






2024深度学习发论文&模型涨点之——频域+注意力机制
频域结合注意力机制是一种在信号处理和深度学习领域中新兴的技术,它通过在频率域中分析信号的特性,并利用注意力机制来增强模型对关键特征的识别能力。
频域+注意力机制的优势:
特征选择:注意力机制可以帮助模型自动选择最重要的频率特征,减少噪声和不相关特征的干扰。
表示能力:结合频域分析和注意力机制可以提供更丰富的特征表示,使模型能够捕捉到更细微的模式和趋势。
计算效率:在某些情况下,频域分析可以减少模型的计算负担,因为频率成分通常比时间域信号更加稀疏。
泛化能力:通过关注关键频率成分,模型可以更好地泛化到新的、未见过的数据上。
论文原文+开源代码需要的同学关注“AI科研论文”公号,那边回复“频域+注意力机制”获取。
论文1:
A Comparative Study of CNN, ResNet, and Vision Transformers for Multi-Classification of Chest Diseases
用于胸部疾病多分类的CNN、ResNet和视觉变换器的比较研究
方法
模型比较:研究比较了卷积神经网络(CNN)、残差网络(ResNet)和视觉变换器(Vision Transformers,简称ViT)在胸部疾病多标签分类任务中的性能。
数据集使用:使用了国家卫生研究院(NIH)胸部X光数据集,该数据集包含超过100,000张胸部X光图像,用于模型的训练和评估。
模型训练:对视觉变换器模型进行了微调,包括在ImageNet上预训练的模型和从零开始训练的模型。
性能评估:通过准确率这一指标对不同模型的性能进行了严格评估,并比较了它们在14种胸部疾病分类任务上的表现。
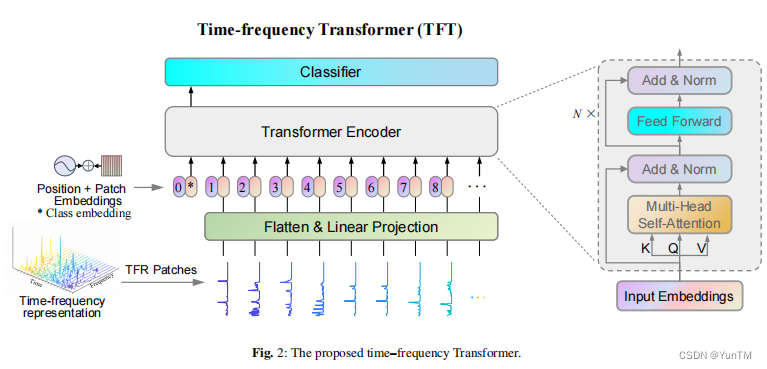
创新点
视觉变换器的应用:研究首次将视觉变换器模型应用于胸部疾病的多标签分类任务,并展示了其在提高分类准确性方面的潜力。
预训练模型的优势:研究发现,预训练的视觉变换器模型在多标签分类任务中的表现超越了传统的卷积神经网络和残差网络模型。
深度学习技术的进步:研究强调了深度学习技术在医学图像分析中的重要性,尤其是在提高胸部疾病检测准确性方面。
论文2:
CONVOLUTION-BASED CHANNEL-FREQUENCY ATTENTION FOR TEXT-INDEPENDENT SPEAKER VERIFICATION用于文本无关说话人验证的基于卷积的通道-频率注意力
方法
模型构建:提出了一种高效的二维卷积基注意力模块C2D-Att,通过轻量级卷积层涉及卷积通道和频率之间的交互来计算注意力权重。
数据集使用:在VoxCeleb数据集上进行实验,该数据集包含超过100万条来自5994名说话者的语音样本。
模型训练:使用Adam优化器和Additive Angular Margin softmax(AAM-softmax)函数作为识别损失进行训练。
性能评估:通过比较不同模型在VoxCeleb数据集上的等错误率(EER)和最小检测成本函数(minDCF)来评估模型性能。
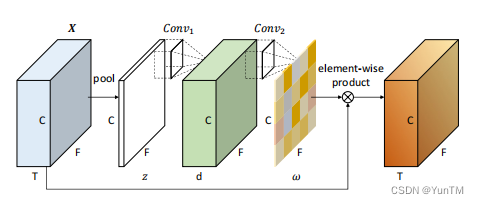
创新点
通道-频率注意力机制:C2D-Att模块能够产生细粒度的通道和频率特定信息的注意力权重,以改善说话人建模的表示能力。
参数效率:与SE模块相比,C2D-Att在注意力计算中使用更少的参数,提高了效率。
性能提升:实验结果表明,C2D-Att在生成区分性注意力图和超越其他注意力方法方面是有效的,并且在不同规模的模型大小下都能实现稳健的性能。
论文3:
CycleGAN-based Non-parallel Speech Enhancement with an Adaptive Attention-in-attention Mechanism
基于CycleGAN的非平行语音增强与自适应注意力-注意力机制
方法
模型构建:提出了一种新颖的自适应注意力-注意力CycleGAN(AIA-CycleGAN)用于非平行语音增强,包括自适应时频注意力(ATFA)和自适应层次注意力(AHA)。
数据集使用:使用公开的Voice Bank语料库进行训练和测试,包含28名说话者的训练集和2名未见过的说话者的测试集。
模型训练:采用Adam优化器进行训练,使用相对对抗损失、循环一致性损失和身份映射损失共同优化模型。
性能评估:通过客观指标(如PESQ、STOI、SSNR等)和主观质量评估DNSMOS来评估语音增强性能。
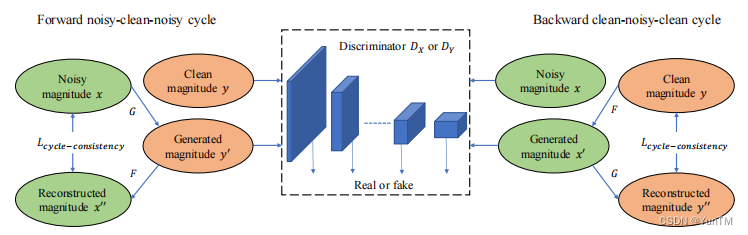
创新点
自适应注意力-注意力机制:AIA模块能够更灵活地学习特征融合和特征相关性,特别是在非平行训练中提高了性能。
语音完整性和失真减少:AIA-CycleGAN在保持语音完整性和减少语音失真方面表现优于其他基于GAN和非GAN的语音增强方法。
非平行训练的优越性:在非平行训练中,AIA-CycleGAN能够实现与平行训练相当的性能,并且在某些情况下优于现有的GAN和CycleGAN方法。
论文4:
FECAM- Frequency Enhanced Channel Attention Mechanism for Time Series Forecasting
用于时间序列预测的频率增强通道注意力机制
方法
模型构建:提出了一种新型的频率增强通道注意力机制(FECAM),基于离散余弦变换(DCT)自适应地建模通道间频率互依赖性。
数据集使用:在六个真实世界的数据集上进行测试,包括能源、天气、交通、经济和地震预警等领域的数据。
模型训练:通过最小化均方误差(MSE)进行训练,并将FECAM作为模块灵活应用于不同的网络结构中。
性能评估:通过比较FECAM与传统的LSTM、Reformer、Informer、Autoformer和Transformer等模型的性能,评估其在时间序列预测任务上的有效性。

创新点
避免吉布斯现象:FECAM基于DCT,从根本上避免了傅里叶变换(FT)中因周期性问题引起的吉布斯现象和高频噪声。
频率域建模:FECAM通过在频率域中建模,能够为不同的通道分配权重,并学习每个通道不同频率的重要性,从而学习时间序列的频率域表示。
模块化设计:FECAM作为一个模块化设计,可以轻松地添加到现有的时间序列预测模型中,以提高预测性能,同时保持计算复杂度。

















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









