CLIP 中不一定会被注意的细节(ResNet 网络的改进)
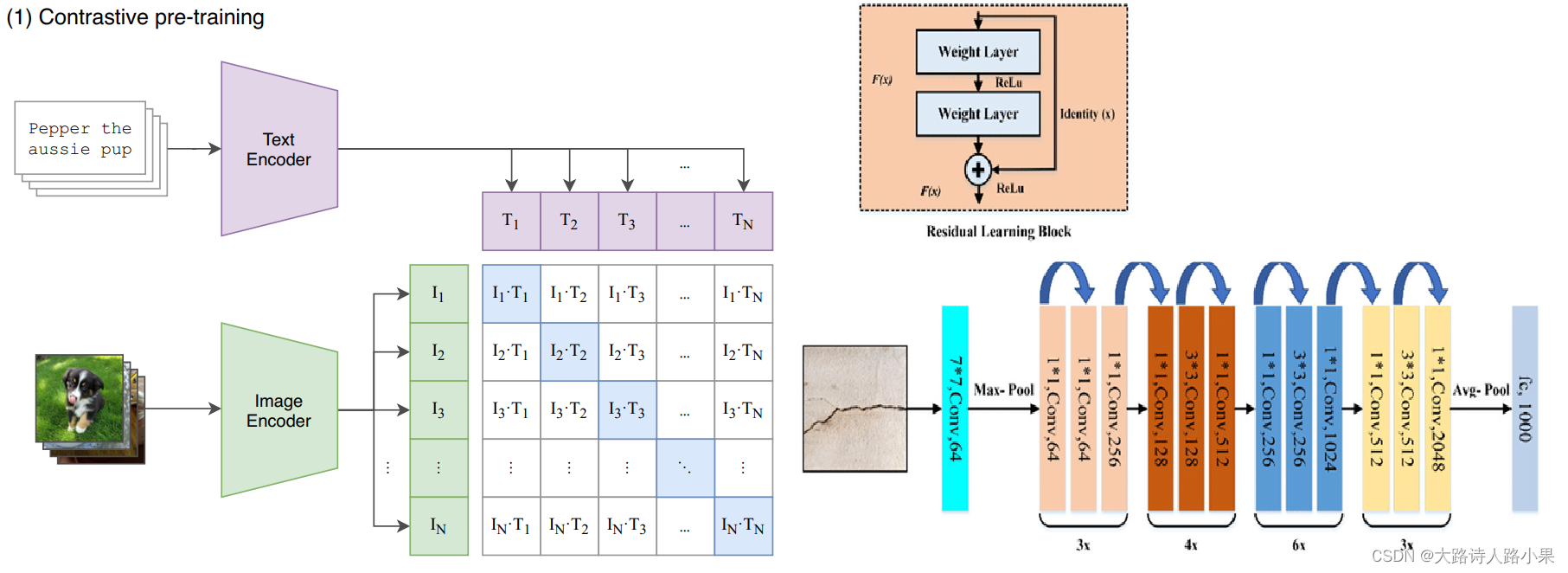
在一开始使用CLIP的时候,CLIP的 ResNet50 网络并不是直接从 torchvision.models 直接导入进来的,这一点对于CLIP的模型设计非常重要。
更改原因
-
1. 首先想要进行 CLIP 这样的对比学习,进行特征比较的过程需要的向量,仅仅是特征向量长度而不是序列,所以没有序列维度,而ResNet这样的网络去掉池化和全连接出来的特征如果输入的是标准大小的图片的话是一个(7*7)的特征向量。所以这个向量含有位置信息,而不能对齐局部信息
- There are now 3 “stem” convolutions as opposed to 1, with an average pool instead of a max pool.
- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1
- The final pooling layer is a QKV attention instead of an average pool
-
中文意思就是:
- 与之前仅有1个的不同,现在有 3个“茎”卷积层 ,并且采用 平均池化 而非最大池化。
- 执行抗锯齿的步幅卷积,当步幅大于1时,在卷积之前添加平均池化。
- 最后的 池化层 采用了QKV 注意力机制,而不是平均池化。
对比之下我们就可以看出来不同
ModifiedResNet(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU(inplace=True)
(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu2):








 文章介绍了在使用CLIP进行对比学习时,对原始ResNet网络进行的改进,重点在于移除池化层后添加注意力池化,以消除位置信息并适应特征向量的对比需求。
文章介绍了在使用CLIP进行对比学习时,对原始ResNet网络进行的改进,重点在于移除池化层后添加注意力池化,以消除位置信息并适应特征向量的对比需求。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5592
5592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









