










目标检测中的正负样本分配策略是目标检测算法中的关键环节,它决定了哪些样本被用作正样本(即包含目标物体的样本)和哪些样本被用作负样本(即不包含目标物体的样本)。这些策略对于提高检测精度和训练效率至关重要。
一、常见分配策略
1. 基于IoU(交并比)的分配策略
MaxIoU匹配:
- 原理:通过计算每个候选框(anchor或proposal)与真实框(ground truth, GT)之间的IoU值,并根据设定的阈值来确定正负样本。
- 步骤:
- 计算每个GT和所有候选框的IoU。
- 对于每个候选框,找到与其IoU最大的GT。
- 根据IoU值是否超过设定的正样本阈值或低于负样本阈值,将候选框分配为正样本或负样本。
- 应用:广泛应用于Faster R-CNN、Mask R-CNN、SSD、YOLOv3等目标检测框架中。
ATSS(Adaptive Training Sample Selection):
- 原理:ATSS根据候选框与GT之间的IoU以及中心点距离来动态设置正样本阈值。
- 步骤:
- 计算每个候选框与所有GT的中心点距离,并选择距离最小的前k个GT。
- 计算这些候选框与对应GT的IoU,并计算IoU的均值和标准差。
- 使用均值和标准差的和作为正样本筛选阈值,将IoU大于该阈值的候选框分配为正样本。
- 优点:能够根据不同大小和形状的目标动态调整正样本阈值,提高检测精度。
2. 基于损失的分配策略
SimOTA(Simple Optimal Transport Assignment):
- 原理:SimOTA将正负样本分配问题转化为一个最优传输(Optimal Transport, OT)问题,通过最小化传输成本来分配正负样本。
- 步骤:
- 计算每个候选框与GT之间的IoU损失和分类损失。
- 构造一个成本矩阵,其中每个元素表示将一个候选框分配给一个GT的成本(通常是IoU损失和分类损失的加权和)。
- 使用SimOTA算法(如Top-K近似策略)来找到成本最小的分配方案。
- 应用:YOLOX和YOLOv6等框架采用了SimOTA策略,以提高检测精度和训练效率。
3.Multi-Anchor策略:
- 在YOLOv4等框架中,只要anchor与GT的IoU大于某个阈值,该anchor就可以作为正样本。这种策略增加了正样本的数量,有助于提高检测精度。
4.基于宽高比的领域匹配策略:
- 如YOLOv5中引入的自适应anchor box和领域正负样本分配策略。该策略根据anchor box与GT的宽高比例以及GT在特征图中的位置来分配正负样本,以增加高质量正样本的数量并加速收敛。
v5在v4的基础上引入自适应anchor box(Auto Learning Bounding Box Anchors)和领域正负样本分配策略
- 自适应anchor box: 训练前,针对不同的训练数据,聚类anchor box
- 基于宽高比的领域正负样本分配策略: 增加高质量正样本检测框可以显著加速收敛,v5的领域正负样本分配策略:
- 宽高匹配: 将ground truth与当前feature map中的anchor box进行比较,如果ground truth与anchor box的宽高比例都处在[1/4, 4]那么这个ground truth就能与当前featuer map相匹配。
- 领域匹配: 将当前feature map中的ground truth分配给对应的grid cell。将这个grid cell分为四个象限,针对与当前feature map匹配的ground truth,会计算该ground truth处于四个象限中的哪一个,并将邻近的两个grid cell中的检测框也作为正样本。如下图所示,若ground truth偏向于右上角的象限,就会将ground truth所在grid cell的上面和右边的grid cell中的检测框也作为正样本。
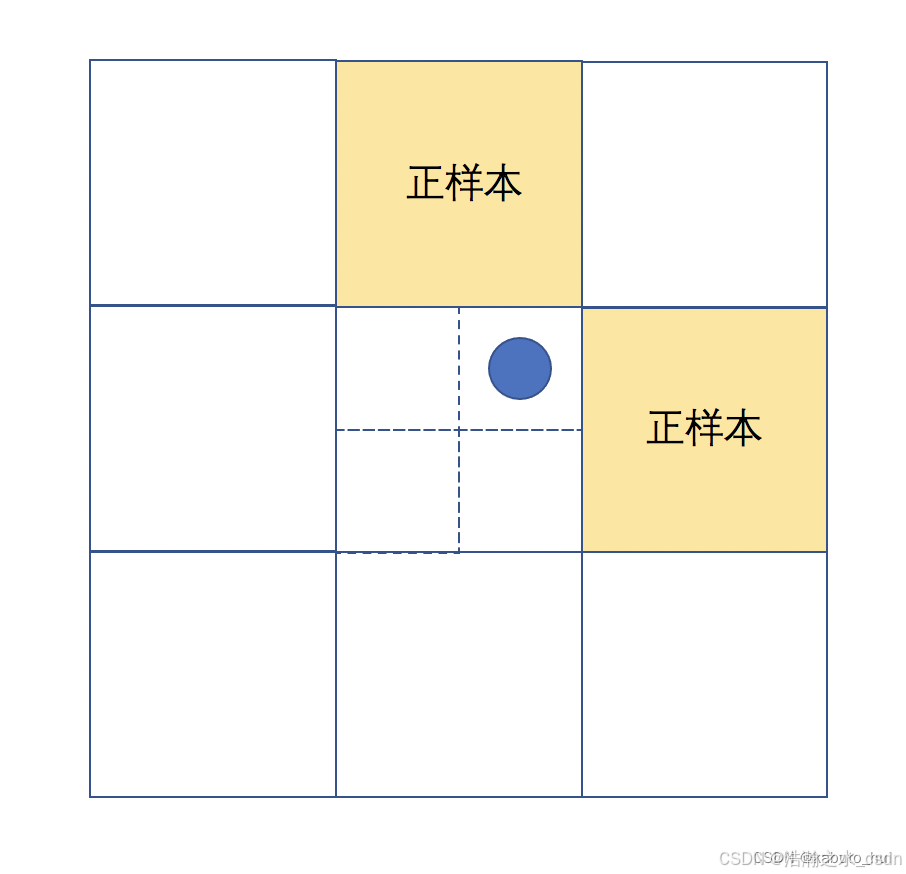
比起yolov4中一个ground truth只能匹配一个正样本,YOLOv5能够在多个grid cell中都分配到正样本,有助于训练加速和正负样本平衡。

总结
正负样本分配策略在目标检测中起着至关重要的作用。不同的策略适用于不同的场景和目标检测框架。在实际应用中,可以根据具体需求和目标检测框架的特点选择合适的分配策略。同时,随着目标检测技术的不断发展,新的分配策略也在不断涌现,为进一步提高检测精度和训练效率提供了可能。
二、常见目标检测正负样本分配策略
2.1 RCNN正负样本分配策略
Fast R-CNN与Faster R-CNN在正负样本分配策略上存在一些差异,这些差异主要体现在它们处理候选区域(proposals)和真实框(ground truth, gt)之间的交并比(Intersection over Union, IoU)的方式上。
Fast R-CNN的正负样本分配策略
在Fast R-CNN中,正负样本的分配主要基于候选区域与真实框之间的IoU。具体来说:
- 正样本:当候选区域与某个真实框的IoU大于或等于0.5时,该候选区域被视为正样本。
- 负样本:如果候选区域与所有真实框的最大IoU值在0.1到0.5之间(不包括0.5),则该候选区域被视为负样本。这种策略有助于确保负样本中包含了一些与真实目标有部分重叠但又不完全匹配的背景区域。
- 难例挖掘:为了处理那些难以区分的负样本(即loss较大的负样本),Fast R-CNN采用了难例挖掘技术。这些样本在训练过程中会被更多地关注,以提高模型对这些困难样本的识别能力。
Faster R-CNN的正负样本分配策略
Faster R-CNN在正负样本分配上采用了更为复杂的策略,主要涉及RPN(Region Proposal Network)和后续的分类器两个阶段:
RPN阶段
- 正样本:对于每个真实框,选择与其IoU最高的一个anchor作为正样本。同时,对于剩余的anchor,如果它们与某个真实框的IoU大于0.7,也被视为正样本。
- 负样本:如果anchor与所有真实框的IoU都小于0.3,则该anchor被视为负样本。
- 忽略的样本:IoU值在0.3到0.7之间的anchor被忽略,不参与训练。
在RPN阶段,为了控制正负样本的比例,通常会从所有候选anchor中选取一定数量的正负样本进行训练。例如,可能会选择256个样本,其中正负样本的比例通常为1:1,但实际情况中可能会根据正负样本的实际数量进行调整。
后续分类器阶段
在RPN阶段生成的候选区域(proposals)会进一步送入后续的分类器进行精细分类和位置回归。在这个阶段,正负样本的分配策略与Fast R-CNN类似,但具体的IoU阈值可能有所不同。通常,当proposals与真实框的IoU大于或等于某个阈值(如0.5)时,该proposals被视为正样本;而当IoU小于某个阈值(如0.3)时,则被视为负样本。
2.2 YOLO正负样本分配策略
YOLO(You Only Look Once)系列目标检测算法在正负样本分配策略上经历了多个版本的迭代和优化,以提高检测精度和训练效率。以下是YOLO系列中几个关键版本的正负样本分配策略概述:
1. YOLOv1~v3:Max-IoU Matching
- 策略概述:在这些版本中,正负样本的分配主要基于IoU(交并比)匹配。具体地,选择与GT(真实框)具有最大IoU的anchor box作为正样本,剩余的anchor box则被视为负样本。
- 详细步骤:
- 确定GT的中心点所在的网格。
- 计算该网格内所有anchor box与GT的IoU。
- 选择IoU最大的anchor box作为正样本,用于分类、回归和置信度学习;其他anchor box作为负样本,仅用于置信度学习。
选取与gt的IOU最大的bounding box或者anchor,作为真样本,剩余的都是负样本。
YOLOv1:grid cell不包含目标,只计算置信度误差;有目标,选取与gt最大IOU的bbox计算分类、回归误差;
YOLOv2:5个anchor box;选择与gt最大IOU的anchor来计算分类和回归误差;
YOLOv3:9个anchor box,3个尺度检测头,每个尺度3个anchor box;选择与gt最大IOU的anchor来计算分类和回归误差;
存在的问题:正样本太少,负样本太多。
2. YOLOv4:Multi-Anchor策略
- 策略概述:为了增加正样本的数量,YOLOv4采用了Multi-Anchor策略。只要anchor box与GT的IoU大于某个阈值,该anchor box就可以被视为正样本。
- 详细步骤:
- 计算每个anchor box与所有GT的IoU。
- 如果anchor box与某个GT的IoU大于设定的正样本阈值,则将该anchor box分配为正样本。
- 注意,YOLOv4的GT需要利用Max-IoU原则分配到指定的检测头上,然后再与指定检测头上的anchor box计算正负样本和忽略样本。
3. YOLOv5:基于宽高比的领域匹配策略
- 策略概述:YOLOv5在YOLOv4的基础上引入了自适应anchor box和基于宽高比的领域正负样本分配策略。
- 详细步骤:
- 自适应anchor box:训练前,针对不同的训练数据,聚类生成anchor box。
- 宽高匹配:将GT与当前特征图中的anchor box进行比较,如果GT与anchor box的宽高比例都处在[1/4, 4]范围内,则GT能与当前特征图相匹配。
- 领域匹配:将当前特征图中的GT分配给对应的grid cell,并将该grid cell分为四个象限。对于与当前特征图匹配的GT,会计算该GT处于哪个象限,并将邻近的两个grid cell中的检测框也作为正样本。
4. YOLOX和YOLOv6:SimOTA(Simple Optimal Transport Assignment)匹配策略
- 策略概述:SimOTA是一种动态分配正样本的策略,通过最小化传输成本来找到最佳的正负样本分配方案。
- 详细步骤:
- 计算所有候选框与GT之间的IoU损失和分类损失。
- 构造一个成本矩阵,其中每个元素表示将一个候选框分配给一个GT的成本(通常是IoU损失和分类损失的加权和)。
- 使用SimOTA算法(如Top-K近似策略)来找到成本最小的分配方案,为每个GT选择损失最小的前K个候选框作为正样本。
5. YOLOv7:领域匹配+SimOTA
- 策略概述:YOLOv7结合了YOLOv5的领域匹配策略和YOLOX的SimOTA策略,以实现更高效的正负样本分配。
- 详细步骤:
- 使用YOLOv5的领域匹配策略分配部分正样本。
- 计算每个样本对每个GT的Reg+cls loss(损失感知)。
- 使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k)。
- 为每个GT取loss最小的前dynamic k个样本作为正样本,并人工去掉同一个样本被分配到多个GT的正样本的情况(全局信息)。
6. YOLOv8和YOLOv9:TaskAlignedAssigner匹配策略
- 策略概述:YOLOv8和YOLOv9采用了TaskAlignedAssigner匹配策略,根据分类与回归的分数加权的分数去选择正样本。
- 详细步骤:
- 计算每个点对应的GT类别的分类置信度(s)和每个点对应预测的回归框与GT的IoU(u)。
- 使用加权分数 t=sα+uβ 来衡量对齐程度(alignment metrics)。
- 针对每一个GT,基于alignment metrics选取top-k个样本作为正样本。
这些策略在YOLO系列的不同版本中得到了应用和优化,以提高目标检测的精度和效率。
参考:



















 6348
6348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











