







- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾: 【论文精读】Few-Shot Anomaly Detection via Category-Agnostic Registration Learning全类别通用!提升11%!CAReg:超越FSAD
- 每日一言🌼: 不管前方的路有多苦,只要走的方向正确,不管多么崎岖不平,都比站在原地更接近幸福。
—— 宫崎骏《千与千寻》
前言
“Few Shot Part Segmentation Reveals Compositional Logic for Industrial Anomaly Detection” 一文提出了一种新颖的组件分割模型,用于工业异常检测中的逻辑异常检测。该模型利用少量标记样本和共享逻辑约束的未标记图像,通过自适应缩放策略和多个记忆库来提高检测性能。
- 论文题目:《Few Shot Part Segmentation Reveals Compositional Logic for Industrial Anomaly Detection》(PSAD)
- 论文链接:https://ojs.aaai.org/index.php/AAAI/article/view/28703
- 代码链接:https://github.com/oopil/PSAD_logical_anomaly_detection.git
- 作者:Soopil Kim,Sion An,Philip Chikontwe,Myeongkyun Kang,Ehsan Adeli,Kilian M. Pohl,Sang Hyun Park
Abstract——摘要
翻译
逻辑异常(LA)是指违反潜在逻辑约束的数据,例如图像中组件的数量、排列或组成(the quantity, arrangement, or composition of components)。准确检测此类异常需要模型通过分割对各种组件类型进行推理。然而,语义分割的像素级标注的整理既耗时又昂贵。尽管已有一些少样本或无监督的共部分分割算法,但它们在工业对象图像上往往失败。这些图像中的组件具有相似的纹理和形状,精确区分具有挑战性。在本研究中,我们引入了一种用于 LA 检测的新型组件分割模型,该模型利用了少量标记样本和共享逻辑约束的未标记图像。为了确保未标记图像的分割一致性,我们采用了直方图匹配损失和熵损失。由于分割预测起着关键作用,我们建议通过三个记忆库(类直方图、组件组成特征嵌入和局部Patch级表示)从视觉语义中捕获关键方面,来增强局部和全局样本有效性检测。为了有效地检测 LA,我们提出了一种自适应缩放策略(an adaptive scaling strategy),以便在推理时标准化来自不同记忆库的异常分数。在公共基准 MVTec LOCO AD 上的大量实验表明,我们的方法在 LA 检测中实现了 98.1% 的 AUROC,而竞争方法仅为 89.6%。
精读
- 研究背景与问题提出
- 逻辑异常的定义与检测难点
- 首先明确逻辑异常是指数据违反如组件数量、排列或组成等潜在逻辑约束。这意味着在工业图像中,不仅仅是组件本身的异常,其相互之间的逻辑关系不符合正常情况也算异常。
- 准确检测这种异常需要模型能对组件类型进行推理,而这依赖于分割技术。但语义分割的像素级标注工作困难重重,既耗费时间又需要高昂成本。
- 现有算法的局限性
- 尽管存在一些少样本或无监督的共部分分割算法,但在工业对象图像上效果不佳。因为工业图像中的组件纹理和形状相似,给精确区分带来很大挑战。
- 逻辑异常的定义与检测难点
- 研究方法
- 新型组件分割模型
- 样本利用:利用少量标记样本和共享逻辑约束的未标记图像。这种利用方式既减少了对大量标记样本的依赖,又充分考虑了未标记图像中的逻辑信息。
- 损失函数应用:采用直方图匹配损失和熵损失来确保未标记图像的分割一致性。直方图匹配损失有助于使不同图像在分割时保持某种一致性,熵损失则用于处理不确定性。
- 样本有效性检测增强
- 通过三个记忆库(类直方图、组件组成嵌入和补丁级表示)从视觉语义中捕获关键方面。类直方图可以记录组件的类别信息,组件组成嵌入能捕捉组件之间的组合关系,补丁级表示则关注局部细节,三者结合全面地增强了样本有效性检测。
- 自适应缩放策略:提出自适应缩放策略,目的是在推理时标准化来自不同记忆库的异常分数。由于不同记忆库的异常分数可能具有不同的尺度和分布,这种标准化是必要的,以便更好地进行综合判断和比较。
- 新型组件分割模型
- 研究成果
- 通过在公共基准MVTec LOCO AD上的大量实验验证了方法的有效性。
- 取得了显著的性能提升,在LA检测中实现了98.1%的AUROC,相比竞争方法的89.6%优势明显。这表明该研究提出的方法在逻辑异常检测方面具有很高的准确性和有效性。
1. Introduction—引言
翻译
在工业图像中,缺陷可分为两种主要类型:结构异常和逻辑异常(Bergmann等人,2022)。结构异常(例如裂缝和污染)出现在正常数据中通常不存在的局部区域,而逻辑异常是指不遵守潜在逻辑约束的数据,例如组件的组成和排列。在此,有效的检测需要考虑图像内部和图像之间的长距离依赖关系。
现有针对工业图像的异常检测(AD)研究主要集中在无监督方法上,这些方法旨在学习正常数据的分布并将异常值检测为异常。这导致了一些报告得分超过99%的先进模型(Roth等人,2022)。这种高得分可归因于公共基准(例如MVTec AD(Bergmann等人,2019)和MTD(Huang等人,2020))的性质,它们主要包含结构异常,导致在针对逻辑异常时模型性能低得多(Bergmann等人,2022)。
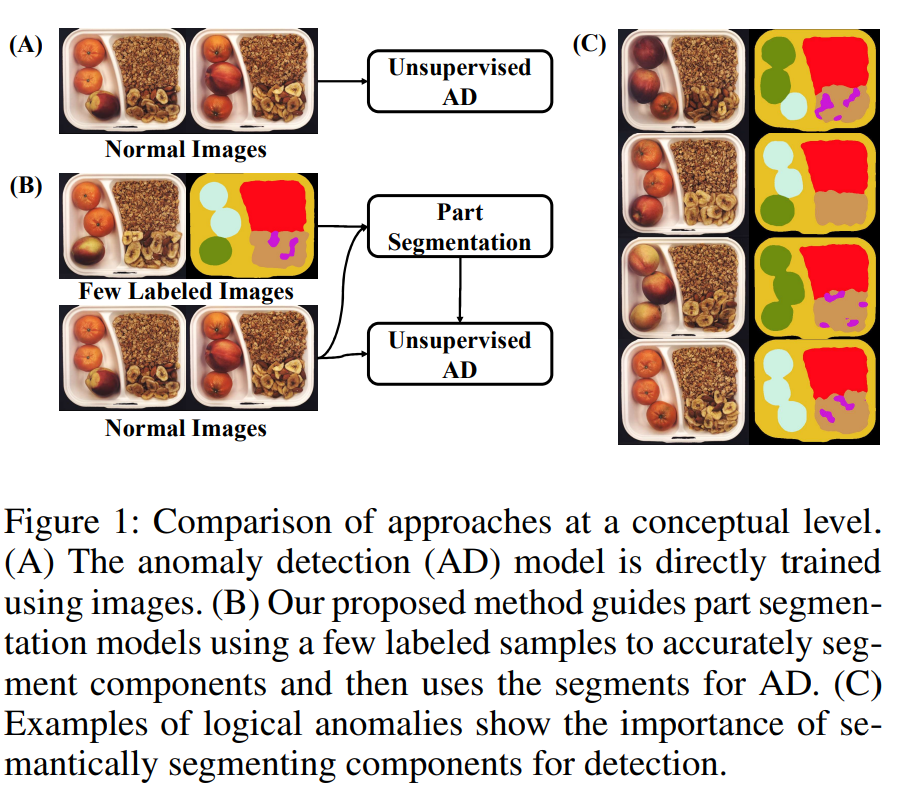
图1:概念层面方法的比较。(A)异常检测模型直接使用图像进行训练。(B)我们提出的方法使用少量标记样本引导部分分割模型以准确分割组件,然后使用这些分割用于AD。(C)逻辑异常的示例显示了语义分割组件对检测的重要性。
为了解决逻辑异常检测,当前方法隐含地考虑多个组件之间的全局依赖关系以进行有效检测,如图1A 所示。例如,(Bergmann等人,2022)提出了一种混合特征重建模型,而(Tzachor,Hoshen等人,2023)引入了一种基于直方图的密度估计模型。尽管有这些进展,但由于无法准确区分各种组件,性能受到限制。为了更准确地检测逻辑AD,对产品的组件进行语义分割是至关重要的,因为它们通常具有相似的特征(例如图1C中的桃子与橘子)。这个任务与共部分分割密切相关(Hung等人,2019),因为正常样本的相似组件遵循预定义的逻辑。然而,现有的无监督方法(Hung等人,1999;Gao等人,2021)往往无法精确地分割这些组件,因为它们无法在不依赖监督指导的情况下区分相似特征。
一种更有效的方法可能是利用制造商对产品组装所需的各个元素的先验知识,使用一组标记图像来指导部分分割,如图1B所示。然而,为大量训练图像创建像素级注释是一项成本高昂且劳动密集的任务。虽然少样本分割方法在减少标记样本数量方面取得了显著进展(Wang等人,2023;Hong等人,2022),但它们同样无法分割具有相似纹理或形状的不同部分。为此,我们引入了一种新的部分分割模型,该模型使用少量标记图像和一些未标记图像来区分工业图像中的组件。具体来说,我们利用位置特征进行预测,并最小化未标记图像的直方图匹配损失,确保每个图像中每个类的像素数量保持一致。不同损失的组合使模型能够准确地分割图像中的元素。
我们将准确的部分分割集成到我们新的AD方法PSAD(基于部分分割的异常检测)中。具体来说,PSAD通过依赖类直方图、组件组成嵌入和补丁级表示的记忆库来检测元素的局部和全局依赖关系。为了从记忆库的不同缩放输出中获得统一的异常分数,我们提出了一种自适应策略,使用训练数据的分数来重新缩放异常分数。我们在一个包含逻辑和结构AD的五个类别的公共数据集上评估了所提出的方法。我们报告的结果在逻辑AD和而在结构AD方面都比现有技术具有更高的AUROC。我们的贡献可
总结如下:
- 我们提出了一种新的异常检测方法PSAD,它通过利用视觉特征和语义分割使用3个不同的记忆库。
- 我们提出了一种新的部分分割方法,该方法由有限数量的标记图像监督,并使用未标记图像共享的逻辑约束进行正则化。
- 我们提出了一种自适应缩放方法来聚合不同尺度的异常分数。
- 我们的方法在逻辑和结构异常检测方面都达到了最先进的性能。
精读
1. 工业图像异常类型及检测需求
- 异常类型介绍
- 工业图像中的缺陷分为结构异常·Structural Anomaly(如裂缝和污染,在局部区域且正常数据中一般无)和逻辑异常·Logical Anomaly(数据违反组件组成和排列等潜在逻辑约束)。
- 强调检测逻辑异常需要考虑图像内和图像间的长距离依赖关系。
- 现有研究倾向及问题
- 现有工业图像异常检测研究多集中在无监督方法,学习正常数据分布并检测异常值,已有一些得分超99%的先进模型。
- 但这些高得分是因为公共基准数据集主要是结构异常,针对逻辑异常时模型性能低得多。
2. 逻辑异常检测方法的发展与局限
- 现有方法及进展
- 当前方法隐含考虑多组件全局依赖关系检测逻辑异常,如混合特征重建模型和基于直方图的密度估计模型。
- 局限及原因
- 因无法准确区分组件,性能受限。准确检测逻辑异常需对产品组件语义分割,但现有无监督方法难以精确分割相似组件,因其无法在无监督下区分相似特征。
3. 本研究的方法及贡献
- 提出新的部分分割模型
- 利用制造商先验知识,用少量标记图像和未标记图像区分组件。
- 通过位置特征预测并最小化直方图匹配损失,保证像素数量一致,不同损失组合实现准确分割。
- PSAD方法及贡献
- 将部分分割集成到PSAD方法,通过三个记忆库检测元素依赖关系。
- 提出自适应策略重新缩放异常分数以获统一分数。
- 在包含逻辑和结构AD的五个类别公共数据集上评估,结果在逻辑AD和结构AD方面都优于现有技术,具体贡献包括提出新检测方法、部分分割方法、自适应缩放方法且在逻辑和结构异常检测达先进水平。
2. Related Work—相关工作
翻译
2.1 Anomaly Detection in Industrial Images:工业图像中的异常检测
在文献中,现有的异常检测(AD)方法通常训练模型首先学习正常数据的分布,然后将异常值检测为异常。这些方法大致可分为基于重建、自监督和密度估计的模型。
基于重建的方法学习重建正常输入样本,并根据输入和重建之间的差异确定异常分数。自监督方法创建合成异常样本并使用它们来训练分类器。例如,CutPaste(Li等人,2021)和DRAEM(Zavrtanik等人,2021)生成异常样本用于学习异常性。密度估计方法首先使用预训练模型从正常样本中提取特征,然后将它们与测试样本特征进行比较以计算异常分数(Roth等人,2022;Jiang等人,2022;Hyun等人,2023)。我们注意到现有方法注重利用局部特征,因为大多数基准主要包含结构异常而非逻辑异常。
随着包含逻辑异常的第一个数据集的发布(Bergmann等人,2022),一些无监督方法已经被提出。GCAD(Bergmann等人,2022)训练局部和全局模型,这些模型基于局部和全局依赖关系重建预训练的图像特征。SINBAD(Tzachor, Hoshen等人,2023)提取一组无序元素并随机投影元素特征以计算直方图,通过密度估计获得异常分数。ComAD(Liu等人,2023a)对预训练特征应用K - 均值聚类以分割图像内的多个组件。然而,性能受到限制,因为精确区分不同组件具有挑战性。
我们观察到产品制造商了解各种组件的逻辑约束,并且这种先验知识可用于AD。在本文中,我们引入一种新的方法PSAD,使用密度估计和语义分割来精确区分组件。然而,由于我们提出的少样本分割方法,PSAD不需要很多标记图像。
当使用多个异常分数并聚合它们时,先前的工作只是简单地相加分数(Tsai等人,2022)或手动设置超参数来缩放它们(Liu等人,2023a)。然而,当多个分数遵循不同分布或超参数设置不正确时,这些方法可能会降低性能(表3)。即使(Bergmann等人,2022)试图在不定义超参数的情况下标准化两个不同的异常分数,他们使用一个验证数据集来确定这些分数的统计信息,这可能会牺牲有价值的训练数据。相反,我们提出一种自适应缩放分数的方法,该方法仅依靠训练数据,将每个样本视为测试样本。
2.2 Object Part Segmentation:对象部分分割
对象部分分割:由于部分分割对于逻辑AD至关重要,可以训练一个监督模型用于对象部分分割(Chen等人,2014)。然而,由于像素标记成本高,能够使用一组未标记图像学习任意分割的无监督模型(Sra和Dhillon,2005)更可取。(Hung等人,1999)提出了一个具有预训练CNN特征的端到端分割模型,使用语义一致性和几何集中损失。后来,(Siarohin等人,2021)和(Gao等人,2021)训练一个分割模型,使用一个部分组装程序,通过变换源图像的部分来重建目标图像。尽管是工业图像分割的可行替代方案,但基于几何集中或仿射变换的学习目标在工业图像中并不普遍适用,因为多个对象可能出现在远距离位置(例如,MVTec LOCO数据集的“早餐盒”中的橘子和“螺丝袋”中的六角螺母)。此外,模型经常过度或不足分割对象部分,因为标签是任意优化的。在本文中,我们提出一种新的部分分割模型,该模型可以使用仅少量标记样本分割各种工业图像中的组件。
2.3 Few Shot Semantic Segmentation: 少样本语义分割
少样本语义分割:少样本分割(FSS)已经被提出以克服深度学习模型对数据的需求,采用了不同的方法,如使用生成或增强图像(Mondal, Dolz和Desrosiers,2018),生成模型(Tritrong等人,2021;Han等人,2022;Baranchuk等人,2021),元学习(Hong等人,2022;Kim等人,2023),转导推理(Boudiaf等人,2021)和基础模型(Wang等人,2023)。一般来说,采用预训练生成模型的FSS模型报告了良好的部分分割,特别是在一些对齐良好的图像上,如人脸或汽车。然而,生成模型的训练是具有挑战性的,并且需要几个样本以保证良好的性能。注意到我们的方法与转导方法RePRI(Boudiaf等人,2021)密切相关,该方法使用一个固定的预训练骨干和训练一个像素分类器,带有几个正则化损失。在推理时,只有分类器(基于原型的)用少量样本更新。虽然令人印象深刻,但训练受到初始分割的约束,初始分割可能经常是有噪声的。因此,我们不是这样做,而是更新骨干和分类器,并用直方图匹配损失来更好地利用正常图像共享的逻辑约束。
精读
1. 工业图像中的异常检测
- 现有方法分类及原理
- 基于重建的方法:学习重建正常输入样本,根据输入和重建的差异确定异常分数。
- 自监督方法:创建合成异常样本训练分类器,如CutPaste和DRAEM通过生成异常样本来学习异常性。
- 密度估计方法:先用预训练模型从正常样本提取特征,再与测试样本特征比较计算异常分数。多数现有方法注重局部特征,因多数基准含结构异常多。
- 针对逻辑异常的无监督方法及局限
- 随着含逻辑异常数据集发布,一些无监督方法被提出。如GCAD基于局部和全局依赖重建图像特征,SINBAD提取无序元素计算直方图得异常分数,ComAD用K - 均值聚类分割组件,但因区分组件难,性能受限。
- 本研究方法的优势
- 本研究引入PSAD方法,用密度估计和语义分割区分组件,因少样本分割方法,不需要很多标记图像。同时提出自适应缩放分数方法,依靠训练数据,优于简单相加分数或手动设置超参数的旧方法。
2. 对象部分分割
- 监督与无监督方法对比
- 监督模型可用于对象部分分割,但像素标记成本高,无监督模型更可取。
- 一些无监督模型被提出,如Hung等人的端到端模型用预训练CNN特征及语义和几何损失,Siarohin等人和Gao等人用部分组装程序重建目标图像,但基于几何集中或仿射变换的学习目标在工业图像中因多对象位置问题不适用,且模型易过度或不足分割对象部分。
- 本研究的创新
- 本研究提出新的部分分割模型,可仅用少量标记样本分割工业图像组件。
3. 少样本语义分割
- 现有方法及特点
- 少样本分割(FSS)用不同方法克服深度学习对数据的需求,如生成或增强图像、生成模型、元学习、转导推理和基础模型。预训练生成模型的FSS模型在部分图像上有良好分割效果,但生成模型训练有挑战且需多样本。
- 本研究方法的关联与改进
- 本研究方法与转导方法RePRI相关,RePRI用固定预训练骨干和正则化损失训练像素分类器,推理时仅分类器更新。本研究则更新骨干和分类器,并利用直方图匹配损失更好地利用逻辑约束。
3. Methods——方法
3.1 Problem Setting——问题设定
翻译
无监督异常检测(AD)旨在从一组正常数据 { X 1 , . . . , X N t r a i n } \{X^{1},...,X^{N_{train}}\} {X1,...,XNtrain}中训练一个模型,其中 N t r a i n N_{train} Ntrain是数据的数量,并且它们的标签都被指定为0(正常)。该模型被训练用于区分正常和异常的测试数据,预测标签为0(正常)或1(异常)。
为了检测逻辑异常(LA),必须先进行准确的部分分割。在这个过程中,每个组件的类别由制造商定义,因为每个正常图像都包含预定义数量的特定部分,这些部分出现在预定义的位置。因此,即使对于同一对象,对象位置的变化也可能导致不同的类别(例如图4中的“图钉 ‘pushpins”和“拼接连接器 splicing connectors”)。实例分割(Instance segmentation) 不同于语义分割(semantic segmentation),因为预定义的类别标签不会分配给实例。由于构建大量图像的像素级注释是劳动密集型的,我们假设只有少量标记图像 { X l , i ∈ R W × H × 3 , Y l , i ∈ R W × H × N C } i = 1 N L \{X^{l,i} \in \mathbb{R}^{W×H×3}, Y^{l,i} \in \mathbb{R}^{W×H×N_{C}}\}_{i = 1}^{N_{L}} {Xl,i∈RW×H×3,Yl,i∈RW×H×NC}i=1NL以及大量未标记图像 { X u , j } j = 1 N U \{X^{u,j}\}_{j = 1}^{N_{U}} {Xu,j}j=1NU用于训练。这里, N L N_{L} NL、 N U N_{U} NU和 N C N_{C} NC分别代表标记图像、未标记图像和类别的数量。模型通过优化监督损失和无监督损失来进行训练。

精读
1. 无监督异常检测的基本设定
- 模型训练目标
- 无监督异常检测(AD)是要从一组正常数据 { X 1 , . . . , X N t r a i n } \{X^{1},...,X^{N_{train}}\} {X1,...,XNtrain}中训练出一个模型。这里 N t r a i n N_{train} Ntrain表示数据的数量,并且所有数据的标签都设定为0,表示正常状态。
- 训练好的这个模型要能够区分正常和异常的测试数据,预测的标签为0(正常)或者1(异常)。
- 逻辑异常检测与部分分割的关联
- 对于逻辑异常(LA)的检测,准确的部分分割是前提条件。这是因为逻辑异常涉及到组件的组成和排列等逻辑关系,只有先把组件准确分割出来,才能进一步判断其逻辑是否异常。
- 组件类别定义及相关影响
- 每个组件的类别是由制造商定义的。在正常图像中,包含着预定义数量的特定部分,并且这些部分出现在预定义的位置。
- 例如“图钉”和“拼接连接器”,即使是同一对象,如果位置发生变化,可能就会被归为不同的类别。这体现了组件类别定义的严格性和位置相关性。
- 实例分割与语义分割的区别
- 实例分割和语义分割不同。语义分割是给图像中的每个像素都分配一个类别标签,而实例分割不会给实例分配预定义的类别标签。这里强调这个区别是因为在后续的部分分割模型中,需要明确所采用的分割方式是符合实际需求的。
- 训练数据的设定
- 由于构建大量图像的像素级注释是非常耗费人力的,所以假设只有少量标记图像 { X l , i ∈ R W × H × 3 , Y l , i ∈ R W × H × N C } i = 1 N L \{X^{l,i} \in \mathbb{R}^{W×H×3}, Y^{l,i} \in \mathbb{R}^{W×H×N_{C}}\}_{i = 1}^{N_{L}} {Xl,i∈RW×H×3,Yl,i∈RW×H×NC}i=1NL和大量未标记图像 { X u , j } j = 1 N U \{X^{u,j}\}_{j = 1}^{N_{U}} {Xu,j}j=1NU用于训练。其中 N L N_{L} NL是标记图像的数量, N U N_{U} NU是未标记图像的数量, N C N_{C} NC是类别的数量。
- 模型训练的方式
- 模型是通过优化监督损失和无监督损失来进行训练的。监督损失用于处理标记图像,无监督损失用于处理未标记图像,通过综合考虑这两种损失,使模型能够更好地学习到数据的特征和规律。
公式解释
- { X 1 , . . . , X N t r a i n } \{X^{1},...,X^{N_{train}}\} {X1,...,XNtrain}表示一组正常数据,其中 X X X是数据, N t r a i n N_{train} Ntrain是数据的数量。
- { X l , i ∈ R W × H × 3 , Y l , i ∈ R W × H × N C } i = 1 N L \{X^{l,i} \in \mathbb{R}^{W×H×3}, Y^{l,i} \in \mathbb{R}^{W×H×N_{C}}\}_{i = 1}^{N_{L}} {Xl,i∈RW×H×3,Yl,i∈RW×H×NC}i=1NL表示标记图像及其对应的标签。其中 X l , i X^{l,i} Xl,i是第 i i i个标记图像,它是一个三维的矩阵( W × H × 3 W×H×3 W×H×3表示图像的宽度、高度和颜色通道数), Y l , i Y^{l,i} Yl,i是对应的标签,也是一个三维矩阵( W × H × N C W×H×N_{C} W×H×NC表示与图像对应的类别标签, N C N_{C} NC是类别数量), N L N_{L} NL是标记图像的数量。
- { X u , j } j = 1 N U \{X^{u,j}\}_{j = 1}^{N_{U}} {Xu,j}j=1NU表示未标记图像, X u , j X^{u,j} Xu,j是第 j j j个未标记图像, N U N_{U} NU是未标记图像的数量。
3.2 Overview——概述
翻译
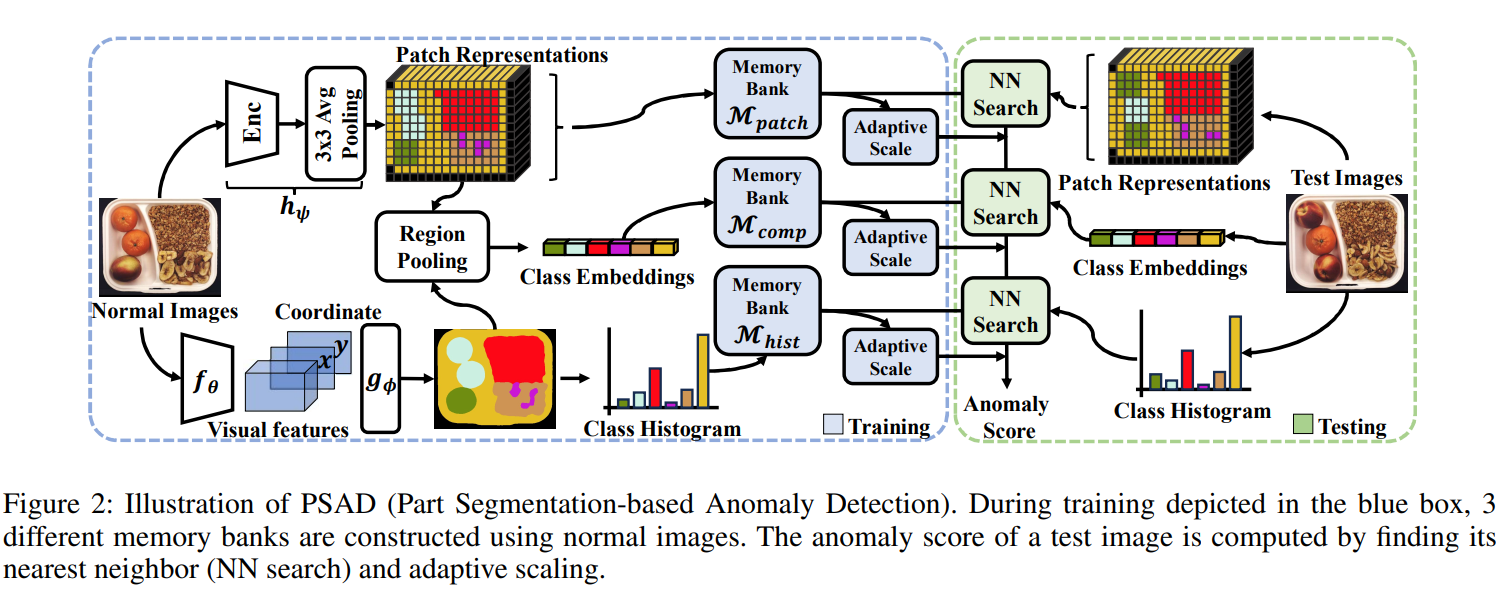
我们提出的PSAD(基于部分分割的异常检测)由两部分组成:语义部分分割和使用部分分割的异常检测。对于部分分割,我们设计了一个基于视觉和位置特征区分多个组件的模型(图3)。一个视觉特征提取器和一个像素分类器通过少量标记图像以及大量未标记图像共享的逻辑约束共同优化。
对于使用部分分割的异常检测,应用于正常样本的分割模型被用于构建三个不同的记忆库(图2)。特别是,(1)一个类直方图记忆库 M h i s t M_{hist} Mhist,它记录每个组件的数量和排列,以评估图像内不同组件的相对丰富程度。(2)一个组件组成记忆库 M c o m p M_{comp} Mcomp,它有助于确定各种组件组合的有效性,以识别因意外或不规则组件排列而产生的异常。最后,(3)一个专门用于补丁级特征的记忆库 M p a t c h M_{patch} Mpatch,用于捕捉图像内细粒度的细节。
从这些记忆库中,我们生成三个不同的异常分数,每个分数都有不同的尺度和分布。为了有效地比较和组合这些分数,我们使用从训练数据中获得的统计信息进行自适应缩放,以确保分数可以在不同尺度上可靠地比较。
精读
1. PSAD的组成部分
- 整体组成
- PSAD由语义部分分割和使用部分分割的异常检测两部分构成。这两部分紧密相关,语义部分分割为异常检测提供了基础,通过准确分割组件,为后续判断组件的逻辑异常提供了可能。
- 语义部分分割
- 模型设计依据:设计了一个基于视觉和位置特征区分多个组件的模型。视觉特征能够捕捉组件的外观特点,位置特征则考虑了组件在图像中的位置信息,两者结合有助于更准确地识别不同组件。
- 模型优化方式:通过少量标记图像以及大量未标记图像共享的逻辑约束共同优化视觉特征提取器和像素分类器。标记图像提供了明确的类别信息,未标记图像则通过逻辑约束补充了更多的信息,使得模型能够更好地学习到组件的特征和规律。
2. 异常检测中的记忆库
- 记忆库的作用及构建
- 在使用部分分割的异常检测中,应用于正常样本的分割模型用于构建三个不同的记忆库。这些记忆库是从不同角度对图像信息进行记录和整理,以便后续用于异常检测。
- 类直方图记忆库(
M
h
i
s
t
M_{hist}
Mhist)
- 功能描述:记录每个组件的数量和排列;通过这种方式可以评估图像内不同组件的相对丰富程度。例如,如果某个组件在正常情况下应该有一定数量且有特定的排列方式,当出现异常时,这种数量和排列可能会发生变化,通过 M h i s t M_{hist} Mhist就能发现这种异常。
- 组件组成记忆库(
M
c
o
m
p
M_{comp}
Mcomp)
- 功能描述:有助于确定各种组件组合的有效性。在工业图像中,组件的组合是有一定逻辑的,如果出现意外或不规则的组件排列,就可能产生异常。 M c o m p M_{comp} Mcomp通过存储相关信息,能够识别这种因组件组合问题导致的异常。
- 补丁级特征记忆库(
M
p
a
t
c
h
M_{patch}
Mpatch)
- 功能描述:专门用于捕捉图像内细粒度的细节。一些微小的异常可能在整体组件的数量和排列上没有明显变化,但在局部细节上会有所体现, M p a t c h M_{patch} Mpatch就能捕捉到这些信息。
3. 异常分数的生成与处理
- 异常分数的生成
- 从三个记忆库中会生成三个不同的异常分数。由于每个记忆库关注的是图像的不同方面,所以生成的分数具有不同的尺度和分布。
- 自适应缩放的必要性及方法
- 必要性:为了能够有效地比较和组合这些分数,需要进行自适应缩放。因为不同尺度和分布的分数直接比较是没有意义的,无法准确判断异常情况。
- 方法:使用从训练数据中获得的统计信息进行自适应缩放,这样可以确保分数在不同尺度上能够可靠地比较,从而更准确地判断图像是否存在异常以及异常的程度。
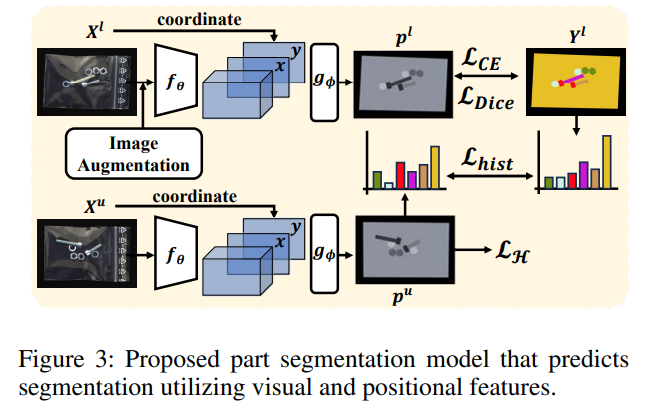
3.3 Part Segmentation Using Limited Annotations——使用有限注释的部分分割
分割模型由一个特征提取器
f
θ
f_{\theta}
fθ和一个像素分类器
g
ϕ
g_{\phi}
gϕ组成,其中
f
θ
(
X
)
f_{\theta}(X)
fθ(X)是一个与输入
X
X
X大小相同的特征图。由于对象的位置很重要,像素的坐标
c
∈
R
W
×
H
×
2
c \in \mathbb{R}^{W×H×2}
c∈RW×H×2与
f
θ
(
X
)
f_{\theta}(X)
fθ(X)被连接作为
g
ϕ
g_{\phi}
gϕ的输入。在训练过程中,给定模型预测概率
p
=
g
ϕ
(
f
θ
(
X
)
⊕
c
)
p = g_{\phi}(f_{\theta}(X) \oplus c)
p=gϕ(fθ(X)⊕c),参数
θ
\theta
θ和
ϕ
\phi
ϕ通过以下方式优化:
L
=
L
D
i
c
e
+
λ
1
L
C
E
+
λ
2
L
H
+
λ
3
L
h
i
s
t
,
(
1
)
\mathcal{L}=\mathcal{L}_{Dice}+\lambda_{1}\mathcal{L}_{C E}+\lambda_{2}\mathcal{L}_{\mathcal{H}}+\lambda_{3}\mathcal{L}_{hist}, (1)
L=LDice+λ1LCE+λ2LH+λ3Lhist,(1)
其中每个
λ
\lambda
λ是一个超参数。对于标记图像
X
l
X^{l}
Xl,我们的模型依赖于交叉熵损失
L
C
E
L_{C E}
LCE和骰子相似性损失
L
D
i
c
e
L_{Dice}
LDice。注意,对未标记图像
X
u
X^{u}
Xu的预测可能是不确定的,特别是在标记图像
X
t
X^{t}
Xt有限的情况下。一种常见的处理方法是通过引入一个熵损失
L
H
L_{H}
LH来减少不确定性(Wang等人,2022)。然而,仅用少量标记图像最小化
L
H
L_{H}
LH可能会导致意想不到的训练结果,并可能降低准确性。为了缓解这个问题,我们提出一个直方图匹配损失
L
h
i
s
t
L_{hist}
Lhist,以确保在分割每个部分时像素数量一致。我们随机从
{
Y
l
,
i
}
i
=
1
N
L
\{Y^{l,i}\}_{i = 1}^{N_{L}}
{Yl,i}i=1NL中选择一个标签
Y
l
Y^{l}
Yl,并将类级体积与未标记图像的预测
p
u
p^{u}
pu进行比较:
L
h
i
s
t
=
1
N
C
∑
n
=
1
N
C
∥
1
W
H
∑
w
,
h
Y
w
,
h
,
n
l
−
1
W
H
∑
w
,
h
p
w
,
h
,
n
u
∥
(
2
)
\mathcal{L}_{hist}=\frac{1}{N_{C}} \sum_{n = 1}^{N_{C}}\parallel \frac{1}{W H} \sum_{w, h} Y_{w, h, n}^{l}-\frac{1}{W H} \sum_{w, h} p_{w, h, n}^{u}\parallel _{(2)}
Lhist=NC1n=1∑NC∥WH1w,h∑Yw,h,nl−WH1w,h∑pw,h,nu∥(2)
在模型参数根据 L C E L_{C E} LCE、 L D i c e L_{Dice} LDice和 L h i s t L_{hist} Lhist的约束更新以减少不确定预测的同时,模型也基于每个组件的视觉和位置相似性学习在大量未标记图像上进行一致的分割。
3.4 Handling Multiple Types of Products——处理多种类型的产品
在工业图像数据集里,产品可能由各种子类型组成(例如MVTec LOCO AD数据集里的“果汁瓶”和“拼接连接器”)。在这种情况下,为了在 L h i s t L_{hist} Lhist中进行比较,有必要确保 X t X^{t} Xt和 X u X^{u} Xu属于同一产品类型。为了在无人为注释的情况下对 X u X^{u} Xu进行分类,我们在潜在空间中比较未标记和标记图像,并为每个未标记图像找到最接近的标记图像。具体来说,我们在训练分割模型之前,使用一个预训练编码器从图像中提取全局平均池化特征。每个 X u X^{u} Xu的类型被确定为潜在空间中最接近的标记图像的类型。随后,同一类型的 X t X^{t} Xt和 X u X^{u} Xu可以一起用于 L h i s t L_{hist} Lhist。因此,我们的模型可以有效地处理包含多种类型产品的数据集。
3.5 Anomaly Detection Using Part Segmentation——使用部分分割的异常检测
我们提出的PSAD遵循一种密度估计方法(Defard等人,2017),其中正常数据特征被存储在一个记忆库 M = { e k } k = 1 N M M = \{e^{k}\}_{k = 1}^{N_{M}} M={ek}k=1NM中,其中 N M N_{M} NM表示 M M M中的元素数量。为了确定一个测试样本 e t e s t e_{test} etest的异常分数 s s s,我们在 M M M中的元素中找到它的最近邻:
s = a r g m i n e ∈ M ∥ e t e s t − e ∥ 2 . ( 3 ) s=\underset{e \in \mathcal{M}}{arg min }\parallel e_{test}-e\parallel ^{2}. (3) s=e∈Margmin∥etest−e∥2.(3)
基于补丁级密度的方法(Roth等人,2022;Jiang等人,2022)已经被证明在通过关注局部特征检测结构异常方面是有效的。然而,逻辑异常通常在多个组件一起形成一个单一产品或实体时出现。
精读
1. PSAD的方法基础及记忆库设定
-
密度估计方法
- PSAD采用了密度估计方法。这种方法的核心思想是通过对正常数据的特征进行学习和存储,来判断测试样本是否异常。
- 具体来说,正常数据的特征被存储在一个记忆库 M = { e k } k = 1 N M M = \{e^{k}\}_{k = 1}^{N_{M}} M={ek}k=1NM中,这里 N M N_{M} NM表示记忆库中元素的数量,每个元素 e k e^{k} ek代表了正常数据的某种特征表示。
-
确定异常分数的方式
- 对于一个测试样本 e t e s t e_{test} etest,要确定它的异常分数 s s s,是通过在记忆库 M M M中的元素里找到它的最近邻来实现的。这个最近邻的寻找是基于公式 s = a r g m i n e ∈ M ∥ e t e s t − e ∥ 2 s=\underset{e \in \mathcal{M}}{arg min }\parallel e_{test}-e\parallel ^{2} s=e∈Margmin∥etest−e∥2。这个公式的含义是,计算测试样本 e t e s t e_{test} etest与记忆库中每个元素 e e e的距离(这里用欧几里得距离 ∥ e t e s t − e ∥ 2 \parallel e_{test}-e\parallel ^{2} ∥etest−e∥2表示),然后找到距离最小的那个元素,这个元素就是最近邻,对应的距离计算结果就是异常分数 s s s。
- 从本质上来说,寻找最近邻是在进行特征匹配。测试样本的特征与记忆库中存储的正常数据特征进行比较,找到最相似的那个(或那些)特征,即最近邻。
-
衡量与正常数据的相似性
- 通过找到最近邻,可以衡量测试样本与记忆库中存储的正常数据特征之间的相似程度。如果测试样本与某个正常数据特征(即最近邻)非常接近,说明它很可能是正常的;反之,如果距离较远,则更有可能是异常的。
-
基于相似性确定异常分数
- 最近邻与测试样本之间的距离被用作异常分数。距离越小,异常分数越低,表示测试样本越接近正常状态;距离越大,异常分数越高,意味着测试样本偏离正常数据的程度越大,也就越有可能是异常的。这种方式将测试样本与正常数据的相似性量化为一个具体的分数,便于后续对异常情况进行判断和分析。
-
利用正常数据分布进行异常检测
- 记忆库中存储的是正常数据的特征,通过寻找最近邻并确定异常分数,实际上是利用了正常数据的分布特征来判断测试样本是否异常。如果测试样本的异常分数超出了正常数据所形成的某种“合理范围”,就可以判定该测试样本为异常。这是一种基于数据分布的异常检测策略,有助于识别那些与正常数据模式不符的样本。
2. 不同方法针对的异常类型
- 补丁级密度方法的有效性及局限
- 基于补丁级密度的方法(如Roth等人和Jiang等人的研究)在检测结构异常方面是有效的。这种方法主要是通过关注局部特征来实现的。例如,在工业图像中,如果某个局部区域的特征与正常情况不符,就可能被判断为结构异常。
- 然而,这种方法对于逻辑异常的检测存在局限性。因为逻辑异常通常是在多个组件一起形成一个单一产品或实体时出现的,它不仅仅是局部特征的问题,还涉及到组件之间的组合和逻辑关系,而补丁级密度方法主要关注局部特征,无法很好地处理这种逻辑关系相关的异常。
3.6 Class Histogram Memory Bank——类直方图记忆库
第一个记忆库 M h i s t M_{hist} Mhist专注于通过一个类直方图量化每个类的组件数量。给定正常图像及其相应的分割,我们构建一个直方图,它代表不同类别的像素分布。这些直方图被存储在 M h i s t M_{hist} Mhist中,并且相应的异常分数通过公式(3)预测。
3.7 Component Composition Memory Bank——组件组成记忆库
值得注意的是,仅仅依靠 M h i s t M_{hist} Mhist无法验证组件是否正确组合。为了解决这个问题,我们引入一个组件组成记忆库 M c o m p M_{comp} Mcomp,它存储图像内不同部分的特征组合。在使用一个预训练编码器 h ψ h_{\psi} hψ提取一个特征图 w = h ψ ( X ) w = h_{\psi}(X) w=hψ(X)之后,分割图允许我们定义一个类嵌入作为属于每个类的像素的平均特征向量。这些类嵌入的连接被保存在 M c o m p M_{comp} Mcomp中,以有效地捕捉图像内每个组件的视觉特征及其组合。异常分数通过公式(3)预测。
精读
1. 引入组件组成记忆库的原因
- 类直方图记忆库( M h i s t M_{hist} Mhist)主要关注组件的数量和排列情况,它可以帮助我们了解图像中各个组件的出现频率和位置分布。然而,仅仅知道组件的数量和位置是不够的,我们还需要知道这些组件是否正确地组合在一起。
- 例如,在一个工业产品的图像中,可能有多个零件按照特定的顺序和方式组装在一起才是正常的。如果只是通过 M h i s t M_{hist} Mhist,我们无法确定这些零件是否组装正确,所以需要引入一个专门用于验证组件组合情况的记忆库,即组件组成记忆库( M c o m p M_{comp} Mcomp)。
2. 组件组成记忆库的工作原理
- 特征提取与类嵌入定义
- 首先,使用一个预训练编码器 h ψ h_{\psi} hψ对图像 X X X进行处理,提取出一个特征图 w = h ψ ( X ) w = h_{\psi}(X) w=hψ(X)。然后,根据分割图(可能是通过前面提到的部分分割模型得到的),我们可以为每个类定义一个类嵌入。类嵌入是将属于每个类的像素的特征进行平均得到的一个向量,它代表了这个类的一种综合特征表示。
- 存储特征组合
- 将这些类嵌入连接起来并保存在 M c o m p M_{comp} Mcomp中。这样, M c o m p M_{comp} Mcomp就存储了图像内不同部分的特征组合信息。通过这种方式,它可以有效地捕捉图像内每个组件的视觉特征以及它们之间的组合关系。
- 异常分数预测
- 当需要预测异常分数时,同样使用公式(3)。这个公式是基于密度估计方法来确定异常分数的,通过比较测试样本与记忆库中存储的特征组合之间的距离,找到最近邻,进而确定异常分数。在这里, M c o m p M_{comp} Mcomp作为存储组件组合特征的记忆库,参与到这个异常分数的预测过程中,帮助判断是否存在因组件组合异常而导致的问题。
3.8 Patch Representation Memory Bank——补丁级特征记忆库
最后,我们通过存储补丁级表示来构建一个补丁级特征记忆库
M
p
a
t
c
h
M_{patch}
Mpatch,以按照既定方法(Defard等人,2017;Roth等人,2022)检测细粒度特征:
M
p
a
t
c
h
=
∪
k
=
1
N
t
r
a
i
n
h
ψ
(
X
k
)
l
l
=
1
N
P
M_{patch}=\cup _{k = 1}^{N_{train}}{h_{\psi}(X^{k})_{l}}_{l = 1}^{N_{P}}
Mpatch=∪k=1Ntrainhψ(Xk)ll=1NP
其中
h
ψ
(
X
k
)
t
h_{\psi}(X^{k})_{t}
hψ(Xk)t是从
X
k
X^{k}
Xk中提取的第
l
l
l个补丁表示,
N
P
N_{P}
NP表示补丁的数量。测试样本
X
t
e
s
t
X_{test}
Xtest的异常分数被预测为:
s
=
m
a
x
e
∈
h
φ
(
X
t
e
s
t
)
i
i
=
1
N
P
m
i
n
e
′
∈
M
p
a
t
c
h
∥
e
−
e
′
∥
2
.
s=max _{e \in{h_{\varphi}(X_{test })_{i}}_{i = 1}^{N_{P}}} min _{e' \in M_{patch }}\left\|e - e'\right\|^{2}.
s=maxe∈hφ(Xtest)ii=1NPmine′∈Mpatch∥e−e′∥2.
精读
1. 补丁级特征记忆库的构建目的
- 在工业图像异常检测中,除了关注组件的整体情况(如数量、排列和组合)外,还需要检测图像中的细粒度特征。一些微小的异常可能不会在组件的宏观层面体现出来,但会在局部的细节部分有所表现。因此,构建补丁级特征记忆库( M p a t c h M_{patch} Mpatch)的目的就是为了能够捕捉这些细粒度特征,从而更全面地检测图像中的异常情况。
2. 记忆库的构建方式
- 补丁级特征记忆库是通过存储补丁级表示来构建的。具体来说,对于训练数据集中的每一个样本 X k X^{k} Xk( k k k从1到 N t r a i n N_{train} Ntrain, N t r a i n N_{train} Ntrain是训练样本的数量),使用编码器 h ψ h_{\psi} hψ提取出多个补丁表示 h ψ ( X k ) l h_{\psi}(X^{k})_{l} hψ(Xk)l( l l l从1到 N P N_{P} NP, N P N_{P} NP是补丁的数量)。然后,将所有这些补丁表示集合起来,就构成了补丁级特征记忆库 M p a t c h M_{patch} Mpatch,即 M p a t c h = ∪ k = 1 N t r a i n h ψ ( X k ) l l = 1 N P M_{patch}=\cup _{k = 1}^{N_{train}}{h_{\psi}(X^{k})_{l}}_{l = 1}^{N_{P}} Mpatch=∪k=1Ntrainhψ(Xk)ll=1NP。
3. 异常分数的预测方法
- 对于测试样本 X t e s t X_{test} Xtest,其异常分数的预测方式如下:
- 首先,从测试样本 X t e s t X_{test} Xtest中也提取出多个补丁表示 h φ ( X t e s t ) i h_{\varphi}(X_{test})_{i} hφ(Xtest)i( i i i从1到 N P N_{P} NP)。然后,对于每一个从测试样本中提取的补丁表示 e ∈ h φ ( X t e s t ) i i = 1 N P e \in{h_{\varphi}(X_{test })_{i}}_{i = 1}^{N_{P}} e∈hφ(Xtest)ii=1NP,在记忆库 M p a t c h M_{patch} Mpatch中找到与之距离最小的补丁表示 e ′ ∈ M p a t c h e' \in M_{patch} e′∈Mpatch(这里的距离是通过计算 ∥ e − e ′ ∥ 2 \left\|e - e'\right\|^{2} ∥e−e′∥2得到的)。接着,在所有这些距离最小的情况中,找到最大的那个距离值,这个最大距离值就是测试样本 X t e s t X_{test} Xtest的异常分数 s s s,即 s = m a x e ∈ h φ ( X t e s t ) i i = 1 N P m i n e ′ ∈ M p a t c h ∥ e − e ′ ∥ 2 s=max _{e \in{h_{\varphi}(X_{test })_{i}}_{i = 1}^{N_{P}}} min _{e' \in M_{patch }}\left\|e - e'\right\|^{2} s=maxe∈hφ(Xtest)ii=1NPmine′∈Mpatch∥e−e′∥2。这种预测方式是基于比较测试样本的补丁表示与记忆库中存储的补丁表示之间的相似性,通过找到最不相似(距离最大)的情况来确定异常分数,从而判断测试样本是否存在异常以及异常的程度。
3.9 Aggregating Anomaly Scores of Different Scales——聚合不同尺度的异常分数
考虑到记忆库的不同尺度和分布,为每个异常分数设置适当的超参数是至关重要的,因为任意配置一个超参数可能会对整体准确性产生负面影响。为了缓解这个问题,我们的解决方案是根据每个记忆库中训练数据的异常分数进行缩放。具体来说,我们从训练数据中导出一组异常分数,记为
S
˙
t
r
a
i
n
=
{
s
1
,
.
.
.
,
s
N
M
}
\dot{S}_{train} = \{s^{1},...,s^{N_{M}}\}
S˙train={s1,...,sNM},
通过将每个数据点
e
k
e^{k}
ek视为一个测试样本。然后我们使用所有其他训练样本(除了
e
k
e^{k}
ek)构建记忆库如下:
s
k
=
m
i
n
e
∈
M
,
e
≠
e
k
∥
e
k
−
e
∥
2
s^{k}=min _{e \in M, e \neq e^{k}}\left\|e^{k}-e\right\|^{2}
sk=mine∈M,e=ek
ek−e
2。
在
M
h
i
s
t
M_{hist}
Mhist和
M
c
o
m
p
M_{comp}
Mcomp的背景下,
e
e
e分别代表一个类直方图和一个组件组成嵌入,它们是从一个数据样本中导出的。然而,对于
M
p
a
t
c
h
M_{patch}
Mpatch,
s
k
s^{k}
sk的定义方式不同,因为从一个数据样本中保存了多个元素,如下所示:
s
k
=
m
a
x
e
∈
h
ψ
(
X
k
)
l
l
=
1
N
P
m
i
n
e
′
∈
M
p
a
t
c
h
′
∥
e
−
e
′
∥
2
s^{k}=max _{e \in{h_{\psi}(X^{k})_{l}}_{l = 1}^{N_{P}}} min _{e' \in M_{patch }'}\left\|e - e'\right\|^{2}
sk=maxe∈hψ(Xk)ll=1NPmine′∈Mpatch′∥e−e′∥2,
其中
M
a
t
c
h
′
=
∪
m
=
1
,
m
≠
k
N
t
r
a
i
n
h
ψ
(
X
m
)
l
l
=
1
N
P
.
M_{atch }'=\cup _{m = 1, m \neq k}^{N_{train}}{h_{\psi}(X^{m})_{l}}_{l = 1}^{N_{P}}.
Match′=∪m=1,m=kNtrainhψ(Xm)ll=1NP.
我们定义一个考虑到
S
t
r
a
i
n
S_train
Strain统计信息的归一化异常分数为
s
^
M
=
s
/
m
a
x
{
s
1
,
.
.
.
,
s
N
M
}
\hat{s}_{M}=s / max \{s^{1},...,s^{N_{M}}\}
s^M=s/max{s1,...,sNM}。这种自适应缩放方法提高了检测异常的准确性和鲁棒性。最终的异常分数被定义为来自不同记忆库的三个异常分数之和:
s
=
s
^
M
h
i
s
t
+
s
^
M
c
o
m
p
+
s
^
M
p
a
t
c
h
s=\hat{s}_{M_{hist}}+\hat{s}_{M_{comp}}+\hat{s}_{M_{patch}}
s=s^Mhist+s^Mcomp+s^Mpatch,这有助于对结构和逻辑异常进行评分。
精读
1. 聚合异常分数的必要性及超参数设置问题
- 不同记忆库的差异导致的问题
- 文中构建了三个不同的记忆库( M h i s t M_{hist} Mhist、 M c o m p M_{comp} Mcomp和 M p a t c h M_{patch} Mpatch)用于异常检测,每个记忆库都有其独特的构建方式和所关注的特征,这导致它们生成的异常分数具有不同的尺度和分布。
- 例如, M h i s t M_{hist} Mhist关注组件数量和排列, M c o m p M_{comp} Mcomp关注组件组合, M p a t c h M_{patch} Mpatch关注细粒度特征,这些不同的关注点使得它们产生的异常分数在数值范围和分布规律上可能存在很大差异。
- 超参数设置的重要性及不当设置的影响
- 为了能够有效地利用这些不同尺度和分布的异常分数进行综合判断,需要为每个异常分数设置适当的超参数。超参数的作用是调整不同记忆库的异常分数在最终综合判断中的权重。
- 如果超参数设置不当,例如任意配置一个超参数,可能会导致某些记忆库的异常分数在综合判断中所占比重过大或过小,从而对整体的异常检测准确性产生负面影响。
2. 自适应缩放的方法及原理
- 从训练数据中导出异常分数并构建记忆库
- 为了解决超参数设置的问题,采用了一种自适应缩放的方法。首先,从训练数据中导出一组异常分数,记为 S ˙ t r a i n = { s 1 , . . . , s N M } \dot{S}_{train} = \{s^{1},...,s^{N_{M}}\} S˙train={s1,...,sNM}。这里是通过将每个数据点 e k e^{k} ek视为一个测试样本的方式来实现的。
- 对于每个数据点 e k e^{k} ek,使用除它自身之外的所有其他训练样本构建记忆库,并计算其异常分数 s k s^{k} sk。在 M h i s t M_{hist} Mhist和 M c o m p M_{comp} Mcomp的情况下, e e e分别代表一个类直方图和一个组件组成嵌入(这些都是从一个数据样本中导出的),异常分数 s k s^{k} sk的计算公式为 s k = m i n e ∈ M , e ≠ e k ∥ e k − e ∥ 2 s^{k}=min _{e \in M, e \neq e^{k}}\left\|e^{k}-e\right\|^{2} sk=mine∈M,e=ek ek−e 2。而对于 M p a t c h M_{patch} Mpatch,由于从一个数据样本中保存了多个元素(以补丁表示的形式),其异常分数 s k s^{k} sk的计算公式为 s k = m a x e ∈ h ψ ( X k ) l l = 1 N P m i n e ′ ∈ M p a t c h ′ ∥ e − e ′ ∥ 2 s^{k}=max _{e \in{h_{\psi}(X^{k})_{l}}_{l = 1}^{N_{P}}} min _{e' \in M_{patch }'}\left\|e - e'\right\|^{2} sk=maxe∈hψ(Xk)ll=1NPmine′∈Mpatch′∥e−e′∥2,其中 M a t c h ′ = ∪ m = 1 , m ≠ k N t r a i n h ψ ( X m ) l l = 1 N P M_{atch }'=\cup _{m = 1, m \neq k}^{N_{train}}{h_{\psi}(X^{m})_{l}}_{l = 1}^{N_{P}} Match′=∪m=1,m=kNtrainhψ(Xm)ll=1NP。
- 定义归一化异常分数
- 基于上述从训练数据中导出的异常分数 S ˙ t r a i n \dot{S}_{train} S˙train,定义一个考虑到其统计信息的归一化异常分数 s ^ M = s / m a x { s 1 , . . . , s N M } \hat{s}_{M}=s / max \{s^{1},...,s^{N_{M}}\} s^M=s/max{s1,...,sNM}。这个归一化的过程是为了将不同尺度的异常分数进行标准化,使得它们在后续的综合判断中能够更合理地进行比较和组合。
3. 最终异常分数的计算及意义
- 最终异常分数的计算方式
- 最终的异常分数被定义为来自不同记忆库的三个异常分数之和,即 s = s ^ M h i s t + s ^ M c o m p + s ^ M p a t c h s=\hat{s}_{M_{hist}}+\hat{s}_{M_{comp}}+\hat{s}_{M_{patch}} s=s^Mhist+s^Mcomp+s^Mpatch。这里通过将三个记忆库经过自适应缩放后的异常分数相加,综合考虑了组件数量和排列、组件组合以及细粒度特征等多个方面的信息,从而更全面地对结构和逻辑异常进行评分。
- 这种计算方式的意义
- 这种计算方式有助于提高异常检测的准确性和鲁棒性。通过综合多个记忆库的信息,避免了单一记忆库可能存在的局限性,能够更准确地判断图像是否存在异常以及异常的程度。同时,自适应缩放方法使得不同尺度的异常分数能够合理地参与到最终的判断中,提高了整个异常检测系统在面对不同数据和情况时的稳定性和可靠性。
3.10 Implementation Details——实施细节⭐
我们使用一个预训练的Wide ResNet101(Zagoruyko和Komodakis,2016)来初始化分割模型 f θ f_{\theta} fθ的参数。在 f θ f_{\theta} fθ的4个卷积块中,从前面3个块中提取的特征被调整大小到输入 X X X的大小,并连接起来以获得 v ∈ R W × H × ( 256 + 512 + 1024 ) v \in \mathbb{R}^{W×H×(256+512+1024)} v∈RW×H×(256+512+1024)。标记图像按照(Buslaev等人,2022)进行增强。对于训练,我们使用一个AdamW优化器,学习率为0.001,每次迭代的批量大小为5,在一个NVIDIA RTX A5000 GPU工作站上进行。模型首先使用只含 L C E L_{C E} LCE和 L D i c e L_{Dice} LDice的损失函数训练50个epoch。在使用监督损失进行热身之后,模型使用公式(1)再训练50个epoch。由于 L D i c e L_{Dice} LDice通常比其他损失大,超参数 λ 1 \lambda_{1} λ1、 λ 2 \lambda_{2} λ2、 λ 3 \lambda_{3} λ3被设置为10。 h ψ h_{\psi} hψ使用Wide ResNet101作为视觉特征编码器,并按照PatchCore(Roth等人,2022)的设置进行一个 3 × 3 3×3 3×3平均池化操作,PatchCore是用于检测结构异常的最先进模型之一。
精读
1. 分割模型参数初始化及特征处理
- 模型参数初始化
- 使用预训练的Wide ResNet101来初始化分割模型 f θ (特征提取器) f_{\theta}(特征提取器) fθ(特征提取器)的参数。预训练模型通常在大规模数据集上进行了训练,已经学习到了一些通用的图像特征,利用这些预训练的参数可以加快模型的训练速度并提高性能。
- 特征提取与连接
- 在 f θ f_{\theta} fθ的4个卷积块中,对前面3个块提取的特征进行处理。首先将这些特征调整大小到与输入 X X X相同的尺寸,然后将它们连接起来。这样做的目的是为了综合利用不同卷积层提取到的特征信息 。连接后的特征向量 v v v的维度是 R W × H × ( 256 + 512 + 1024 ) \mathbb{R}^{W×H×(256 + 512 + 1024)} RW×H×(256+512+1024),其中 256 256 256、 512 512 512和 1024 1024 1024分别是来自三个卷积块的特征维度, W W W和 H H H是图像的宽度和高度。
2. 标记图像增强及训练设置
- 标记图像增强
- 标记图像按照(Buslaev等人,2022)的方法进行增强。图像增强是一种常用的技术,通过对原始图像进行一些变换(如旋转、翻转、缩放等),可以增加训练数据的多样性,提高模型的泛化能力。
- 训练设置
- 优化器选择:使用AdamW优化器进行训练。AdamW是一种基于自适应矩估计的优化算法,它结合了Adam算法的优点,并对权重衰减进行了改进,能够更有效地更新模型参数,使模型更快地收敛到较好的性能。
- 学习率和批量大小:学习率设置为0.001,每次迭代的批量大小为5。学习率决定了模型参数更新的步长,合适的学习率对于模型的训练效果至关重要。批量大小则影响了每次迭代中使用的数据量,较小的批量大小可能会使训练过程更加波动,但也可能有助于模型更好地学习到数据的细节。
- 训练设备:在NVIDIA RTX A5000 GPU工作站上进行训练。GPU具有强大的并行计算能力,可以加速模型的训练过程,大大缩短训练时间。
3. 模型训练过程
- 初步训练
- 模型首先使用只包含交叉熵损失( L C E L_{C E} LCE)和骰子相似性损失( L D i c e L_{Dice} LDice)的损失函数进行训练,训练的轮数(epoch)为50。在这个阶段,模型主要学习标记图像中的类别信息和像素之间的相似性。
- 进一步训练
- 在使用监督损失进行热身之后,模型使用公式(1)中的损失函数(包括交叉熵损失、骰子相似性损失、熵损失和直方图匹配损失)再训练50个epoch。这个过程是对模型的进一步优化,通过引入更多的损失项,使模型能够更好地适应不同的情况,提高分割的准确性。
- 超参数设置
- 由于 L D i c e L_{Dice} LDice通常比其他损失大,为了平衡不同损失项在模型训练中的作用,将超参数 λ 1 \lambda_{1} λ1、 λ 2 \lambda_{2} λ2、 λ 3 \lambda_{3} λ3都设置为10。这些超参数用于调整不同损失项在总损失函数中的权重,确保各个损失项对模型训练的影响相对均衡。
4. 视觉特征编码器设置
- h ψ h_{\psi} hψ作为视觉特征编码器,使用Wide ResNet101。这与前面初始化分割模型 f θ f_{\theta} fθ的参数所使用的预训练模型相同,这样可以保证在特征提取过程中具有一致性和连贯性。
- 并且按照PatchCore(Roth等人,2022)的设置进行一个 3 × 3 3×3 3×3平均池化操作。平均池化操作可以减少特征图的尺寸,同时保留重要的特征信息,有助于提高模型的计算效率和性能。PatchCore是用于检测结构异常的先进模型,采用其设置可以借鉴其在结构异常检测方面的优势。
四. Experiments——实验
4.1 Experimental Setting——实验设置
我们在MVTec LOCO AD数据集(Bergmann等人,2022)上评估我们的方法,据我们所知,这是检测逻辑异常的唯一基准。该数据集包含5个类别(早餐盒、果汁瓶、图钉、螺丝袋、拼接连接器)。对于每个类别,按照比较方法的设置,使用351/335/372/360/360张正常图像进行训练,使用275/330/310/341/312张图像进行测试。
测试数据被分类为正常、结构异常(SA)和逻辑异常(LA)。
对于分割任务,我们使用5张标记图像,因为现有的少样本分割(FSS)模型在5 - 样本设置下显示出更稳定的准确性。
如果产品有多种类型(例如在“果汁瓶”和“拼接连接器”中有3种类型),我们为每种类型创建一张标记图像,因此总共使用3张标记图像。
包括PatchCore(Roth等人,2022)、RD4AD(Deng和Li,2022)、DRAEM(Zavrtan,ik等人,2021)、AST(Rudolph等人,2023)、ST(Bergmann等人,2020)、ComAD(Liu等人,2023a)、GCAD(Bergmann等人,2022)、SINBAD(Tzachor,Hoshen等人,2023)和SLSG(Yang等人,2023)在内的先进的异常检测(AD)方法被用作比较方法。这些模型分别在结构异常(SA)和逻辑异常(LA)检测上进行评估。我们将所有图像的大小调整为使宽度和高度中较长边的像素数为512。按照先前的工作(Roth等人,2022),使用ROC曲线下面积(AUROC)作为评估指标
精读
1. 数据集选择及类别介绍
- 数据集:选择MVTec LOCO AD数据集来评估方法,它在检测逻辑异常方面具有独特性,是目前所知的唯一相关基准。
- 类别:该数据集包含5个不同的类别,分别是早餐盒、果汁瓶、图钉、螺丝袋和拼接连接器。这些类别涵盖了不同类型的工业产品图像,为实验提供了多样化的样本。
2. 数据划分及使用
- 训练和测试数据量
- 对于每个类别,按照比较方法的设定,划分了训练集和测试集。训练集分别使用351、335、372、360、360张正常图像,测试集使用275、330、310、341、312张图像。这样的划分是为了在遵循已有研究方法的基础上,保证有足够的数据用于模型的训练和评估。
- 测试数据分类
- 测试数据进一步被分类为正常、结构异常(SA)和逻辑异常(LA)。这种分类方式有助于更细致地评估模型在不同类型异常检测上的性能。
3. 分割任务的标记图像选择
- 标记图像数量
- 在分割任务中,使用了5张标记图像。这是因为现有的少样本分割(FSS)模型在5 - 样本设置下,准确性表现更稳定。通过利用这种相对稳定的设置,可以更好地进行分割任务,为后续的异常检测提供更准确的基础。
- 针对多种类型产品的处理
- 如果产品有多种类型,比如在“果汁瓶”和“拼接连接器”中存在3种类型,那么会为每种类型创建一张标记图像,总共就会使用3张标记图像。这样做是为了更准确地处理不同类型产品的图像,使标记图像能够更好地反映产品的特性,从而提高分割的准确性。
4. 比较方法及模型评估设置
- 比较方法
- 选择了一系列先进的异常检测(AD)方法作为比较对象,包括PatchCore、RD4AD、DRAEM、AST、ST、ComAD、GCAD、SINBAD和SLSG等。这些方法涵盖了当前在该领域具有代表性的研究成果,通过与它们比较,可以更全面地评估所提出方法的性能。
- 模型评估
- 这些模型都将分别在结构异常(SA)和逻辑异常(LA)检测上进行评估。这意味着会分别考察模型在检测这两种不同类型异常时的能力。
- 同时,将所有图像的大小调整为使宽度和高度中较长边的像素数为512。这样做是为了统一图像的尺寸,避免因图像大小差异对实验结果产生影响。
- 最后,按照先前的工作(如Roth等人的研究),使用ROC曲线下面积(AUROC)作为评估指标。AUROC是一种常用的评估指标,它能够综合反映模型在不同阈值下的性能表现,通过比较不同模型的AUROC值,可以直观地判断模型的优劣。
4.2 Comparison with State-of-the-art Methods——与现有技术方法的比较
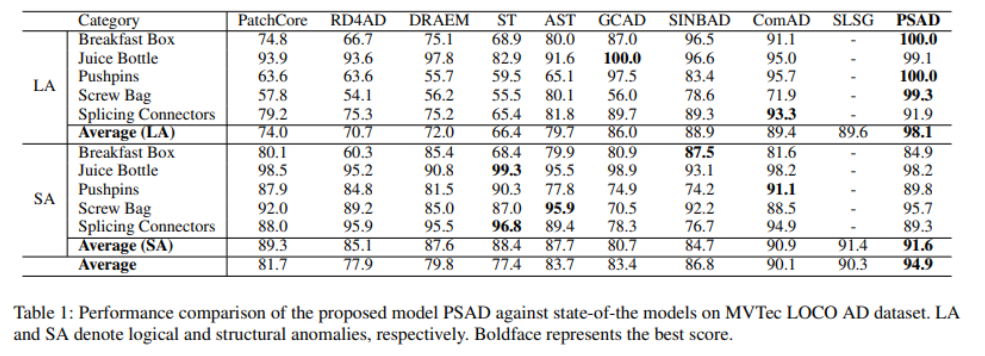
表1列出了在MVTec LOCO AD数据集上训练和测试的方法在逻辑异常(LA)和结构异常(SA)检测中的AUROC。现有设计用于关注局部特征的方法(例如PatchCore、RD4AD、DRAEM、AST、ST)在逻辑异常(LA)检测中得分较低,因为它们无法捕捉图像中多个组件之间的全局依赖关系,尽管在结构异常(SA)检测中表现出较好的分数。虽然最近用于检测逻辑异常(LA)的方法(例如ComAD、GCAD、SINBAD、SLSG)相对于关注局部特征的方法有所改进,但它们仍然无法精确地区分图像内的不同组件。另一方面,我们提出的PSAD在与其他方法相比时有显著的优势(即在逻辑异常(LA)检测中,5个类别上的平均AUROC得分提高了8.5)。值得注意的是,我们在“螺丝袋”类别中实现了99.3%的AUROC分数,而在该类别中其他方法的最高准确性仅为80.1%。此外,我们提出的方法在结构异常(SA)检测中也显示出最佳的平均得分。这些结果表明使用语义信息对于检测逻辑异常(LA)和结构异常(SA)都是有益的。因此,我们提出的方法在这两项任务中都获得了最佳的AUROC分数。
4.3 Qualitative Comparison of FSS Methods——少样本分割(FSS)方法的定性比较
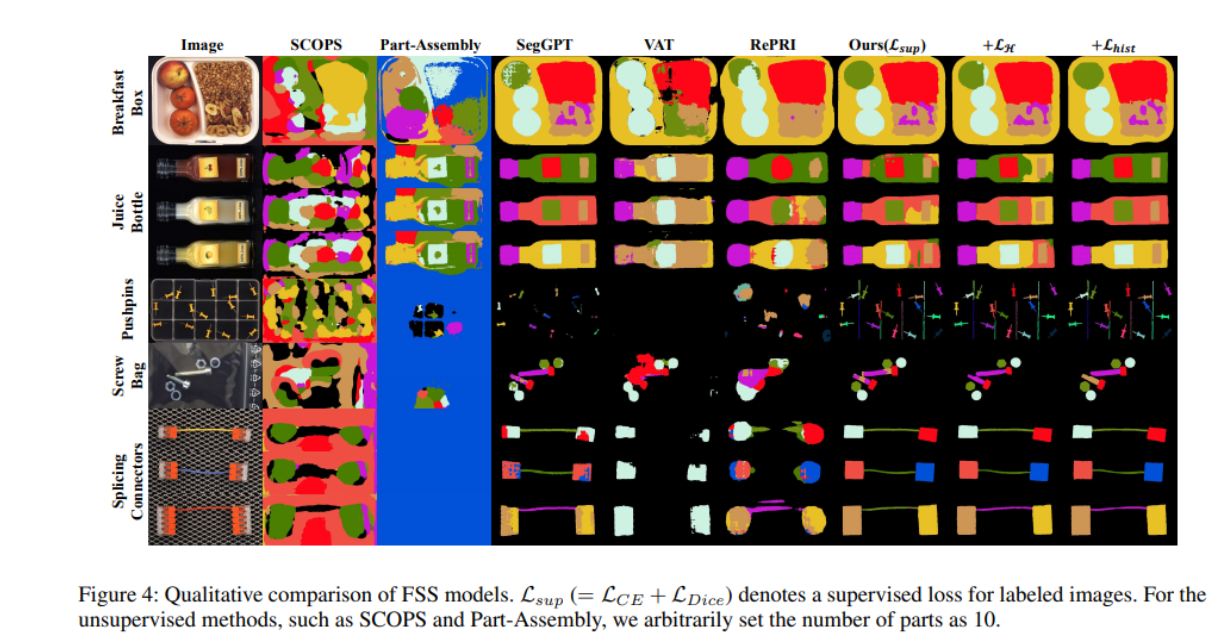
在图4中,我们展示了在MVTec LOCO AD数据集上不同分割模型的定性比较。当我们应用无监督的共部分分割模型SCOPS(Hung等人,1999)和Part - Assembly(Gao等人,2021)时,我们得到了任意的分割结果,这些结果无法区分应该被分割为不同类别的不同组件。
在某些情况下,Part - Assembly无法获得正确的结果,因为它专注于单个体对象。
我们还评估了各种先进的少样本分割(FSS)模型:一个基于元学习的模型VAT(Hong等人,2022),一个基础模型SegGPT(Wang等人,2023),以及一个转导模型RePRI(Boudiaf等人,2021)。VAT和RePRI,各自具有在PASCAL - 5 i 5^{i} 5i数据集(Shaban等人,1976)上预训练的ResNet - 101骨干网络,在大多数情况下表现不佳。
这是由于(1)训练期间冻结的编码器,(2)在不同领域数据上预训练的编码器,以及(3)依赖不准确/噪声初始预测的模型。虽然SegGPT在某些类别如“果汁瓶”中表现出相对较好的结果,但在多个组件具有相似纹理但不同类别的情况下表现出有限的性能。
例如在图4中,SegGPT无法区分“拼接连接器”的左右部分以及“螺丝袋”中的短长螺栓,因为它们具有相似的纹理。现有少样本分割(FSS)方法的局限性主要归因于使用现有分割数据集训练模型,这些数据集不需要考虑位置或长度比较。由于大多数元学习的少样本分割(FSS)模型专注于基于纹理和形状区分类别,它们在工业图像上也同样表现出有限的准确性,因为工业图像可能有多个属于不同类别的相似组件。
4.4 Anomaly Detection Using Different Segmentation Model——使用不同分割模型的异常检测
基于分割结果,我们也检查准确分割是否与异常检测(AD)性能相关。表2显示了我们的方法使用不同分割模型时的平均AUROC分数。少样本分割(FSS)模型(SegGPT、VAT和RePRI)和无监督模型(SCOPS和Part - Assembly)在逻辑异常(LA)检测中表现不佳,因为它们在分割某些类别数据(如“图钉”)时表现不佳。然而,值得注意的是,它们的逻辑异常(LA)检测分数高于我们的基线PatchCore。这表明利用即使不完美的分割对于逻辑异常(LA)检测也是有益的。
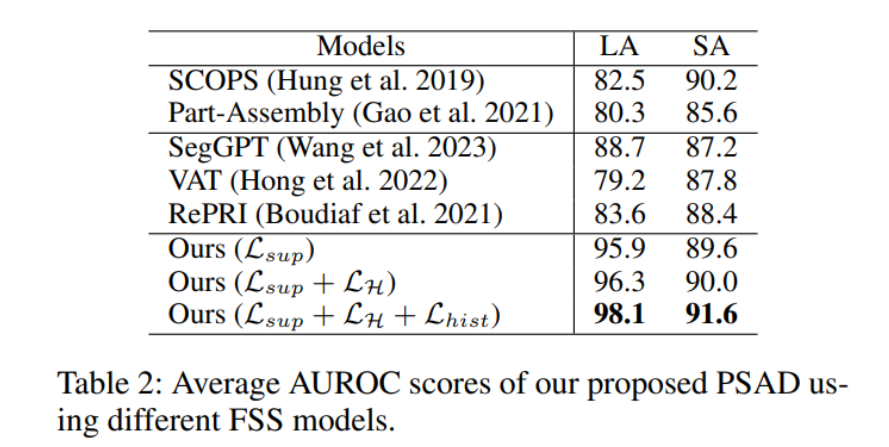
另一方面,我们的模型使用 L s u p ( = L C E + L D i c e ) L_{sup}(=L_{C E}+L_{Dice}) Lsup(=LCE+LDice)训练时表现出显著提高的分数,即使它不如我们的最终模型准确。这表明我们的方法,即联合训练编码器和分类器并利用图像增强和位置信息,对于分割工业图像数据是有益的。当我们使用 L H L_{H} LH和 L h i s t L_{hist} Lhist一起时,我们获得了进一步提高的逻辑异常(LA)检测分数。有趣的是,结构异常(SA)的检测性能也随着更准确的分割结果而增强。这些发现表明准确分割在实现精确异常检测中的关键作用。
4.5 Effect of Various Memory Banks And Adaptive Scaling——各种记忆库及自适应缩放的影响
表3显示了使用不同组合的记忆库时的异常检测(AD)性能。当单独使用每个记忆库时,
M
h
i
s
t
M_{hist}
Mhist和
M
c
o
m
p
M_{comp}
Mcomp在逻辑异常(LA)检测中表现良好但在结构异常(SA)检测中表现不佳,而
M
p
a
t
c
h
M_{patch}
Mpatch则呈现相反的情况。当我们不使用任何缩放策略将3个不同记忆库的异常分数相加时,我们获得了一个更好的逻辑异常(LA)检测分数和一个退化的结构异常(SA)检测分数。这主要归因于异常分数根据记忆库的不同而具有不同的尺度。当我们应用自适应缩放时,我们获得了在逻辑异常(LA)和结构异常(SA)检测中最好的分数。
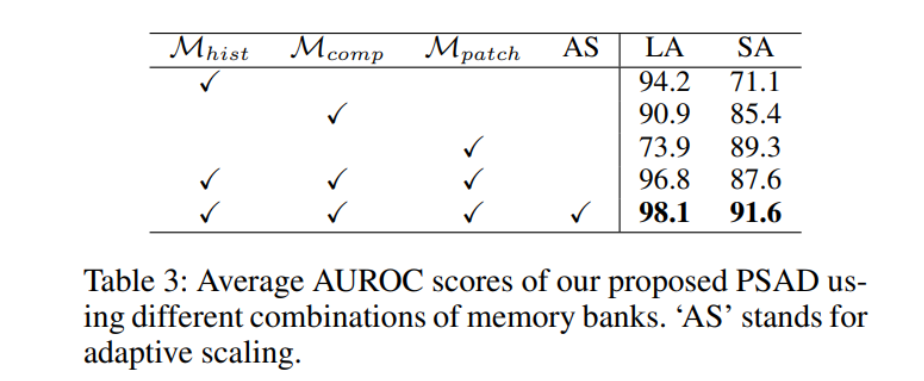
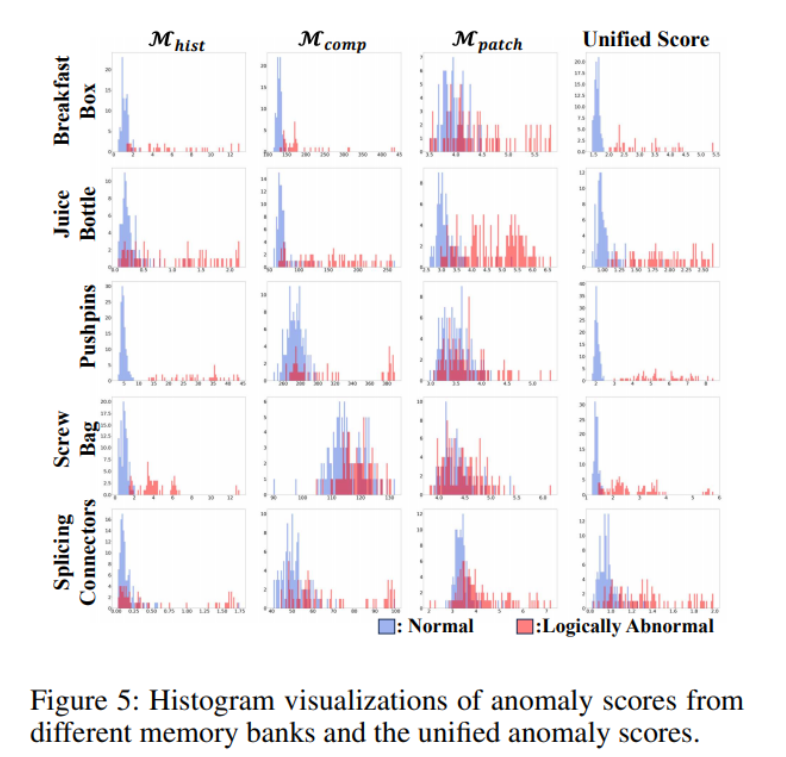
图5展示了从各种记忆库获得的异常分数的直方图以及自适应缩放后的统一异常分数。它表明异常分数的尺度在不同记忆库之间是不同的,这意味着在聚合之前缩放分数是很重要的。值得注意的是,来自补丁级特征记忆库的异常分数由于其依赖于局部特征而较差。然而,在将每个分数归一化并将它们集成到一个统一的分数后,观察到了对正常和异常样本的清晰区分。总体而言,这些发现强调了自适应缩放对于提高使用多个记忆库进行异常检测的有效性的重要性。
4.6 Logical Anomaly Detection Using Less Training Samples——使用较少训练样本的逻辑异常检测
表4列出了使用不同数量的未标记图像时逻辑异常(LA)检测的AUROC。尽管使用较少数据时平均AUROC分数略有下降,但我们的方法仍然优于其他方法,即使在数据集减少的情况下。这一发现强调了准确的分割图在即使数据有限的情况下实现精确逻辑异常(LA)检测的重要性。

五. Conclusion——结论
在本研究中,我们提出了一种用于工业异常检测的新颖方法,该方法利用少量标记样本和未标记图像来准确分割组件并检测异常。我们的方法基于部分分割,由两个主要部分组成:一个是使用少量标记图像和未标记图像共享的逻辑约束进行训练的部分分割模型,另一个是利用从部分分割构建的三个记忆库进行异常检测的模块。
我们在公共基准MVTec LOCO AD数据集上评估了我们的方法,该数据集包含结构异常和逻辑异常。实验结果表明,我们的方法在逻辑异常检测中实现了98.1%的AUROC,在结构异常检测中也取得了优异的成绩,优于现有方法。
我们的研究表明准确的部分分割对于逻辑异常检测至关重要。通过利用少量标记样本和未标记图像的逻辑约束,我们的部分分割模型能够有效地分割组件。此外,我们提出的三个记忆库(类直方图记忆库、组件组成记忆库和补丁级特征记忆库)能够从不同角度捕捉图像的特征,为异常检测提供了丰富的信息。同时,我们提出的自适应缩放策略能够有效地聚合不同尺度的异常分数,提高了异常检测的性能。
我们的研究为工业异常检测提供了一种新的思路和方法,特别是对于逻辑异常的检测具有重要的应用价值。未来的研究可以进一步探索如何更好地利用未标记图像的信息,以及如何进一步提高部分分割的准确性和异常检测的性能。
写在最后
可能我个人目前也还只是本科生,刚刚也才读几篇科研论文,也许并没有资格对前辈们写的大佬进行点评,这里只想记录一下目前精读完几篇论文的感谢吧。
首先这篇文章精读的论文是我有史以来见过最简洁,思路最清晰明了,方法、实验讲解最清晰的论文。大部分我看过的论文都说的太“高级”,其实我看的云里雾里也很暗理解。
但这篇论文由浅入深,一步一步,力求让每一个督读到这篇论文的“小白”都能增长知识,增长见解,而不是“看似高级,其实一头雾水”。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











