







1. merge
合并两个matrix
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False)
concat函数只能根据索引对齐,而如果想在任意列上对齐合并,则需要merge函数,其在sql应用很多。
- left, right: 两个要对齐合并的DataFrame;
- how: 先做笛卡尔积操作,然后按照要求,保留需要的,缺失的数据填充NaN;
- left: 以左DataFrame为基准,即左侧DataFrame的数据全部保留(不代表完全一致、可能会存在复制),保持原序;
- right: 以右DataFrame为基准,保持原序;
- inner: 交,保留左右DataFrame在on上完全一致的行,保持左DataFrame顺序;
- outer: 并,按照字典顺序重新排序;
- on:对应列名或者行索引的名字,如果要在DataFrame相同的列索引做对齐,用这个参数;通常是相同的列索引用于做为merge的key
- left_on, right_on, left_index, right_index:
- on对应列名或者行索引的名字(所以行索引一般要跟列一样看待,有自己的名字),用这俩参数;
- index对应要使用的index,不建议使用,会搞晕。
- sort: True or False,是否按字典序重新排序。
举例:
result = pd.merge(left, right, how="left", on=["key1", "key2"])
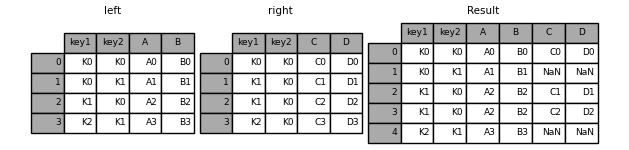
result = pd.merge(left, right, how="right", on=["key1", "key2"])

result = pd.merge(left, right, how="outer", on=["key1", "key2"])
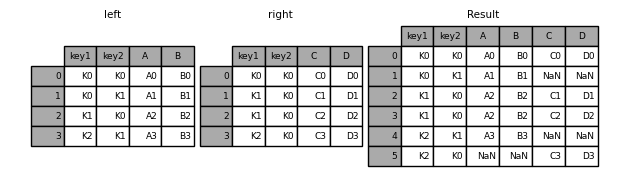
result = pd.merge(left, right, how="inner", on=["key1", "key2"])

result = pd.merge(left, right, how="cross")
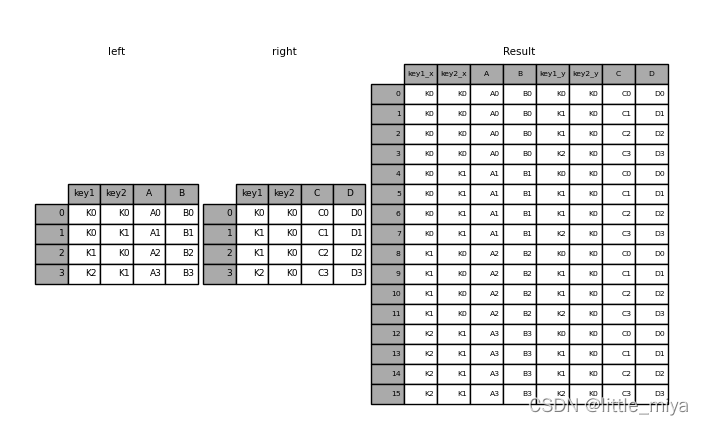
2. set_index
将普通列转换为索引:
DataFrame.set_index(keys, drop=True, append=False, inplace=False)
- keys:用于转化的列名称,列名或列名的列表,如果是列表则转化为多重索引;
- drop:True or False,是否保留原列;
- append:True or False,是否保留当前索引;
- inplace:True or False,是否原地修改。
3. reset_index
索引列转换为普通列
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
- level:int 或者行索引的名字,可以为列表,默认包含所有行索引。
- drop:True or False,是否将行索引插入到列中,默认是插入;
- inplace:是否本地修改;
- col_level:如果列索引也是多重的,那么新插入的列设置哪一重索引;
- col_fill:如果有多重索引,除了col_level已经设置的
4. 快速查看整体信息
DataFrame.info(verbose=None, memory_usage=True, null_counts=True)
快捷查看多种信息:总行数和列数、每列元素类型和非NaN的个数,总内存。
- verbose:True or False,字面意思是冗长的,也就说如何DataFrame有很多列,是否显示所有列的信息,如果为否,那么会省略一部分;
- memory_usage:True or False,默认为True,是否查看DataFrame的内存使用情况;
- null_counts:True or False,默认为True,是否统计NaN值的个数。
DataFrame.describe(include=[np.number])
快速查看每一列的统计信息,默认排除所有NaN元素。
- include:'all’或者[np.number 或 np.object]。numberic只对元素属性为数值的列做数值统计,object只对元素属性为object的列做类字符串统计。















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









