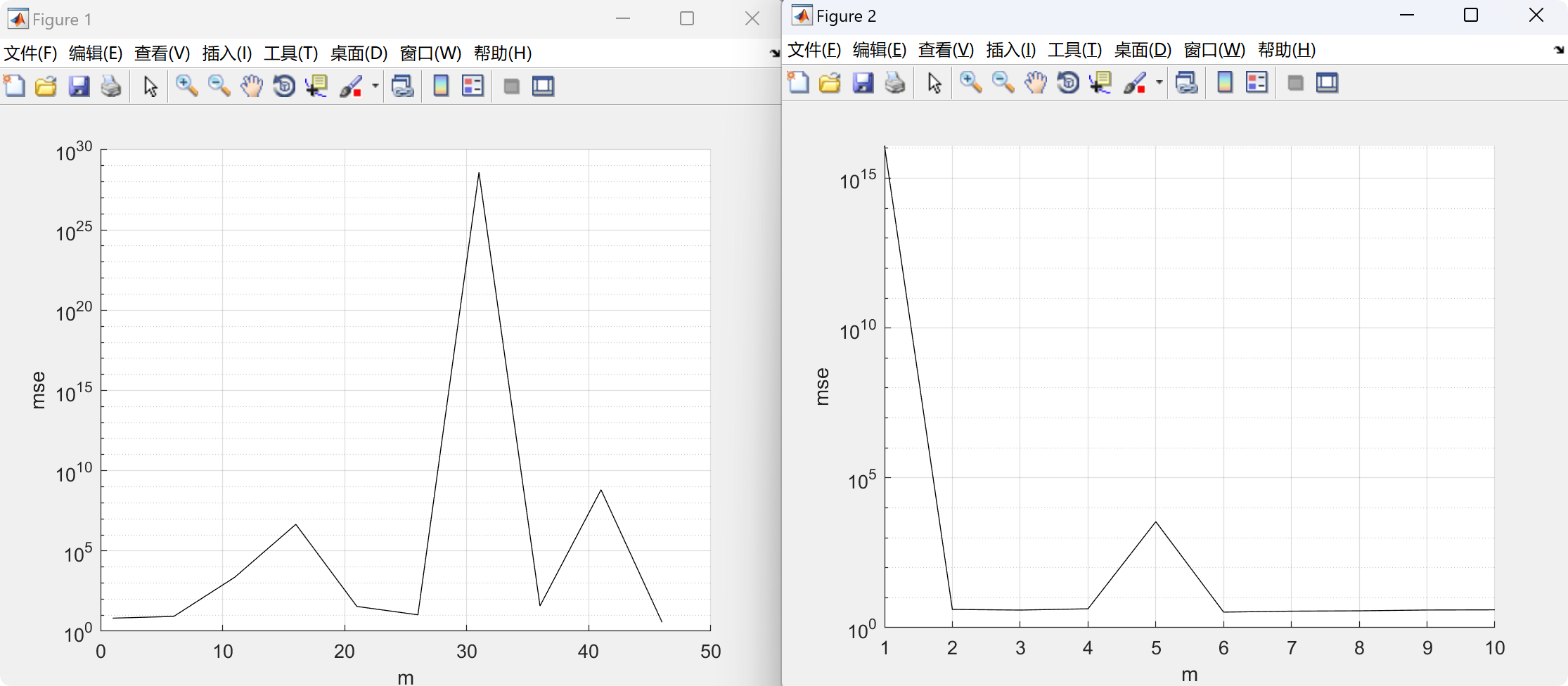
实现这种优化归功于神经网络的通用逼近性质,本研究中使用神经网络对代价函数作为矩阵的函数进行回归。采用交叉验证程序以选择能够实现最小均方误差的神经元数量。
该方法在线性和非线性系统中进行了广泛的测试,并在不同的通信场景下与现有文献进行了比较。正如结果部分所展示的,基于神经网络的MPC实现了更快的响应,并减少了调节时间。然而,代价是某些状态的均方误差较大。
需要注意的是,所提出的方法是为随机切换和非线性动态设计的。因此,这些特性的特定情况,例如确定性切换或有无干扰的线性动态,也包含在内,并可以通过基于神经网络的MPC算法实现共识。
📚2 运行结果
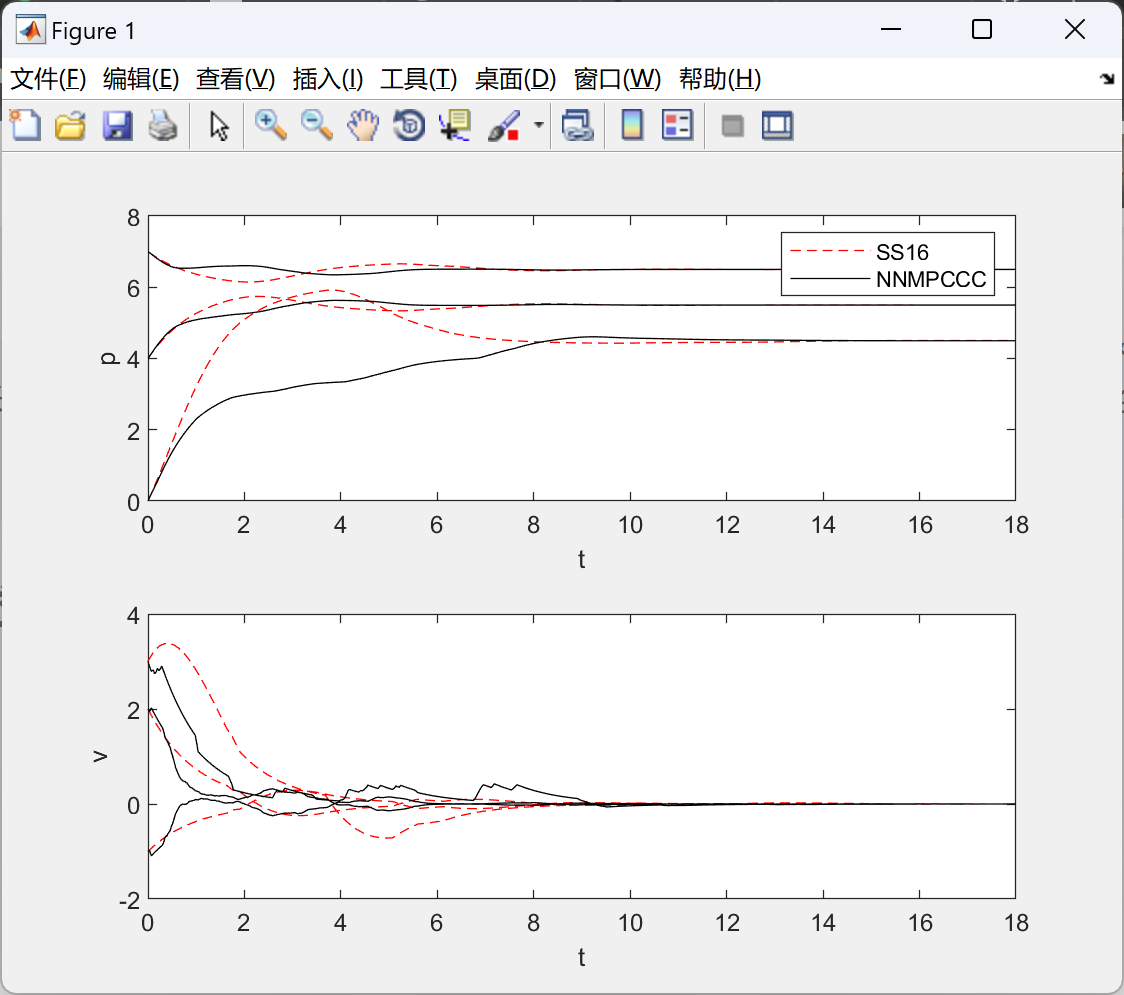
文献结果:
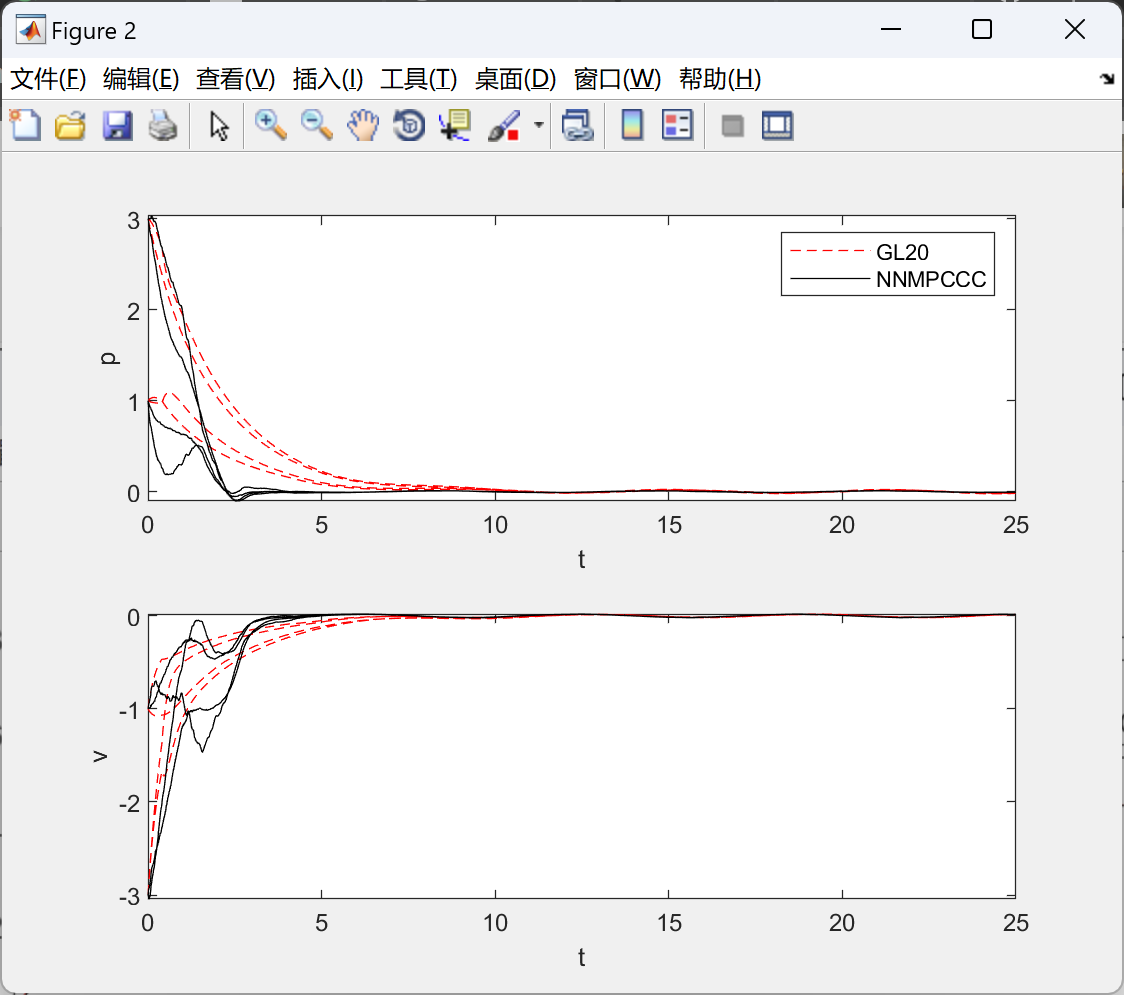
复现结果:
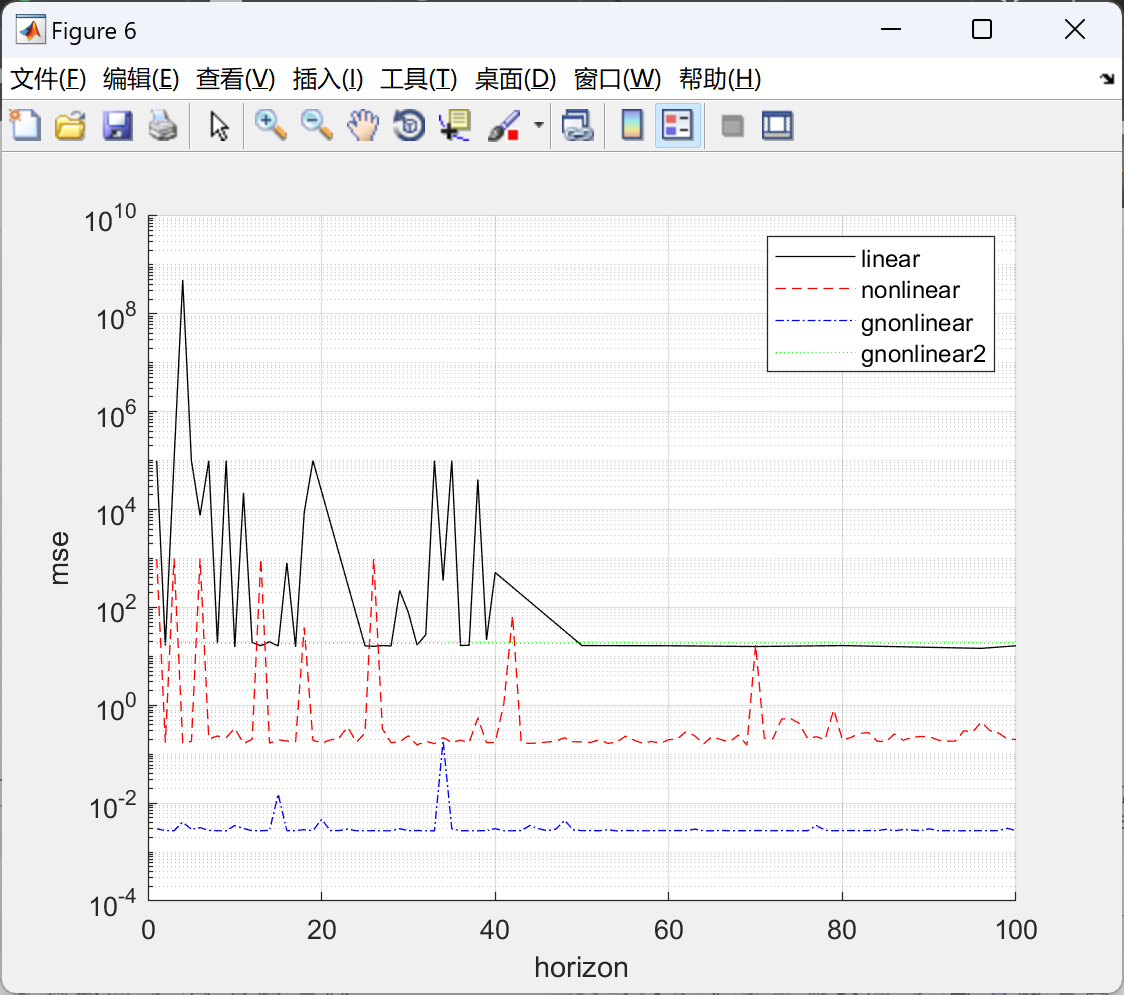
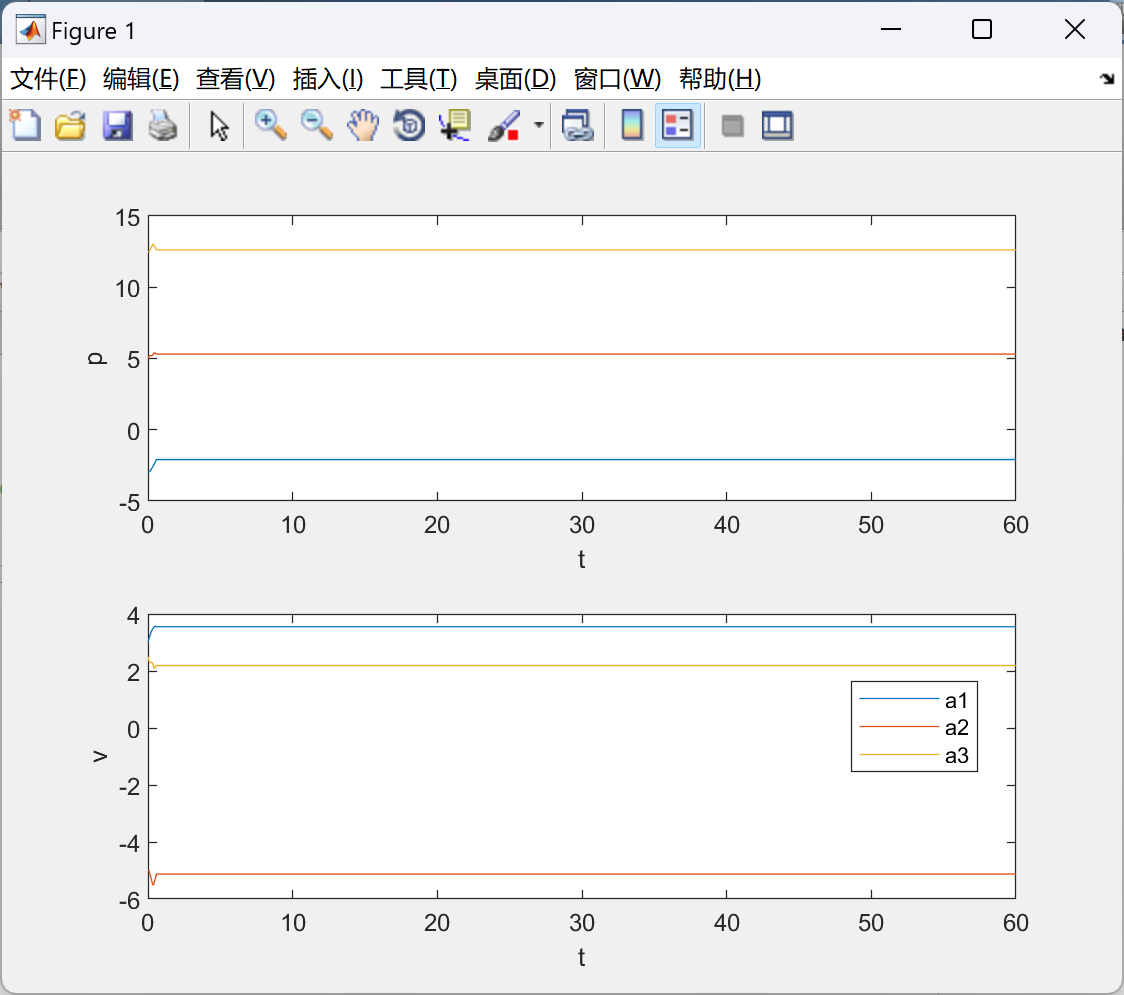
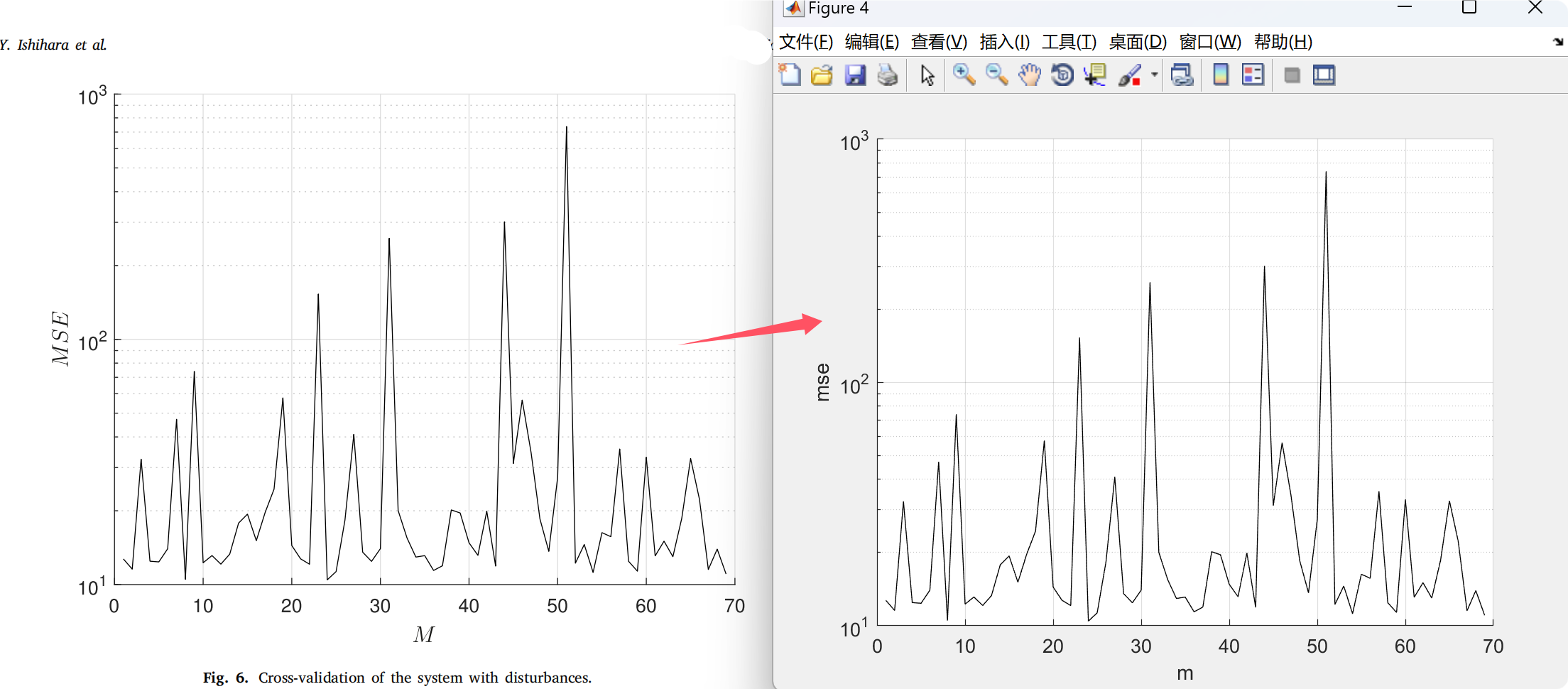
做到了完美复现。
部分代码:
% DYNAMIC SYSTEM
theta = mode(round(i*tdelta/Delta));
Laplacian = L{theta};
if ONLINE == 0
K = Km{theta};
end
if i - 1 - round(delay(i)/tdelta) <= 0
delayedstate = zeros(length(state(:,1)),1);
else
delayedstate = state(:,i-1-round(delay(i)/tdelta));
end
u = - kron(Laplacian,K)*delayedstate; % Eq. (4)
eval(dynamic_function); % Eq. (1) and (5)
eval(dynamic_function0);% Eq. (7)
% MPC
if MPC == 1
eye_matrix = eye(S);
vstate(:,1) = state(:,i);
vstate0(:,1) = state(1:n,i);
vmode = simulate(mc,horizon,'X0',eye_matrix(theta,:));
%vmode(1) = theta;
for vtime = 1:horizon
for s = 1:S
if vtime > 1
vu = - kron(L{s},K)*vstate(:,vtime-1);
eval(vdynamic_function);
eval(vdynamic_function0);
end
e = vstate(:,vtime) - kron(ones(N,1),vstate0(:,vtime)); % Eq. (8)
Jinst(vtime,s) = 0.5*e'*kron((L{s}+L{s}'),eye(n))*e; % Eq. (13)
end
if vtime == 1
Jmean(vtime) = Jinst(vtime,theta);
else
Jmean(vtime) = sum(Jinst(vtime,:).*Psi(vmode(vtime-1),:)); % Eq. (14)
end
end
J(i) = sum(Jmean);
else
J(i) = state(:,i)'*kron(Laplacian,eye(n))*state(:,i);
end
Jprev = J(i-1);
% Simulation situation display
current_sim = i/length(t)*100;
if rem(i,100) == 0 && MULTIPLE_SIMULATIONS == 0
fprintf('Sim is at %d %% \n',round(current_sim));
end
end
current_sim = j;
if MULTIPLE_SIMULATIONS == 1
error = state;% - [alpha';0;0;0];
serror = error.^2;
MSE(:,cnt) = sum( serror' )/length(state) ;
for st = 1:6
info = stepinfo(state(st,:),t);
settling_time(st,cnt) = info.SettlingTime;
end
MSEn(cnt) = norm(MSE(:,cnt));
Jfinal(j) = state(:,i)'*state(:,i);
fprintf('Sim is at %d %% \n',round(100*current_sim/max_sim));
end
cnt = cnt + 1;
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%% PLOT %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
figure
subplot(2,1,1)
title('Without offset added')
%plot(t,state([1:2:N*2-1],:)+alpha');
% charc = [':-.'];
% color = ['rbg'];
% vector = [1:2:N*2-1];
% for agent = 1:N
% plot(t,state(vector(agent),:),[color(agent) charc(agent)]);
% hold on
% end
%plot(t,state([1:2:N*2-1],:));
plot(t,state([1:n:n*(N-1)+1],:));
xlabel('t')
ylabel('p')
subplot(2,1,2)
%plot(t,state([2:2:N*2],:));
plot(t,state([2:n:n*(N-1)+2],:));
ylabel('v')
xlabel('t')
legend('a1','a2','a3')
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈4 Matlab代码、数据、文章
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取


















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









