







文章目录
前言
免疫浸润是指免疫细胞如淋巴细胞、浆细胞、巨噬细胞等进入到组织或器官中,并在这些组织或器官中发挥免疫功能的过程。免疫细胞的浸润可以是炎症反应的一部分,也可以是针对感染、肿瘤或其他疾病的免疫应答的一部分。
免疫浸润通过调节免疫反应和炎症反应的程度和类型,起到维护机体免疫平衡和清除异常细胞或病原体的作用。在某些情况下,免疫浸润可能导致炎症反应过度,引起组织损伤,例如自身免疫性疾病。因此,免疫浸润在许多疾病的诊断和治疗中都具有重要的意义。
免疫浸润可以通过组织切片染色和免疫组织化学等方法观察和分析。通过分析免疫细胞的类型、分布和密度,可以帮助医生判断疾病的类型、预后和治疗反应。免疫浸润也是免疫治疗的一个重要指标,一些抗肿瘤药物和免疫疗法目前已用于增强免疫浸润来治疗癌症。
一、为什么要进行免疫浸润分析?
诊断和鉴别诊断:免疫浸润可以提供关于疾病类型和性质的重要信息。不同类型的疾病在免疫细胞的浸润模式上可能存在差异,因此通过分析免疫细胞的类型和分布可以帮助医生进行准确的诊断和鉴别诊断。
预后评估:免疫浸润与疾病的预后密切相关。一些研究表明,某些免疫细胞的浸润水平与患者的生存期、复发率和治疗反应等有关。因此,通过分析免疫细胞的浸润情况可以对患者的预后进行评估,为个体化的治疗方案提供依据。
治疗导向:免疫浸润分析可以为个体化的治疗方案提供指导。免疫细胞的浸润与免疫治疗的疗效密切相关,一些疾病可能对免疫治疗更为敏感。通过分析免疫细胞的浸润情况可以预测患者对免疫治疗的反应,从而选择最合适的治疗方案。
治疗监测:免疫浸润分析可以用于监测治疗效果。治疗后,免疫细胞的浸润情况可能发生变化。通过定期分析免疫细胞的浸润情况,可以评估治疗的效果并进行适时的调整。
总的来说,免疫浸润分析可以提供关于疾病类型、预后、治疗导向和治疗监测的重要信息,有助于指导临床决策和个体化治疗。
二、如何进行免疫浸润分析
本期我们介绍一下简单易上手的Cibersort算法。CIBERSORTx是Newman等人开发的一种分析工具,可基于基因表达数据估算免疫细胞的丰度:
CIBERSORT是一种在单个样本中进行免疫细胞类型比例推断的计算方法。它是由斯坦福大学的团队开发的,通过基因表达数据进行免疫细胞类型的浸润程度推断。使用了一组免疫相关的参考基因表达特征,这些特征由已知免疫细胞类型的基因表达数据构建而成。在分析中,CIBERSORT将待推断样本的基因表达数据与参考基因表达特征进行比较,从而推断出样本中不同免疫细胞类型的相对比例。
CIBERSORT的工作原理基于免疫细胞类型在基因表达模式上的独特性。每个免疫细胞类型都有不同的基因表达特征,通过量化样本与已知免疫细胞类型的相似度,CIBERSORT可以对各个细胞类型的比例进行推断。
在使用CIBERSORT进行分析时,首先需要准备待推断样本的基因表达数据,并下载相应的参考基因表达特征文件。然后,在R或命令行中运行CIBERSORT软件包,将样本数据输入,并进行计算。最后,CIBERSORT会输出每个免疫细胞类型的相对比例。
三、实现流程
1.数据准备
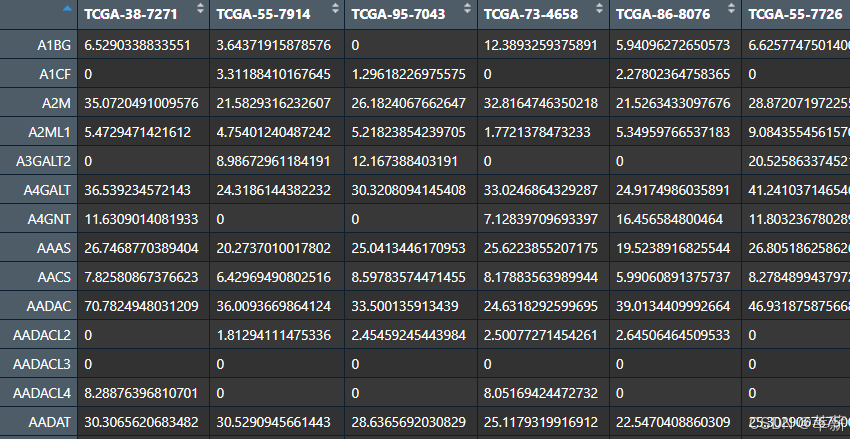
1. 基因表达矩阵
行名是基因名,列名是样本名(大致就是以下类型的格式)
2. LM22.file文件
主要包含22种免疫细胞在基因中的表达情况
展示如下:

2.Cibersort分析
1. 数据处理
# 可以直接从这里开始
# 这个也跑一遍即可,保存结果
if(T){
# 基因表达数据,行名是基因名,列名是样本名
TCGA_exp.file <- "./extdata.txt"
library(CIBERSORT)
# 从CIBERSORT中获取参考免疫细胞的数据LM22.file
LM22.file = system.file("extdata", "LM22.txt", package = "CIBERSORT")
# 估计样本中各种细胞类型的相对比例
TCGA_TME.results <- CIBERSORT(LM22.file ,TCGA_exp.file, perm = 1000, QN = F) # 通过设置 perm = 1000,表示进行 1000 次重抽样或排列来评估结果的稳定性和统计显著性。QN = F 表示不进行定量标准化(quantile normalization)处理
}
2. 分组
进行正式的免疫浸润分析开始之前,我们要根据自己的实际需求,对所拥有的样本进行分析,不同的分析,最终得到的结果也会有不同的意义!(比如按照正常组和疾病组进行哦分析,可以清晰的看到免疫细胞之间表达的差异)
TCGA_TME.results <- read.csv('./TCGA_CIBERSORT_Results500.csv',header = T,row.names = 1)
library(dplyr)
# 分组
# 这里导入的是对样本名称的分组水平
load('5genemodel_riskscore.Rdata')
group_list <- riskScore_df$risk %>%
# 这里将因子水平设置为high和low两个表达水平
factor(.,levels = c("high","low"))
table(group_list)
# group_list
# high low
# 250 250
3. 数据可视化
1.箱线图
1. 数据粗处理
# 提取前22列的免疫细胞相关的数据
TME_data <- as.data.frame(TCGA_TME.results[,1:22])
# 添加分组列
TME_data$group <- riskScore_df$risk[match(rownames(TME_data), rownames(riskScore_df))]
TME_data$sample <- row.names(TME_data)
2. 融合数据
library(reshape2)
TME_New = melt(TME_data) # 将宽格式转换为长格式
colnames(TME_New)=c("Group","Sample" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1947
1947

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











